jsoup爬取图片到本地
因为项目需求,需要车辆品牌信息和车系信息,昨天用一天时间研究了jsoup爬取网站信息。项目是用maven+spring+springmvc+mybatis写的。
jsoup开发指南地址:http://www.open-open.com/jsoup/
这个是需要爬取网站的地址 https://car.autohome.com.cn/zhaoche/pinpai/
1.首先在pom.xml中添加依赖
因为需要把图片保存到本地所以又添加了commons-net包
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-net/commons-net -->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.3</version>
</dependency>
2.然后是爬虫代码的实现
@Controller
@RequestMapping("/car/")
public class CarController {
//图片保存路径
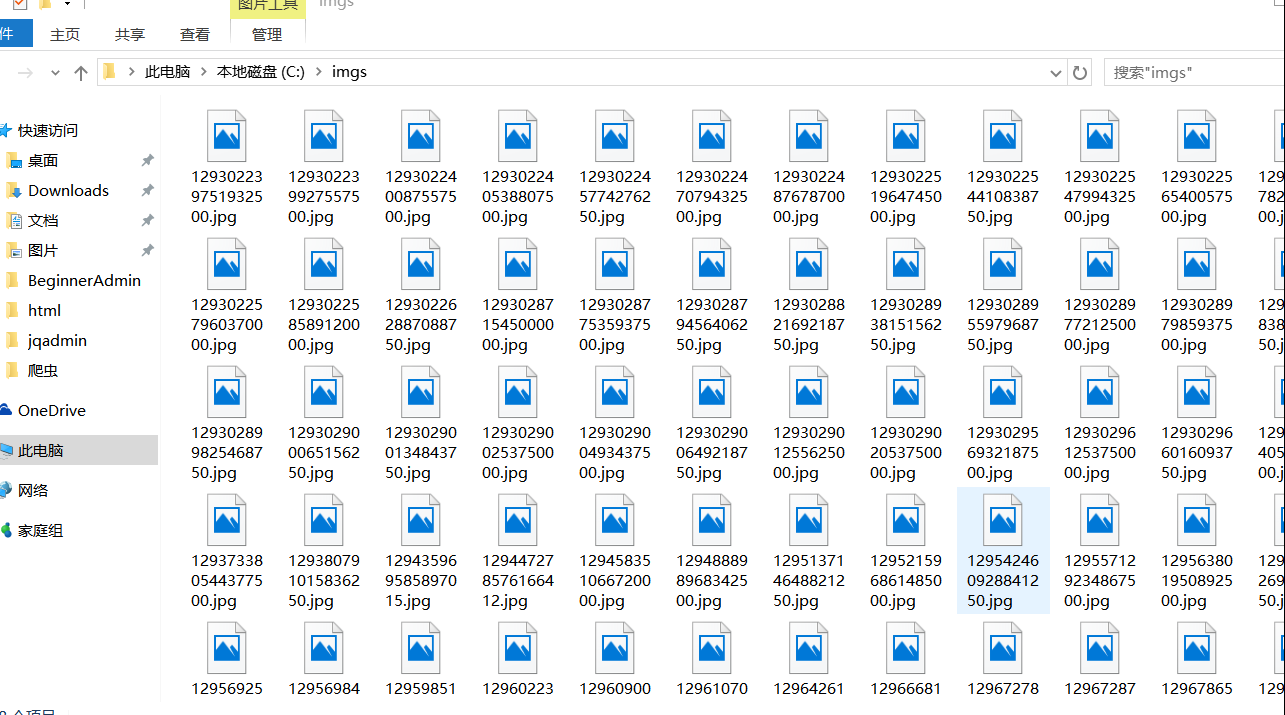
private static final String saveImgPath="C://imgs";
/**
* @Title: insert 品牌名称 和图片爬取和添加
* @Description:
* @param @throws IOException
* @return void
* @throws
* @date 2018年1月29日 下午4:42:57
*/
@RequestMapping("add")
public void insert() throws IOException {
//定义想要爬取数据的地址
String url = "https://car.autohome.com.cn/zhaoche/pinpai/";
//获取网页文本
Document doc = Jsoup.connect(url).get();
//根据类名获取文本内容
Elements elementsByClass = doc.getElementsByClass("uibox-con");
//遍历类的集合
for (Element element : elementsByClass) {
//获取类的子标签数量
int childNodeSize_1 = element.childNodeSize();
//循环获取子标签内的内容
for (int i = 0; i < childNodeSize_1; i++) {
//获取车标图片地址
String tupian = element.child(i).child(0).child(0).child(0).child(0).attr("src");
//获取品牌名称
String pinpai = element.child(i).child(0).child(1).text();
//输出获取内容看是否正确
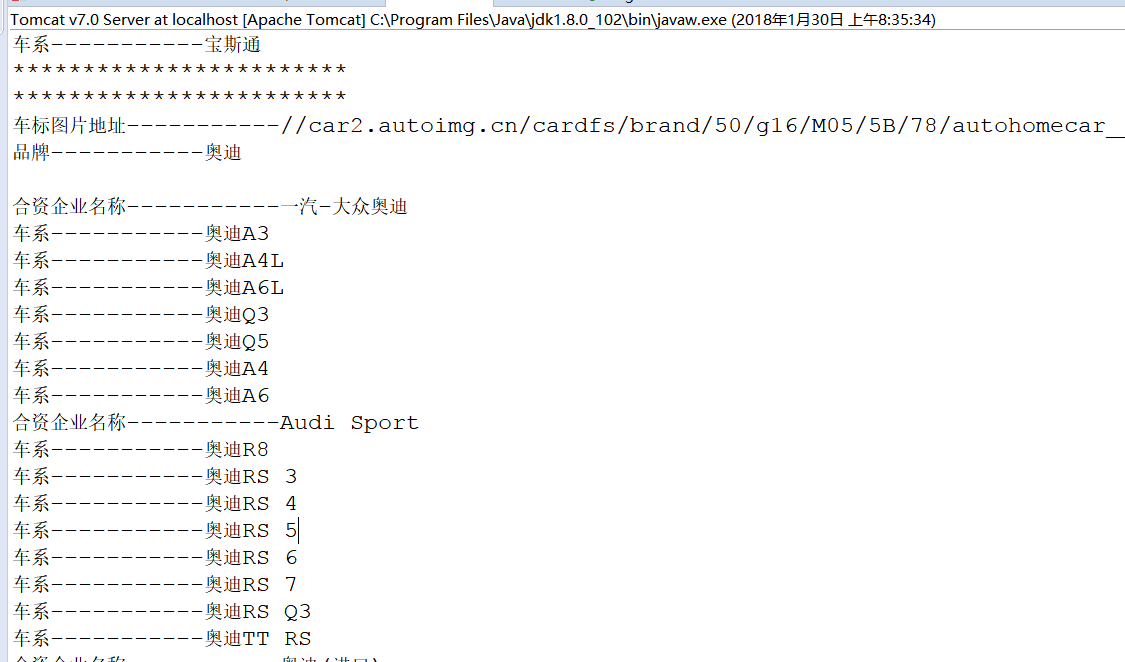
System.out.println("车标图片地址-----------" + tupian);
System.out.println("品牌-----------" + pinpai);
System.out.println();
//把车标图片保存到本地
String tupian_1 = "http:"+tupian;
//连接url
URL url1 = new URL(tupian_1);
URLConnection uri=url1.openConnection();
//获取数据流
InputStream is=uri.getInputStream();
//获取后缀名
String imageName = tupian.substring(tupian.lastIndexOf("/") + 1,tupian.length());
//写入数据流
OutputStream os = new FileOutputStream(new File(saveImgPath, imageName));
byte[] buf = new byte[1024];
int p=0;
while((p=is.read(buf))!=-1){
os.write(buf, 0, p);
}
/**
* 因为每个品牌下有多个合资工厂
* 比如一汽大众和上海大众还有进口大众
* 所有需要循环获取合资工厂名称和旗下
* 车系
*/ //获取车系数量
int childNodeSize_2 = element.child(i).child(1).child(0).childNodeSize();
/**
* 获取标签下子标签数量
* 如果等于1则没有其他合资工厂
*/
int childNodeSize_3 = element.child(i).child(1).childNodeSize();
if(childNodeSize_3==1){
//循环获取车系信息
for (int j = 0; j < childNodeSize_2; j++) {
String chexi = element.child(i).child(1).child(0).child(j).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}else{
/**
* 如果childNodeSize_3大于1
* 则有多个合资工厂
*/
//分别获取各个合资工厂旗下车系
for (int j = 0; j < childNodeSize_3; j++) { int childNodeSize_4 = element.child(i).child(1).child(j).childNodeSize();
/**
* 如果j是单数则是合资工厂名称
* 否则是车系信息
*/
int k = j%2; if(k==0){
//获取合资工厂信息
String hezipinpai = element.child(i).child(1).child(j).child(0).text();
System.out.println("合资企业名称-----------" + hezipinpai);
}else{
//int childNodeSize_5 = element.child(i).child(1).child(0).childNodeSize();
//循环获取合资工厂车系信息
for(int l = 0; l < childNodeSize_4; l++){
String chexi = element.child(i).child(1).child(j).child(l).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}
} } System.out.println("************************");
System.out.println("************************"); }
}
} }
3.运行结果

4.
jsoup爬取图片到本地的更多相关文章
- Java jsoup爬取图片
jsoup爬取百度瀑布流图片 是的,Java也可以做网络爬虫,不仅可以爬静态网页的图片,也可以爬动态网页的图片,比如采用Ajax技术进行异步加载的百度瀑布流. 以前有写过用Java进行百度图片的抓取, ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- PHP 爬取图片 保存本地
public function getImage($url,$filename='') { if($url == ''){ return false; } if($filename == ''){ $ ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
随机推荐
- K:二叉树的非递归遍历
相关介绍: 二叉树的三种遍历方式(先序遍历,中序遍历,后序遍历)的非递归实现,虽然递归方式的实现较为简单且易于理解,但是由于递归方式的实现受其递归调用栈的深度的限制,当递归调用的深度超过限制的时候, ...
- Python可视化库Matplotlib的使用
一.导入数据 import pandas as pd unrate = pd.read_csv('unrate.csv') unrate['DATE'] = pd.to_datetime(unrate ...
- kotlin的方言(语法糖)
概述 之前介绍了kotlin的快速入门,http://www.cnblogs.com/lizo/p/7231167.html 大多数还是参照java.kotlin中提供了更多更方便的语言特性 这个方言 ...
- Keepalived学习笔记
注LVS(Linux Virtual Server):Linux虚拟服务器,这里通过keepalived作为负载均衡器RS(Real Server):真实服务器VRRP(Virtual Router ...
- AIO5凭证性质设置接收下/上差(%),但是订单操作不起效。
问题: AIO5凭证性质设置接收下/上差(%),但是订单操作不起效. 例如: 现在采购订单下了200个,我想限制收货只能收两百以内. 在在线帮助上看到有接收下/上差(%)字段可以进行限制,但是在凭证性 ...
- Flask知识点一
1 flask安装 pip3 install falsk 一Werkzeug Werkzeug是什么? Werkzeug就是Python对WSGI的实现的一个通用库,它是Flask所使用的底层WSGI ...
- python3之模块
1.python3模块 模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py.模块可以被别的程序引入,以使用该模块中的函数等功能.这也是使用 python 标准库的方法. 模块让你能够有逻辑地 ...
- Error: Your project contains C++ files but it is not using a supported native build system
我在编写有关JNI的代码的时候回报这个错误,我在网上搜了相关的资料后,找到了一篇文章解决了这个问题,点击这里查看这篇文章,我在照着这篇文章尝试的时候,总有一些错误,现在我把自己详细的解决流程贴出来,供 ...
- Spring框架入门之基于xml文件配置bean详解
关于Spring中基于xml文件配置bean的详细总结(spring 4.1.0) 一.Spring中的依赖注入方式介绍 依赖注入有三种方式 属性注入 构造方法注入 工厂方法注入(很少使用,不推荐,本 ...
- ssh远程登录命令简单实例
ssh远程登录命令简单实例 ssh命令用于远程登录上Linux主机. 常用格式:ssh [-l login_name] [-p port] [user@]hostname 更详细的可以用ssh -h查 ...