Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐
首先我们需要进入到这个界面
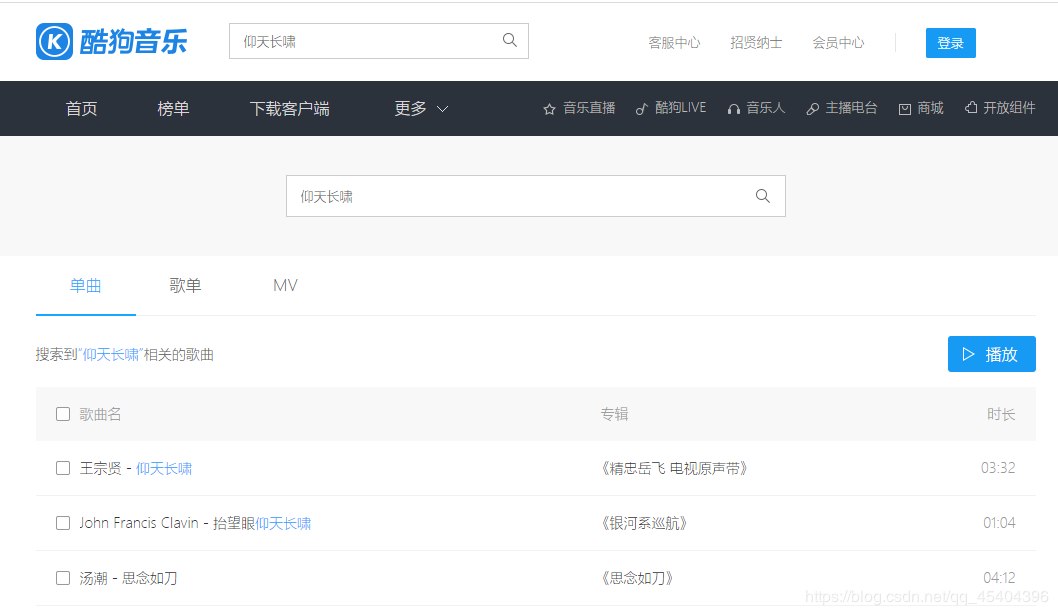
想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息。
这个时候我们就应该换一种思路了,点击Network下的JS,如果没有什么信息,可按F5进行刷新。之后我们点击如下:
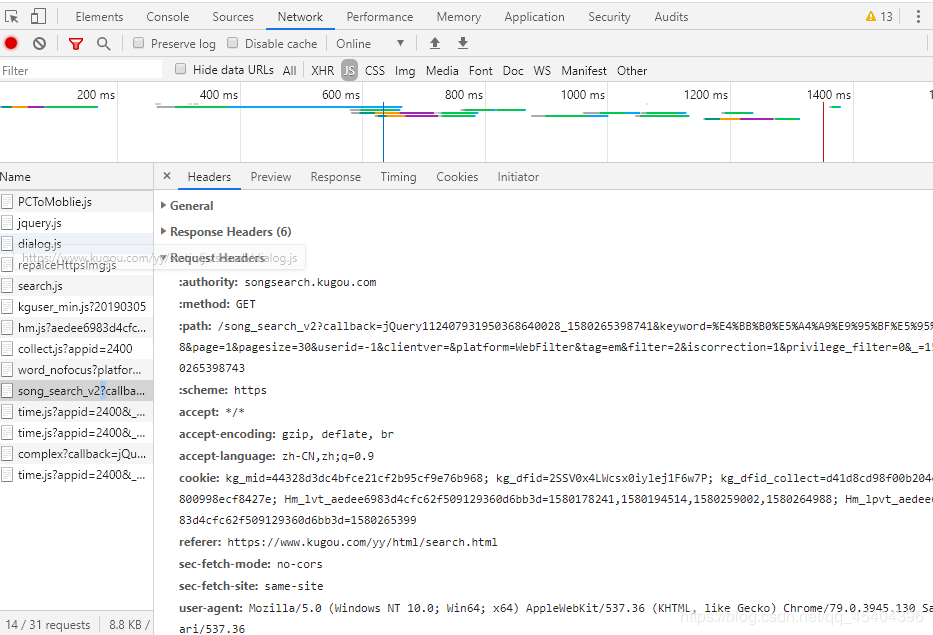
然后我们在点击Preview,可发现:

lists下面有我们需要的信息,可以通过这些信息重新组成一个网址:
https://www.kugou.com/song/#hash=(FileHash)&album_id=(AlbumID)
FileHash和AlbumID的值能在lists下面找到。
完成这个操作,点击进入这个组合的网址,就可以进入到这个界面了。
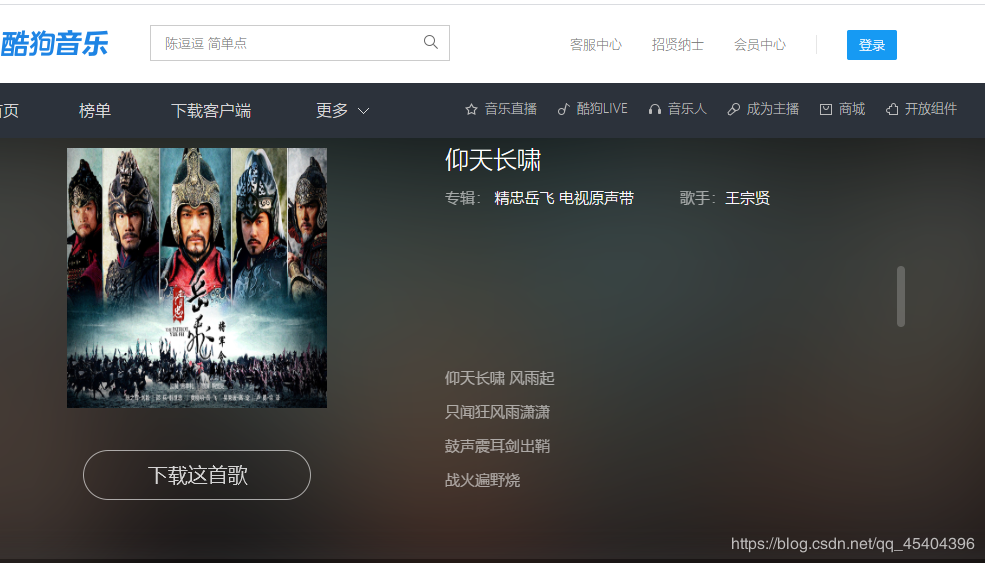
再单击右键进行检查,发现这里有这首歌的下载链接
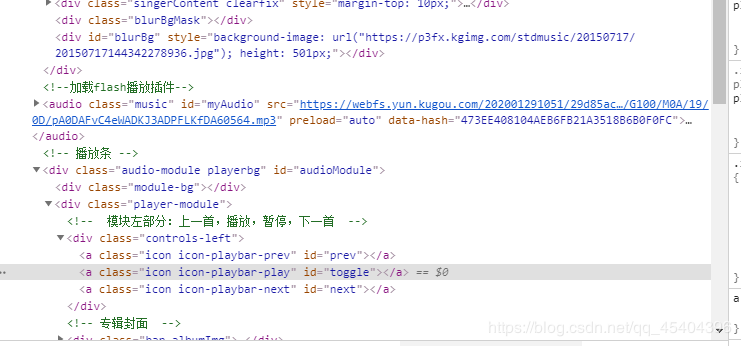
这个时候再进行爬取,发现其他信息都有,唯独没有这个下载链接,点击Network下面的JS,刷新发现有一个JS文件上有这个链接
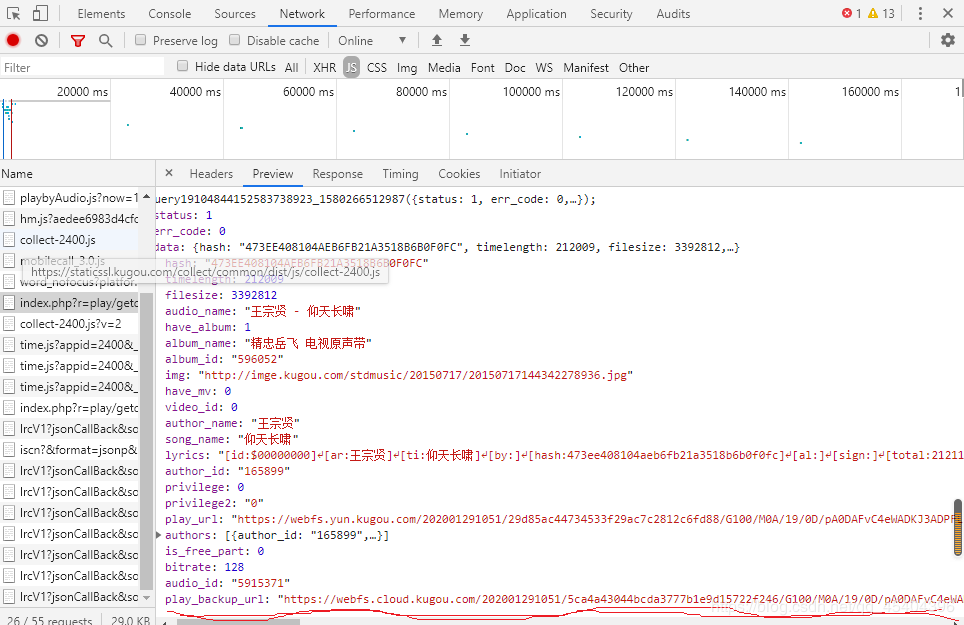
然后我们只需将这个网址进行组合即可https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104844152583738923_1580266512987&hash=473EE408104AEB6FB21A3518B6B0F0FC&album_id=596052&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4&_=1580266512988
通过多次组合发现,这个网址只需hash、album_id、dfid、mid和platid就可以得到所需要的信息了,且dfif、mid和platid的值是不变的,而前面的两个变量的值在我说的第四幅图中可以找到。
完成这个之后,点击进入,就可以得到想要的信息了。、
代码代码如下:
from urllib.request import urlopen
import urllib.parse
import json # 导入json模块,为了使下载的js文件更容易得到所需的信息
import time
import sys
import os # 导入sys和time模块是为了显示进度条 def Time_1(): # 进度条函数
for i in range(1,51):
sys.stdout.write('\r')
sys.stdout.write('{0}% |{1}'.format(int(i%51)*2,int(i%51)*'■'))
sys.stdout.flush()
time.sleep(0.125)
sys.stdout.write('\n') def KuGou_music(): keyword=urllib.parse.urlencode({'keyword':input('请输入歌名:')})
keyword=keyword[keyword.find('=')+1:]
url='https://songsearch.kugou.com/song_search_v2?callback=jQuery1124042761514747027074_1580194546707&keyword='+keyword+'&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1580194546709'
content=urlopen(url=url)
content=content.read().decode('utf-8')
str_1=content[content.find('(')+1:-2]
str_2=json.loads(str_1)
Music_Hash={}
Music_id={}
for dict_1 in str_2['data']['lists']:
Music_Hash[dict_1['FileName']]=dict_1['FileHash']
Music_id[dict_1['FileName']]=dict_1['AlbumID']
# print(dict_1) list_music_1=[music for music in Music_Hash] # 匹配到的所有歌曲名 列表
list_music=[music for music in Music_Hash] for i in range(len(list_music)):
if '- <em>' in list_music[i]:
list_music[i]=list_music[i].replace('- <em>','-')
if '</em>' in list_music[i]:
list_music[i]=list_music[i].replace('</em>','')
if '<em>' in list_music[i]:
list_music[i]=list_music[i].replace('<em>','') # 使歌曲名称更加美观
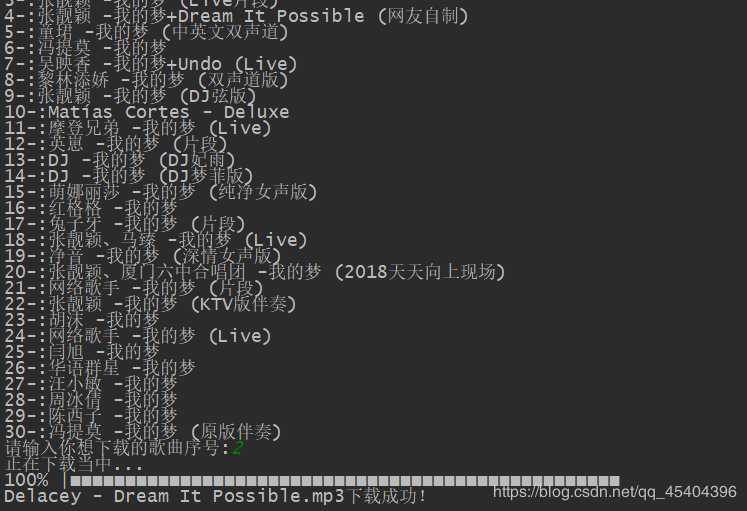
# 如: < em > 战狼 < / em > - 断情笔 经过这个处理之后 战狼 - 断情笔 for i in range(len(list_music)):
print("{}-:{}".format(i+1,list_music[i])) music_id_1=int(input('请输入你想下载的歌曲序号:')) # 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=E77548A33D7AF84F727C32A786C107D0&album_id=542163&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
# 一个加载js文件的标椎式样网址 url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash='+Music_Hash[list_music_1[music_id_1-1]]+'&album_id='+Music_id[list_music_1[music_id_1-1]]+'&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
js_content=urlopen(url=url)
str_3=js_content.read().decode('utf-8') #所加载的js中的内容
dict_2=json.loads(str_3) # 将这个js格式转换成为字典格式 try:
music_href=dict_2['data']['play_backup_url'] #下载的歌曲网址 music_content=urlopen(url=music_href).read()
try:
os.mkdir('D:\酷狗音乐下载')
except Exception as e:
print(e,'但不要紧,程序仍然执行')
finally:
music_path='D:\酷狗音乐下载\\'+list_music[music_id_1-1]+'.mp3' # 歌曲下载路径
with open(music_path,'wb') as f:
print('正在下载当中...')
f.write(music_content)
Time_1()
print('{}.mp3下载成功!'.format(list_music[music_id_1-1])) except:
print('对不起,没有该歌曲的版权!') if __name__=='__main__':
print('------声明:本小程序仅供娱乐,切莫用于商业活动,一经发现,概不负责!-------')
KuGou_music()
注意:代码中的那个下载路径必须是已经存在了的,否则会报错。
一些歌曲是下载不了的,如 你的名字 ,这个是付费歌曲,这个程序只能下载 酷狗音乐在网页上能播放的。
注意:这个代码仅供娱乐和学习,切莫用于商业目的,一经发现,概不负责!
Python 应用爬虫下载酷狗音乐的更多相关文章
- Python爬虫下载酷狗音乐
目录 1.Python下载酷狗音乐 1.1.前期准备 1.2.分析 1.2.1.第一步 1.2.2.第二步 1.2.3.第三步 1.2.4.第四步 1.3.代码实现 1.4.运行结果 1.Python ...
- 【Python3爬虫】下载酷狗音乐上的歌曲
经过测试,可以下载要付费下载的歌曲(n_n) 准备工作:Python3.5+Pycharm 使用到的库:requests,re,json,time,fakeuseragent 步骤: 打开酷狗音乐的官 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Python实例---爬去酷狗音乐
项目一:获取酷狗TOP 100 http://www.kugou.com/yy/rank/home/1-8888.html 排名 文件&&歌手 时长 效果: 附源码: import t ...
- Python代码搜索并下载酷狗音乐
运行环境: Python3.5+Pycharm 实例代码: import requests,re keyword = input("请输入想要听的歌曲:") url = " ...
- Python爬虫:通过做项目,小编了解了酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 【python3】酷狗音乐及评论回复下载
新年快乐,上班第一天分享一个python源码,功能比较简单,就是实现酷狗音乐的音乐文件(包含付费音乐)和所有评论回复的下载. 以 米津玄師 - Lemon 为例, 以下为效果图: 1.根据关键词搜索指 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
随机推荐
- 暑假自学java第十一天
1,使用java.util.Arrays类处理数组 (1 ) public static void sort(数值类型 [ ] a):对指定的数值型数组按数字升序进行排序.在数组排序中设计一个简单的冒 ...
- mysql某建表语句
CREATE TABLE `product_info`( `product_id` VARCHAR(32) NOT NULL COMMENT '主键', `product_name` VARCHAR( ...
- python 01篇
一.Pycharm 使用小tips 1.1 pycharm创建项目时,选择Python环境,不使用默认的虚拟环境 1.2 如何在pycharm中查看python版本 路径:File-Settings- ...
- WSL2:在Windows系统中开发Linux程序的又一神器
作 者:道哥,10+年的嵌入式开发老兵. 公众号:[IOT物联网小镇],专注于:C/C++.Linux操作系统.应用程序设计.物联网.单片机和嵌入式开发等领域. 公众号回复[书籍],获取 Linux. ...
- CentOS 命令提示符
命令提示符的设置就是对PS1的配置: export PS1="\[\e[35;40m\][\[\e[32;40m\]\u\[\e[37;40m\]@\[\e[36;40m\]\h \[\e ...
- python -- 程序异常与调试(识别异常)
一.识别异常 程序中出现的错误又称为异常.异常通常分为两大类:编译错误和运行错误. 如下源码是已经修改: # -----------------------------------------# 编程 ...
- 你有没有乱用“leader”,担当是个好东西
PS:此文为个人认知,不足处请多多批评. 近期在一线leader(经理)身上发现了几个case,然后又回想起前几年自己做的一些傻事,可能都属于明面上leader不会说什么,但私下会有情绪的类型: Ca ...
- java String转List<Device>集合
// 从Redis中获得正常设备的数量 String success = redisService.get(RedisKey.CULTIVATION_RECORD_SUCCESS); //建立一个li ...
- JAVA学习笔记之基础概念(一)
一.Java 简介: Java 是由 Sun Microsystems 公司于 1995 年 5 月推出的 Java 面向对象程序设计语言和 Java 平台的总称. 由 James Gosling和同 ...
- 爬取千千小说 -- xpath
今天以其中一本小说为例,讲一下下载小说的主体部分,了解正常的爬取步骤,用到的是request和xpath. 爬取数据三步走:访问url -->爬取数据 -->保存数据 一.访问千千小说网址 ...