MySQL慢查询及优化
最近做一个CRM系统,发现了慢查询日志里记载了许多的慢sql,于是就对其进行了sql优化。在优化的过程中,自己也归纳整理了一些sql优化的方案。今天就来和大家聊聊。
**1、慢查询的分析**
常见的分析慢查询sql的方法大概有三种:explain、show profile、trace 分析 sql优化器。本文主要介绍explain的方法去分析慢sql,其余两种方法有兴趣的同学可以去了解下。
**2、explain各参数解释**
(1)explain语法:explain+“需分析的sql”;
例:我想分析“select * from table1 where b=500;”这条sql的执行效率,那么直接在sql命令行下执行“expalin select * from table1 where b=500;”就可以查看了;执行结果如下:
根据上图,可以看到有许多个字段,那这些字段分别有什么意义呢?见下图(红框标出的为重点关注字段):
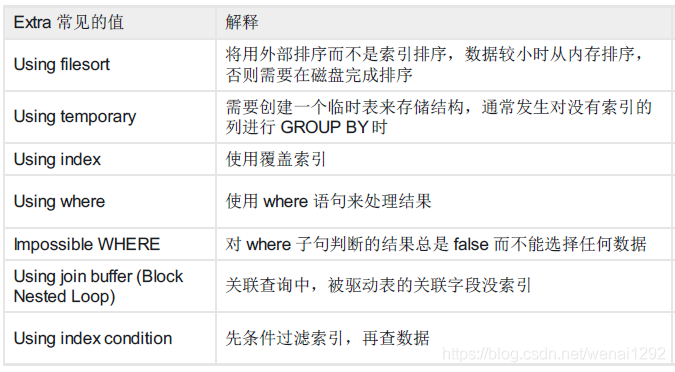
其中各个字段又可能有多个不同的值,重点关注字段select_type、type、Extra的可能值如下图所示: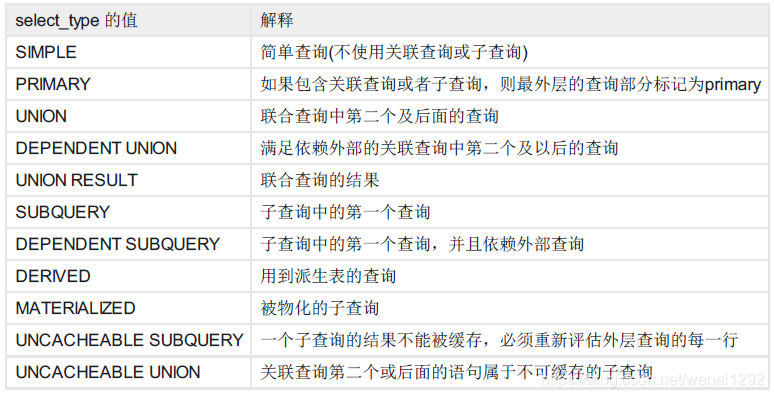

其中,上图中的“type”的值的查询性能从上到下依次是最好到最差。
**3、常用sql优化方法**
(1)使用索引
大家对MySQL的索引应该不会感到陌生吧,数据量大的时候,最常见的加快查询效率的方法那肯定是加索引了,要知道MySQL的B+索引树可是能在2~4层树就能从上亿的数据中提取出相关数据的,不加索引的话得进行上亿次磁盘io查找(关于B+树的具体原理,大家可以参考下这篇文章,写得很不错,http://www.liuzk.com/410.html。索引虽好用,但是存在很多不走索引的情况。下面列举常见几种不走索引的情况,以及如何让它走索引:
①对查询条件使用函数
如:select * from table1 where date(c) ='2020-08-20';
应改为:select * from table1 where c>='2020-08-20 00:00:00' and c<='2020-08-20 23:59:59';
②隐式转换:如把varchar类型当成int型去写
例:select * from table1 where a=1000; (其中,a字段在数据库中是varchar类型)
应改为:select * from table1 where a='1000';
③模糊查询
如:select * from table1 where a like '%1111%';
应改为:select * from table1 where a like '1111%'; 但要看具体业务,可能不对
注意:select * from table1 where a like '%1111'; 这种也是不走索引的
可以这么理解:like 匹配是%在前面的都不走索引
④范围查询
如:select * from table1 where b>=1 and b <=2000; (这条数据查询范围过大,是全表扫描,优化器选择不走索引)
应改为:select * from table1 where b>=1 and b <=1000;
select * from table1 where b>=1001 and b <=2000;
⑤计算操作 (但一般在代码层面做操作,很少会在数据库做操作)
如:select * from table1 where b-1 =1000;
应改为:select * from table1 where b =1000 + 1;
⑥OR 操作
如果条件中有OR,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须建立索引。所以除非每个列都建立了索引,否则不建议使用OR,在多列OR中,可以考虑用UNION 替换
如:select * from table1 where create_time = '2020-08-20 11:49:30' OR b > 854;
应改为:select * from table1 where create_time = '2020-08-20 11:49:30' UNION select * from table1 where b > 854;
(2)分页优化
如:select * from table1 order by a limit 99000,10; (其中,a字段有索引)
但结果不走索引,原因是扫描整个索引并查找到没索引的行的成本比扫描全表的成本更高,所以优化器放弃使用索引。(关键是让排序时返回的字段尽可能少)
应改为:select * from table1 f inner join (select id from table1 order by a limit 99000,10)g on f.id = g.id;
或者 select * from table1 where id >= (select id from table1 order by a limit 99000,1) limit 10;
(3)连接查询优化
在项目中,表连接查询是比较常见的,尤其是一些统计模块。表连接有两种算法,一种叫Nested-Loop Join 算法(简称NLJ),另一种是Block Nested-Loop Join 算法(简称BNL)(关联字段不存在索引时会使用到)。感兴趣的小伙伴可以深入去了解下相关原理哦。我们进行关联查询优化的方法是:尽量让 BNL变成 NLJ ,就是说在关联字段上加上索引。
(4)order by和group by优化
①首先我们要知道MySQL中有两种排序方式,一种是通过有序索引直接返回有序数据(Extra字段:Using index);另一种是通过 Filesort 进行的排序,不走索引(Extra字段:Using filesort);毫无疑问,肯定是有序索引排序更快。
常见order by优化方法:
①在排序字段上添加索引
如:select c,id from table1 order by c; (c有索引)
②多个字段排序,可以在多个排序字段上添加联合索引来优化排序语句
如:select id,a,b from table1 order by a,b; (a,b是联合索引)
注意:select id,a,b from table1 order by b,a; (a,b是联合索引)此时不走索引,最左匹配前缀原则了解下
③对于先等值查询再排序的语句,可以通过在条件字段和排序字段添加联合索引来优化
如:select id,a,b from table1 where a=1000 order by b; (a,b是联合索引)
如果a,b不是联合索引的话,即时有a索引,b索引,排序也不会走索引
④去掉不必要的返回字段
如:select * from table1 order by a,b; /* 根据a和b字段排序查出所有字段的值 */
应改为:select id,a,b from table1 order by a,b; /* 根据a和b字段排序查出id,a,b字段的值 */
不走索引原因:扫描整个索引并查找到没索引的行的成本比扫描全表的成本更高,
所以优化器放弃使用索引。
默认情况,会对 group by 字段排序,因此group by优化方式与 order by 基本一致。
本篇文章就写到这,你们工作中还有什么好的优化sql的方法吗?欢迎在评论区分享!
MySQL慢查询及优化的更多相关文章
- 开启Mysql慢查询来优化mysql
开启Mysql慢查询来优化mysql 优化sql语句是优化数据库的一个很重要的方面,那么怎么发现那些耗时耗资源的sql语句呢,开启Mysql慢查询! 1.查看是否开启慢查询,默认情况下是关闭的.你的m ...
- mysql数据库优化课程---16、mysql慢查询和优化表空间
mysql数据库优化课程---16.mysql慢查询和优化表空间 一.总结 一句话总结: a.慢查询的话找到存储慢查询的那个日志文件 b.优化表空间的话可以用optimize table sales; ...
- MySQL子查询的优化
本文基于MySQL5.7.19测试 创建四张表,pt1.pt2表加上主键 mysql> create table t1 (a1 int, b1 int); mysql> create ta ...
- MySql学习—— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- MySQL之查询性能优化(四)
优化特定类型的查询 COUNT()的作用 COUNT()是一个特殊函数,有两个非常不同的作用:它可以统计某个列值的数量,也可以统计行数.在统计列值时要求列值是非空的(不统计NULL). 如果在COUN ...
- MySQL之查询性能优化(三)
MySQL查询优化器的局限性 MySQL的万能“嵌套循环”并不是对每种查询都是最优的.不过还好,MySQL查询优化只对少部分查询不适用,而且我们往往可以通过改写查询让MySQL高效地完成工作. 关联子 ...
- MySQL之查询性能优化(二)
查询执行的基础 当希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的.MySQL执行一个查询的过程,根据图1-1,我们可以看到当向MySQL发送一个请求时, ...
- MySQL之查询性能优化(一)
为什么查询速度会慢 通常来说,查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段, ...
- 使用聚集索引和非聚集索引对MySQL分页查询的优化
内容摘录来源:MSSQL123 ,lujun9972.github.io/blog/2018/03/13/如何编写bash-completion-script/ 一.先公布下结论: 1.如果分页排序字 ...
- mysql 分页查询及优化
1.分页查询 select * from table limit startNum,pageSize 或者 select * from table limit pageSize offset star ...
随机推荐
- SQL HAVING 子句详解:在 GROUP BY 中更灵活的条件筛选
SQL HAVING子句 HAVING子句被添加到SQL中,因为WHERE关键字不能与聚合函数一起使用. HAVING语法 SELECT column_name(s) FROM table_name ...
- C# 属性概述
属性概述 属性允许类公开获取和设置值的公共方法,而隐藏实现或验证代码. get 属性访问器用于返回属性值,而 set 属性访问器用于分配新值. 这些访问器可以具有不同的访问级别. 有关详细信息,请参阅 ...
- 医疗BI系统如何使医疗行业完成精细化管理转型?
不久前在北京召开的全国医疗管理工作会议,确定了今年的医疗管理工作重点.会议强调,推动医疗管理改革工作的过程中要对形势.规律准确把握,积极应对可能面临的挑战,以"三个转变.三个提高" ...
- openGauss系统函数添加指导
openGauss 系统函数添加指导 1.函数架构简介 openGauss 内函数的可以分为两个部分: 身份注册声明:openGauss 中存在一个系统表 pg_proc,这个表存放了所有函数的基 ...
- HDC技术分论坛:ArkCompiler(方舟编译器)原理解析
作者:xianyuqiang 编译器首席架构师 ArkCompiler(方舟编译器)是组件化.可配置的多语言编译和运行平台,它既能支撑单一语言运行环境,也能支撑多种语言组合的运行环境.它目前主要支持的 ...
- 【开发者说】XstoryMaker快速书写剧本场景动画
原文:https://mp.weixin.qq.com/s/63V0dfD2IufbX92JeD-G_A,点击链接查看更多技术内容. [开发者说]栏目是为HarmonyOS开发者提供的展示和分享平台, ...
- k8s之Pod
什么是Pod 通俗的来讲就是以pause为基础容器,其它容器共享pause容器的网络名称空间.主机名以及进程间通信,组成的一个逻辑的容器集合. • Kubernetes Pod是Kubernetes的 ...
- python3中os.renames()和os.rename()区别
renames源码:def renames(old, new): head, tail = path.split(new) # 作用是分割为两部分,head为路径,tail为文件名: if head ...
- java 后台获取文件上传的真实扩展名
package common.util; import java.io.File; import org.apache.commons.io.FileUtils; import org.apache. ...
- Node 中的 Stream ?应用场景?
一.是什么 流(Stream),是一种数据传输手段,是端到端信息交换的一种方式,是有顺序的,是逐块读取数据.处理内容,用于顺序读取输入或写入输出 在很多时候,流(Stream)是字节流(Byte St ...