KNN算法--python实现
邻近算法
或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
关于K最近邻算法,非常好的一篇文章:KNN算法理解; 另外一篇文章也值得参考:KNN最近邻Python实现
行业应用: 客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)
写在前面的:Python2.7
数据iris: http://pan.baidu.com/s/1bHuQ0A 测试数据集: iris的第1行数据; 训练数据: iris的2到150行数据
#coding:utf-8
import pandas as pd
import numpy as np class KNNa(object): #获取训练数据集
def getTrainData(self):
dataSet = pd.read_csv('C:\pythonwork\practice_data\iris.csv', header=None)
dataSetNP = np.array(dataSet[1:150])
trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #获得训练数据
labels = dataSetNP[:,dataSetNP.shape[1]-1] #获得训练数据类别
return trainData,labels
#得到测试数据的类别
def classify(self, testData, trainData, labels, k):
#计算测试数据与训练数据之间的欧式距离
dist = []
for i in range(len(trainData)):
td = trainData[i,:] #训练数据
dist.append(np.linalg.norm(testData - td)) #欧式距离
dist_collection = np.array(dist) #获得所有的欧氏距离,并转换为array类型
dist_index = dist_collection.argsort()[0:k] #按升序排列,获得前k个下标
k_labels = labels[dist_index] #获得对应下标的类别 #计算k个数据中,类别的数目
k_labels = list(k_labels) #转换为list类型
labels_count = {}
for i in k_labels:
labels_count[i] = k_labels.count(i) #计算每个类别出现的次数
testData_label = max(labels_count, key=labels_count.get) #次数出现最多的类别
return testData_label if __name__ == '__main__':
kn = KNNa()
trainData,labels = kn.getTrainData() #获得训练数据集,iris从第2行到第150行的149条数据
testData = np.array([5.1, 3.5, 1.4, 0.2]) #取iris中的数据的第1行
k = 10 #最近邻数据数目
testData_label = kn.classify(testData,trainData,labels,k) #获得测试数据的分类类别
print '测试数据的类别:',testData_label
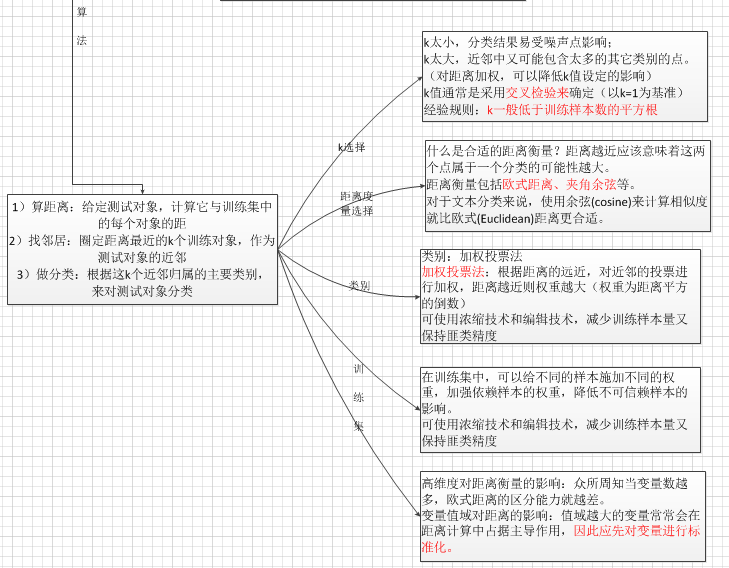
理论:

KNN算法--python实现的更多相关文章
- kNN算法python实现和简单数字识别
kNN算法 算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单 ...
- KNN算法python实现
1 KNN 算法 knn,k-NearestNeighbor,即寻找与点最近的k个点. 2 KNN numpy实现 效果: k=1 k=2 3 numpy 广播,聚合操作. 这里求距离函数,求某点和集 ...
- KNN算法——python实现
二.Python实现 对于机器学习而已,Python需要额外安装三件宝,分别是Numpy,scipy和Matplotlib.前两者用于数值计算,后者用于画图.安装很简单,直接到各自的官网下载回来安装即 ...
- KNN算法python实现小样例
K近邻算法概述优点:精度高.对异常数据不敏感.无数据输入假定缺点:计算复杂度高.空间复杂度高适用数据范围:数值型和标称型工作原理:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习之KNN算法
1 KNN算法 1.1 KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属 ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- kNN算法基本原理与Python代码实践
kNN是一种常见的监督学习方法.工作机制简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k各训练样本,然后基于这k个“邻居”的信息来进行预测,通常,在分类任务中可使用“投票法”,即选择这k ...
随机推荐
- MYSQL数据类型和where条件
MySQL中常见的数据类型 一.字符型 ① CHAR(N):固定N个字符长度的字符串,如果长度不够自动空格补齐; N的范围 0~255 ② VARCHAR(N): 存储可变长度的字符串,最常用 ③ T ...
- js脚本中try与cache捕获异常处理
<script type="text/javascript"> function add_reason(elm){ try{ var pp=$('.pp').val() ...
- win 10 开机后无法显示桌面
我整理了几种方法,可以试一下 1> win + x 然后运行explorer.exe 2> 1/// shift + ctrl + esc 进入 任务管理器 2/// 点击 ...
- 【LeetCode】160. Intersection of Two Linked Lists
题目: Write a program to find the node at which the intersection of two singly linked lists begins. Fo ...
- 遇到android.os等系统sdk包没有自动导入的情况
采取手动导入,build path,然后add external jar,找到sdk的安装目录,导入android 的jar包即可
- 如何使程序运行在UI线程
context.runOnUiThread(new Runnable() { @Override public void run() { _prop = new Prop(buyType, money ...
- HTML5 进阶系列:文件上传下载
前言 HTML5 中提供的文件API在前端中有着丰富的应用,上传.下载.读取内容等在日常的交互中很常见.而且在各个浏览器的兼容也比较好,包括移动端,除了 IE 只支持 IE10 以上的版本.想要更好地 ...
- mongodb远程连接配置
mongodb远程连接配置如下: 1.修改配置文件mongodb.conf 命令:vim /etc/mongodb.conf 把 bind_ip=127.0.0.1 这一行注释掉或者是修改成 bind ...
- python编程快速上手之第5章实践项目参考答案
#!/usr/bin/env python3.5 # coding:utf-8 # 5.6.1 # 好玩游戏的物品清单 # 给定一个字典,包含物品名称和数量,并打印出数量对应的物品 dict_stuf ...
- PostMessage,模拟键盘输入
for i := 0 to length(tel) do begin //SendMessage(cHwnd,WM_KEYDOWN,Integer(tel[ ...