JVM内存模型及垃圾回收的研究总结
Java内存模型
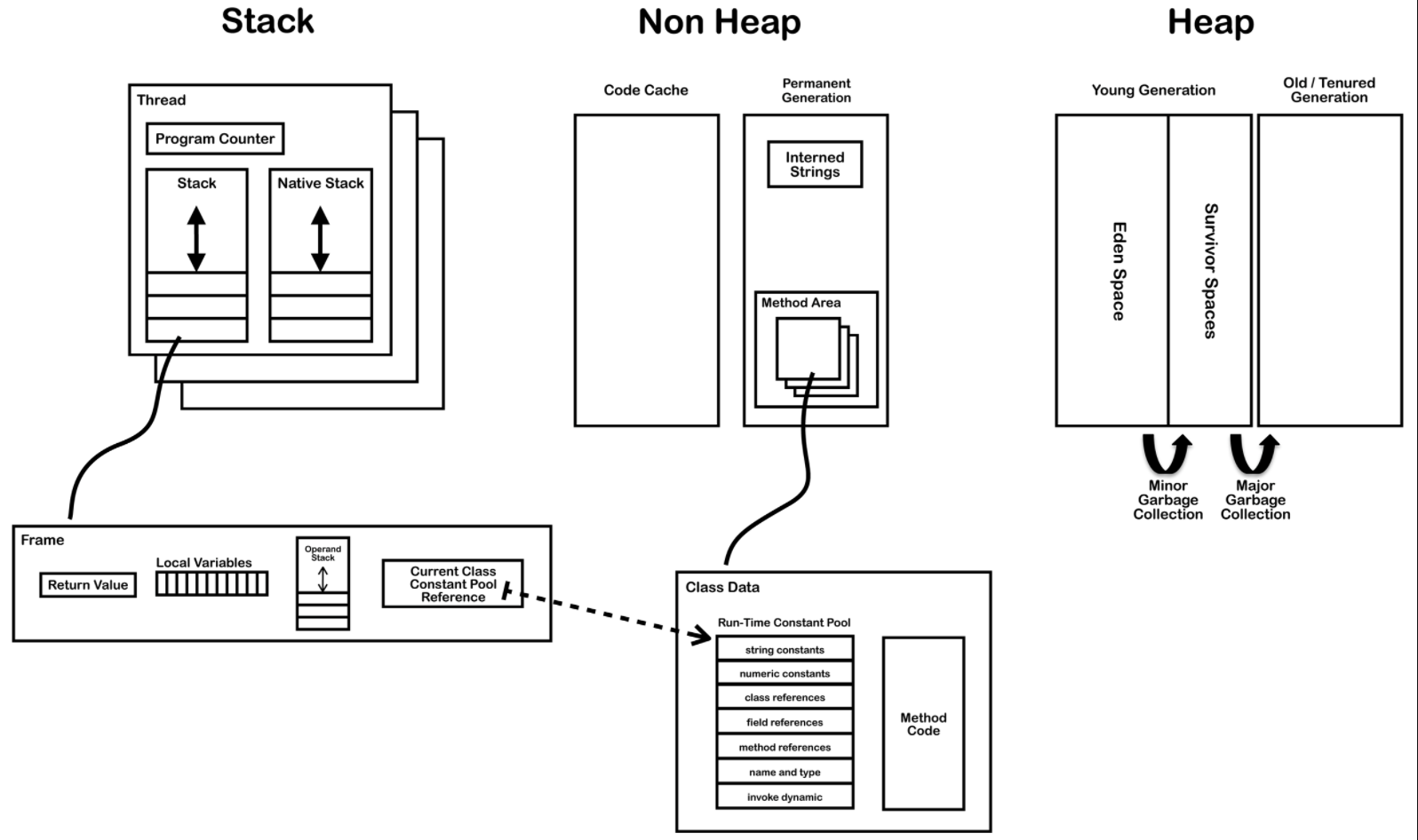
总的来说就分为两个区域,堆内存(Heap)和非堆内存(No-Heap),非堆内存又称为永久代(Permanent),“永久”其实有点儿容易使人误导,好像这部分内容不需要回收。但在永久区中的某些数据也是需要回收的!
在新的JDK8中,这部分的名称已经不叫Permanent了,改成更好理解的Metaspace了。这部分是用来存储JVM工作的相关数据的,比如Load下来的class定义、静态变量、用于调度的方法和线程栈。

分为两个区其实是为了更便于理解,No-Heap区只是非Heap的意思,其中的Stack、Method Area其实是和Heap同级的。
在GC日志中,你会发现PSPermGen也在其中:
[GC-- [PSYoungGen: 569856K->569856K(617472K)] 773089K->928306K(976896K), 0.3285123 secs] [Times: user=0.66 sys=0.08, real=0.33 secs]
[Full GC [PSYoungGen: 569856K->0K(617472K)] [ParOldGen: 358450K->359349K(499712K)] 928306K->359349K(1117184K) [PSPermGen: 64652K->64650K(131072K)], 1.4693823 secs] [Times: user=4.09 sys=0.02, real=1.47 secs]
[Full GC [PSYoungGen: 569856K->0K(617472K)] [ParOldGen: 359349K->488638K(672768K)] 929205K->488638K(1290240K) [PSPermGen: 65041K->65041K(131072K)], 2.4092196 secs] [Times: user=6.75 sys=0.11, real=2.41 secs]
意思是No-Heap(永久代)也需要垃圾回收!
因为在永久代中还存储着ClassLoader、Class的元信息(Metadata)、指向Heap区域对象的指针以及字符串池(Internal String)。这些数据其实也需要垃圾回收。
这样看来,把内存区域划分为年轻代(Young Gen)、老年代(Old Gen)和永久代(Permanent Gen)其实是有道理的,虽然老年代的数据不会提升到永久代中。但是这三个区域的数据都是需要垃圾回收的。
Heap(堆内存)
堆内存是垃圾回收器工作的地方,堆内存又分为Eden和两个大小一样的Survivor区,即From和To。
最开始的对象都会存储在Eden中(如果有些大对象无法存入到年轻代,则会直接存入老年代),然后经过Minor GC之后会被提升到Survivor区,然后再提升到老年代。

Stack(栈内存)
Thread Stack 用来存放栈信息,每个线程栈信息里各自有自己的方法栈(包括本地方法栈),在方法栈的每一帧里存储着方法调用的相关信息,比如参数值、局部变量、返回值等。
Program Counter:记录着当前语句执行到哪儿了。
下图中,其实Stack可以归并到No-Heap中。
垃圾回关注的指标
吞吐量
定义:用户代码执行时间 / ( 用户代码执行时间 + 垃圾回收时间)
越高越好,越高表示执行垃圾回收时间越少。
暂停时间
回收时可能需要暂停用户线程,暂停时间越短越好。
执行频率
单位时间垃圾回收执行的次数。
堆内存大小
比如G1回收器就要去比较大的Heap内存。
敏感度(Promptness)
对象变成垃圾到被回收的时间,时间越短表示回收器越敏感。
垃圾回收类型
串行搜集器(Serial)
年轻代(Young Gen)回收
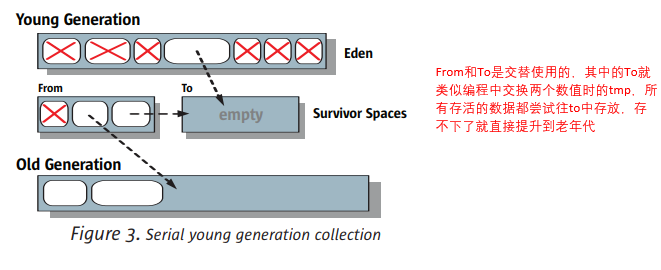
老年代(Old Gen)回收
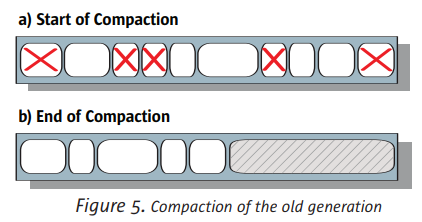
来年代的回收很简单,步骤是“标记-清除-压缩”:
串行回收器的使用场景
一般引用于不要求“低暂停”的client模式。这里参考server和client的区别。j2se5的client模式下默认使用串行回收器进行垃圾回收。
使用串行回收器的参数:-XX:+UseSerialGC
并行回收器(Paraller)
并行回收器可以利用多个CPU进行并行的垃圾回收。(在多个CPU场景下,使用Serial回收器时,其实只有一个CPU在工作,其他CPU相当于闲置状态)
并行回收器在年轻地啊和老年代进行垃圾回收的操作是一样的,都是标记、转移、压缩,只是它启用了多个CPU并发执行。串行和并行都需要stop-the-world。
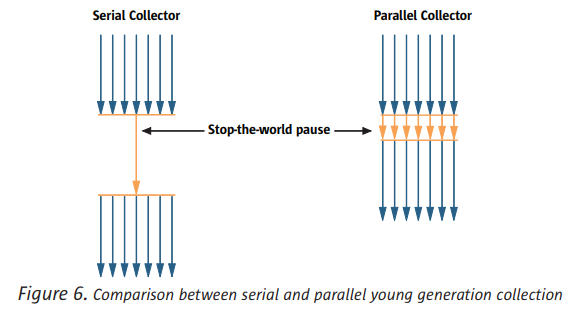
并行回收器的使用场景
应用于多CPU场景下,但是没有太大的暂停时间要求,因为还是有可能会发生长时间的老年代垃圾回收。
适用于批处理、账单、财务、科学计算等场景。
j2se5的server模式下默认使用该回收器。
使用并行回收器的参数:-XX:+UseParallelGC
ParNew
这是一个加强版的Parallel回收器。它可以与下面提到的CMS回收器进行配合。
并行压缩回收器(Parallel Compacting)
年轻代使用并行回收器一样的算法(多CPU并行回收)。(stop-the-world)
-XX:+UseParallelOldGC.
对于老年代,回收过程分为三个阶段
并行标记(Marking)
标记出每个区域的活动数据。标记动作其实是和用户线程一起跑的。
计算总结(Summary)
计算各个区域的稠密程度,得出移动数据的方案。(稀疏的往稠密位置移动,压缩速度肯定比相反方向要快)
压缩(Compaction)
把数据移动到一端,保证另外一端空白。
并行压缩回收器的使用场景
多CPU,它相对于并行回收器感觉没有什么区别(谁知道吗???),因为在官方文档中是这样说的:

使用该回收器的参数:-XX:-UseParallelOldGC
并发标记清理回收器(Concurrent Mark-Sweep (CMS))
低延迟的回收器。
一般而言,年轻代的回收不会有太大的暂停。而老年代的回收不会经常执行,所以老年代的回收暂停时间长一点儿也没事。CMS的回收步骤如下:
年轻代还是使用并发回收器(Parallel)。
对于老年代:
初始标记(init mark):单线程stop-the-world执行,短暂停,确定出直接和程序关联的活动对象集合。
并发标记(concurrent marking):根据上一步标记出来的集合,并发找出与集合中元素关联的其他活动对象。这一步的执行是和用户线程并发执行的。
重新标记(remark):由于用户线程也在运行,所以上一步标记出来的对象还有可能又参数了垃圾,所以这里再次stop-the-world,重新找出活动数据。这一步对现场并发执行。很容易理解,这里的stop-the-world也是非常短的。
清理(sweep):根据上一步标记结果,清理内存。
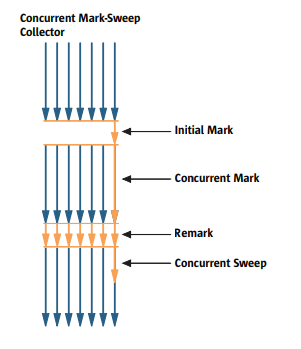
从CMS的执行步骤可以看出,它的核心思想其实就是把事情分成多个步骤来做,不要一次把事情做完,且尽量和用户线程一起执行,从而实现对用户线程的低延迟。
CMS回收器使用场景
任何需要低延迟的应用。甚至在单CPU上都运行良好。
使用CMS回收器参数:-XX:+UseConcMarkSweepGC
G1(Gargage First)回收器
G1回收器是用于server模式下,多处理器、大内存的环境。其目标是高吞吐量、高可用性。在JDK7 update4以后的版本中都支持。长期计划中G1是用来代替CMS回收器的。
G1不像其他回收器那样,把内存明确地划分为三个固定大小的区域。而是把heap看成一个整体。
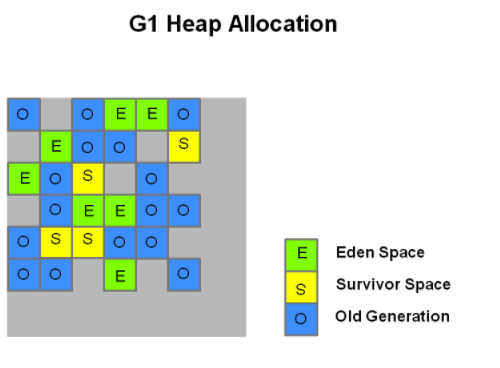
更多细节详见参考连接。
垃圾收集器参数总结
收集器设置:
-XX:+UseSerialGC:年轻串行(Serial),老年串行(Serial Old)
-XX:+UseParNewGC:年轻并行(ParNew),老年串行(Serial Old)
-XX:+UseConcMarkSweepGC:年轻并行(ParNew),老年串行(CMS),备份(Serial Old)
-XX:+UseParallelGC:年轻并行吞吐(Parallel Scavenge),老年串行(Serial Old)
-XX:+UseParalledlOldGC:年轻并行吞吐(Parallel Scavenge),老年并行吞吐(Parallel Old)
收集器参数:
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
个人学习总结,难免有误,欢迎指正讨论!
参考:
Java堆内存:http://www.blogjava.net/fancydeepin/archive/2013/09/29/jvm_heep.html
Memory Management in the Java HotSpot™ Virtual Machine:http://www.oracle.com/technetwork/java/javase/tech/memorymanagement-whitepaper-1-150020.pdf
JVM内部结构:http://blog.jamesdbloom.com/JVMInternals.html
JVM参数:http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html,http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
官网GC日志介绍:http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html
G1回收器:http://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
JVM内存模型及垃圾回收的研究总结的更多相关文章
- 程序猿的日常——JVM内存模型与垃圾回收
Java开发有个很基础的问题,虽然我们平时接触的不多,但是了解它却成为Java开发的必备基础--这就是JVM.在C++中我们需要手动申请内存然后释放内存,否则就会出现对象已经不再使用内存却仍被占用的情 ...
- JVM内存模型和垃圾回收
Java开发有个很基础的问题,虽然我们平时接触的不多,但是了解它却成为Java开发的必备基础——这就是JVM.在C++中我们需要手动申请内存然后释放内存,否则就会出现对象已经不再使用内存却仍被占用的情 ...
- 【Java_基础】JVM内存模型与垃圾回收机制
1. JVM内存模型 Java虚拟机在程序执行过程会把jvm的内存分为若干个不同的数据区域来管理,这些区域有自己的用途,以及创建和销毁时间. JVM内存模型如下图所示 1.1 程序计数器 程序计数器( ...
- JVM的stack和heap,JVM内存模型,垃圾回收策略,分代收集,增量收集
(转自:http://my.oschina.net/u/436879/blog/85478) 在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认 ...
- JVM内存模型,垃圾回收算法
JVM内存模型总体架构图 程序计数器多线程时,当线程数超过CPU数量或CPU内核数量,线程之间就要根据时间片轮询抢夺CPU时间资源.因此每个线程有要有一个独立的程序计数器,记录下一条要运行的指令.线程 ...
- JVM内存模型以及垃圾回收
JAVA堆的描述如下: 内存由Perm和Heap组成.其中Heap = {Old + NEW = { Eden , from, to } } JVM内存模型中分两大块: NEW Generation: ...
- JVM内存模型及垃圾回收算法
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- JVM内存模型与垃圾回收
内存模型 1,程序计数器(Program Counter Register):程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,可以理解为是当前线程的行号指示器.字节码解 ...
- JVM 内存模型及垃圾回收
java内存模型 根据 JVM 规范,JVM 内存共分为虚拟机栈.堆.方法区.程序计数器.本地方法栈五个部分. 程序计数器:程序计数器是指CPU中的寄存器,它保存的是程序当前执行的指令的地址(也可以说 ...
随机推荐
- 视觉词袋模型(BOVW)
一.介绍 Bag-of-words model (BoW model) 最早出现在神经语言程序学(NLP)和信息检索(IR)领域. 该模型忽略掉文本的语法和语序, 用一组无序的单词(words)来表达 ...
- c语言的,三个工具可以使编译器生成性能更佳的代码。
内联函数声明inline 函数有时可以非常短.短函数的每次调用可以用实现该函数功能的内联代码替代,以提高执行性能.意味着不需要给函数传递或返回一个值,要让编译器采用这种技术,可以把短函数指定为inli ...
- Leetcode题解(十一)
31.Next Permutation 题目 这道题目的意思是给定一个序列,找出其按照字典顺序的下一个顺序,如果给定顺序是字典中的最后一个顺序,其下一个顺序则为字典中的第一个顺序.比如: 1,2,3, ...
- 按键精灵 vbs 获取网页源码 xp系统被拒绝
如下面的代码所示,获取新浪博客某个指定网页的源码 verurl = "http://blog.sina.com.cn/s/blog_9ea1db7b0101o7ch.html?" ...
- JavaScript系列----正则表达式
1.正则表达式 1.1.正则表达式的类型 正则表达式在JavaScript中,提供了一种内置的构造函数--RegExp. 正则表达式有三种匹配模式: g: 表示全局模式,即模式应用于所有的字符串,而非 ...
- Dijkstra算法(Swift版)
原理 我们知道,使用Breadth-first search算法能够找到到达某个目标的最短路径,但这个算法没考虑weight,因此我们再为每个edge添加了权重后,我们就需要使用Dijkstra算法来 ...
- nodejs a和b文件相互引用
//取自于node中文网 http://nodejs.cn/api/modules.html 当循环调用 require() 时,一个模块可能在未完成执行时被返回. 例如以下情况: a.js: con ...
- eclipse搭建maven ssm项目
file --> new --> maven project -->创建个简单的maven项目 会报错,没事 右键 properties 先去掉,然后再勾上 接下来配置maven的相 ...
- flask 之定时任务开发
最近开发我的接口测试平台 ,但是遇到了一个需求,需要开发定时任务,于是百度搜索,找到了这么一个叫 pFlask-APScheduler然后开始了我的第一次的学习,于是乎, 需求是这么的: 1.添加定时 ...
- Java 读取 .properties 配置文件的几种方式
Java 开发中,需要将一些易变的配置参数放置再 XML 配置文件或者 properties 配置文件中.然而 XML 配置文件需要通过 DOM 或 SAX 方式解析,而读取 properties 配 ...