内存数据库之Apache Ingite
上一篇文章,我们做了内存数据库的技术选型:
本文中,我们继续深入研究Apache Ignite,同时分享一些我们.Net的编码实践。
首先,Apache Ignite是一个内存数据组织是高性能的、集成化的以及分布式的内存平台,他可以实时地在大数据集中执行事务和计算,和传统的基于磁盘或者闪存的技术相比,性能有数量级的提升。
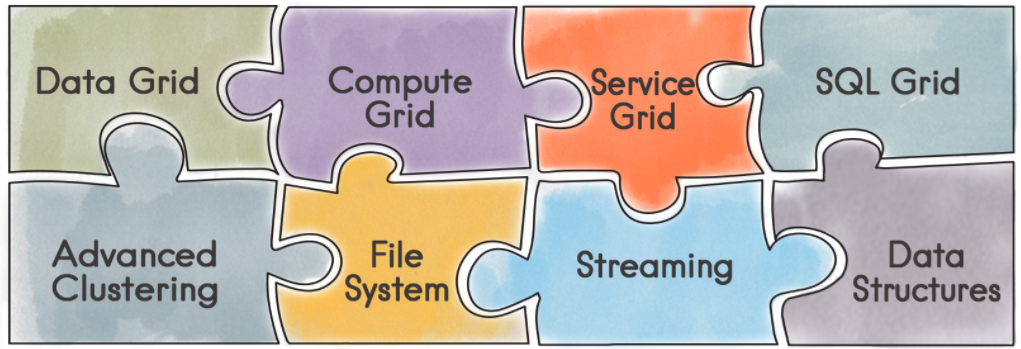
其中:
Data Grid:Ignite内存数据网格是一个内存内的键值存储,他可以在分布式集群的内存内缓存数据。
它通过强语义的数据位置和关系数据路由,来降低冗余数据的噪声,使其可以节点数的线性增长,直至几百个节点。
Ignite数据网格速度足够快,经过官方不断的测试,目前,他是分布式集群中支持事务性或原子性数据的最快的实现之一。
SQL Grid:内存SQL网格为Apache Ignite提供了分布式内存数据库的功能,它水平可扩展,容错并且兼容SQL的ANSI-99标准。 SQL网格支持完整的DML命令,包括SELECT, UPDATE, INSERT, MERGE以及DELETE。 同时支持分布式SQL Join关联
RDBMS集成: Ignite支持与各种持久化存储的集成,它可以连接数据库,导入模式,配置索引类型,以及自动生成所有必要的XML OR映射配置和Java领域模型POJO,这些都可以轻易地下载和复制进自己的工程。
Ignite可以与任何支持JDBC驱动的关系数据库集成,包括Oracle、PostgreSQL、MS SQL Server和MySQL
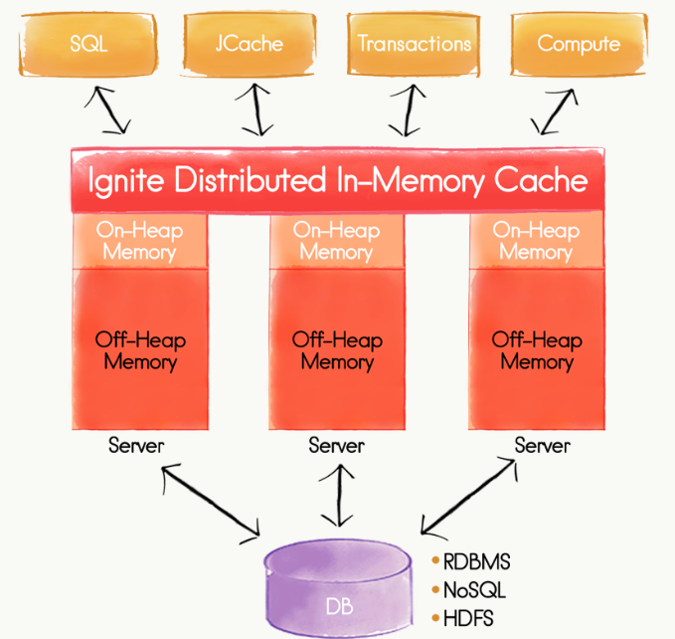
Apache Ignite 的功能特性有:
- 分布式键值存储:Ignite数据网格是一个内存内的键值存储,分布式的分区化的哈希,集群中每个节点都持有所有数据的一部分,这意味着集群内节点越多,就可以缓存的数据越多。 Ignite通过可插拔的哈选算法来决定数据的位置,每个客户端都可以通过插入一个自定义的哈希函数来决定一个键属于那个节点,并不需要任何特殊的映射服务或者命名节点。
- 内存优化:Ignite在内存中支持2种模式的数据缓存,堆内和堆外。当缓存数据占用很大的堆,超过了Java主堆空间时,堆外存储可以克服JVM垃圾回收(gc)导致的长时间暂停,但数据仍然在内存内。
- SQL查询:Ignite支持使用标准的SQL语法(ANSI 99)来查询缓存,可以使用任何的SQL函数,包括聚合和分组。
- 分布式关联:Ignite支持分布式的SQL关联和跨缓存的关联。
- ACID事务:Ignite提供了一个完全符合ACID的分布式事务来保证一致性。 支持乐观和悲观的并发模型以及读提交、可复制读和序列化的隔离级别。 Ignite的事务使用了二阶段提交协议,适当地也进行了很多一阶段提交的优化。
- 同写和同读:通写模式允许更新数据库中的数据,通读模式允许从数据库中读取数据。
- 数据库异步更新:Ignite提供了一个选项,通过后写缓存来异步地执行数据库更新
- 自动持久化:自动化地连接底层数据库并且生成XML的对象关系映射配置和Java领域模型POJO
- 数据库支持:Ignite可以自动地与外部数据库集成,包括RDBMS、NoSQL和HDFS。
Apache Ignite具有非常先进的集群能力,部署非常灵活。
- 节点平等:Ignite没有master节点或者server节点,也没有worker节点或者client节点,按照Ignite的观点所有节点都是平等的。但是开发者可以将节点配置成master,worker或者client以及data节点。
- 自动发现机制:Ignite节点之间会自动感知,集群可扩展性强,不需要重启集群,简单地启动新加入的节点然后他们就会自动地加入集群。这是通过一
- 个发现机制实现的,他使节点可以彼此发现对方,Ignite默认使用TcpDiscoverySpi通过TCP/IP协议来作为节点发现的实现,也可以配置成基于多播的或者基于静态IP的,这些方式适用于不同的场景。
- 部署模式:Ignite可以独立运行,也可以在集群内运行,也可以将几个jar包嵌入应用内部以嵌入式的模式运行,也可以运行在Docker容器以及Mesos和Yarn等环境中,可以在物理机中运行,也可以在虚拟机中运行,这个广泛的适应性是他的一个很大的优势。
- 配置方式:Ignite的大部分配置选项,都同时支持通过基于Spring的XML配置方式以及通过Java代码的编程方式进行配置。
- 客户端和服务端:Ignite中各个节点是平等的,但是可以根据需要将节点配置成客户端或者服务端,服务端节点参与缓存,计算,流式处理等等,而原生的客户端节点提供了远程连接服务端的能力。Ignite原生客户端可以使用完整的Ignite API,包括近缓存,事务,计算,流,服务等等。
- 所有的Ignite节点默认都是以服务端模式启动的,客户端模式需要显式地启用。
上面大致介绍了Apache Ignite的架构和功能特性,现在我们以代码示例的方式,分享一下做的技术原型验证:
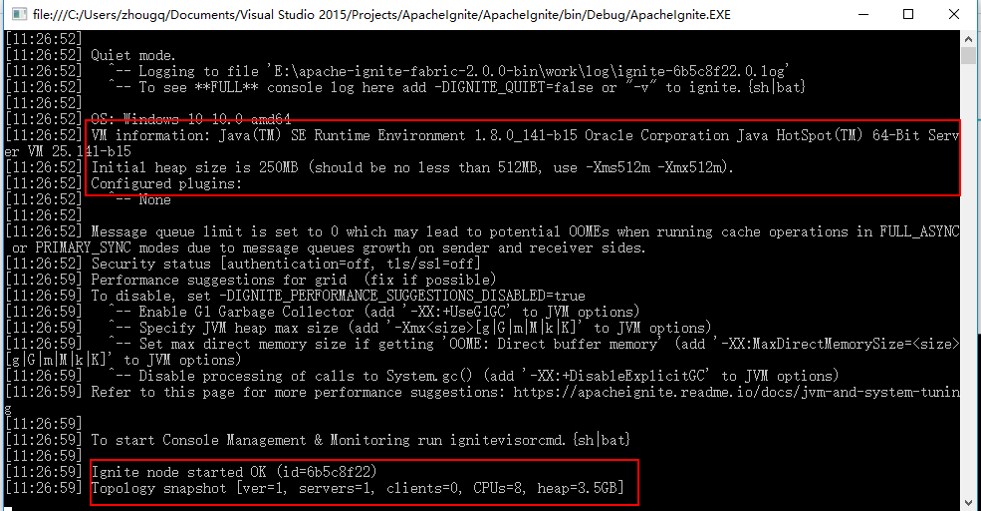
1. 启动Apache Ignite
代码中通过调用Ignition.Start()启动一个Ignite节点。
直接执行apache.Ignite.exe也可以启动一个Ignite节点,其内部引用了Apache.Ignite.Core.dll,调用了Ignition.Start()方法
- Ignite可以Host在Console和Winform中
- Ignite依赖Oracle JDK 7及更高版本
- Ignite可以独立运行
- 存在跨进程访问的情况
2. 创建指定的缓存区域

3. 数据写入缓存

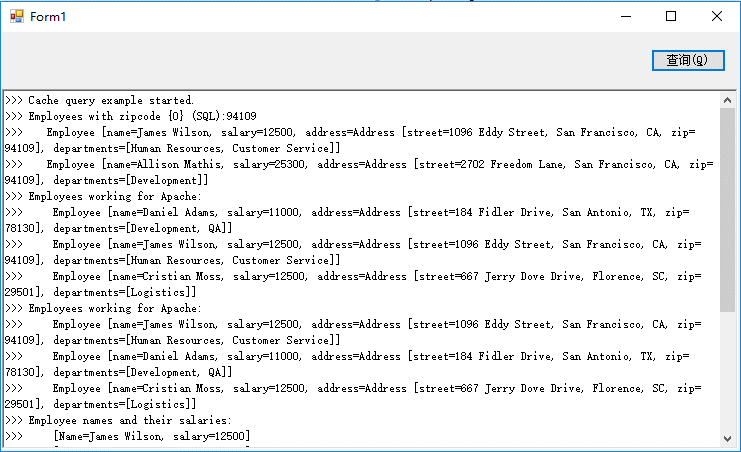
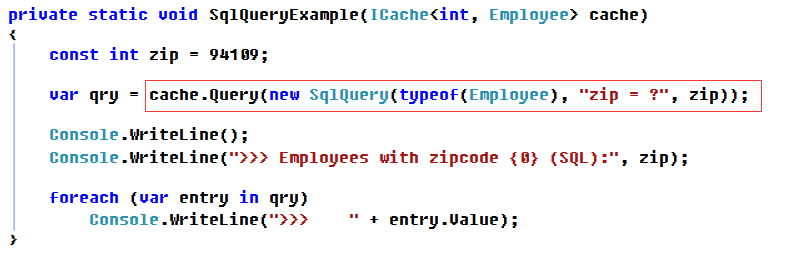
4.数据查询
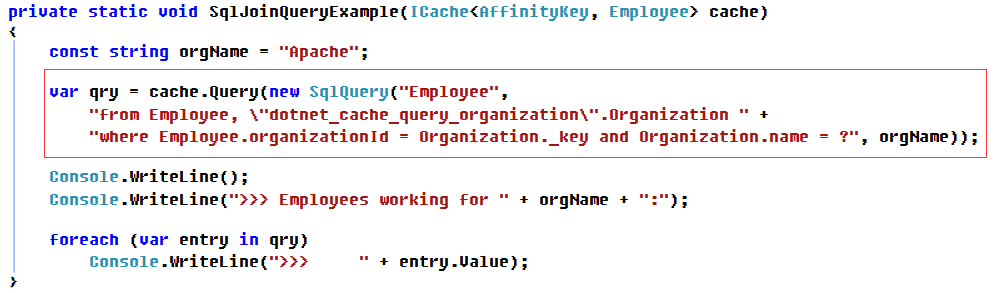
5. 数据关联查询
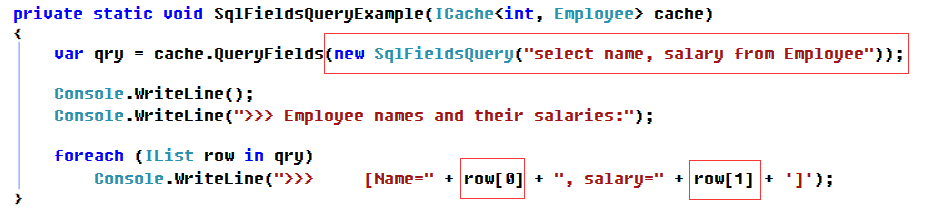
6.查询指定的字段
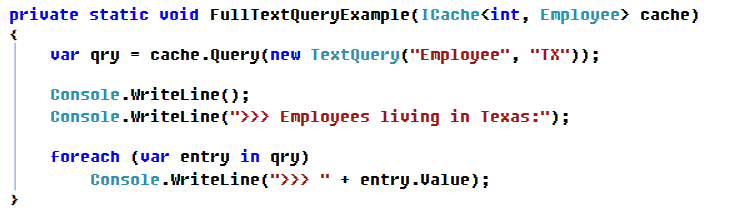
7.全文搜索
8. Apache Ignite集群部署
节点平等
Ignite没有master节点或者server节点,也没有worker节点或者client节点,按照Ignite的观点所有节点都是平等的。但是开发者可以将节点配置成master,worker或者client以及data节点。
自动发现机制
Ignite节点之间会自动感知,集群可扩展性强,不需要重启集群,简单地启动新加入的节点然后他们就会自动地加入集群。这是通过一个发现机制实现的,他使节点可以彼此发现对方,Ignite默认使用TcpDiscoverySpi通过TCP/IP协议来作为节点发现的实现,也可以配置成基于多播的或者基于静态IP的,这些方式适用于不同的场景。
部署模式
Ignite可以独立运行,也可以在集群内运行,也可以将几个jar包嵌入应用内部以嵌入式的模式运行,也可以运行在Docker容器以及Mesos和Yarn等环境中,可以在物理机中运行,也可以在虚拟机中运行,这个广泛的适应性是他的一个很大的优势。
配置方式
Ignite的大部分配置选项,都同时支持通过基于Spring的XML配置方式以及通过Java代码的编程方式进行配置,这个也是个重要的优点。
9. 客户端和服务端
Ignite中各个节点是平等的,但是可以根据需要将节点配置成客户端或者服务端,服务端节点参与缓存,计算,流式处理等等,而原生的客户端节点提供了远程连接服务端的能力。Ignite原生客户端可以使用完整的Ignite API,包括近缓存,事务,计算,流,服务等等。
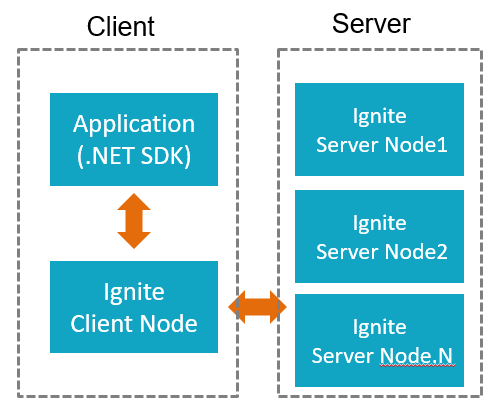
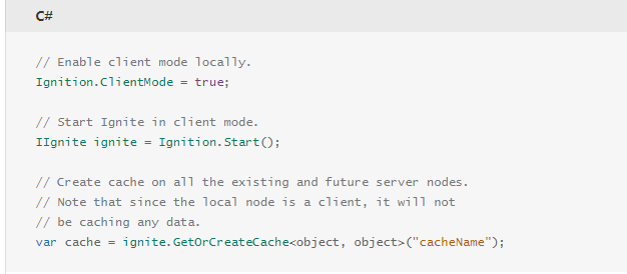
代码以Client模式启动Ignite
Client/Server架构,带来了很大的问题!!
- 每个使用Ignite的主机都要安装JDK,同时启动一个Ignite Client节点
- 开发、运维、管理成本很高
10. Apache Ignite REST API
Apache Ignite 提供了Restful API,支持对缓存的读、写、执行任务、获取各类指标等。
启用HTTP连接:将libs\optional\ignite-rest-http 拷贝到libs\ignite-rest-http即可。
http://localhost:8080/ignite?cmd=version
Get or create cache
http://localhost:8080/ignite?cmd=getorcreate&cacheName=partionedCache
Add
http://localhost:8080/ignite?cmd=add&key=newKey&val=newValue&cacheName=partionedCache
Get
http://localhost:8080/ignite?cmd=get&key=newKey&cacheName=partionedCache
SQL Query
http://localhost:8080/ignite?cmd=qryexe&type=Person&pageSize=10&cacheName=Person&arg1=1000&arg2=2000qry=salary+%3E+%3F+and+salary+%3C%3D+%3F
以上就是整个Apache Ignite的技术分享。
周国庆
2017/8/26
内存数据库之Apache Ingite的更多相关文章
- JDK由浅到深的理解
一.JDK的安装 二.JDK安装后目录下的文件夹的用处 bin:编译器(javac.exe); db:jdk从1.6之后内置Derby数据库,它是一个纯用Java实现的内存数据库,Apache的开源项 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
- 高性能jdbc封装工具 Apache Commons DbUtils 1.6(转载)
转载自原文地址:http://gao-xianglong.iteye.com/blog/2166444 前言 关于Apache的DbUtils中间件或许了解的人并不多,大部分开发人员在生成环境中更多的 ...
- Apache Kafka开发入门指南(1)
Apache Kafka可以帮助你解决在发布/订阅架构中遇到消费数百万消息的问题.如今,商业应用.社交应用以及其它类型的应用产生的实时信息在不断增长,这些信息需要以简单的方式快速.可靠地路由到各种类型 ...
- 10. 管理Apache ZooKeeper配置
Tips 有关ZooKeeper部署和管理的详细说明,请参阅官方文档http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html. 1. 配置Zo ...
- Apache ZooKeeper 服务启动源码解释
转载:https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper-code/ 本文首先讲解了 Apache ZooKeeper 服 ...
- Apache Ignite 学习笔记(四): Ignite缓存冗余备份策略
Ignite的数据网格是围绕着基于内存的分布式key/value存储能力打造的.当初技术选型的时候,决定用Ignite也是因为虽然同样是key/value存储,它有着和其他key/value存储系统不 ...
- Apache Ignite 学习笔记(三): Ignite Server和Client节点介绍
在前两篇文章中,我们把Ignite集群当做一个黑盒子,用二进制包自带的脚本启动Ignite节点后,我们用不同的客户端连接上Ignite进行操作,展示了Ignite作为一个分布式内存缓存,内存数据库的基 ...
- Java内存数据库-H2介绍及实例(SpringBoot)
介绍 内存数据库(Embedded database或in-momery database)具有配置简单.启动速度快.尤其是其可测试性等优点,使其成为开发过程中非常有用的轻量级数据库.在spring中 ...
随机推荐
- Spring Boot 系列(五)web开发-Thymeleaf、FreeMarker模板引擎
前面几篇介绍了返回json数据提供良好的RESTful api,下面我们介绍如何把处理完的数据渲染到页面上. Spring Boot 使用模板引擎 Spring Boot 推荐使用Thymeleaf. ...
- 【MySQL故障处理】 Seconds_Behind_Master= NULL Error_code: 1197
版本:mysql 5.6.32**错误描述:**```Error_code: 1197Last_Error: Worker 3 failed executing transaction '352aa3 ...
- log4go的精确定时程序(带自动延迟补偿)
程序设计目标是在程序启动10秒后执行某个任务,例如日志转储(rotate),以后每隔15秒执行一次. 初次的设计 package main import ( "time" &quo ...
- docker~save与load的使用
回到目录 对于没有私有仓库来说,将本地镜像放到其它服务器上执行时,我们可以使用save和load方法,前者用来把镜像保存一个tar文件,后台从一个tar文件恢复成一个镜像,这个功能对于我们开发者来说还 ...
- Android 自定义帧动画
Android 自定义帧动画 Android L : Android Studio 帧动画 和gif图片类似,顺序播放准本好的图片文件:图片资源在xml文件中配置好 将图片按照预定的顺序一张张切换,即 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- (转)logback 打印Mybitis中的sql执行过程
场景:在程序开发过程中经常需要跟踪程序中sql语句的执行过程,在控制台打印出sql语句和对应的参数传递就能够更快的定位错误! 原文出处:http://www.cnblogs.com/beiyeren/ ...
- 快速搭建MySQL复制集
快速搭建MySQL复制集 1 环境说明 MySQL版本 5.6 basedir :/u01/my3306 #MySQL软件目录 数据目录 :/u01/mysql/[实例名]/data 日志目录 :/u ...
- year:2017 month:7 day:20
2017-07-20 JavaScript(Dom) 1:获取节点对象 document.getElementById("html元素的id") document.getEleme ...
- EntityFramework Core查询问题集锦(一)
前言 和大家脱离了一段时间,有时候总想着时间挤挤总是会有的,但是并非人愿,后面会借助周末的时间来打理博客,如有问题可以在周末私信我或者加我QQ皆可,欢迎和大家一起探讨,本节我们来讨论EF Core中的 ...