使用Flink时遇到的问题(不断更新中)
1.启动不起来
查看JobManager日志:
WARN org.apache.flink.runtime.webmonitor.JobManagerRetriever - Failed to retrieve leader gateway and port.
akka.actor.ActorNotFound: Actor not found for: ActorSelection[Anchor(akka.tcp://flink@t-sha1-flk-01:6123/), Path(/user/jobmanager)]
at akka.actor.ActorSelection$$anonfun$resolveOne$.apply(ActorSelection.scala:)
at akka.actor.ActorSelection$$anonfun$resolveOne$.apply(ActorSelection.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:)
at akka.dispatch.BatchingExecutor$Batch.run(BatchingExecutor.scala:)
at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.unbatchedExecute(Future.scala:)
at akka.dispatch.BatchingExecutor$class.execute(BatchingExecutor.scala:)
at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.execute(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at akka.pattern.PromiseActorRef$$anonfun$.apply$mcV$sp(AskSupport.scala:)
at akka.actor.Scheduler$$anon$.run(Scheduler.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:)
at scala.concurrent.BatchingExecutor$class.execute(BatchingExecutor.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:)
at akka.actor.LightArrayRevolverScheduler$TaskHolder.executeTask(Scheduler.scala:)
at akka.actor.LightArrayRevolverScheduler$$anon$.executeBucket$(Scheduler.scala:)
at akka.actor.LightArrayRevolverScheduler$$anon$.nextTick(Scheduler.scala:)
at akka.actor.LightArrayRevolverScheduler$$anon$.run(Scheduler.scala:)
at java.lang.Thread.run(Thread.java:)
解决方案:/etc/hosts中配置的主机名都是小写,但是在Flink配置文件(flink-config.yaml、masters、slaves)中配置的都是大写的hostname,将flink配置文件中的hostname都改为小写或者IP地址
2.运行一段时间退出
AsynchronousException{java.lang.Exception: Could not materialize checkpoint for operator Compute By Event Time (/).}
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.lang.Exception: Could not materialize checkpoint for operator Compute By Event Time (/).
... more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size= , maxSize= . Consider using a different state backend, like the File System State backend.
at java.util.concurrent.FutureTask.report(FutureTask.java:)
at java.util.concurrent.FutureTask.get(FutureTask.java:)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:)
... more
Suppressed: java.lang.Exception: Could not properly cancel managed keyed state future.
at org.apache.flink.streaming.api.operators.OperatorSnapshotResult.cancel(OperatorSnapshotResult.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.cleanup(StreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:)
... more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size= , maxSize= . Consider using a different state backend, like the File System State backend.
at java.util.concurrent.FutureTask.report(FutureTask.java:)
at java.util.concurrent.FutureTask.get(FutureTask.java:)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:)
at org.apache.flink.runtime.state.StateUtil.discardStateFuture(StateUtil.java:)
at org.apache.flink.streaming.api.operators.OperatorSnapshotResult.cancel(OperatorSnapshotResult.java:)
... more
Caused by: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size= , maxSize= . Consider using a different state backend, like the File System State backend.
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory.checkSize(MemCheckpointStreamFactory.java:)
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory$MemoryCheckpointOutputStream.closeAndGetBytes(MemCheckpointStreamFactory.java:)
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory$MemoryCheckpointOutputStream.closeAndGetHandle(MemCheckpointStreamFactory.java:)
at org.apache.flink.runtime.checkpoint.AbstractAsyncSnapshotIOCallable.closeStreamAndGetStateHandle(AbstractAsyncSnapshotIOCallable.java:)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend$.performOperation(HeapKeyedStateBackend.java:)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend$.performOperation(HeapKeyedStateBackend.java:)
at org.apache.flink.runtime.io.async.AbstractAsyncIOCallable.call(AbstractAsyncIOCallable.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.snapshot(HeapKeyedStateBackend.java:)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask.checkpointState(StreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.notifyCheckpoint(BarrierBuffer.java:)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.processBarrier(BarrierBuffer.java:)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.getNextNonBlocked(BarrierBuffer.java:)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:)
... more
[CIRCULAR REFERENCE:java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size= , maxSize= . Consider using a different state backend, like the File System State backend.]
解决方案:
状态存储,默认是在内存中,改为存储到HDFS中:
state.backend.fs.checkpointdir: hdfs://t-sha1-flk-01:9000/flink-checkpoints
3.长时间运行后,多次重启
AsynchronousException{java.lang.Exception: Could not materialize checkpoint 1488 for operator Compute By Event Time -> (MonitorData, MonitorDataMapping, MonitorSamplingData) (6/6).}
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:948)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.Exception: Could not materialize checkpoint 1488 for operator Compute By Event Time -> (MonitorData, MonitorDataMapping, MonitorSamplingData) (6/6).
... 6 more
Caused by: java.util.concurrent.ExecutionException: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /flink-checkpoints/8c274785f1ab027e6146a59364be645f/chk-1488/2c612f30-c57d-4ede-9025-9554ca11fd12 could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1628)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3121)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3045)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:725)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:493)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2213)
查看hdfs日志,
WARN org.apache.hadoop.hdfs.protocol.BlockStoragePolicy:
Failed to place enough replicas: expected size is 2 but only 0 storage types can be selected
(replication=3, selected=[], unavailable=[DISK], removed=[DISK, DISK],
policy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]})
搭建的Flink使用HDFS作为CheckPoint的存储,当flink重启时,原来的checkpoint没有用了,我就手动给删了,不知道和这个有没有关系,为了不继续报异常,便重启了Flink、HDFS,重启后不再有异常信息了。
但是查看HDFS日志时,发现如下警告(不合规范的URI格式):
WARN org.apache.hadoop.hdfs.server.common.Util:
Path /mnt/hadoop/dfs/name should be specified as a URI in configuration files.
Please update hdfs configuration
原来是配置错了,hdfs-site.xml中的
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/hadoop/dfs/name</value>
</property>
应该改为:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mnt/hadoop/dfs/name</value>
</property>
至此问题解决,根上的问题应该是hdfs-site.xml配置的不对导致的。
4.Unable to load native-hadoop library for your platform
Flink启动时,有时会有如下警告信息:
WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
参考资料1:http://blog.csdn.net/jack85986370/article/details/51902871
解决方案:编辑/etc/profile文件,增加
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
未能解决该问题
5.hadoop checknative -a
WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version
INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /usr/hadoop-2.7./lib/native/libhadoop.so.1.0.
zlib: true /lib64/libz.so.
snappy: false
lz4: true revision:
bzip2: false
openssl: false Cannot load libcrypto.so (libcrypto.so: cannot open shared object file: No such file or directory)!
INFO util.ExitUtil: Exiting with status
参考资料:http://blog.csdn.net/zhangzhaokun/article/details/50951238
解决方案
cd /usr/lib64/
ln -s libcrypto.so.1.0.1e libcrypto.so
6.TaskManager退出
Flink运行一段时间后,出现TaskManager退出情况,通过jvisualvm抓取TaskManager的Dump,使用MAT进行分析,结果如下:
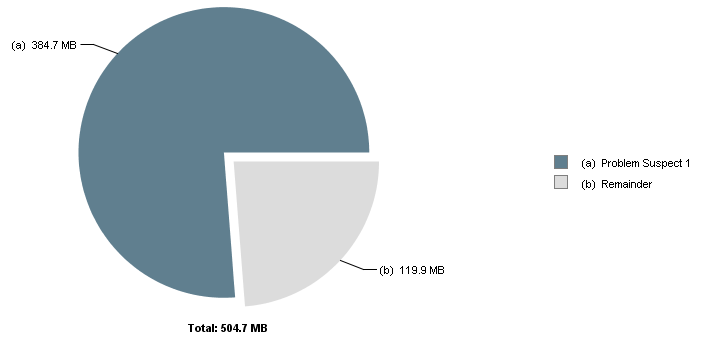
One instance of "org.apache.flink.runtime.io.network.buffer.NetworkBufferPool"
loaded by "sun.misc.Launcher$AppClassLoader @ 0x6c01de310" occupies 403,429,704 (76.24%) bytes.
The memory is accumulated in one instance of "java.lang.Object[]" loaded by "<system class loader>". Keywords
sun.misc.Launcher$AppClassLoader @ 0x6c01de310
java.lang.Object[]
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool
发现是网络缓冲池不足,查到一篇文章:
https://issues.apache.org/jira/browse/FLINK-4536
和我遇到的情况差不多,也是使用了InfluxDB作为Sink,最后在Close里进行关闭,问题解决。
另外,在$FLINK_HOME/conf/flink-conf.yaml中,也有关于TaskManager网络栈的配置,暂时未调整
# The number of buffers for the network stack.
#
# taskmanager.network.numberOfBuffers:
7.Kafka partition leader切换导致Flink重启
现象:
7.1 Flink重启,查看日志,显示:
java.lang.Exception: Failed to send data to Kafka: This server is not the leader for that topic-partition.
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.checkErroneous(FlinkKafkaProducerBase.java:)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.invoke(FlinkKafkaProducerBase.java:)
at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
7.2 查看Kafka的Controller日志,显示:
INFO [SessionExpirationListener on ], ZK expired; shut down all controller components and try to re-elect (kafka.controller.KafkaController$SessionExpirationListener)
7.3 设置retries参数
参考:http://colabug.com/122248.html 以及 Kafka官方文档(http://kafka.apache.org/082/documentation.html#producerconfigs),关于producer参数设置
设置了retries参数,可以在Kafka的Partition发生leader切换时,Flink不重启,而是做3次尝试:
kafkaProducerConfig
{
"bootstrap.servers": "192.169.2.20:9093,192.169.2.21:9093,192.169.2.22:9093"
"retries":
}
使用Flink时遇到的问题(不断更新中)的更多相关文章
- 使用Flink时从Kafka中读取Array[Byte]类型的Schema
使用Flink时,如果从Kafka中读取输入流,默认提供的是String类型的Schema: val myConsumer = new FlinkKafkaConsumer08[String](&qu ...
- [转帖]升级 Ubuntu,解决登录时提示有软件包可以更新的问题
升级 Ubuntu,解决登录时提示有软件包可以更新的问题 2017年12月05日 11:58:17 阅读数:2953更多 个人分类: ubuntu Connecting to ... Connecti ...
- [转] 检查更新时出错:无法启动更新检查(错误代码为 4: 0x80070005 — system level)
Google浏览器Chrome更新到时候提示错误:检查更新时出错:无法启动更新检查(错误代码为 4: 0x80070005 -- system level),很有可能是Chrome更新服务被禁用了,我 ...
- 安装SQL数据库时遇到问题。需要更新以前的visual studio 2010实例
安装SQL数据库时遇到问题.需要更新以前的visual studio 2010实例此计算机安装了需要service pack 1更新的visual 2010,必须安装此更新才能成功安装选择的SQL s ...
- 史上最全的spark面试题——持续更新中
史上最全的spark面试题——持续更新中 2018年09月09日 16:34:10 为了九亿少女的期待 阅读数 13696更多 分类专栏: Spark 面试题 版权声明:本文为博主原创文章,遵循C ...
- 微软承诺将在今年的 Visual C++ 更新中加入 Clang 编译器
微软最近发布将在2015年11月 Visual C++ 更新中加入 Clang 编译器 ,Clang 开源编译器以相比GCC更快的编译速度和更优的错误提示著称. Clang关于C,C++,及Objec ...
- Android开发面试经——4.常见Android进阶笔试题(更新中...)
Android开发(29) 版权声明:本文为寻梦-finddreams原创文章,请关注:http://blog.csdn.net/finddreams 关注finddreams博客:http:/ ...
- 《WCF技术剖析》博文系列汇总[持续更新中]
原文:<WCF技术剖析>博文系列汇总[持续更新中] 近半年以来,一直忙于我的第一本WCF专著<WCF技术剖析(卷1)>的写作,一直无暇管理自己的Blog.在<WCF技术剖 ...
- HBase常见问题答疑解惑【持续更新中】
HBase常见问题答疑解惑[持续更新中] 本文对HBase开发及使用过程中遇到过的常见问题进行梳理总结,希望能解答新加入的HBaser们的一些疑惑. 1. HTable线程安全吗? HTable不是线 ...
- 充电-ios(未完更新中...
[reference]http://www.cocoachina.com/ios/20160323/15770.html OC的理解与特性 OC作为一门面向对象的语言,自然具有面向对象的语言特性:封装 ...
随机推荐
- python进阶-------进程线程(二)
Python中的进程线程(二) 一.python中的"锁" 1.GIL锁(全局解释锁) 含义: Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(G ...
- pt-stalk
1.名词解释 Collect forensic data about MySQL when problems occur 在问题发生的时候采集现场数据 pt-stalk waits for a tri ...
- Liunx vi编辑器一些指令
最近几天学习了Liunx vi编辑器 的使用,感觉还比较容易.总结的一点心得: vi分为3个模式,命令模式,尾行模式,编辑模式. 1. 命令模式 与 编辑模式切换 a:光标向后移动一位进入编辑模式 i ...
- phpcms实现全站搜索
如果制作的静态页面中有搜索功能,那么使用phpcms进行替换怎么替换呢?会不会越到很多的麻烦呢?接下来进行phpcms替换静态页面中的搜索功能. 第一步:搜索页面的form表单提交书写,form表单怎 ...
- PHP date()函数格式与用法汇总
在页面的最前页加上 date_default_timezone_set("PRC"); /*把时间调到北京时间,php5默认为格林威治标准时间*/ date () a: & ...
- MS08_067漏洞学习研究
p197 MS08-067漏洞渗透攻击 按照书上的设置做,exploit得到错误信息: Exploit failed [unreachable]: Rex::ConnectionRefused The ...
- webstorm激活破解码+++使用技巧
Webstorm激活破解码 2017-06-15更新 之前都是使用2017.2.27的方法,版本是2017.1.1,还没提示过期,但是根据评论说这个链接已经失效了,评论也给出了个新地址:http:// ...
- 微信小程序与Java后台通信
一.写在前面 最近接触了小程序的开发,后端选择Java,因为小程序的代码运行在腾讯的服务器上,而我们自己编写的Java代码运行在我们自己部署的服务器上,所以一开始不是很明白小程序如何与后台进行通信的, ...
- 基于iframe的移动端嵌套
需求描述 上上周接到了新的项目,移动端需要做一个底部有五个导航,点击不同的导航页面主体显示不同的页面,其中两个页面是自己做,而另外三个页面是引用另外三个网址,其中两个网址为内部项目,另外一个为外部(涉 ...
- 在windows下vs使用pthread
首先从http://sourceware.org/pthreads-win32/下载pthread 的windows安装包,我下的是pthread-w32-2-9-1-release.zip,其他版本 ...