Redis 数据结构与内存管理策略(上)
Redis 数据结构与内存管理策略(上)
标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射
作者:王清培(Plen wang) 沪江Java资深架构师
- Redis 数据类型特点与使用场景
- String、List、Hash、Set、Zset
- 案例:沪江团购系统大促 hot-top 接口 cache 设计
- Redis 内存数据结构与编码
- OBJECT encoding key、DEBUG OBJECT key
- 简单动态字符串(simple dynamic string)
- 链表(linked list)
- 字典(dict)
- 跳表(skip list)
- 整数集合(int set)
- 压缩表(zip list)
- Redis Object 类型与映射
- Redis 内存管理策略
- 键 过期时间、生存时间
- 过期键删除策略
- AOF 、RDB 处理过期键策略
- Redis LRU 算法
- Redis 持久化方式
- AOF (Append-only file)
- RDB (Redis DataBase)
Redis 数据类型特点与使用场景
redis 为我们提供了 5 种数据类型,基本上我们使用频率最高的就是 string ,而对其他四种数据类型使用的频次稍弱于 string 。
一方面是由于 string 使用起来比较简单,可以方便存储复杂大对象,使用场景比较多。还有一个原因就是由于 redis expire time 只能设置在 key 上,像 list、hash、set、zset 属于集合类型,会管理一组 item,我们无法在这些集合的 item 上设置过期时间,所以使用 expire time 来处理集合的 cache 失效会变得稍微复杂些。但是 string 使用 expire time 来管理过期策略会比较简单,因为它包含的项少。这里说的集合是宽泛的类似集合。
导致我们习惯性的使用 string 而忽视其他四种数据类型的另一个深层次原因,大多是由于我们对另外四种数据类型的使用和原理不是太了解。这个时候往往会忽视在特定场景下使用某种数据类型可能会比 string 性能高出很多,比如使用 hash 结构来提高某个实体的某个项的修改等。
这里我们不打算罗列这 5 种数据类型的使用方法,这些资料网上有很多。我们主要讨论这 5 种数据类型的功能特点,这些特点分别适合用于处理哪些现实的业务场景,最重要的是我们如何组合性的使用这 5 种数据类型来解决复杂的 cache 问题。
String、List、Hash、Set、Zset
String
string 是 redis 提供的字符串类型。可以针对 string 类型独立设置 expire time 。通常用来存储长字符串数据,比如,某个对象的 json 字符串。
string 类型我们在使用上最巧妙的是可以动态拼接 key。通常我们可以将一组 id 放在 set 里,然后动态查找 string 还是否存在,如果不存在说明已经过期或者由于数据修改主动 delete 了,需要再做一次 cache 数据 load 。
虽然 set 无法设置 item 的过期时间,但是我们可以将 set item 与 string key 关联来达到相同的效果。
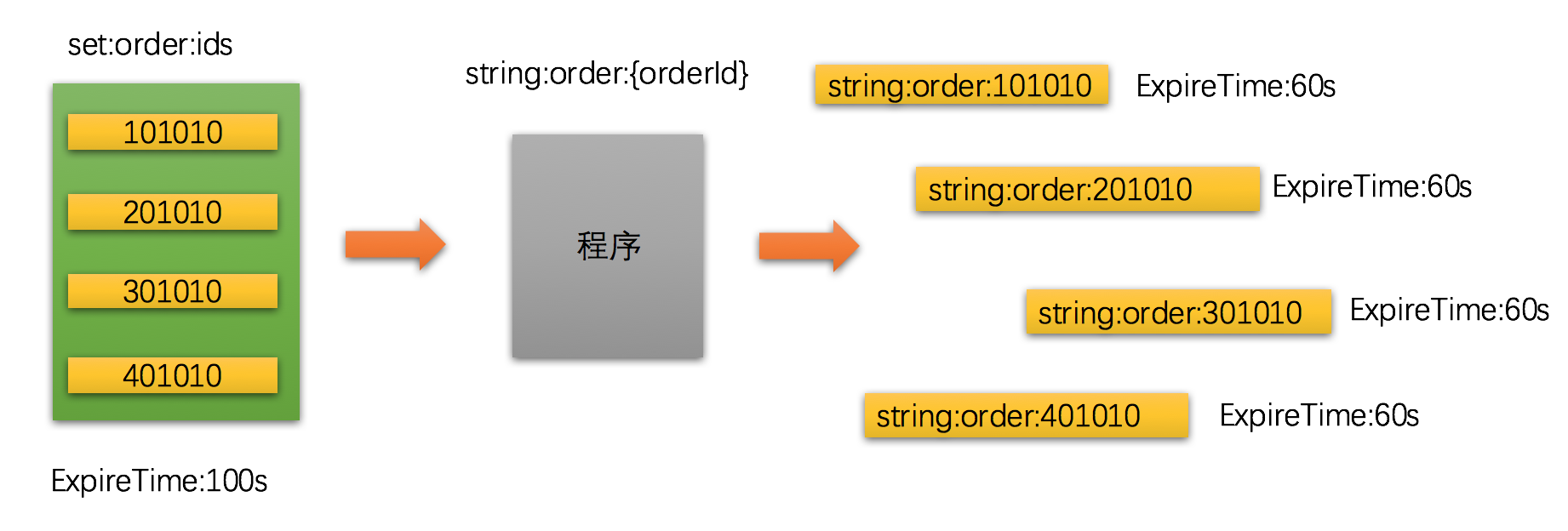
上图中的左边是一个 key 为 set:order:ids 的 set 集合,它可能是一个全量集合,也可能是某个查询条件获取出来的一个集合。
有时候复杂点的场景需要多个 set 集合来支撑计算,在 redis 服务器 里可能会有很多类似这样的集合。
这些集合我们可以称为 功能数据,这些数据是用来辅助 cache 计算的,当进行各种集合运算之后会得出当前查询需要返回的子集,最后我们才会去获取某个订单真正的数据。
这些 string:order:{orderId} 字符串 key 并不一定是为了服务一种场景,而是整个系统最底层的数据,各种场景最后都需要获取这些数据。那些 set 集合可以认为是查询条件数据,用来辅助查询条件的计算。
redis 为我们提供了 TYPE 命令来查看某个 key 的数据类型,如:string 类型:
SET string:order:100 order-100
TYPE string:order:100
string
List
list 在提高 throughput 的场景中非常适用,因为它特有的 LPUSH、RPUSH、LPOP、RPOP 功能可以无缝的支持生产者、消费者架构模式。
这非常适合实现类似 Java Concurrency Fork/Join 框架中的 work-stealing 算法 (工作窃取) 。
java fork/join 框架使用并行来提高性能,但是会带来由于并发 take task 带来的 race condition (竞态条件) 问题,所以采用 work-stealing 算法 来解决由于竞争问题带来的性能损耗。
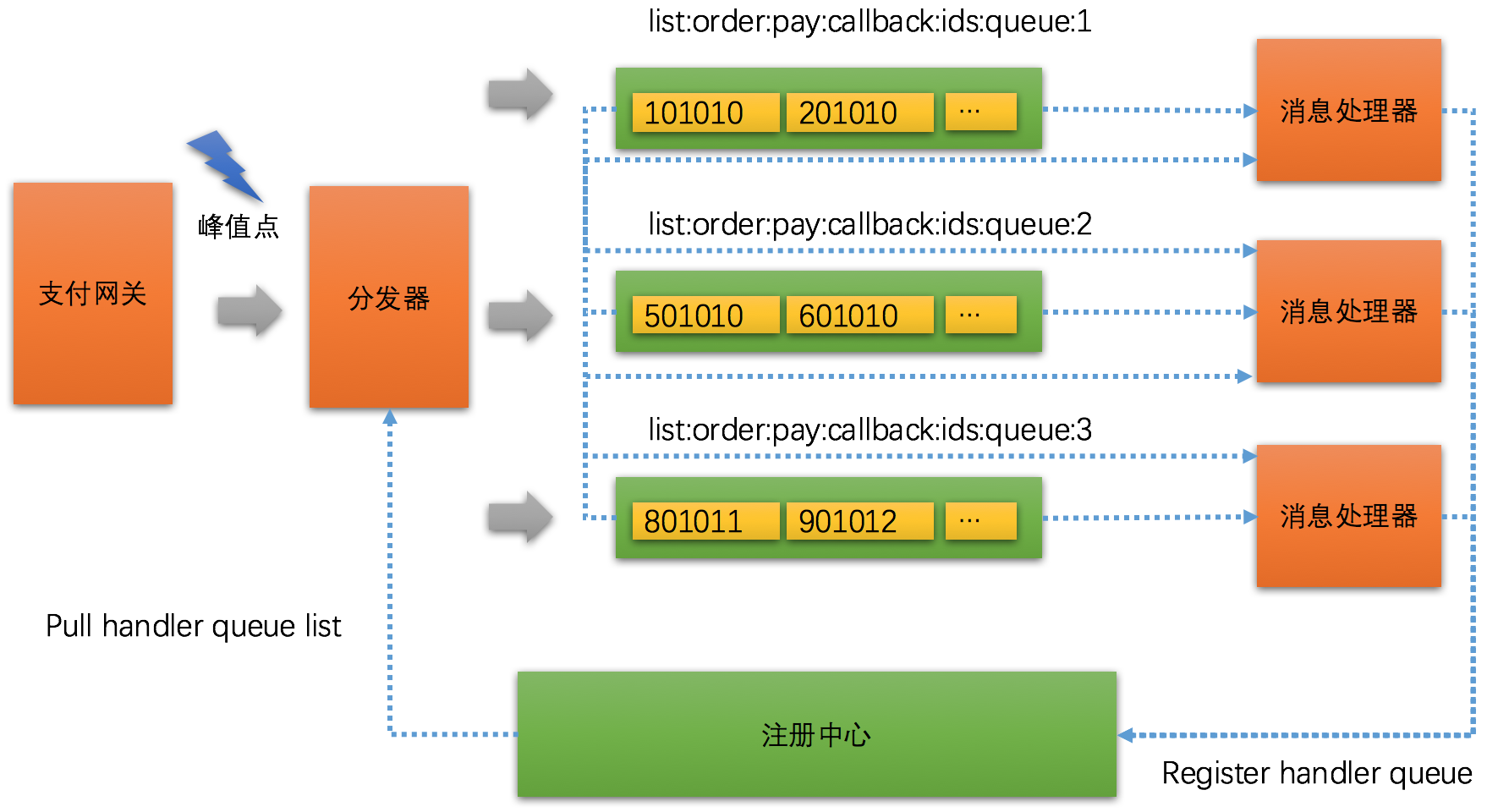
上图中模拟了一个典型的支付 callback 峰值场景。在峰值出现的地方一般我们都会使用加 buffer 的方式来加快请求处理速度,这样才能提高并发处理能力,提高 throughput 。
支付 gateway 收到 callback 之后不做任何处理直接交给 分发器 。分发器 是一个无状态的 cluster ,每个 node 通过向 注册中心 pull handler queue list ,也就是获取下游处理器注册到注册中心里的消息通道。
每一个分发器 node 会维护一个本地 queue list ,然后顺序推送消息到这些 queue list 即可。这里会有点小问题,就是 支付 gateway 调用分发器的时候是如何做 load balance ,如果不是平均负载可能会有某个 queue list 高出其他 queue list 。
而分发器不需要做 soft load balance ,因为哪怕某个 queue list 比其他 queue list 多也无所谓,因为下游 message handler 会根据 work-stealing 算法来窃取其他消费慢的 queue list 。
redis list 的 LPUSH、RPUSH、LPOP、RPOP 特性确实可以在很多场景下提高这种横向扩展计算能力。
Hash
hash 数据类型很明显是基于 hash 算法的,对于项的查找时间复杂度是 O(1) 的,在极端情况下可能出现项 hash 冲突问题,redis 内部是使用链表加 key 判断来解决的。具体 redis 内部的数据结构我们在后面有介绍,这里就不展开了。
hash 数据类型的特点通常可以用来解决带有映射关系,同时又需要对某些项进行更新或者删除等操作。如果不是某个项需要维护,那么一般可以通过使用 string 来解决。
如果有需要对某个字段进行修改,使用 string 很明显是会多出很多开销,需要读取出来反序列化成对象然后操作,然后再序列化写回 redis ,这中间可能还有并发问题。
那我们可以使用 redis hash 提供的实体属性 hash 存储特性,我们可以认为 hash value 是一个 hash table ,实体的每一个属性都是通过 hash 得到属性的最终数据索引。
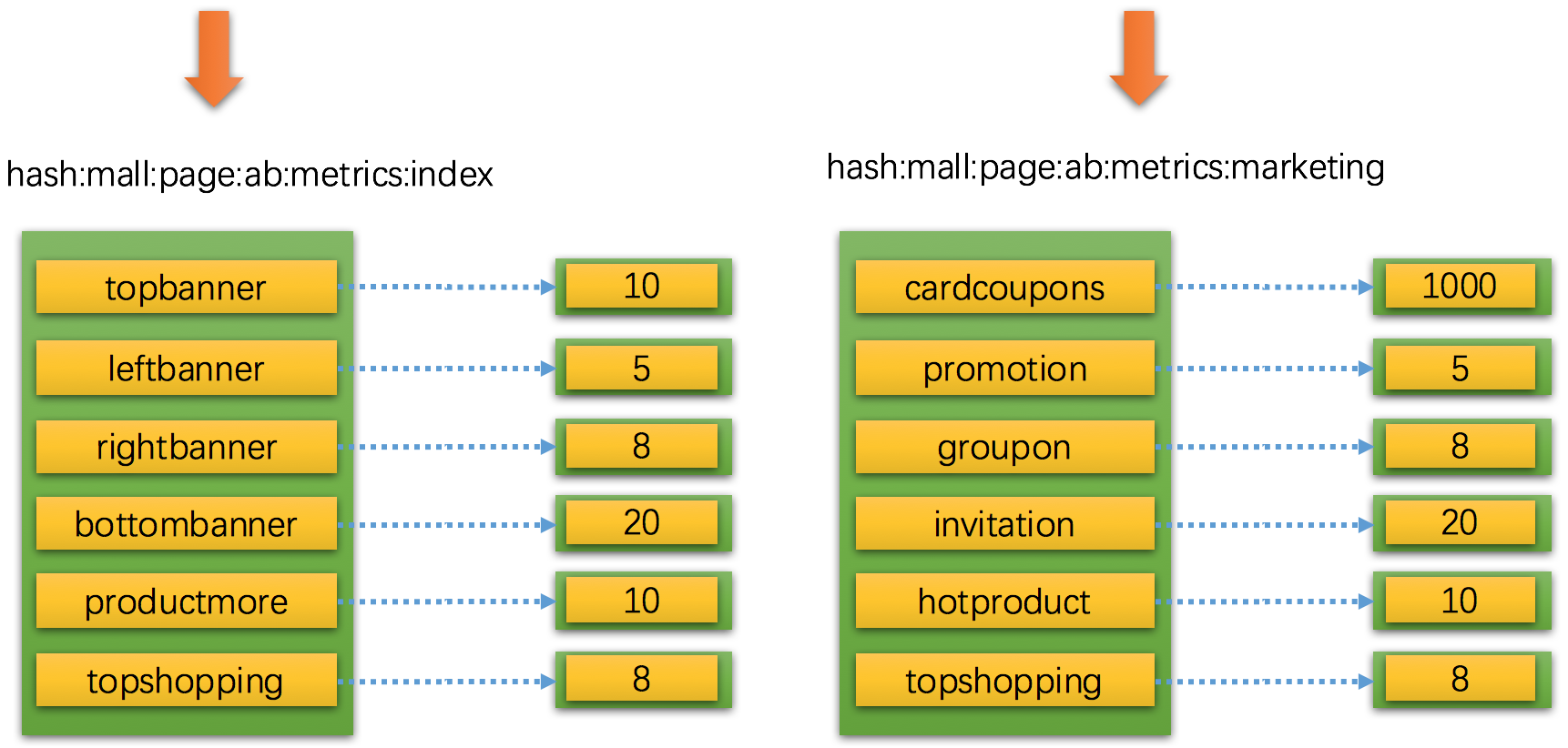
上图使用 hash 数据类型来记录页面的 a/b metrics ,左边的是首页 index 的各个区域的统计,右边是营销 marketing 的各个区域统计。
在程序里我们可以很方便的使用 redis 的 atomic 特性对 hash 某个项进行累加操作。
HMSET hash:mall:page:ab:metrics:index topbanner 10 leftbanner 5 rightbanner 8 bottombanner 20 productmore 10 topshopping 8
OK
HGETALL hash:mall:page:ab:metrics:index
1) "topbanner"
2) "10"
3) "leftbanner"
4) "5"
5) "rightbanner"
6) "8"
7) "bottombanner"
8) "20"
9) "productmore"
10) "10"
11) "topshopping"
12) "8"
HINCRBY hash:mall:page:ab:metrics:index topbanner 1
(integer) 11
使用 redis hash increment 进行原子增加操作。HINCRBY 命令可以原子增加任何给定的整数,也可以通过 HINCRBYFLOAT 来原子增加浮点类型数据。
Set
set 集合数据类型可以支持集合运算,不能存储重复数据。
set 最大的特点就是集合的计算能力,inter 交集、union 并集、diff 差集,这些特点可以用来做高性能的交叉计算或者剔除数据。
set 集合在使用场景上还是比较多和自由的。举个简单的例子,在应用系统中比较常见的就是商品、活动类场景。用一个 set 缓存有效商品集合,再用一个 set 缓存活动商品集合。如果商品出现上下架操作只需要维护有效商品 set ,每次获取活动商品的时候需要过滤下是否有下架商品,如果有就需要从活动商品中剔除。
当然,下架的时候可以直接删除缓存的活动商品,但是活动是从 marketing 系统中 load 出来的,就算我将 cache 里的活动商品删除,当下次再从 marketing 系统中 load 活动商品时候还是会有下架商品。当然这只是举例,一个场景有不同的实现方法。
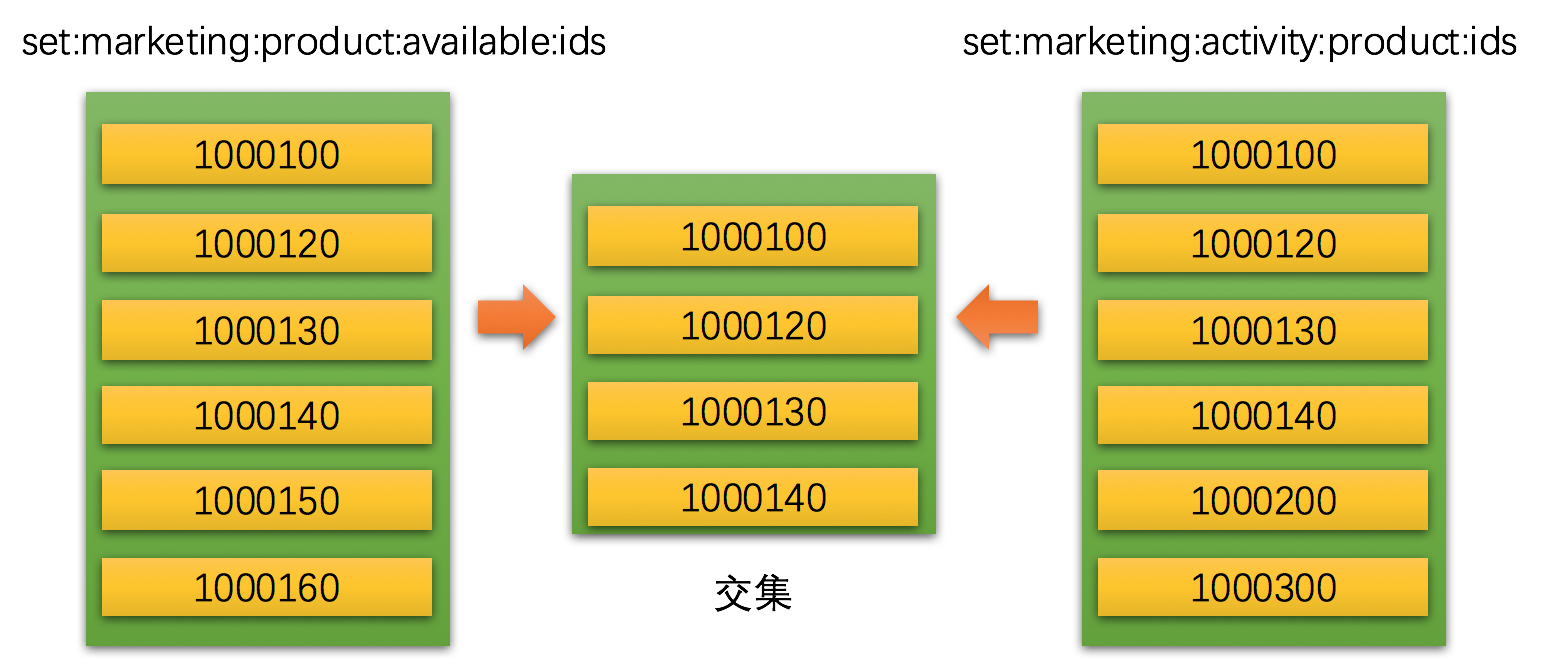
上图中左右两边是两个不同的集合,左边是营销域中的可用商品ids集合,右边是营销域中活动商品ids集合,中间计算出两个集合的交集。
SADD set:marketing:product:available:ids 1000100 1000120 1000130 1000140 1000150 1000160
SMEMBERS set:marketing:product:available:ids
1) "1000100"
2) "1000120"
3) "1000130"
4) "1000140"
5) "1000150"
6) "1000160"
SADD set:marketing:activity:product:ids 1000100 1000120 1000130 1000140 1000200 1000300
SMEMBERS set:marketing:activity:product:ids
1) "1000100"
2) "1000120"
3) "1000130"
4) "1000140"
5) "1000200"
6) "1000300"
SINTER set:marketing:product:available:ids set:marketing:activity:product:ids
1) "1000100"
2) "1000120"
3) "1000130"
4) "1000140"
在一些复杂的场景中,也可以使用 SINTERSTORE 命令将交集计算后的结果存储在一个目标集合中。 这在使用 pipeline 命令管道中特别有用,将 SINTERSTORE 命令包裹在 pipeline 命令串中可以重复使用计算出来的结果集。
由于 redis 是 Signle-Thread 单线程模型 ,基于这个特性我们就可以使用 redis 提供的 pipeline 管道 来提交一连串带有逻辑的命令集合,这些命令在处理期间不会被其他客户端的命令干扰。
Zset
zset 排序集合与 set 集合类似,但是 zset 提供了排序的功能。在介绍 set 集合的时候我们知道 set 集合中的成员是无序的,zset 填补了集合可以排序的空隙。
zset 最强大的功能就是可以根据某个 score 比分值 进行排序,这在很多业务场景中非常急需。比如,在促销活动里根据商品的销售数量来排序商品,在旅游景区里根据流入人数来排序热门景点等。
基本上人们在做任何事情都需要根据某些条件进行排序。
其实 zset 在我们应用系统中能用到地方到处都是,这里我们举一个简单的例子,在团购系统中我们通常需要根据参团人数来排序成团列表,大家都希望参加那些即将成团的团。
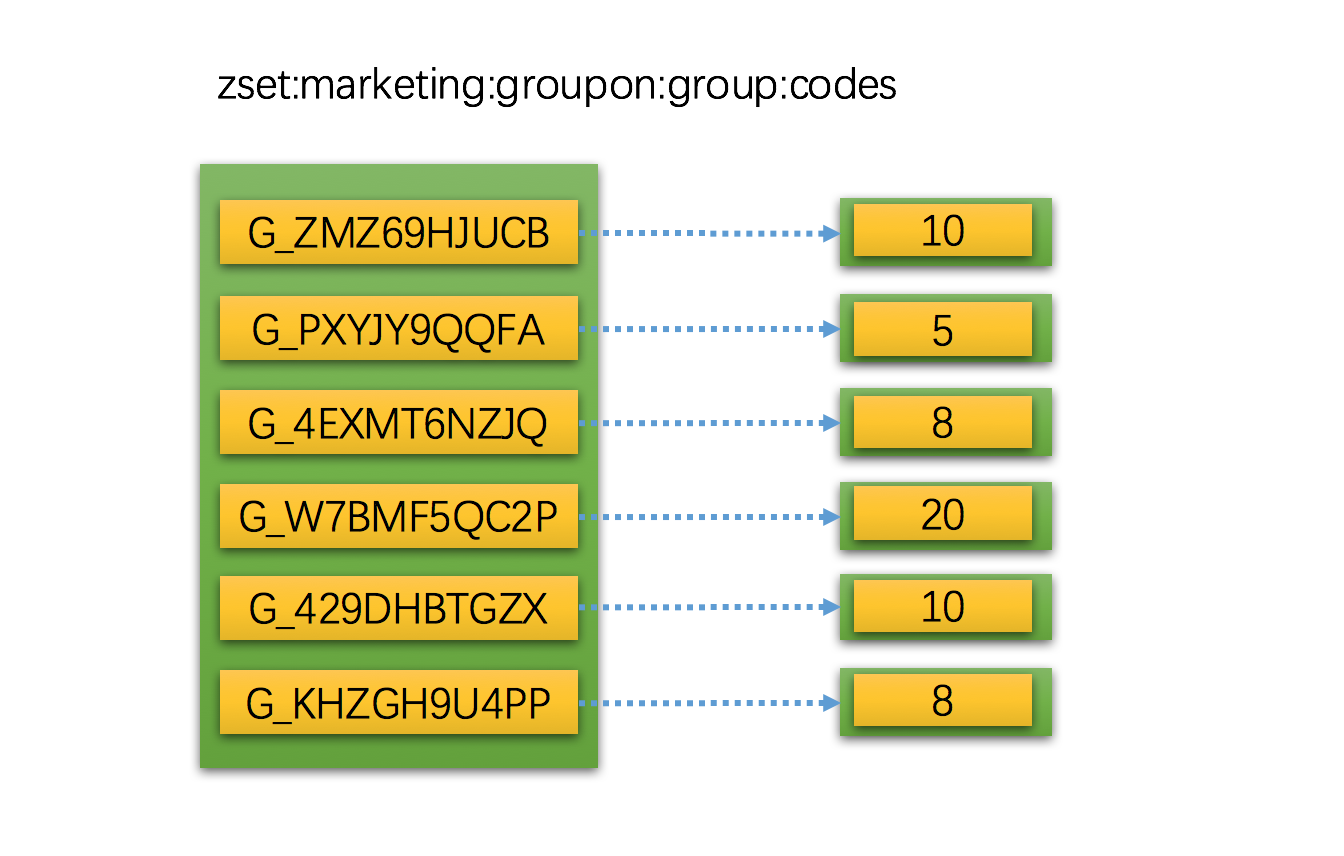
上图是一个根据团购code创建的zset,score 分值 就是参团人数累加和。
ZADD zset:marketing:groupon:group:codes 5 G_PXYJY9QQFA 8 G_4EXMT6NZJQ 20 G_W7BMF5QC2P 10 G_429DHBTGZX 8 G_KHZGH9U4PP
ZREVRANGEBYSCORE zset:marketing:groupon:group:codes 1000 0
1) "G_W7BMF5QC2P"
2) "G_ZMZ69HJUCB"
3) "G_429DHBTGZX"
4) "G_KHZGH9U4PP"
5) "G_4EXMT6NZJQ"
6) "G_PXYJY9QQFA"
ZREVRANGEBYSCORE zset:marketing:groupon:group:codes 1000 0 withscores
1) "G_W7BMF5QC2P"
2) "20"
3) "G_ZMZ69HJUCB"
4) "10"
5) "G_429DHBTGZX"
6) "10"
7) "G_KHZGH9U4PP"
8) "8"
9) "G_4EXMT6NZJQ"
10) "8"
11) "G_PXYJY9QQFA"
12) "5"
zset 本身提供了很多方法用来进行集合的排序,如果需要 score 分值可以使用 withscore 字句带出每一项的分值。
在一些比较特殊的场合可能需要组合排序,可能有多个 zset 分别用来对同一个实体在不同维度的排序,按时间排序、按人数排序等。这个时候就可以组合使用 zset 带来的便捷性,利用 pipeline 再结合多个 zset 最终得出组合排序集合。
案例:沪江团购系统大促 hot-top 接口 cache 设计
我们总结了 redis 提供的 5 种数据类型的各自特点和一般的使用场景。但是我们不仅仅可以分开使用这些数据类型,我们完全可以综合使用这些数据类型来完成复杂的 cache 场景。
下面我们分享一个使用多个 zset 、string 来优化 团购系统 前台接口的例子。由于篇幅和时间限制,这里只介绍跟本次案例相关的信息。
hot-top 接口是指热点、排名接口的意思,表示它的浏览量、并发量比较高,一般大促的时候都会有几个这种性能要求比较高的接口。
我们先来分析一个查询接口所包含的常规信息。
首先一个查询接口肯定是有 query condition 查询条件 ,然后是 sort 排序信息_ 、最后是 page 分页信息_ 。这是一般接口所承担的基本职责,当然,特殊场景下还需要支持 master/slave replication 时关于数据 session 一致性 的要求,需要提供跟踪标记来回 master 查询数据,这里就不展开了。
我们可以抽象出这几个维度的信息:
query condition
查询条件,companyid=100,sellerid=1010101 诸如此类。
sort
排序信息,一般是默认一个列排序,但是在复杂的场景下会有可能让接口使用者定制排序字段,比如一些租户信息列。
page
分页信息,简单理解就是数据记录排完序之后的第几行到第几行。
由于这里我们纯粹用 redis 来提高 cache 能力,不涉及到有关于任何搜索的能力,所以这里忽略其他复杂查询的情况。其实我们在复杂的地方使用了 elastcsearch 来提高搜索能力。
上述我们分析总结出了一个查询接口的基本信息,这里还有一个有关于高并发接口的设计原则就是将 hot-top 接口和一般 search 接口分离开,因为只有分而治之才能分别根据特点选用不同的技术。如果我们不分职责将所有的查询场景封装在一个接口里,那么在后面优化接口性能的时候基本就很麻烦了,有些场景是无法或者很难用 cache 来解决的,因为接口里耦合了各种场景逻辑,就算勉强能实现性能也不会高。
前面做这些铺垫是为了能在介绍案例的时候达成一个基本的共识。现在我们来看下这个团购系统的 hot-top 接口的具体逻辑。
在大促的时候需要展现团购列表,这个接口的访问量是非常大的,团购活动需要根据参团人数倒序排序,并且分页返回指定数量的团列表。
我们假设这个接口名为 getTopGroups(getTopGroupsRequest request)
query condition 查询条件问题
我们来仔细分析下,首先不同的查询条件从 DB 里查询出来的数据是不一样的,也就是说查询出来的团列表是不一样的,可能有 company 公司 、channel 渠道 等过滤条件。由于一个团购活动下不会有太多团,顶多上百个是极限了,所以一个查询条件出来的团列表也顶多几十个,而且根据场景分析热点查询条件不会超过十个,所以我们选择将 查询条件 hash 出一个 code 来缓存本次查询条件的全量团列表集合,但是这些结果集是没有任何排序的。
sort 排序问题
再看根据参团人数排序问题,我们立刻就可以想到使用 zset 来处理团排序问题,因为只有一个排序维度,所以一个 zset 就够了。我们使用一个 __zset__来缓存所有团的参团人数集合,它是一个全量的团排序集合。
那么我们如何将用户的查询条件出来的团列表根据参团人数排序尼,刚好可以使用 zset 的交集运算直接计算出当前这个集合的 zset 子集。
page 分页问题
通过对已经排序之后的团列表 zset 使用 zrange 来获取出分页集合。
我们来看下完整的流程,如何处理查询、排序、分页的。
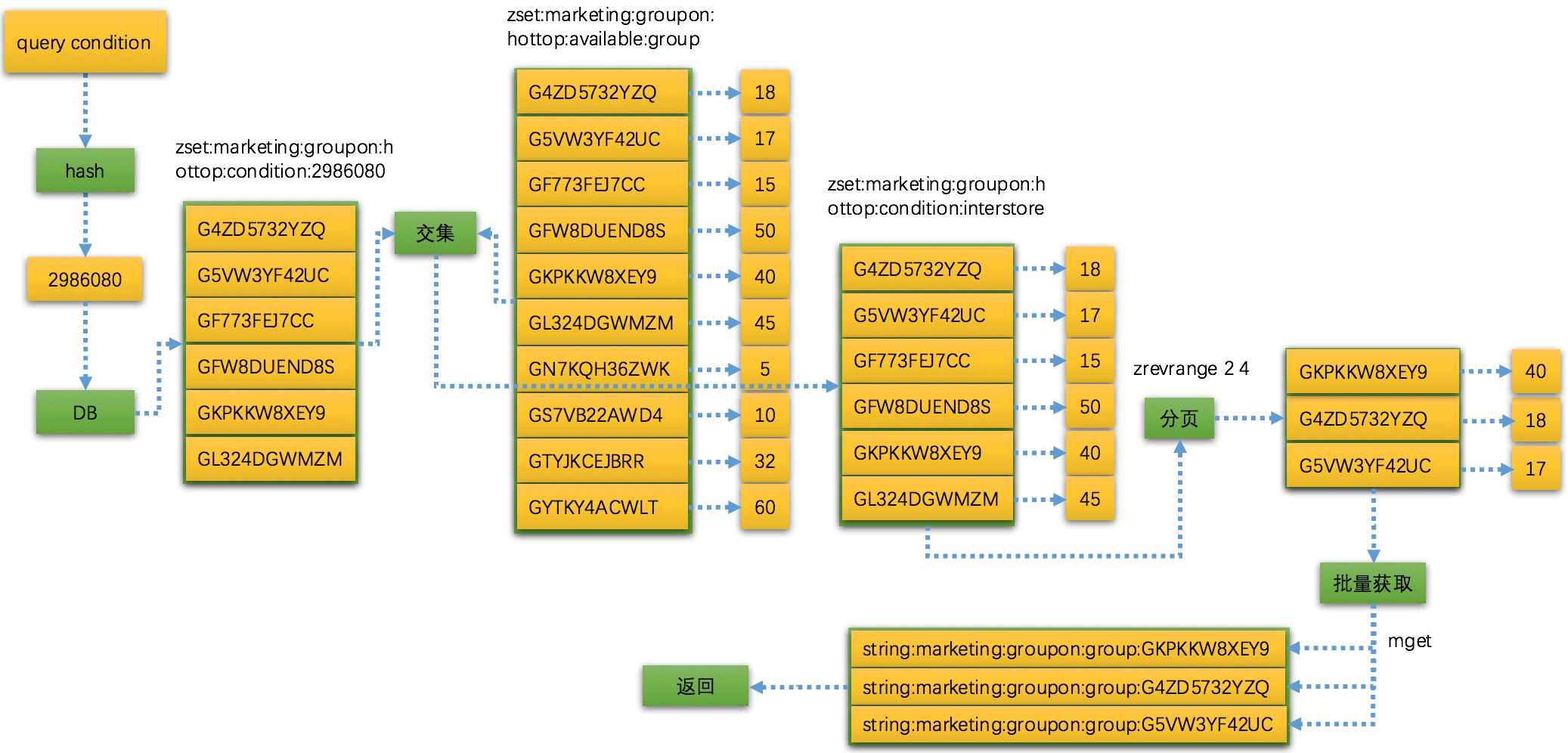
上图从 query condition 计算 hash code ,然后通过 DB 查询出当前条件全量团列表。
zset:marketing:groupon:hottop:available:group key 表示全量团的参团人数,用一个 zset 来缓存。接着将这两个 zset 计算交集,就可以得出当前查询所需要的带有参团人数的 zset ,最后在使用 zrevrange 获取分页区间。
ZADD zset:marketing:groupon:hottop:condition:2986080 0 G4ZD5732YZQ 0 G5VW3YF42UC 0 GF773FEJ7CC 0 GFW8DUEND8S 0 GKPKKW8XEY9 0 GL324DGWMZM
(integer) 6
ZADD zset:marketing:groupon:hottop:available:group 5 GN7KQH36ZWK 10 GS7VB22AWD4 15 GF773FEJ7CC 17 G5VW3YF42UC 18 G4ZD5732YZQ 32 GTYJKCEJBRR 40 GKPKKW8XEY9 45 GL324DGWMZM 50 GFW8DUEND8S 60 GYTKY4ACWLT
(integer) 10
ZINTERSTORE zset:marketing:groupon:hottop:condition:interstore 2 zset:marketing:groupon:hottop:condition:2986080 zset:marketing:groupon:hottop:available:group
(integer) 6
ZRANGE zset:marketing:groupon:hottop:condition:interstore 0 -1 withscores
1) "GF773FEJ7CC"
2) "15"
3) "G5VW3YF42UC"
4) "17"
5) "G4ZD5732YZQ"
6) "18"
7) "GKPKKW8XEY9"
8) "40"
9) "GL324DGWMZM"
10) "45"
11) "GFW8DUEND8S"
12) "50"
ZREVRANGE zset:marketing:groupon:hottop:condition:interstore 2 4 withscores
1) "GKPKKW8XEY9"
2) "40"
3) "G4ZD5732YZQ"
4) "18"
5) "G5VW3YF42UC"
6) "17"
有了返回的团 code 集合之后就可以通过 mget 来批量获取 string 类型的团详情信息,这里就不贴出代码了。
由于篇幅和时间关系,这里就不展开太多的业务场景介绍了。这其中还涉及到计算 cache 过期时间的问题,这也跟促销活动的运营规则有关系,还涉及到有可能 query condition hash 冲突问题等,但是这些已经不与我们本节主题相关。
Redis 内存数据结构与编码
我们已经了解了 redis 提供的 5 种数据类型,那么 redis 内部到底是如何支持这 5 种数据类型的,也就是说 redis 到底是使用什么样的数据结构来存储、查找我们设置在内存中的数据。
虽然我们使用 5 种数据类型来缓存数据,但是 redis 会根据我们存储数据的不同而选用不同的数据结构和编码。
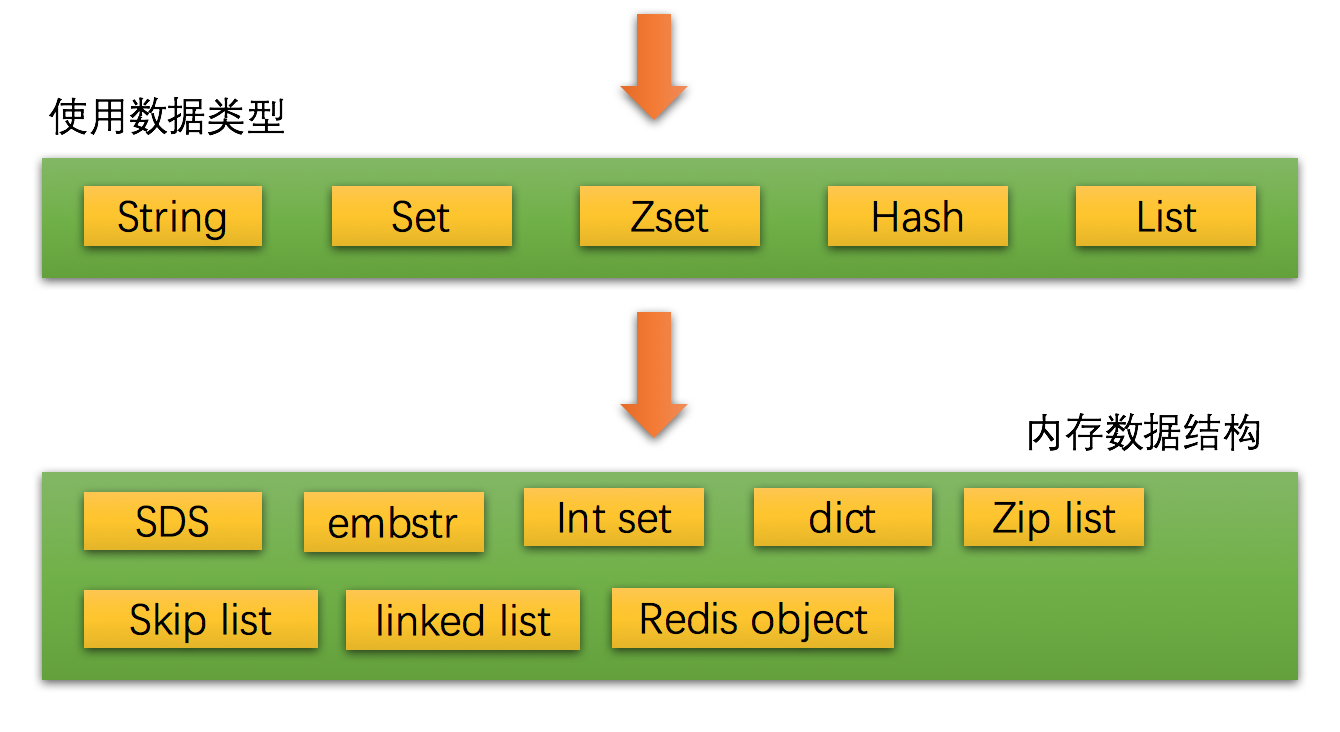
我们日常使用的是 redis 提供的 5 种数据类型,但是这 5 种数据类型在内存中的数据结构和编码有很多种。随着我们存储的数据类型的不同、数据量的大小不同都会引起内存数据结构的动态调整。
本节只是做数据结构和编码的一般性介绍,不做过多细节讨论,一方面是关于 redis 源码分析的资料网上有很多,还有一个原因就是 redis 每一个版本的实现有很大差异,一旦展开细节讨论每一个点每一个数据结构都会很复杂,所以我们这里就不展开讨论这些,只是起到抛砖引玉作用。
OBJECT encoding key、DEBUG OBJECT key
我们知道使用 type 命令可以查看某个 key 是否是 5 种数据类型之一,但是当我们想查看某个 key 底层是使用哪种数据结构和编码来存储的时候可以使用 OBJECT encoding 命令。
SET string:orderid:10101010 10101010
OK
OBJECT encoding string:orderid:10101010
"int"
SET string:orderid:10101010 "orderid:10101010"
OK
OBJECT encoding string:orderid:10101010
"embstr"
同样一个 key ,但是由于我们设置的值不同而 redis 选用了不同的内存数据结构和编码。虽然 redis 提供的 string 数据类型,但是 redis 会自动识别我们 cache 的数据类型是 int 还是 string 。
如果我们设置的是字符串,且这个字符串长度不大于 39 字节那么将使用 embstr 来编码,如果大于 39 字节将使用 raw 来编码。redis 4.0 将这个阀值扩大了 45 个字节。
除了使用 OBJECT encoding 命令外,我们还可以使用 DEBUG OBJECT 命令来查看更多详细信息。
DEBUG OBJECT string:orderid:10101010
Value at:0x7fd190500210 refcount:1 encoding:int serializedlength:5 lru:6468044 lru_seconds_idle:8
DEBUG OBJECT string:orderid:10101010
Value at:0x7fd19043be60 refcount:1 encoding:embstr serializedlength:17 lru:6465804 lru_seconds_idle:1942
DEBUG OBJECT 能看到这个对象的 refcount 引用计数 、serializedlength 长度 、lru_seconds_idle 时间 ,这些信息决定了这个 key 缓存清除策略。
简单动态字符串(simple dynamic string)
简单动态字符串简称 SDS ,在 redis 中所有涉及到字符串的地方都是使用 SDS 实现,当然这里不包括字面量。 SDS 与传统 C 字符串的区别就是 SDS 是结构化的,它可以高效的处理分配、回收、长度计算等问题。
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
这是 redis 3.0 版本的 sds.h 头文件定义,3.0.0 之后变化比较大。len 表示字符串长度,free 表示空间长度,buf 数组表示字符串。
SDS 有很多优点,比如,获取长度的时间复杂度 O(1) ,不需要遍历所有 char buf[] 组数,直接返回 len 值。
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
当然还有空间分配检查、空间预分配、空间惰性释放等,这些都是 SDS 结构化字符串带来的强大的扩展能力。
链表(linked list)
链表数据结构我们是比较熟悉的,最大的特点就是节点的增、删非常灵活。redis List 数据类型底层就是基于链表来实现。这是 redis 3.0 实现。
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
在 redis 3.2.0 版本的时候引入了 quicklist 链表结构,结合了 linkedlist 和 ziplist 的优势。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
quicklist 提供了灵活性同时也兼顾了 ziplist 的压缩能力,quicklist->encoding 指定了两种压缩算法。 quicklist->compress 表示我们可以进行 quicklist node 的深度压缩能力。redis 提供了两个有关于压缩的配置。
list-max-ziplist-size:ziplist长度控制
list-compress-depth:控制链表两端节点的压缩个数,越是靠近两端的节点被访问的机率越大,所以可以将访问机率大的节点不压缩,其他节点进行压缩
对比 redis 3.2 的 quicklist 与 redis 3.0 ,很明显 quicklist 提供了更加丰富的压缩功能。redis 3.0 的版本是每个 listnode 直接缓存值,而 quicklistnode 还有强大的有关于压缩能力。
LPUSH list:products:mall 100 200 300
(integer) 3
OBJECT encoding list:products:mall
"quicklist"
Redis 数据结构与内存管理策略(上)的更多相关文章
- Redis 数据结构与内存管理策略(下)
Redis 数据结构与内存管理策略(下) 标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射 Redis 数据类型特点与使用场景 String.Li ...
- iOS: ARC & MRC下string内存管理策略探究
ARC & MRC下string内存管理策略探究 前两天跟同事争论一个关于NSString执行copy操作以后是否会发生变化,两个人整了半天,最后写代码验证了一下,发现原来NSString操作 ...
- iOS内存管理策略和实践
转:http://www.cocoachina.com/applenews/devnews/2013/1126/7418.html 内存管理策略(memory Management Policy) N ...
- iOS 内存管理策略
内存管理策略(memory Management Policy) NSObject protocol中定义的的方法和标准命名惯例一起提供了一个引用计数环境,内存管理的基本模式处于这个环境中.NSObj ...
- Rs2008内存管理策略
Rs2008 在内存管理方面已经有了很大的改变.主要增加了文件缓存,允许把内存数据卸载到文件缓存中.而Rs2005 都是把数据放到内存中.对于大数据量的报表而言,很容易出现OutOfMemory 错误 ...
- Linux堆内存管理深入分析(上)
Linux堆内存管理深入分析(上半部) 作者:走位@阿里聚安全 0 前言 近年来,漏洞挖掘越来越火,各种漏洞挖掘.利用的分析文章层出不穷.从大方向来看,主要有基于栈溢出的漏洞利用和基于堆溢出的漏洞 ...
- 分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 分布式缓存技术redis学习(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- OS之内存管理 ---基本的内存管理策略(一)
基本概念 基本硬件 CPU可以直接访问的通用存储只有内存和处理器的内置的寄存器.机器指令可以用内存地址作为参数,而不能用磁盘地址作为参数.所以执行指令以及指令使用的数据,应在这些可执行访问的存储设备上 ...
随机推荐
- vue双向绑定的原理及实现双向绑定MVVM源码分析
vue双向绑定的原理及实现双向绑定MVVM源码分析 双向数据绑定的原理是:可以将对象的属性绑定到UI,具体的说,我们有一个对象,该对象有一个name属性,当我们给这个对象name属性赋新值的时候,新值 ...
- 【java】实例化对象的3种方式:new、clone、反射
实例化对象的3种方式:new.clone.反射
- 【JMeter】JMeter代码里若有外部自定义方法调用需要写进方法体里,否则报错
- 【java】缓冲字符字节输入输出流:java.io.BufferedReader、java.io.BufferedWriter、java.io.BufferedInputStream、java.io.BufferedOutputStream
BufferedReader最重要,因为有个方法public String readLine() package System输入输出; import java.io.BufferedReader; ...
- SP的封装(数据持久化方式一)
1.先看一段描述: Interface for accessing and modifying preference data returned by Context.getSharedPrefere ...
- AntData.ORM框架 之 读写分离
环境准备 准备2台机器配置好Master Slaver模式 我是用vmware 2台虚拟机配置的.有需要请联系. Master:192.168.11.130 Slaver:192.168.11.133 ...
- Who Will Win?
Gautam and Subhash are two brothers. They are similar to each other in all respects except one. They ...
- DNS 域名系统的简介
一.DNS域名系统简介 1.网络中为了区别各个主机,必须为每台主机分配一个唯一的地址, 这个地址即称为“IP 地址.但这些数字难以记忆, 所以采用“域名” 的方式来取代这些数字. 2.当某台主机要与其 ...
- TreeMap源码
一.TreeMap简介 TreeMap是基于红黑树的java版实现,作者Josh Bloch and Doug Lea(这二人在java发展的早期做了重大贡献,比如集合框架JDK1.2.并发包JDK1 ...
- python logging一个通用的使用模板
import os import logbook from logbook.more import ColorizedStderrHandler from functools import wraps ...