#使用C#winform编写渗透测试工具--子域名挖掘
使用C#winform编写渗透测试工具--子域名挖掘
这篇文章主要介绍使用C#winform编写渗透测试工具--子域名挖掘。在渗透测试中,子域名的收集十分重要,通常一个网站的主站的防御能力特别强,而他们的非主站相对较弱,我们便可以通过收集子站信息从而扩大攻击范围,增大渗透的可能。
- 下面是使用C#winform编写的渗透测试工具,前面我们已经完成了端口扫描、敏感目录扫描和暴力破解的工作,这一部分将介绍如何实现子域名挖掘。

目录
- 各种子域名挖掘技术
- 代码实现
- 使用步骤
一、各种子域名挖掘技术
字典爆破
- 字典爆破就是通过收集来的字典,拼接到顶级域名前面,然后通过自动化工具进行访问,判断返回结果,从而跑出子域名是否存在。比如ESD,subDomainsBrute。
证书SSL查询
- 因为SSL证书支持证书透明度,而SSL里包含子域名。证书SSL查询就是通过HTTPS 证书,ssl证书等搜集子域名记录。比如网站cet就是从SSL证书收集子域名。
DNS数据
- DNS原理就是搜集DNS的解析历史,通过查询dns记录来获取到对方的解析记录,从而获取到子域名,正常来说你的域名经DNS解析过一般就会搜到。比如virustotal执行DNS解析来构建数据库,来检索子域名。
爬虫提取子域名(js文件提取)
- 利用爬虫从页面源代码中提取子域名,比如JSFinder。
二、代码实现
这里分别使用两种方式实现子域名的挖掘,即通过证书SSL查询和js文件提取。
1.使用证书SSL查询方式
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import urllib.request
import urllib.parse
import re
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
def crt_domain(domains):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
with urllib.request.urlopen('https://crt.sh/?q=' + domains) as f:
code = f.read().decode('utf-8')
for cert, domain in re.findall('<tr>(?:\s|\S)*?href="\?id=([0-9]+?)"(?:\s|\S)*?<td>([*_a-zA-Z0-9.-]+?\.' + re.escape(domains) + ')</td>(?:\s|\S)*?</tr>', code, re.IGNORECASE):
domain = domain.split('@')[-1]
print(domain)
with open('crt_result.txt', 'a+') as f:
f.write(str(domain)+'\n')
if __name__ == '__main__':
if len(sys.argv) == 2:
domains=sys.argv[1]
crt_domain(domains[11:])
else:
print('User: python3 crt_domain.py domain')
C#调用脚本
对于python脚本中包含第三方模块的情况,同样,通过直接创建Process进程,调用python脚本,返回扫描结果。
- 创建按钮按下事件button1_Click,运行“调用python脚本”函数runPythonSubdomain_ssl()
private void button9_Click(object sender, EventArgs e)
{
richTextBox4.Clear();
runPythonSubdomain_ssl();//运行python函数
label22.Text = "开始扫描...";
}
- 实例化一个python进程 调用.py 脚本
void runPythonSubdomain_ssl()
{
string url = textBox9.Text;
p = new Process();
string path = "Subdomain.py";//待处理python文件的路径,本例中放在debug文件夹下
string sArguments = path;
ArrayList arrayList = new ArrayList();
arrayList.Add(url);//需要挖掘的域名
foreach (var param in arrayList)//拼接参数
{
sArguments += " " + param;
}
p.StartInfo.FileName = @"D:\Anaconda\python.exe"; //没有配环境变量的话,可以写"xx\xx\python.exe"的绝对路径。如果配了,直接写"python"即可
p.StartInfo.Arguments = sArguments;//python命令的参数
p.StartInfo.UseShellExecute = false;
p.StartInfo.RedirectStandardOutput = true;
p.StartInfo.RedirectStandardInput = true;
p.StartInfo.RedirectStandardError = true;
p.StartInfo.CreateNoWindow = true;
p.StartInfo.WindowStyle = ProcessWindowStyle.Hidden;
p.Start();//启动进程
//MessageBox.Show("启动成功");
p.BeginOutputReadLine();
p.OutputDataReceived += new DataReceivedEventHandler(p_OutputDataReceived_subdomain_ssl);
Console.ReadLine();
//p.WaitForExit();
}
void p_OutputDataReceived_subdomain_ssl(object sender, DataReceivedEventArgs e)
{
var printedStr = e.Data;
Action at = new Action(delegate ()
{
//接受.py进程打印的字符信息到文本显示框
richTextBox4.AppendText(printedStr + "\n");
label22.Text = "扫描结束";
});
Invoke(at);
}
2.使用js文件提取
#!/usr/bin/env python"
# coding: utf-8
import requests, argparse, sys, re
from requests.packages import urllib3
from urllib.parse import urlparse
from bs4 import BeautifulSoup
def parse_args():
parser = argparse.ArgumentParser(epilog='\tExample: \r\npython ' + sys.argv[0] + " -u http://www.baidu.com")
parser.add_argument("-u", "--url", help="The website")
parser.add_argument("-c", "--cookie", help="The website cookie")
parser.add_argument("-f", "--file", help="The file contains url or js")
parser.add_argument("-ou", "--outputurl", help="Output file name. ")
parser.add_argument("-os", "--outputsubdomain", help="Output file name. ")
parser.add_argument("-j", "--js", help="Find in js file", action="store_true")
parser.add_argument("-d", "--deep",help="Deep find", action="store_true")
return parser.parse_args()
def extract_URL(JS):
pattern_raw = r"""
(?:"|') # Start newline delimiter
(
((?:[a-zA-Z]{1,10}://|//) # Match a scheme [a-Z]*1-10 or //
[^"'/]{1,}\. # Match a domainname (any character + dot)
[a-zA-Z]{2,}[^"']{0,}) # The domainextension and/or path
|
((?:/|\.\./|\./) # Start with /,../,./
[^"'><,;| *()(%%$^/\\\[\]] # Next character can't be...
[^"'><,;|()]{1,}) # Rest of the characters can't be
|
([a-zA-Z0-9_\-/]{1,}/ # Relative endpoint with /
[a-zA-Z0-9_\-/]{1,} # Resource name
\.(?:[a-zA-Z]{1,4}|action) # Rest + extension (length 1-4 or action)
(?:[\?|/][^"|']{0,}|)) # ? mark with parameters
|
([a-zA-Z0-9_\-]{1,} # filename
\.(?:php|asp|aspx|jsp|json|
action|html|js|txt|xml) # . + extension
(?:\?[^"|']{0,}|)) # ? mark with parameters
)
(?:"|') # End newline delimiter
"""
pattern = re.compile(pattern_raw, re.VERBOSE)
result = re.finditer(pattern, str(JS))
if result == None:
return None
js_url = []
return [match.group().strip('"').strip("'") for match in result
if match.group() not in js_url]
# 发送请求
def Extract_html(URL):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36",
"Cookie": args.cookie}
try:
raw = requests.get(URL, headers = header, timeout=3, verify=False)
raw = raw.content.decode("utf-8", "ignore")
return raw
except:
return None
# 处理url
def process_url(URL, re_URL):
black_url = ["javascript:"] # Add some keyword for filter url.
URL_raw = urlparse(URL)
ab_URL = URL_raw.netloc
host_URL = URL_raw.scheme
if re_URL[0:2] == "//":
result = host_URL + ":" + re_URL
elif re_URL[0:4] == "http":
result = re_URL
elif re_URL[0:2] != "//" and re_URL not in black_url:
if re_URL[0:1] == "/":
result = host_URL + "://" + ab_URL + re_URL
else:
if re_URL[0:1] == ".":
if re_URL[0:2] == "..":
result = host_URL + "://" + ab_URL + re_URL[2:]
else:
result = host_URL + "://" + ab_URL + re_URL[1:]
else:
result = host_URL + "://" + ab_URL + "/" + re_URL
else:
result = URL
return result
def find_last(string,str):
positions = []
last_position=-1
while True:
position = string.find(str,last_position+1)
if position == -1:break
last_position = position
positions.append(position)
return positions
def find_by_url(url, js = False):
if js == False:
try:
print("url:" + url)
except:
print("Please specify a URL like https://www.baidu.com")
html_raw = Extract_html(url)
if html_raw == None:
print("Fail to access " + url)
return None
#print(html_raw)
html = BeautifulSoup(html_raw, "html.parser")
html_scripts = html.findAll("script")
script_array = {}
script_temp = ""
for html_script in html_scripts:
script_src = html_script.get("src")
if script_src == None:
script_temp += html_script.get_text() + "\n"
else:
purl = process_url(url, script_src)
script_array[purl] = Extract_html(purl)
script_array[url] = script_temp
allurls = []
for script in script_array:
#print(script)
temp_urls = extract_URL(script_array[script])
if len(temp_urls) == 0: continue
for temp_url in temp_urls:
allurls.append(process_url(script, temp_url))
result = []
for singerurl in allurls:
url_raw = urlparse(url)
domain = url_raw.netloc
positions = find_last(domain, ".")
miandomain = domain
if len(positions) > 1:miandomain = domain[positions[-2] + 1:]
#print(miandomain)
suburl = urlparse(singerurl)
subdomain = suburl.netloc
#print(singerurl)
if miandomain in subdomain or subdomain.strip() == "":
if singerurl.strip() not in result:
result.append(singerurl)
return result
return sorted(set(extract_URL(Extract_html(url)))) or None
def find_subdomain(urls, mainurl):
url_raw = urlparse(mainurl)
domain = url_raw.netloc
miandomain = domain
positions = find_last(domain, ".")
if len(positions) > 1:miandomain = domain[positions[-2] + 1:]
subdomains = []
for url in urls:
suburl = urlparse(url)
subdomain = suburl.netloc
#print(subdomain)
if subdomain.strip() == "": continue
if miandomain in subdomain:
if subdomain not in subdomains:
subdomains.append(subdomain)
return subdomains
def find_by_url_deep(url):
html_raw = Extract_html(url)
if html_raw == None:
print("Fail to access " + url)
return None
html = BeautifulSoup(html_raw, "html.parser")
html_as = html.findAll("a")
links = []
for html_a in html_as:
src = html_a.get("href")
if src == "" or src == None: continue
link = process_url(url, src)
if link not in links:
links.append(link)
if links == []: return None
print("ALL Find " + str(len(links)) + " links")
urls = []
i = len(links)
for link in links:
temp_urls = find_by_url(link)
if temp_urls == None: continue
print("Remaining " + str(i) + " | Find " + str(len(temp_urls)) + " URL in " + link)
for temp_url in temp_urls:
if temp_url not in urls:
urls.append(temp_url)
i -= 1
return urls
def find_by_file(file_path, js=False):
with open(file_path, "r") as fobject:
links = fobject.read().split("\n")
if links == []: return None
print("ALL Find " + str(len(links)) + " links")
urls = []
i = len(links)
for link in links:
if js == False:
temp_urls = find_by_url(link)
else:
temp_urls = find_by_url(link, js=True)
if temp_urls == None: continue
print(str(i) + " Find " + str(len(temp_urls)) + " URL in " + link)
for temp_url in temp_urls:
if temp_url not in urls:
urls.append(temp_url)
i -= 1
return urls
def giveresult(urls, domian):
if urls == None:
return None
print("Find " + str(len(urls)) + " URL:")
content_url = ""
content_subdomain = ""
for url in urls:
content_url += url + "\n"
print(url)
subdomains = find_subdomain(urls, domian)
print("\nFind " + str(len(subdomains)) + " Subdomain:")
for subdomain in subdomains:
content_subdomain += subdomain + "\n"
print(subdomain)
if args.outputurl != None:
with open(args.outputurl, "a", encoding='utf-8') as fobject:
fobject.write(content_url)
print("\nOutput " + str(len(urls)) + " urls")
print("Path:" + args.outputurl)
if args.outputsubdomain != None:
with open(args.outputsubdomain, "a", encoding='utf-8') as fobject:
fobject.write(content_subdomain)
print("\nOutput " + str(len(subdomains)) + " subdomains")
print("Path:" + args.outputsubdomain)
if __name__ == "__main__":
urllib3.disable_warnings()
args = parse_args()
if args.file == None:
if args.deep is not True:
urls = find_by_url(args.url)
giveresult(urls, args.url)
else:
urls = find_by_url_deep(args.url)
giveresult(urls, args.url)
else:
if args.js is not True:
urls = find_by_file(args.file)
giveresult(urls, urls[0])
else:
urls = find_by_file(args.file, js = True)
giveresult(urls, urls[0])
C#调用脚本
- 创建按钮按下事件button1_Click,运行“调用python脚本”函数runPythonSubdomain_js()
private void button10_Click(object sender, EventArgs e)
{
richTextBox5.Clear();
runPythonSubdomain_js();//运行python函数
label24.Text = "开始扫描...";
}
- 实例化一个python进程 调用.py 脚本
void runPythonSubdomain_js()
{
string url = textBox9.Text;
p = new Process();
string path = "JSFinder.py";//待处理python文件的路径,本例中放在debug文件夹下
string sArguments = path;
ArrayList arrayList = new ArrayList();
arrayList.Add("-u");
arrayList.Add(url);//需要挖掘的域名
foreach (var param in arrayList)//拼接参数
{
sArguments += " " + param;
}
p.StartInfo.FileName = @"D:\Anaconda\python.exe"; //没有配环境变量的话,可以写"xx\xx\python.exe"的绝对路径。如果配了,直接写"python"即可
p.StartInfo.Arguments = sArguments;//python命令的参数
p.StartInfo.UseShellExecute = false;
p.StartInfo.RedirectStandardOutput = true;
p.StartInfo.RedirectStandardInput = true;
p.StartInfo.RedirectStandardError = true;
p.StartInfo.CreateNoWindow = true;
p.StartInfo.WindowStyle = ProcessWindowStyle.Hidden;
p.Start();//启动进程
//MessageBox.Show("启动成功");
p.BeginOutputReadLine();
p.OutputDataReceived += new DataReceivedEventHandler(p_OutputDataReceived_subdomain_js);
Console.ReadLine();
//p.WaitForExit();
}
void p_OutputDataReceived_subdomain_js(object sender, DataReceivedEventArgs e)
{
var printedStr = e.Data;
Action at = new Action(delegate ()
{
//接受.py进程打印的字符信息到文本显示框
richTextBox5.AppendText(printedStr + "\n");
label24.Text = "扫描结束";
});
Invoke(at);
}
}
}
三、使用步骤
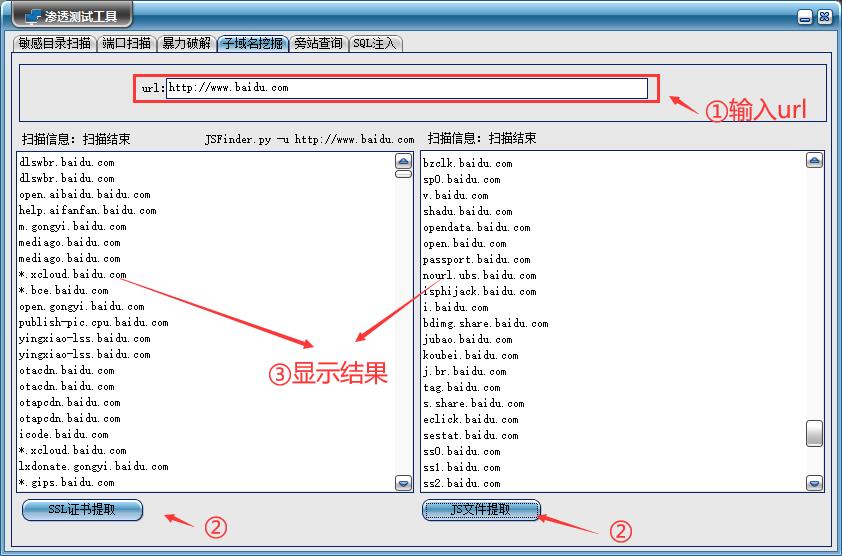
- 首先在url栏中输入地址,接着可以选择是使用ssl证书提取或者Js文件提取的方式进行挖掘,最后得到子域名信息。
github地址:https://github.com/Chenmengx/Penetration-testing-tool
#使用C#winform编写渗透测试工具--子域名挖掘的更多相关文章
- 使用C#winform编写渗透测试工具--敏感目录扫描
使用C#winform编写渗透测试工具--敏感目录扫描 由于之前在做渗透测试的时候,发现使用的工具较多,切换起来较麻烦,便萌生了开发一个包含各种渗透测试工具的小程序,包括敏感目录扫描.端口查询.子域名 ...
- 使用C#winform编写渗透测试工具--暴力破解
使用C#winform编写渗透测试工具--暴力破解 这篇文章主要介绍使用C#winform编写渗透测试工具--暴力破解.暴力破解是指通过利用大量猜测和穷举的方式来尝试获取用户口令的攻击方式.简单来说就 ...
- 使用C#winform编写渗透测试工具--端口扫描
使用C#winform编写渗透测试工具--端口扫描器 主要介绍使用C#winform编写渗透测试工具--端口扫描器,端口扫描器则是一种检测服务器或者主机虚拟端口是开启或关闭的工具.由于连接到局域网或互 ...
- 使用C#winform编写渗透测试工具--Web指纹识别
使用C#winform编写渗透测试工具--web指纹识别 本篇文章主要介绍使用C#winform编写渗透测试工具--Web指纹识别.在渗透测试中,web指纹识别是信息收集关键的一步,通常是使用各种工具 ...
- 使用C#winform编写渗透测试工具--SQL注入
使用C#winform编写渗透测试工具--SQL注入 本篇文章主要介绍使用C#winform编写渗透测试工具,实现SQL注入的功能.使用python编写SQL注入脚本,基于get显错注入的方式进行数据 ...
- github渗透测试工具库
本文作者:Yunying 原文链接:https://www.cnblogs.com/BOHB-yunying/p/11856178.html 导航: 2.漏洞练习平台 WebGoat漏洞练习平台: h ...
- github渗透测试工具库[转载]
前言 今天看到一个博客里有这个置顶的工具清单,但是发现这些都是很早以前就有文章发出来的,我爬下来后一直放在txt里吃土.这里一起放出来. 漏洞练习平台 WebGoat漏洞练习平台:https://gi ...
- 渗透测试工具SQLmap
一.简介 SQLmap 是一款用 Python 编写的开源渗透测试工具,用来自动检测和利用 SQL 注入漏洞. 二.Windows 下安装 2.1 安装 Python 环境 注:Python 3.0会 ...
- 渗透测试工具BurpSuite做网站的安全测试(基础版)
渗透测试工具BurpSuite做网站的安全测试(基础版) 版权声明:本文为博主原创文章,未经博主允许不得转载. 学习网址: https://t0data.gitbooks.io/burpsuite/c ...
随机推荐
- Qt实现网络聊天室(客户端,服务端)
1. 效果演示 客户端 服务器 连接成功之后 2. 预备知识 如果不知道网络编程的可以去看我的上一篇文章C++网络编程 在Qt中,实现网络编程的方式比用C++或C实现要方便简单许多,因为Qt已经替我们 ...
- delphi xe 10.3 利用Git组群开发,Git服务器安装,Git 拉取,提交,推送相关设置操作
1. Git服务器安装, 参考 https://blog.csdn.net/u012842630/article/details/97175397 Git服务器官方网站,要FQ. 2. 工具软件 gi ...
- react 中的PropTypes与DefaultProps
每个组件都有自己的props参数,这参数是从父组件接收的一些属性.那我们应该如何对参数的类型做校验,如何定义参数的默认值呢? 1.使用PropTypes校验父组件传过来的参数是否合法 import P ...
- CapsuleAO实现的学习
正是一个炎夏,又到了整活的好时候.最近抽些时间研究下CapsuleAO,记述实践体会. 1.简介 这是一个通过在角色骨骼上绑定虚拟胶囊体并以数学方法实现胶囊近似的AO环境光遮蔽效果的方法, 当角色处于 ...
- IDEA搭建一个SpringBoot项目——十分详细(web+mysql)
前排提示: IDEA版本:IntelliJ IDEA 2021.1.1 专业版(是否为专业版影响不大) 搭建目的:前端web页面能够获取到MySQL数据库中的数据 详细步骤: 1. 创建一个新项目 ...
- 【原创】SystemVerilog中的多态和虚方法
封装可以隐藏实现细节,使代码模块化,继承可以扩展已经存在的代码模块,目的都是为了代码重用.多态是为了实现接口的重用.在SystemVerilog中,子类和父类之间多个子程序使用同一个名字的现象称为Sy ...
- MobileNet系列之MobileNet_v2
MobileNet系列之MobileNet_v1 Inception系列之Inception_v1 Inception系列之Batch Normalization Inception系列之Ince ...
- 温故知新,.Net Core遇见Consul(HashiCorp),实践分布式服务注册与发现
什么是Consul 参考 https://www.consul.io https://www.hashicorp.com 使用Consul做服务发现的若干姿势 ASP.NET Core 发布之后通过命 ...
- VS 2017 RC .net core ef+ MySql 出现错误
在di注入时会出现错误 MySql.Data.EntityFrameworkCore.Storage.Internal.MySQLCommandBuilderFactory..ctor(ISensit ...
- 12、elk的使用(1)
12.0.架构图: 服务器名称 ip地址 controller-node1(主) 172.16.1.90 slave-node1(从) 172.16.1.91 12.1.elk介绍: (1)ELK是三 ...