基于nodejs模拟浏览器post请求爬取json数据
今天想爬取某网站的后台传来的数据,中间遇到了很多阻碍,花了2个小时才请求到数据,所以我在此总结了一些经验。
首先,放上我所爬取的请求地址http://api.chuchujie.com/api/?v=1.0;
下面我们开始爬取数据。
一.写一个基于nodejs的爬虫
1.引入所需模块
这里需要引入http模块(nodejs用来向浏览器发送http请求的模块)和querystring模块(把前台传过来的对象形式的参数转化成字符串形式);
var http = require("http"); //http 请求
//var https = require("https"); //https 请求
var querystring = require("querystring");
2.配置http.router(options,fn)参数options
在配置中,重点在于模拟浏览器请求头,一般必须模拟Cookie,User-Agent(访问设备系统),Content-Type,有的需要模拟更多。在这里,我们的这个目标并没有Cookie,所以不用传。
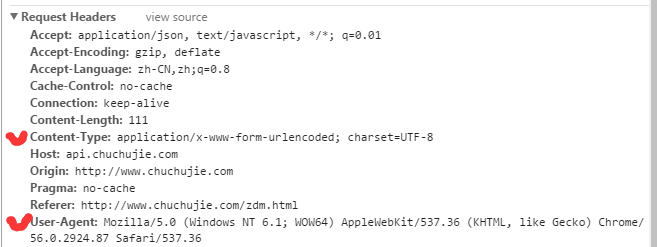
3.给目标后台发起http post请求得到数据
var req = http.request(options, function (res) {
var json = ""; //定义json变量来接收服务器传来的数据
console.log(res.statusCode);
//res.on方法监听数据返回这一过程,"data"参数表示数数据接收的过程中,数据是一点点返回回来的,这里的chunk代表着一条条数据
res.on("data", function (chunk) {
json += chunk; //json由一条条数据拼接而成
})
//"end"是监听数据返回结束,callback(json)利用回调传参的方式传给后台结果再返回给前台
res.on("end", function () {
callback(json);
})
})
req.on("error", function () {
console.log('error')
})
//这是前台参数的一个样式,这里的参数param由后台的路由模块传过来,而后台的路由模块参数是前台传来的
// var obj = {
// query: '{"function":"newest","module":"zdm"}',
// client: '{"gender":"0"}',
// page: 1
//}
req.write(querystring.stringify(param)); //post 请求传参
req.end(); //必须要要写,
4.模块化导出
完整的spider代码
/**
* Created by Administrator on 2017/2/12.
*/
var http = require("http"); //http 请求
//var https = require("https"); //https 请求
var querystring = require("querystring");
function request(path,param,callback) {
var options = {
hostname: 'api.chuchujie.com',
port: 80, //端口号 https默认端口 443, http默认的端口号是80
path: path,
method: 'POST',
headers: {
"Connection": "keep-alive",
"Content-Length": 111,
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
}//伪造请求头
}; var req = http.request(options, function (res) { var json = ""; //定义json变量来接收服务器传来的数据
console.log(res.statusCode);
//res.on方法监听数据返回这一过程,"data"参数表示数数据接收的过程中,数据是一点点返回回来的,这里的chunk代表着一条条数据
res.on("data", function (chunk) {
json += chunk; //json由一条条数据拼接而成
})
//"end"是监听数据返回结束,callback(json)利用回调传参的方式传给后台结果再返回给前台
res.on("end", function () {
callback(json);
})
}) req.on("error", function () {
console.log('error')
})
//这是前台参数的一个样式,这里的参数param由后台的路由模块传过来,而后台的路由模块参数是前台传来的
// var obj = {
// query: '{"function":"newest","module":"zdm"}',
// client: '{"gender":"0"}',
// page: 1
//}
req.write(querystring.stringify(param)); //post 请求传参
req.end(); //必须要要写, }
module.exports = request;
基于nodejs模拟浏览器post请求爬取json数据的更多相关文章
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- httpClient模拟浏览器发请求
一.介绍 httpClient是Apache公司的一个子项目, 用来提高高效的.最新的.功能丰富的支持http协议的客户端编程工具包.完成可以模拟浏览器发起请求行为. 二.简单使用例子 : 模拟浏览器 ...
- 使用HttpClient配置代理服务器模拟浏览器发送请求调用接口测试
在调用公司的某个接口时,直接通过浏览器配置代理服务器可以请求到如下数据: 请求url地址:http://wwwnei.xuebusi.com/rd-interface/getsales.jsp?cid ...
- 爬虫学习(四)——post请求爬取
百度翻译爬取数据 import urllib.requestimport urllib.parsepost_url = "https://fanyi.baidu.com/sug"h ...
- NodeJs本地搭建服务器,模拟接口请求,获取json数据
最近在学习Node.js,虽然就感觉学了点皮毛,感觉这个语言还不错,并且也会一步步慢慢的学着的,这里实现下NodeJs本地搭建服务器,模拟接口请求,获取json数据. 具体的使用我就不写了,这个博客写 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- 爬虫(十):AJAX、爬取AJAX数据
1. AJAX 1.1 什么是AJAX AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的 ...
随机推荐
- open in browser
Sublime Text 3 Build 3065 Preferences-Key Bindings User: 直接key binding:{ "keys": ["al ...
- C# INotifyPropertyChanged使用方法
INotifyPropertyChanged 接口:向客户端发出某一属性值已更改的通知. NotifyPropertyChanged 接口用于向客户端(通常是执行绑定的客户端)发出某一属性值已更改的通 ...
- Objective-C处理动态类型函数集
-(BOOL) isKindOfClass:class-object 对象是不是class-object或其子类的实例-(BOOL) isMemberOfClass:class-object 对象是不 ...
- OpenCV框架介绍
OpenCV框架介绍 概述 OpenCV是一个开放源代码的计算机视觉应用平台,由英特尔公司下属研发中心俄罗斯团队发起该项目,开源BSD证书,OpenCV的目标是实现实时计算机视觉,,是一个跨平台的计算 ...
- 开源OSS.Social项目进阶介绍和使用展示
在开源OSS.Social微信项目解析的随笔中,我简单给大家分享了进行中微信项目的概要设计,没有全局介绍,没有详细讲解,也没有如何使用,很多朋友估计匆匆一瞥就忙着抢开工红包去了.本着不能马虎的态度,这 ...
- shell 脚本浅入
最常用的Linux命令和工具 目录下个文档:cd name 返回上个目录:cd .. 查看.编辑文本文件:查看文件:more, tail 编辑文件:vi 如编写脚本.sh vi shell.sh ...
- 通过实例解释LinuxC下argc,argc[]的意义
MarkdownPad Document html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,ab ...
- pwnable.kr-fd-Writeup
html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,abbr,acronym,address,bi ...
- Odoo安装
打开终端机0. sudo passwd root #设定超级使用者密码1. sudo apt-get update #更新软件源2. sudo apt-get dist-upgrade #更新软件包, ...
- Monit:开源服务器监控工具
Monit是一个跨平台的用来监控Unix/linux系统(比如Linux.BSD.OSX.Solaris)的工具.Monit特别易于安装,而且非常轻量级(只有500KB大小),并且不依赖任何第三方程序 ...