基于POI和DOM4将Excel(2007)文档写进Xml文件
刚进公司的training, 下面是要求:
Requirements
- Write a java program to read system.xlsx
- Use POI API to parse all contents in the excel
- Write all contents to an output file
- The file should in XML format(optional)
- The program can start with a bat command(optional)
Reference
- POI official site -- http://poi.apache.org/ ---下载poi相关的包
- CBX-Builder implementation -- \\triangle\share\git\training\CBX_Builder [develop branch]
package polproject; import java.io.File;
import java.io.FileWriter;
import java.util.ArrayList;
import java.util.List; import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter; public class ExcelToXml { /**
* @param args
*/
public static void main(String[] args) throws Exception { toXml("D:/excel/system.xlsx", "D:/excel/system.xml");
} /**
* excel to xml
*/
public static void toXml(String sourcePath, String targetPath) throws Exception { // 输出格式化
final OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8"); // 指定XML编码
final XMLWriter output = new XMLWriter(new FileWriter(targetPath), format); // 使用DocumentHelper.createDocument方法建立一个文档实例
final Document document = DocumentHelper.createDocument();
Element rootElm = document.getRootElement(); final File file = new File(sourcePath);
final String fileName = file.getName(); // 如果想获得不带点的后缀,变为fileName.lastIndexOf(".")+1
final String prefix = fileName.substring(fileName.lastIndexOf(".")); // 得到后缀名长度
final int prefix_num = prefix.length(); // 得到文件名。去掉了后缀
final String fileOtherName = fileName.substring(0, fileName.length() - prefix_num); if (rootElm == null) {
// 创建根节点
rootElm = document.addElement(fileOtherName);
rootElm.addAttribute("pistion", fileName);
}
final Workbook wb = WorkbookFactory.create(new File(sourcePath));
final int sheetNum = wb.getNumberOfSheets();
for (int i = 0; i < sheetNum; i++) {
final Sheet sheet = wb.getSheetAt(i); // 标记是否接下来的是否为fieldIdLabel
boolean isFieldIdLabel = false;
boolean isFieldValue = false;
int coloumNum = 0;
final List<String> fields = new ArrayList<String>();
final String sheetName = sheet.getSheetName(); // 1#添加一级节点
final Element firstElm = rootElm.addElement("sheet");
firstElm.addAttribute("id",sheetName);
firstElm.addAttribute("position",fileName+ "," +sheetName);
Element secondElm = null;
Element thirdElm = null;
for (final Row row : sheet) {
coloumNum = row.getPhysicalNumberOfCells(); Element fourthElm = null;
boolean isNextRow = true;
for (final Cell cell : row) { final String cellStr = cellValueToString(cell); // 2#添加二级节点
if (cellStr.startsWith("##")) {
final String cellElm = cellStr.substring(2);
secondElm = firstElm.addElement(cellElm);
secondElm.addAttribute("position", fileName + "," + sheetName +"," +String.valueOf(row.getRowNum()+1)); // 3#添加三级节点
} else if (cellStr.startsWith("#begin")) {
thirdElm = secondElm.addElement("elements");
final String[] arrayStr = cellStr.split(":");
if (arrayStr.length == 1) {
thirdElm.addAttribute("id", "default");
isFieldIdLabel = true;
} else {
thirdElm.addAttribute("pistion", arrayStr[1]);
isFieldIdLabel = true;
} // 4#收集添加四级节点
} else if (isFieldIdLabel) {
//如果不为空,则列数-1,并把头部加进fields里
if( !cellStr.isEmpty()){
if (coloumNum != 0) {
fields.add(cellStr);
coloumNum=coloumNum-1;
}
if (coloumNum == 0) {
isFieldIdLabel = false;
isFieldValue = true;
}
}else{//如果为空,则列数就只-1
if (coloumNum != 0) {
coloumNum=coloumNum-1;
}
if (coloumNum == 0) {
isFieldIdLabel = false;
isFieldValue = true;
}
} } else if (cellStr.startsWith("#end")) {
isFieldValue = false;
fields.clear();
// 5#写入filedvalue
} else if (isFieldValue) { if (isNextRow) {
fourthElm = thirdElm.addElement("element");
fourthElm.addAttribute("position", fileName + "," +sheetName +"," +String.valueOf(row.getRowNum()+1));
final int celIndex = cell.getColumnIndex();
Element fifthElm=null;
if(fields.get(celIndex).lastIndexOf("*")>0){
fifthElm = fourthElm.addElement(fields.get(celIndex).substring(0,fields.get(celIndex).indexOf("*")));
}else{
fifthElm = fourthElm.addElement(fields.get(celIndex));
} fifthElm.setText(cellStr);
isNextRow = false;
} else {
final int celIndex = cell.getColumnIndex();
Element fifthElm=null;
if (celIndex < fields.size()) {
if(fields.get(celIndex).lastIndexOf("*")>0){
fifthElm = fourthElm.addElement(fields.get(celIndex).substring(0,fields.get(celIndex).indexOf("*")-1));
}else{
fifthElm = fourthElm.addElement(fields.get(celIndex));
}
fifthElm.setText(cellStr);
}
}
} else {
// System.out.println(coloumNum + " " + isFieldIdLabel);
}
}
}
}
System.out.println("end---------------------");
output.write(document);
output.flush();
output.close();
} /**
* 将单元格的内容全部转换成字符串
*/
private static String cellValueToString(Cell cell) {
String str = "";
switch (cell.getCellType()) {
case Cell.CELL_TYPE_STRING:
str = cell.getRichStringCellValue().getString();
break;
case Cell.CELL_TYPE_NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
str = cell.getDateCellValue().toString();
} else {
str = String.valueOf(cell.getNumericCellValue());
}
break;
case Cell.CELL_TYPE_BOOLEAN:
str = String.valueOf(cell.getBooleanCellValue());
break;
case Cell.CELL_TYPE_FORMULA:
str = cell.getCellFormula();
break;
default:
// System.out.println("can not format cell value :" + cell.getRichStringCellValue());
str = cell.getRichStringCellValue().getString();
break;
}
return str;
}
}
结果图: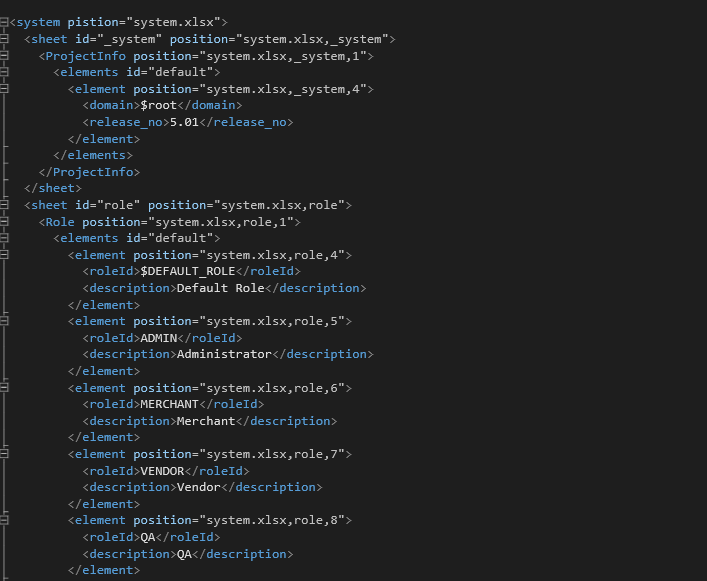
基于POI和DOM4将Excel(2007)文档写进Xml文件的更多相关文章
- Java小知识----POI事件模式读取Excel 2007
一.知识背景 1.读取excel的方法选择问题 java中读excel中的时间,我们通常用POI去解析,在使用new HSSFWorkbook(NEW FileInputStream(excelFil ...
- 使用 Apache FOP 2.3 + docbook-xsl-ns-1.79.1 转换 Docbook 5.1 格式的 XML 文档成 PDF/RTF 文件
使用 Docbook 编写折桂打印平台系统.折桂上传平台系统的产品文档,原因基于如下两点: 第一,文档的不同章节,可使用不同的 .xml 文件,由不同人员分别撰写,图片文件在XML文章中用相对目录方式 ...
- C#生成PDF文档,读取TXT文件内容
using System.IO;using iTextSharp.text;using iTextSharp.text.pdf; //需要在项目里引用ICSharpCode.SharpZipLib.d ...
- 【HTML/XML 10】XML文档中的Schema文件
导读:DTD是对XML文档进行有效性验证的方法之一,事实上,继DTD之后,出现了用来规范和描述XML文档的第二代标准:Schema.Schema是DTD的继承,但是也有其不同的地方,它是真正的以独立的 ...
- UINavigationController 导航控制器 ,根据文档写的一些东西
今天讲了导航控制器UINavigationController 和标签栏视图控制器UITabBarController 先来说一说导航视图控制器 UINavigationController 导航控 ...
- 判断pdf、word文档、图片等文件类型(格式)、大小的简便方法
判断pdf.word文档.图片等文件类型(格式).大小的简便方法 很久没发文了,今天有时间就写一下吧. 关于上传文件,通常我们都需要对其进行判断,限制上传的类型,如果是上传图片,我们甚至会把图片转化成 ...
- WPF:将Office文档、任意类型文件嵌入到EXE可执行文件中
原文:WPF:将Office文档.任意类型文件嵌入到EXE可执行文件中 版权声明:本文为博主原创文章,未经博主允许可以随意转载 https://blog.csdn.net/songqingwei198 ...
- 【XML】利用Dom4j读取XML文档以及写入XML文档
Dom4j简介 dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的.dom4j是一个十分优秀的JavaXML API,具有性能优异.功能强大和极其易使用的特点,它的性能 ...
- java合并多个word 2007 文档 基于docx4j
参考文章:http://dh.swzhinan.com/post/185.html 引入的jar包 <dependency> <groupId>org.docx4j</g ...
随机推荐
- 用JS实现Ajax请求
AJAX核心(XMLHttpRequest) 其实AJAX就是在Javascript中多添加了一个对象:XMLHttpRequest对象.所有的异步交互都是使用XMLHttpServlet对象完成的. ...
- django框架中的中间件
什么是中间件 中间件就是在url进入路由之前进行检测的一个类 也就是说,每一个请求都是先通过中间件中的 process_request 函数,这个函数返回 None 或者 HttpResponse 对 ...
- 51nod 1020 逆序排列 DP
在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序.一个排列中逆序的总数就称为这个排列的逆序数. 如2 4 3 1中,2 1,4 3,4 1,3 1是逆序 ...
- Filebeat轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器.这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据. 一.架构图 此次试验基于前几 ...
- java 之 命令模式(大话设计模式)
命令模式,笔者一直以为当我们开发的过程中基本上很难用到,直到维护阶段或者重构阶段,我们会发现有些撤销命令和追加命令比较频繁时,自然而然就用到命令模式. 先看下类图 大话设计模式-类图 简单说下类图,最 ...
- 倒水问题 (FillUVa 10603) 隐式图
题意:本题的题意是给你三个杯子,第一二个杯子是空的,第三个杯子装满水,要求是量出一定容量d升的水.若是得不到d升的水,那就让某一个杯子里面的水达到d',使得d'尽量接近d升. 解题思路:本题是给出初始 ...
- 《RabbitMQ Tutorial》译文 第 5 章 主题
原文来自 RabbitMQ 英文官网的教程(5.Topics),其示例代码采用了 .NET C# 语言. In the previous tutorial we improved our loggin ...
- java傻瓜简单100%一定看的懂新手安装教程
1.java官网 最新的不是很稳定 http://www.oracle.com/technetwork/java/javase/downloads/index.html 一直点下一步就可以,但别忘 ...
- startup alter.log spfile.ora
SQL> select * from v$version where rownum=1; BANNER --------------------------------------------- ...
- USACO Section 2.1 Healthy Holsteins
/* ID: lucien23 PROG: holstein LANG: C++ */ #include <iostream> #include <fstream> #incl ...