Java8 Stream代码详解+BenchMark测试
1、基本介绍
1、创建方式
1、Array的Stream创建
1、直接创建
// main
Stream stream = Stream.of("a", "b", "c");
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
// Stream.of()
@SafeVarargs
@SuppressWarnings("varargs") // Creating a stream from an array is safe
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
2、直接使用Arrays.stream工具创建
// main
String [] strArray = new String[] {"a", "b", "c"};
stream = Arrays.stream(strArray);
下面是Arrays.stream的具体实现
// Arrays.stream()
public static <T> Stream<T> stream(T[] array) {
return stream(array, 0, array.length);
}
/**
* Arrays.stream()
* @param startInclusive 起始坐标
* @param endExclusive 最终坐标
*/
public static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) {
return StreamSupport.stream(spliterator(array, startInclusive, endExclusive), false);
}
StreamSupport.stream的实现使用的是ReferencePipeline.Head<>这个方法,注意这个方法,这个方法是Stream流水线解决方案的核心之一
// StreamSupport.stream()
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
注意这里的Spliterator,这个类是Stream实现并行的核心类。这里Array生成的spliterator的特征值是ordered和immutable。(目前没看到关于特征值的相关操作,具体解释可以看源码的注释)
/**
* ReferencePipeline.Head<>()
* 默认生成一个ordered、immutable的Spliterator
*/
public static <T> Spliterator<T> spliterator(T[] array, int startInclusive, int endExclusive) {
return Spliterators.spliterator(array, startInclusive, endExclusive,
Spliterator.ORDERED | Spliterator.IMMUTABLE);
}
2、Collection的Stream创建
// main
List<Integer> integers = new ArrayList<>();
integers.stream();
Collection的Stream的创建使用的是Collection.stream方法
// Collection.stream()
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
这个spliterator(),创建的是Spliterator下的特增值为sized、subSized的Spliterator
// Collection.spliterator()
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
// Spliterators.spliterator()
public static <T> Spliterator<T> spliterator(Collection<? extends T> c,
int characteristics) {
return new IteratorSpliterator<>(Objects.requireNonNull(c),
characteristics);
}
/**
* IteratorSpliterator<>()
* 默认生成一个sized、subSized的Spliterator
*/
public IteratorSpliterator(Collection<? extends T> collection, int characteristics) {
this.collection = collection;
this.it = null;
this.characteristics = (characteristics & Spliterator.CONCURRENT) == 0
? characteristics | Spliterator.SIZED | Spliterator.SUBSIZED
: characteristics;
}
最后还是将Spliterator放入ReferencePipeline.Head<>方法创建了Stream
// ReferencePipeline.Head<>
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
3、其他创建方式
1、Stream.iterate()
Stream.iterate(1,i->i++)
该方法放入一个seed值作为种子值,使用第二个参数方法生成一个无限大小的Stream,特征值与Array的Stream特征值相同。
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {
Objects.requireNonNull(f);
final Iterator<T> iterator = new Iterator<T>() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
}
2、Stream.generate()
Stream.generate(Math::random)
该方法没有放入种子值,放入的是一个Supplier,该类就是java1.8以后加入的函数式接口,该接口只有一个方法就是get()方法,用于提供生成Stream需要的每一个的数据,最后生成长度最大为9223372036854775807L(2的63次方-1)的Stream。
public static<T> Stream<T> generate(Supplier<T> s) {
Objects.requireNonNull(s);
return StreamSupport.stream(
new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
}
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
2、中间操作(intermediate operation)
每一个流能有多个中间操作,中间操作的作用就是将原始的流转化为需要的流,并且为惰性操作,关于惰性操作后面会有具体介绍。并且中间操作可分为有状态和无状态两种,两种不同的操作在构成Stream流水线时会使用不同的创建方式和操作。
1、有状态操作(statefulOp)
1、Stream<T> distinct();// 除去流种重复的元素
2、Stream<T> limit(long maxSize);// 只取前几个元素
3、Stream<T> skip(long n);// 跳过前几个元素
4、Stream<T> sorted();// 根据自然排序对流排序
5、Stream<T> sorted(Comparator<? super T> comparator);// 根据自己实现的排序对流排序
2、无状态操作(statelessOp)
1、Stream<T> filter(Predicate<? super T> predicate);// 根据过滤规则过滤流种的元素
2、<R> Stream<R> map(Function<? super T, ? extends R> mapper);// 将每一个元素映射成另一个元素
3、<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);// 和上一个map映射不同的是,扁平映射会将流中的最基础的元素映射出来
4、Stream<T> peek(Consumer<? super T> action);// 每一个元素都要做一下这个action
5、IntStream mapToInt(ToIntFunction<? super T> mapper);// 映射为IntStream
6、LongStream mapToLong(ToLongFunction<? super T> mapper);// 映射为LongStream
7、DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);// 映射为DoubleStream
2、结束操作(terminal operation)
每个流只能有一个结束操作,结束操作会将和之前的中间操作一同起作用,在使用了结束操作后该流便被消费掉了,不能再次使用。由于流可以是无限大的,所以也会有短路操作,当无限大的流使用了短路操作并且满足了短路条件时便会直接结束。
1、非短路操作
1、void forEach(Consumer<? super T> action);// 每一个元素都要做一下这个aciton
2、void forEachOrdered(Consumer<? super T> action);// 确保并行时保持顺序执行这个action
3、Object[] toArray();// 转化成Object数组
4、<A> A[] toArray(IntFunction<A[]> generator);// 转化成自己定义的数组
5、T reduce(T identity, BinaryOperator<T> accumulator);// 汇聚,有起始值,操作
6、Optional<T> reduce(BinaryOperator<T> accumulator);// 汇聚,无起始值,返回的是Optional对象
7、<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> comb iner);// 汇聚,有起始值,操作,合并
8、<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner);// 可变汇聚,自己实现汇聚,容器、操作、合并操作
9、<R, A> R collect(Collector<? super T, A, R> collector);// 可变汇聚,Collectors有封装工具
10、Optional<T> min(Comparator<? super T> comparator);// 封装了reduce,使用自己的比较器找到最小的
11、Optional<T> max(Comparator<? super T> comparator);// 封装了reduce,使用自己的比较器找到最大的
12、long count();// 封装了reduce,把每个数变成1再求和
2、短路操作(short-circuiting)
1、boolean anyMatch(Predicate<? super T> predicate);// 有一个符合判断
2、boolean noneMatch(Predicate<? super T> predicate);// 没有一个符合判断
3、Optional<T> findFirst();// 有序的,找到第一个
4、Optional<T> findAny();// 不要求有序的,找到一个
5、boolean (Predicate<? super T> predicate);// 全部符合判断
2、Stream流水线解决方案
1、ReferencePipeLine
Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的PipelineHelper来代表Stage,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。跟Stream相关类和接口的继承关系图示。
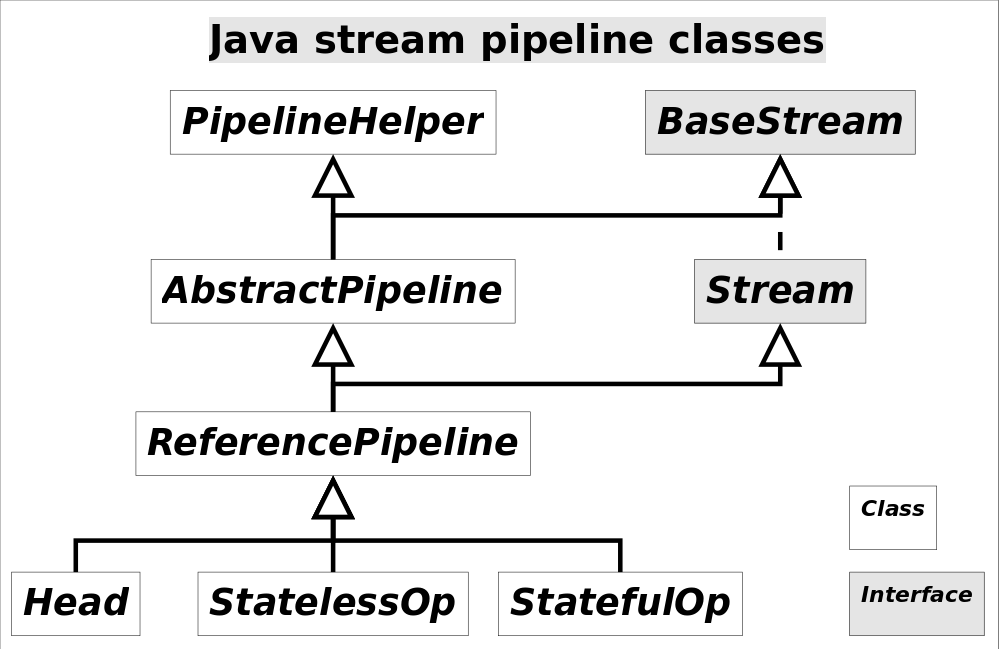
下面是源码,Head表示Source stage,例如Collection.stream(),这里面没有对数据的操作,StatelessOp和StatefuleOp分别对应无状态和有状态的中间操作
/**
* Source stage of a ReferencePipeline.
*
* @param <E_IN> type of elements in the upstream source
* @param <E_OUT> type of elements in produced by this stage
* @since 1.8
*/
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT>
@Override
final Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink) {
throw new UnsupportedOperationException();
}
/**
* Base class for a stateless intermediate stage of a Stream.
*
* @param <E_IN> type of elements in the upstream source
* @param <E_OUT> type of elements in produced by this stage
* @since 1.8
*/
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT>
/**
* Base class for a stateful intermediate stage of a Stream.
*
* @param <E_IN> type of elements in the upstream source
* @param <E_OUT> type of elements in produced by this stage
* @since 1.8
*/
abstract static class StatefulOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT>
通过之前就可以看到的ReferencePipeline.Head<>生成第一个Source stage,紧接着调用一系列的中间操作,不断产生新的Stream。这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作。这就是Stream记录操作的方式。
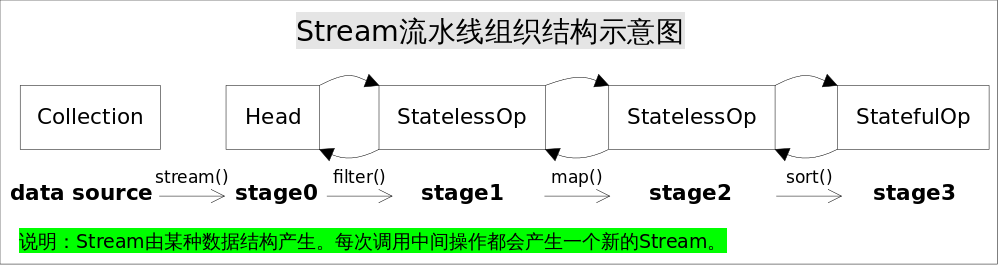
2、Sink
上面讲到的是Stream流水线如何流水操作计算,但是如何组合就要看Sink这个接口了,该接口包含以下方法
| 方法名 | 作用 |
|---|---|
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
通过以上方法,各个Stage之间的调用就实现了,每个Stage将自己的操作封装到Sink中,然后只需要访问下一个Stage的accept方法即可。
下面分别举无状态中间操作和有状态中间操作对这几个方法的实现。
首先是map的实现
// Stream.map()
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override/*opWripSink()方法返回由回调函数包装而成Sink*/
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));// 将数据处理并且交给下游
}
};
}
};
}
sorted的实现
/**
* Stream.sort()
* {@link Sink} for implementing sort on reference streams.
*/
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
// 创建一个存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
public void end() {
list.sort(comparator);// 只有元素全部接收之后才能开始排序
downstream.begin(list.size());
if (!cancellationWasRequested) {// 下游Sink不包含短路操作
list.forEach(downstream::accept);// 将处理结果传递给流水线下游的Sink
}
else {// 下游Sink包含短路操作
for (T t : list) {// 每次都调用cancellationRequested()询问是否可以结束处理。
if (downstream.cancellationRequested()) break;
downstream.accept(t);// 将处理结果传递给流水线下游的Sink
}
}
downstream.end();
list = null;
}
@Override
public void accept(T t) {
list.add(t);// 使用当前Sink包装动作处理t,只是简单的将元素添加到中间列表当中
}
}
上述代码完美的展现了Sink的四个接口方法是如何协同工作的:
1、首先begin()方法告诉Sink参与排序的元素个数,方便确定中间结果容器的的大小;
2、之后通过accept()方法将元素添加到中间结果当中,最终执行时调用者会不断调用该方法,直到遍历所有元素;
3、最后end()方法告诉Sink所有元素遍历完毕,启动排序步骤,排序完成后将结果传递给下游的Sink;
4、如果下游的Sink是短路操作,将结果传递给下游时不断询问下游cancellationRequested()是否可以结束处理。
3、整合与执行
Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。那么整个操作的启动动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
结束操作会创建一个包装了自己操作的Sink,这也是流水线中最后一个Sink,这个Sink只需要处理数据而不需要将结果传递给下游的Sink(因为没有下游)。对于Sink的[处理->转发]模型,结束操作的Sink就是调用链的出口。
Stream设置了一个Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法来得到Sink,该方法的作用是返回一个新的包含了当前Stage代表的操作以及能够将结果传递给downstream的Sink对象。使用opWrapSink()将当前操作与下游Sink(上文中的downstream参数)结合成新Sink。
从流水线的最后一个Stage开始,不断调用上一个Stage的opWrapSink()方法直到最开始(不包括source stage,因为source stage代表数据源,不包含操作),就可以得到一个代表了流水线上所有操作的Sink,用代码表示就是这样:
// AbstractPipeline.wrapSink()
// 从下游向上游不断包装Sink。如果最初传入的sink代表结束操作,
// 函数返回时就可以得到一个代表了流水线上所有操作的Sink。
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
...
for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
流水线上从开始到结束的所有的操作都被包装到了一个Sink里,执行这个Sink就相当于执行整个流水线,执行Sink的代码如下:
// AbstractPipeline.copyInto(), 对spliterator代表的数据执行wrappedSink代表的操作。
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
...
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());// 通知开始遍历
spliterator.forEachRemaining(wrappedSink);// 迭代
wrappedSink.end();// 通知遍历结束
}
...
}
上述代码首先调用wrappedSink.begin()方法告诉Sink数据即将到来,然后调用spliterator.forEachRemaining()方法对数据进行迭代,最后调用wrappedSink.end()方法通知Sink数据处理结束。
3、Stream并行实现原理
1、执行结束操作的默认实现,以findFirst为例
@Override
public final Optional<P_OUT> findFirst() {
return evaluate(FindOps.makeRef(true));
}
并行的实现在AbstractPipeline的evaluate中的evaluateParallel中
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}

@Override
public <P_IN> O evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new FindTask<>(this, helper, spliterator).invoke();
}
private static final class FindTask<P_IN, P_OUT, O>
extends AbstractShortCircuitTask<P_IN, P_OUT, O, FindTask<P_IN, P_OUT, O>> {
private final FindOp<P_OUT, O> op;
FindTask(FindOp<P_OUT, O> op,
PipelineHelper<P_OUT> helper,
Spliterator<P_IN> spliterator) {
super(helper, spliterator);
this.op = op;
}
这里一FindOps的实现为例,这四个操作都是创建一个Task的示例,然后执行invoke方法。这些Task的继承关系如图:

这里可以看出Stream的并行实现都继承了jdk7中的ForkJoin并行框架的ForkJoinTask。
下面是AbstractShortCircuitTask的并行计算方法
@Override
public void compute() {
Spliterator<P_IN> rs = spliterator, ls;
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
AtomicReference<R> sr = sharedResult;
R result;
while ((result = sr.get()) == null) {
if (task.taskCanceled()) {
result = task.getEmptyResult();
break;
}
if (sizeEstimate <= sizeThreshold || (ls = rs.trySplit()) == null) {
result = task.doLeaf();
break;
}
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
task.setLocalResult(result);
task.tryComplete();
}
这里面的主要逻辑是
1、通过estimateSize方法预估工作量总数
2、通过getTargetSize(sizeEstimate)获得最后能把工作量分成多少分,具体如下图,获得当前可用核数减1,然后乘以4,再用预估工作量总数除以该数得到目标工作量
protected final long getTargetSize(long sizeEstimate) {
long s;
return ((s = targetSize) != 0 ? s :
(targetSize = suggestTargetSize(sizeEstimate)));
}
public static long suggestTargetSize(long sizeEstimate) {
long est = sizeEstimate / LEAF_TARGET;
return est > 0L ? est : 1L;
}
static final int LEAF_TARGET = ForkJoinPool.getCommonPoolParallelism() << 2;
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
this.config = (parallelism & SMASK) | mode;
int par = common.config & SMASK; // report 1 even if threads disabled
commonParallelism = par > 0 ? par : 1;
3、在将工作全部fork开之前不断循环将当前任务分为左右子任务
4、退出循环后尝试结束,调用子类实现的doLeaf方法,完成最小计算单元的计算任务,然后设置到当前任务的localResult中
5、再使用tryComplete方法进行最终任务的扫尾工作,如果该任务pending 值不等于0,则原子的减1,如果已经等于0,说明任务都已经完成,则调用onCompletion 回调,如果该任务是叶子任务,则直接销毁中间数据结束;如果是中间节点会将左右子节点的结果进行合并
6、检查如果这个任务已经没有父级任务了,则将该任务置为正常结束,如果还有则尝试递归的去调用父级节点的onCompletion回调,逐级进行任务的合并
/**
* If the pending count is nonzero, decrements the count;
* otherwise invokes {@link #onCompletion(CountedCompleter)}
* and then similarly tries to complete this task's completer,
* if one exists, else marks this task as complete.
*/
public final void tryComplete() {
CountedCompleter<?> a = this, s = a;
for (int c;;) {
if ((c = a.pending) == 0) {
a.onCompletion(s);
if ((a = (s = a).completer) == null) {
s.quietlyComplete();
return;
}
}
else if (U.compareAndSwapInt(a, PENDING, c, c - 1))
return;
}
}
总结:最后可以看出Stream并行的实现本质上就是在ForkJoin上进行了一层封装,将Stream不断分解成更小的Spliterator进行计算。
2、自己控制线程数
ForkJoinPool pool = new ForkJoinPool(2);
Long result = pool.submit(() -> LongStream.range(1, 10)
.parallel()
.map(x -> x + 1)
.filter(x -> x < 5)
.reduce((x,y) -> x+y)
.getAsLong()
).get();
System.out.println(result);
4、测试,Benchmark
1、JAVA版本
java version "1.8.0_131"
2、机器的配置
处理器:1.4GHz Intel Core i5
内存:8GB 1600 MHz DDR3
3、Benchmark配置
2 个JVM、5 次预热迭代和 5 次测量迭代来测试平均时间
4、检验的方法:
普通for循环
public int forMaxInteger() {
int max = Integer.MIN_VALUE;
for (int i = 0; i < size; i++) {
max = Math.max(max, integers.get(i));
}
return max;
}
简写for循环(forEach)
public int forMaxSimpleInteger() {
int max = Integer.MIN_VALUE;
for (Integer n : integers) {
max = Math.max(max, n);
}
return max;
}
iterator循环
public int iteratorMaxInteger() {
int max = Integer.MIN_VALUE;
for (Iterator<Integer> it = integers.iterator(); it.hasNext(); ) {
max = Math.max(max, it.next());
}
return max;
}
forEach+Lambda
public int forEachLambdaMaxInteger() {
final Wrapper wrapper = new Wrapper();
wrapper.inner = Integer.MIN_VALUE;
integers.forEach(i -> helper(i, wrapper));
return wrapper.inner.intValue();
}
public static class Wrapper {
public Integer inner;
}
private int helper(int i, Wrapper wrapper) {
wrapper.inner = Math.max(i, wrapper.inner);
return wrapper.inner;
}
stream
public int streamMaxInteger() {
OptionalInt max = integers.stream().mapToInt(i->i.intValue()).max();
return max.getAsInt();
}
parallelStream
public int parallelStreamMaxInteger() {
OptionalInt max = integers.parallelStream().mapToInt(i->i.intValue()).max();
return max.getAsInt();
}
5、测试结果
1、找到最大的数
1、10万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 0.703 | ± 0.024 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 0.148 | ± 0.003 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 0.135 | ± 0.005 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 0.150 | ± 0.003 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 0.186 | ± 0.002 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 0.353 | ± 0.006 | ms/op |
2、100万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 8.870 | ± 0.094 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 1.870 | ± 0.036 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 1.979 | ± 0.034 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 1.890 | ± 0.065 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 1.895 | ± 0.297 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 3.738 | ± 0.087 | ms/op |
3、1000万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 84.733 | ± 1.989 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 20.063 | ± 0.559 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 21.301 | ± 0.712 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 19.838 | ± 0.585 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 15.481 | ± 0.677 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 37.521 | ± 0.689 | ms/op |
2、累加
1、10万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 0.840 | ± 0.275 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 0.139 | ± 0.012 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 0.177 | ± 0.017 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 0.172 | ± 0.012 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 0.126 | ± 0.080 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 0.715 | ± 0.008 | ms/op |
2、100万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 11.053 | ± 1.540 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 1.882 | ± 0.194 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 1.860 | ± 0.038 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 1.892 | ± 0.039 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 2.407 | ± 1.767 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 2.868 | ± 3.522 | ms/op |
3、1000万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark.forEachLambdaMaxInteger | avgt | 10 | 91.385 | ± 14.993 | ms/op |
| StreamBenchmark.forMaxInteger | avgt | 10 | 13.175 | ± 0.188 | ms/op |
| StreamBenchmark.forMaxSimpleInteger | avgt | 10 | 16.285 | ± 0.466 | ms/op |
| StreamBenchmark.iteratorMaxInteger | avgt | 10 | 15.999 | ± 0.244 | ms/op |
| StreamBenchmark.parallelStreamMaxInteger | avgt | 10 | 29.746 | ± 0.251 | ms/op |
| StreamBenchmark.streamMaxInteger | avgt | 10 | 10.196 | ± 0.194 | ms/op |
3、模拟数据处理
1、10万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark3.forEachLambdaTrans | avgt | 10 | 3.100 | ± 0.169 | ms/op |
| StreamBenchmark3.forTrans | avgt | 10 | 2.863 | ± 0.204 | ms/op |
| StreamBenchmark3.forTransSimple | avgt | 10 | 2.667 | ± 0.126 | ms/op |
| StreamBenchmark3.iteratorTrans | avgt | 10 | 2.648 | ± 0.140 | ms/op |
| StreamBenchmark3.parallelStreamTrans | avgt | 10 | 2.118 | ± 0.058 | ms/op |
| StreamBenchmark3.streamTrans | avgt | 10 | 2.896 | ± 0.049 | ms/op |
2、100万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark3.forEachLambdaTrans | avgt | 10 | 37.726 | ± 7.249 | ms/op |
| StreamBenchmark3.forTrans | avgt | 10 | 31.871 | ± 1.802 | ms/op |
| StreamBenchmark3.forTransSimple | avgt | 10 | 30.901 | ± 1.921 | ms/op |
| StreamBenchmark3.iteratorTrans | avgt | 10 | 31.023 | ± 0.876 | ms/op |
| StreamBenchmark3.parallelStreamTrans | avgt | 10 | 25.768 | ± 0.985 | ms/op |
| StreamBenchmark3.streamTrans | avgt | 10 | 31.347 | ± 1.519 | ms/op |
3、1000万数据
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| StreamBenchmark3.forEachLambdaTrans | avgt | 10 | 3171.935 | ± 195.461 | ms/op |
| StreamBenchmark3.forTrans | avgt | 10 | 3088.757 | ± 373.870 | ms/op |
| StreamBenchmark3.forTransSimple | avgt | 10 | 3073.300 | ± 224.154 | ms/op |
| StreamBenchmark3.iteratorTrans | avgt | 10 | 3083.537 | ± 223.975 | ms/op |
| StreamBenchmark3.parallelStreamTrans | avgt | 10 | 3347.938 | ± 485.051 | ms/op |
| StreamBenchmark3.streamTrans | avgt | 10 | 3203.518 | ± 357.881 | ms/op |
4、影响并行流的主要五个因素
1、数据大小
输入数据的大小会影响并行化处理,当只有足够大、每个数据处理管道花费的时间足够多时,并行化才有意义
2、源数据结构
一般都是基于集合进行并行化
3、装箱
处理基本类型比处理装箱类型要快
4、核的数量
只有在多核的机器上使用才有意义,并且是运行时能够使用的多核
5、单元处理开销
原先处理耗时较长,使用并行化才有意义
5、资料:
1、http://ifeve.com/stream
2、http://lvheyang.com/?p=87
3、http://www.cnblogs.com/CarpenterLee/p/6637118.html
转载请标明出处:http://www.cnblogs.com/MoEee/p/6490573.html
Java8 Stream代码详解+BenchMark测试的更多相关文章
- 【转】Java8 Stream 流详解
当我第一次阅读 Java8 中的 Stream API 时,说实话,我非常困惑,因为它的名字听起来与 Java I0 框架中的 InputStream 和 OutputStream 非常类似.但是 ...
- TextCNN 代码详解(附测试数据集以及GitHub 地址)
前言:本篇是TextCNN系列的第三篇,分享TextCNN的优化经验 前两篇可见: 文本分类算法TextCNN原理详解(一) 一.textCNN 整体框架 1. 模型架构 图一:textCNN 模型结 ...
- Java8 Stream语法详解 2
1. Stream初体验 我们先来看看Java里面是怎么定义Stream的: A sequence of elements supporting sequential and parallel agg ...
- Java8 Stream用法详解
1.概述 Stream 的原理:将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上处理,包括过滤筛选.去重.排序.聚合等.元素流在管道中经过中间操作的处理,最后由最终操作得到前面处理的结 ...
- Java8的Stream语法详解(转载)
1. Stream初体验 我们先来看看Java里面是怎么定义Stream的: A sequence of elements supporting sequential and parallel agg ...
- Java8初体验(二)Stream语法详解(转)
本文转自http://ifeve.com/stream/ Java8初体验(二)Stream语法详解 感谢同事[天锦]的投稿.投稿请联系 tengfei@ifeve.com上篇文章Java8初体验(一 ...
- Java8初体验(二)Stream语法详解---符合人的思维模式,数据源--》stream-->干什么事(具体怎么做,就交给Stream)--》聚合
Function.identity()是什么? // 将Stream转换成容器或Map Stream<String> stream = Stream.of("I", & ...
- Java中String的intern方法,javap&cfr.jar反编译,javap反编译后二进制指令代码详解,Java8常量池的位置
一个例子 public class TestString{ public static void main(String[] args){ String a = "a"; Stri ...
- Java 8 Stream API详解--转
原文地址:http://blog.csdn.net/chszs/article/details/47038607 Java 8 Stream API详解 一.Stream API介绍 Java8引入了 ...
随机推荐
- python中的map、filter、reduce函数
三个函数比较类似,都是应用于序列的内置函数.常见的序列包括list.tuple.str. 1.map函数 map函数会根据提供的函数对指定序列做映射. map函数的定义: map(function ...
- 磁盘配额quota
磁盘配额 1 启用磁盘配额 首先创建新的分区 /dev/sd5,并创建文件系统. [root@local ~]# mkfs.ext4 /dev/sda5 由于xfs 不磁盘配额能成功,这里使用ext4 ...
- Dubbo源码分析系列---服务的发布
摘要: 通过解析配置文件,将xml定义的Bean解析并实例化,(涉及重要的类:ServiceBean.RegistryConfig[注册中心配置].ProtocolConfig[协议配置].Appli ...
- Layered Windows窗口的半透明效果
介绍: Layered Windows是windows窗口中的一类,提供类似半透明的效果(阿尔法混合).半透明效果是字面上有能看出来的,但实际上根据MSND,该类型的窗口还能更好的支持非矩形的窗口,使 ...
- 【论文:麦克风阵列增强】Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
作者:桂. 时间:2017-06-06 16:10:47 链接:http://www.cnblogs.com/xingshansi/p/6951494.html 原文链接:http://pan.ba ...
- php 数据连接 基础
1.造连接对象 $db= new MYSQLi("localhost","root","123","test_0306" ...
- javamail 邮件格式再优化(由详情——>改为统计)
前言:之前扩展的ant-jmeter支持邮件附件形式上传以及邮件内容的html文件格式. 如图: 由于邮件的内容格式是详情信息,也就是说直观的显示的是case,但由于case的增加,邮件内容越来越大! ...
- grid表格选择模式
selModel: { // type: 'checkboxmodel', type: 'cellmodel', // mode: 'SIMPLE', mode: 'SINGLE', checkOnl ...
- Thread初探
Thread初探 前言 以前大家写的都是单线程的程序,全是在main函数中调用方法,可以清楚的看到它的效率是特别低的,就像python中使用单线程取爬一个网站,可以说能让你等的吐血,因为数据量实在太大 ...
- 深入理解PHP对象注入
0x00 背景 php对象注入是一个非常常见的漏洞,这个类型的漏洞虽然有些难以利用,但仍旧非常危险,为了理解这个漏洞,请读者具备基础的php知识. 0x01 漏洞案例 如果你觉得这是个渣渣洞,那么请看 ...