LetNet、Alex、VggNet分析及其pytorch实现
简单分析一下主流的几种神经网络
LeNet
LetNet作为卷积神经网络中的HelloWorld,它的结构及其的简单,1998年由LeCun提出
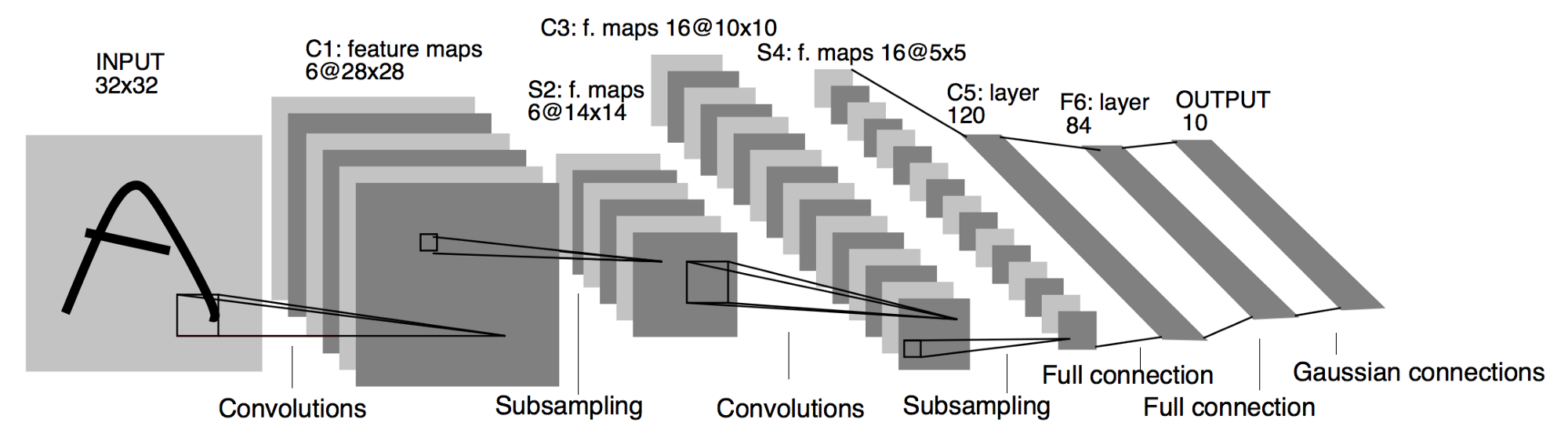
基本过程:
可以看到LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。
代码:
import torch.nn as nn
import torch
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
layer1 = nn.Sequential()
# Convolution with 5x5 kernel+2padding:28×28×6
layer1.add_module('conv1', nn.Conv2d(1, 6, kernel_size=(3, 3), padding=1))
# Pool with 2x2 average kernel+2 stride:14×14×6
layer1.add_module('pool1', nn.MaxPool2d(kernel_size=2))
self.layer1 = layer1
layer2 = nn.Sequential()
# Convolution with 5x5 kernel (no pad):10×10×16
layer2.add_module('conv2', nn.Conv2d(6, 16, kernel_size=(5, 5)))
# Pool with 2x2 average kernel+2 stride: 5x5×16
layer2.add_module('pool2', nn.MaxPool2d(kernel_size=2))
self.layer2 = layer2
layer3 = nn.Sequential()
# 5 = ((28/2)-4)/2
layer3.add_module('fc1', nn.Linear(16 * 5 * 5, 120))
layer3.add_module('fc2', nn.Linear(120, 84))
layer3.add_module('fc3', nn.Linear(84, 10))
self.layer3 = layer3
def forward(self, x):
x = self.layer1(x)
# print(x.size())
x = self.layer2(x)
# print(x.size())
# 展平x
x = torch.flatten(x, 1)
x = self.layer3(x)
return x
# 测试
test_data = torch.rand(1, 1, 28, 28)
model = LeNet()
model(test_data)
输出
tensor([[ 0.0067, -0.0431, 0.1072, 0.1275, 0.0143, 0.0865, -0.0490, -0.0936,
-0.0315, -0.0367]], grad_fn=<AddmmBackward0>)
AlexNet
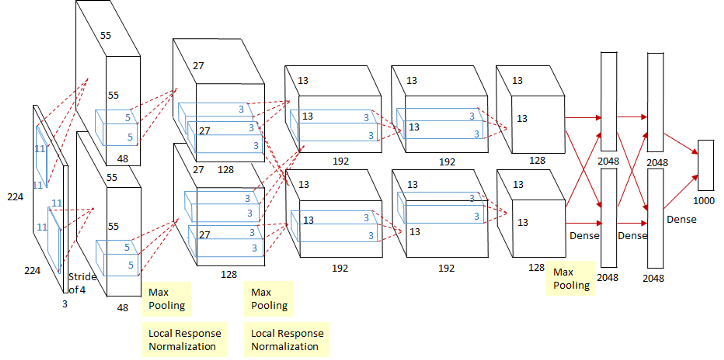
这个图看起来稍微可能有亿点复杂,其实这个是因为当时的GPU计算能力不太行,而Alex又比较复杂,所以Alex使用了两个GPU并行来做运算,现在已经完全可以用一个GPU来代替了。
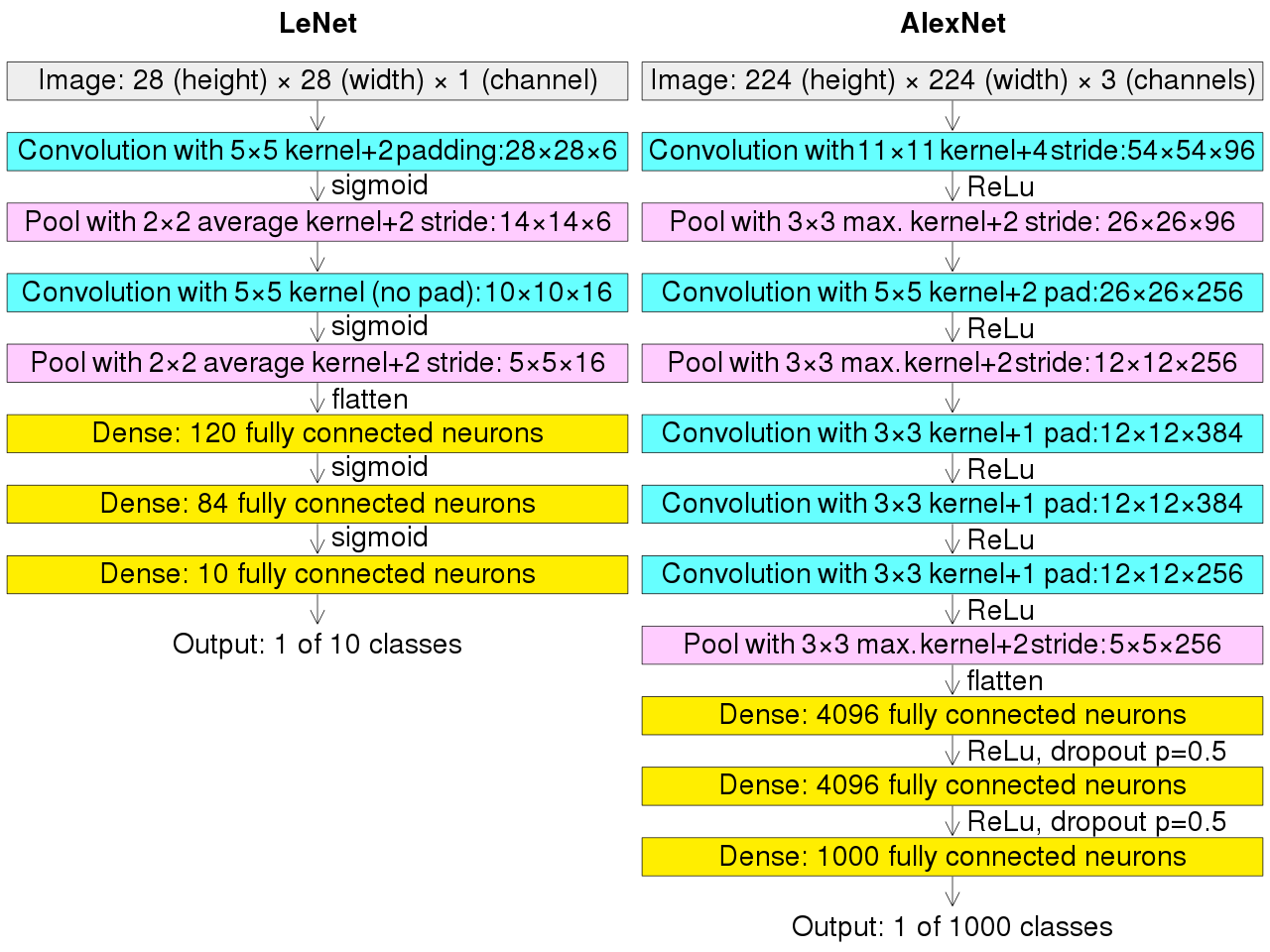
相对于LeNet来说,Alex网络层数更深,同时第一次引入了激活层ReLU,又在全连接层引入了Dropout层防止过拟合。
执行流程图在上面,跟LeNet的执行流程图放在一张图上。
代码:
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_class):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4)),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=(5, 5), padding=2),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(384, 256, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256*5*5, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096, num_class)
)
def forward(self, x):
x = self.features(x)
print(x.size())
x = x.view(x.size(0), 256 * 5 * 5)
x = self.classifier(x)
return x
# 测试
test_data = torch.rand(1, 3, 224, 224)
model = AlexNet(10)
model(test_data)
输出:
torch.Size([1, 256, 5, 5])
tensor([[-0.0044, 0.0114, 0.0032, -0.0099, 0.0035, -0.0024, 0.0103, -0.0194,
0.0149, 0.0094]], grad_fn=<AddmmBackward0>)
VggNet
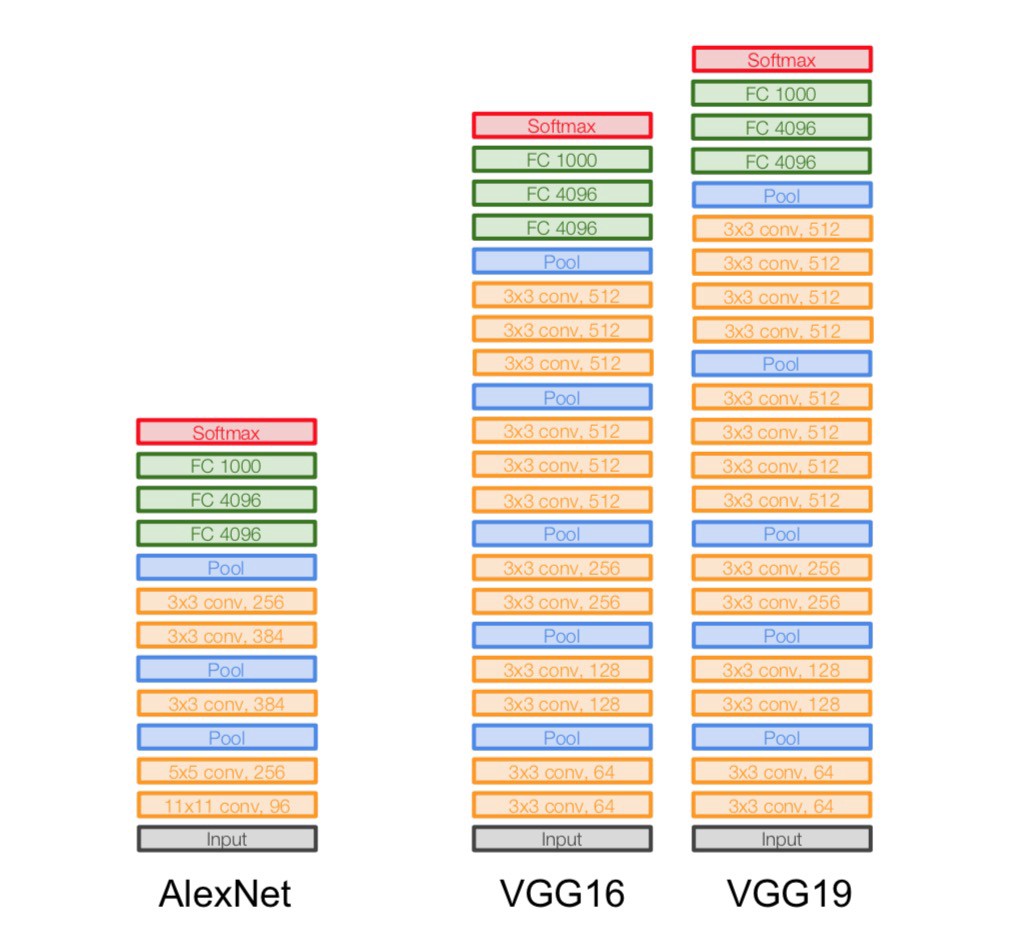
VggNet是ImageNet 2014年的亚军,总的来说就是它使用了更小的滤波器,用了更深的结构来提升深度学习的效果,从图里面可以看出来这一点,它没有使用11*11这么大的滤波器,取而代之的使用的都是3*3这种小的滤波器,它之所以使用很多小的滤波器,是因为层叠很多小的滤波器的感受野和一个大的滤波器的感受野是相同的,还能减少参数。
代码实现:
import torch.nn as nn
class VGG(nn.Module):
def __init__(self, num_class):
super(VGG, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=(3, 3), padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096), nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096), nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
使用卷积神经网络实现对Minist数据集的预测
代码:
import matplotlib.pyplot as plt
import torch.utils.data
import torchvision.datasets
import os
import torch.nn as nn
from torchvision import transforms
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3, 3)),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=(3, 3)),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(3, 3)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3)),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])]
)
train_dataset = torchvision.datasets.MNIST(root='F:/机器学习/pytorch/书/data/mnist', train=True,
transform=data_tf, download=True)
test_dataset = torchvision.datasets.MNIST(root='F:/机器学习/pytorch/书/data/mnist', train=False,
transform=data_tf, download=True)
batch_size = 100
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size
)
model = CNN()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
criterion = criterion.cuda()
optimizer = torch.optim.Adam(model.parameters())
# 节约时间,三次够了
iter_step = 3
loss1 = []
loss2 = []
for step in range(iter_step):
loss1_count = 0
loss2_count = 0
for images, labels in train_loader:
images = images.cuda()
labels = labels.cuda()
images = images.reshape(-1, 1, 28, 28)
output = model(images)
pred = output.squeeze()
optimizer.zero_grad()
loss = criterion(pred, labels)
loss.backward()
optimizer.step()
_, pred = torch.max(pred, 1)
loss1_count += int(torch.sum(pred == labels)) / 100
# 测试
else:
test_loss = 0
accuracy = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.cuda()
labels = labels.cuda()
pred = model(images.reshape(-1, 1, 28, 28))
_, pred = torch.max(pred, 1)
loss2_count += int(torch.sum(pred == labels)) / 100
loss1.append(loss1_count / len(train_loader))
loss2.append(loss2_count / len(test_loader))
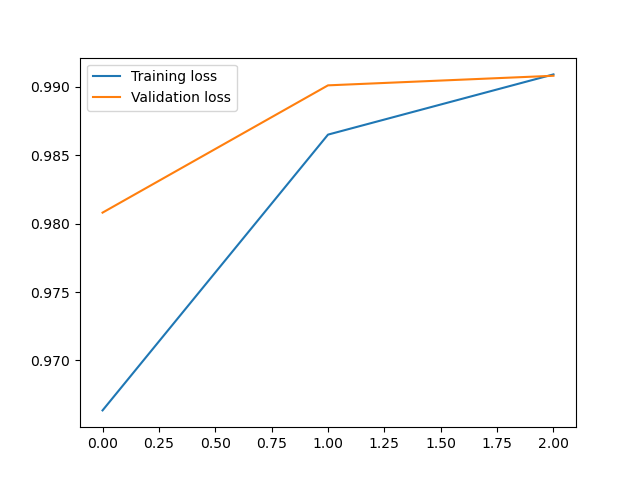
print(f'第{step}次训练:训练准确率:{loss1[len(loss1)-1]},测试准确率:{loss2[len(loss2)-1]}')
plt.plot(loss1, label='Training loss')
plt.plot(loss2, label='Validation loss')
plt.legend()
输出:
第0次训练:训练准确率:0.9646166666666718,测试准确率:0.9868999999999996
第1次训练:训练准确率:0.9865833333333389,测试准确率:0.9908999999999998
第2次训练:训练准确率:0.9917000000000039,测试准确率:0.9879999999999994
<matplotlib.legend.Legend at 0x21f03092fd0>
LetNet、Alex、VggNet分析及其pytorch实现的更多相关文章
- DARTS代码分析(Pytorch)
最近在看DARTS的代码,有一个operations.py的文件,里面是对各类点与点之间操作的方法. OPS = { 'none': lambda C, stride, affine: Zero(st ...
- 【小白学PyTorch】12 SENet详解及PyTorch实现
文章来自微信公众号[机器学习炼丹术].我是炼丹兄,有什么问题都可以来找我交流,近期建立了微信交流群,也在朋友圈抽奖赠书十多本了.我的微信是cyx645016617,欢迎各位朋友. 参考目录: @ 目录 ...
- 使用PyTorch构建神经网络以及反向传播计算
使用PyTorch构建神经网络以及反向传播计算 前一段时间南京出现了疫情,大概原因是因为境外飞机清洁处理不恰当,导致清理人员感染.话说国外一天不消停,国内就得一直严防死守.沈阳出现了一例感染人员,我在 ...
- cs231n --- 3 : Convolutional Neural Networks (CNNs / ConvNets)
CNN介绍 与之前的神经网络不同之处在于,CNN明确指定了输入就是图像,这允许我们将某些特征编码到CNN的结构中去,不仅易于实现,还能极大减少网络的参数. 一. 结构概述 与一般的神经网络不同,卷积神 ...
- 路飞学城-Python开发集训-第3章
学习心得: 通过这一章的作业,使我对正则表达式的使用直接提升了一个level,虽然作业完成的不怎么样,重复代码有点多,但是收获还是非常大的,有点找到写代码的感觉了,遗憾的是,这次作业交过,这次集训就结 ...
- day03.2-内置函数的使用
1. 取绝对值函数,abs() res = abs(-1) print(res) """ 运行结果:1 结果分析:计算-1的绝对值 """ ...
- day03.1-函数编程
python中函数的定义: def test (x,y): "The function definitions" z = x**y return z ""&qu ...
- [Python自学] day-16 (JS、作用域、DOM、事件)
一.JS中的三种函数 1.普通函数 function func(){ console.log("Hello World"); } func() 2.匿名函数 setInterval ...
- python3.x 基础三:装饰器
装饰器:本质是函数,用于装饰其他函数,在不改变其他函数的调用和代码的前提下,增加新功能 原则: 1.不能修改被装饰函数的源代码 2.不能修改被装饰函数的调用方式 3.装饰函数对于被装饰函数透明 参考如 ...
随机推荐
- python 处理xml 数据
1 import xml.sax 2 import xml.sax.handler 3 4 # python 处理xml 数据 类,将xml数据转化为字典 5 ''' 6 原数据:<?xml v ...
- Linux下向windows传输文件【sz 文件】没有弹框提示下载到什么位置
Linux环境向windows环境传输文件 security crt工具,同同一个软件,连接不同服务器,有的服务器传送文件没有弹框选择要下载的文件路径,可以在[Options]-[Session Op ...
- 【编译原理】LL1文法语法分析器
上篇文章[编译原理]语法分析--自上向下分析 分析了LL1语法,文章最后说给出栗子,现在补上去. 说明: 这个语法分析器是利用LL1分析方法实现的. 预测分析表和终结符以及非终结符都是针对一个特定文法 ...
- SimpleNVR流媒体服务在多分屏直播实时阅览时所遇到问题的解决
视频有一个流的概念,称为流媒体.当大量的客户端或WEB访问监控摄像机的时候,大多数的录像机无法承受那么大的网络压力,这时候SimpleNVR流媒体服务器的优势就显示出来了.其能将客户端的访问压力转到服 ...
- VSCode Java 开发环境配置 详细教程
VSCode Java 开发环境配置 详细教程 配置java 下载 用于现在大多数使用者用的是java 8,小白的我先安装java 8好了,^ w ^. 下载地址:Java 8 | Java SE 打 ...
- 模块化开发 | es6模块暴露与引入
CommonJS模块开发 CommonJS定义 每个文件就一个模块,有自己的作用域.在一个文件里面定义的变量.函数.类,都是私有的,对其他文件不可见. 私有作用域不会污染全局作用域. 模块可加载多次, ...
- MySQL:由于找不到VCRUNTIME140_1.dll,无法继续执行代码。重新安装程序可能会解决此问题
我只是搬用工,记录一下 方法一: 安装这个微软常用运行库合集(https://www.repaik.com/), 链接:https://pan.baidu.com/s/1r4JJaUKjw-y1g3l ...
- Javafx-【直方图】文本频次统计工具 中文/英文单词统计
上周倒腾了下 javafx,本来是做平时成绩系统.跟老师提了一下 javafx,他突然兴起,发了个统计中文和英文单词并以直方图显示的实验......只给两三天的期限,笑着说考验我们的潜力SOS,于是带 ...
- PTA甲级1094 The Largest Generation (25分)
PTA甲级1094 The Largest Generation (25分) A family hierarchy is usually presented by a pedigree tree wh ...
- MnogoDB唯一索引,稀疏索引
1,单个字段唯一索引 db.collection.createIndex({name:1},{unique:true} 2,多个字段联合索引示例 db.collection.createIndex({ ...