javaSE高级篇2 — 流技术 — 更新完毕
1、先认识一个类————File类
前言:IO相关的一些常识
- I / O————输入输出
- I 输入 input
- 0 输出 output
- I / o 按数据的流动方向来分————流动方向:指的是计算机的数据流动————其实这个是有参考系的,如:如果说想要把一个数据弄到主存中来,那我所处的角度(位置)就是主存,数据就只是我的目标,因此:这时读数据就是input(从另外的地方把数据读进来嘛),而从本身中(主存中)把数据弄到另一个地方去,那就是output——写数据(把数据向指定地方写进去嘛)————这样就可以理解了涩
- 读数据————输入 input
- 写数据————输出 output
- 这两个东西别搞懵了,很多人在这个地方直接懵了,什么input叫读数据,什么output叫写数据的,这不是反着的吗,所以有些人学完流技术之后,搞来搞去,最后懵逼了(注意:前面我写的 “ 如: ” 中的这个例子)
- I / o按操作目标来分
- 文件流
- 字符流
- 对象流
- 网络流
- ................
- 什么是文件?
- 指的就是电脑中的一种存储形式嘛
- 如:.txt,.doc,.docx,.ppt.........这些都是文件嘛
- 什么是文件夹?
- 指的就是目录的路径涩
- 如:D:\IntallationList\MaveIntallationList,这不就指的是前面这一串儿文件夹下的MavenIntallationList这个文件夹吗,所以它就是一个目录的路径涩
- 指的就是目录的路径涩
- File类是什么?
- 首先它是一个类,在java.io包下
- 其次它和电脑上的文件产生一 一对应的“映射关系”
- 最后:这个类只是对文件本身进行操作,文件里面的数据搞不了( 但是套一层金刚伏魔圈儿就可以搞了 )——后续学了流就懂了
- 它是个类,则就有对象,这个对象就是指的文件 / 文件夹,但是:这个文件 / 文件夹并不是电脑中真实硬盘的文件 / 文件夹
- 而是指的是:“堆内存”中的一个对象,这个对象<————>映射<————>电脑中真实的文件 / 文件夹
- 它是个类,则就有对象,这个对象就是指的文件 / 文件夹,但是:这个文件 / 文件夹并不是电脑中真实硬盘的文件 / 文件夹
- File类如何创建对象?
- 通过new关键字进行创建————有方法重载,但是最常用的是下面这个
- File f = new File( String filePathName )————参数中必须跟一个电脑中真实存在的 文件 / 文件夹路径(是全路径 )————虽然不是真实的也没错,但是就当必须是真实的路径就行(养成习惯),如:
// 1、创建File对象
File file = new File( "D:\\InatallationPackage\\Mybatis\\Resources" ); // 当然这里的 \\,也可以写成 /
- File类中的一些常用方法(完整的方法集可以直接看API)
- length()————获取文件的字节大小
File file = new File("D:\\InatallationPackage\\Mybatis\\Resources"); System.out.println( file.length() );
- length()————获取文件的字节大小
- boolean = CanRead()———查看文件是否可读
// 2、查看文件是否可读
System.out.println( file.canRead() );
- boolean = CanWrite()————查看文件是否可写
// 3、查看文件是否可写
System.out.println( file.canWrite() );
- boolean = CanWrite()————查看文件是否可写
- boolean = CreatNewFile()————创建一个新文件————相比其他这个方法更常用
// 4、创建一个新文件
try { System.out.println( new File("D:/IntallationList/creatNewFile.txt").createNewFile() ); System.out.println( new File("d:/creatNewFile.txt").createNewFile() ); // 这两种创建都行
/*
注:
1、这个方法需要处理异常————抛出或捕获都行
2、创建的文件前面的路径必须是真实有效的,否则:无法创建
*/ } catch (IOException e) {
e.printStackTrace();
}
- boolean = CreatNewFile()————创建一个新文件————相比其他这个方法更常用
- boolean = delete()————删除一个文件 / 文件夹————如果删除的文件夹中还有文件 / 文件夹,则:无法删除
// 5、删除一个文件
System.out.println( new File("D:\\test\\hit-me.txt").delete() );
- boolean = delete()————删除一个文件 / 文件夹————如果删除的文件夹中还有文件 / 文件夹,则:无法删除
- boolean = exists()————查看一个文件是否存在——这个在开发中还有点用
// 6、查看一个文件是否存在
System.out.println( new File("d:/test/aaa.txt").exists() );
- boolean = exists()————查看一个文件是否存在——这个在开发中还有点用
String = getAbsolutePath()————获取文件的绝对路径——还有点用// 7、获取文件夹的绝对路径————即:文件夹的全路径
System.out.println( new File("D:\\IntallationList\\MaveIntallationList").getAbsolutePath() );
- String = getName()————获取文件的名字————也有点用
// 8、获取文件的名字————本例子中结果为:MaveIntallationList
System.out.println( new File("D:\\IntallationList\\MaveIntallationList").getName() );
- String = getName()————获取文件的名字————也有点用
- String = getParent()————获取当前文件的上一层的整个文件路径————结果是个字符串,也没多大用
// 9、获取文件的上层全路径————本例中结果为:D:\IntallationList,这个值是一个字符串
System.out.println( new File("D:\\IntallationList\\MaveIntallationList").getParent() );
- String = getParent()————获取当前文件的上一层的整个文件路径————结果是个字符串,也没多大用
- File = getParentFile()————获取当前文件的上一届的整个文件路径对象————这个就有点用了,因为:返回的是一个File对象
// 10、返回当前文件的上一层的整个文件路径的对象————本例中结果为:D:\IntallationList,但是这个值是一个File对象
System.out.println( new File("D:\\IntallationList\\MaveIntallationList").getParentFile() );
- File = getParentFile()————获取当前文件的上一届的整个文件路径对象————这个就有点用了,因为:返回的是一个File对象
- String[ ] = list()————返回指定文件夹中的所有文件 / 文件夹名 的 String类型数组————还是没多大用
// 11、返回一个文件夹中的所有文件 / 文件夹 名的 String数组
String[] fileList = new File("D:\\IntallationList").list(); for (String list : fileList) { System.out.println( list );
}
- String[ ] = list()————返回指定文件夹中的所有文件 / 文件夹名 的 String类型数组————还是没多大用
- File[] = listFiles()————返回指定文件夹中的所有文件 / 文件夹 的全路径的 File对象数组————这个才是有用的
// 12、返回指定文件夹中的所有文件 / 文件夹 的 全路径的 File对象数组
File[] files = new File("D:\\IntallationList").listFiles();
for (File f : files) { System.out.println( f );
}
- File[] = listFiles()————返回指定文件夹中的所有文件 / 文件夹 的全路径的 File对象数组————这个才是有用的
- mkdir()————创建文件夹,是文件夹,不是前面说的文件————但是:这个方法创建,必须保证要创的文件夹外面那一层文件夹是真实存在的,否则:创建不了————但是这个方法也没什么卵用
// 13、创建文件夹
System.out.println( new File("d:/test/demo").mkdir() ); // 这种好使,因为demo的上一级test是存在的
ew File("d:/test/aaa/bbb").mkdir(); // 这种就不得吃,因为bbb的上一层aaa并没有
- mkdir()————创建文件夹,是文件夹,不是前面说的文件————但是:这个方法创建,必须保证要创的文件夹外面那一层文件夹是真实存在的,否则:创建不了————但是这个方法也没什么卵用
- mkdirs()————这个才是有用的一个,上一层没有文件夹也可以帮忙创建上一层
- 对文件里面的数据进行操作————真正的IO流技术
- IO体系是咋个样的?————就下面这个样,知识好多哦!!!!
- IO体系是咋个样的?————就下面这个样,知识好多哦!!!!
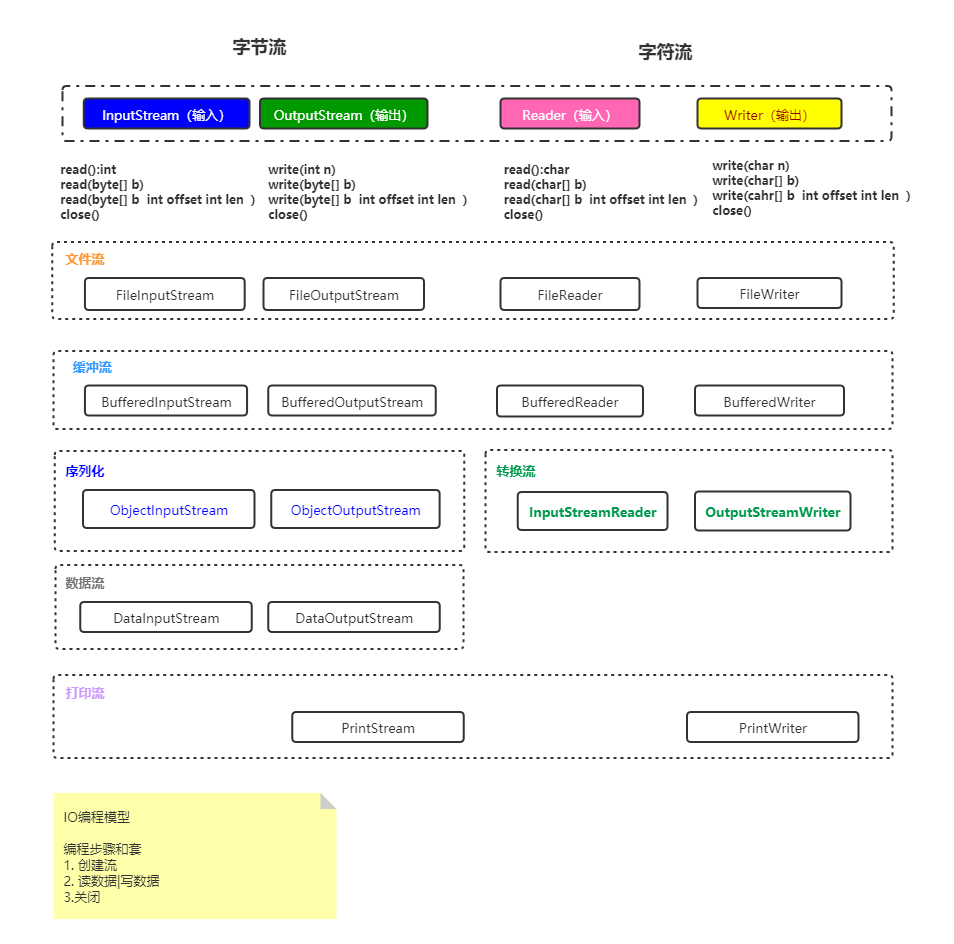
流体系学懂一个,其他的都懂了,流程都是如上图 底部中说的那样,全部流技术都是一模球儿一样的流程
- 1、文件流
- 指的是:
- 从其他地方读取文件的信息( input )
- 将信息写入其他地方的文件中( output )
- 指的是:
- 文件流分为:
- 1、字节型文件流————即:读取 / 写出是以字节形式读写文件
- FileInputStream 字节型文件输入流
- FileOutputStream 字节型文件输出流
- 1、字节型文件流————即:读取 / 写出是以字节形式读写文件
- 文件流分为:
- 2、字符型文件流————即:读取 / 写出是以字符形式读写文件
- 1、FileReader————字符型文件输入流
- 2、FileWriter————字符型文件输出流
- 2、字符型文件流————即:读取 / 写出是以字符形式读写文件
文件流的操作原理————堆内存是JVM里面的那个,在前面的知识中画过多次JVM分析图了
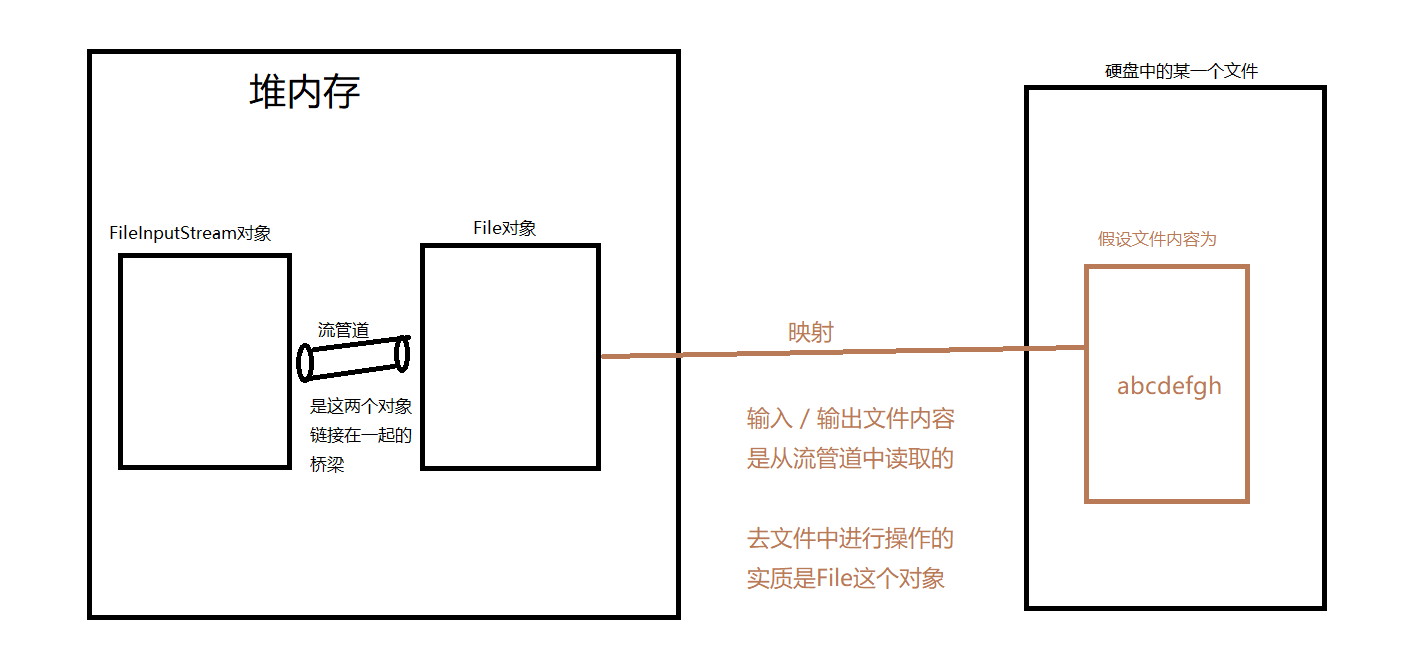
从这图中就可以看出:引入流技术的原因、
- 变量、数组、集合都是java中的类型————这是用对象进行操作内存,都存储在内存中,程序执行完毕之后,虚拟机就停止了,相应的内存中的东西就被回收了,所以这些数据都是临时存储的。而文件也可以存储很多数据,同时是存储在磁盘上的,是永久性保存
- 因此:引入流技术的原因就是
- 在文件中,虽然数据安全了,但不是在内存中,是在磁盘上的,故:无法直接进行操作,因此:引入流技术通过IO操作文件
文件流(重点)
1、字节型文件流
- 1、字节型文件输入流————FileInputStream———套个儿子
- 把一个指定地方的文件的数据读取出来
- 在java.io包下
- FileInputStream继承了InputStream类————InputStream类是字节型输入流的老爹(这是一个抽象类)
- FileInputStream怎么创建对象?
- 通过new关键字创建,但是需要传参,参数有三种方式————最常用的是下图中的前两种

try { // 1、直接利用String类型的有参构造————注意:处理异常,可以抛出,也可以捕获
FileInputStream fis = new FileInputStream( "D:\\IntallationList" ); // 2、通过套个儿子的方式创建
FileInputStream fis2 = new FileInputStream( new File("D:\\IntallationList") ); } catch (FileNotFoundException e) {
e.printStackTrace();
}
- 通过new关键字创建,但是需要传参,参数有三种方式————最常用的是下图中的前两种
- FileInputStream怎么创建对象?
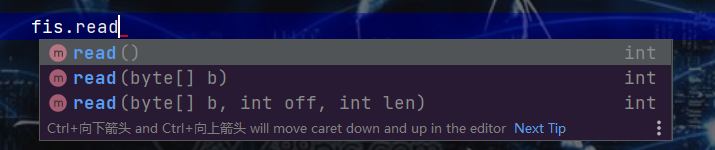
- FileInputStream类中的常用方法————这里面的方法就是真的常用了
- int = read()————指的是:每次从流管道中读取一个字节————有重载
- int = read()————指的是:每次从流管道中读取一个字节————有重载
- FileInputStream类中的常用方法————这里面的方法就是真的常用了
- 对这个方法返回值类型是 int 类型的解释————这是一个反人类的设计——以前的返回值都是指:我们传递进去的数据类型参数(如:这里的int)参与计算得出的值,即:输入型参数————而这里的int不再是我们传进去的数据类型参数参与计算得到的,而是一种输出型参数
- 1、如果是无参的这个read(),则:得到的int值表示的是——要读取的数据的下一个字节的字节码,若:读取的数据已经到了最后,则:返回-1
- 2、read( byte[ ] b , int off , int len )———题外话:off是偏移量,指的是:跳过off之前的字节,从off位置开始读取,len是指:需要读取的字节长度,即:从off开始,往后读取多少个字节
- 如果是使用的这个三个参数的方法,则:得到的int值表示的是——读取的数据的字节数,即:读取了多少个字节的数据,若是文件最后,也是返回-1
- 3、如果是使用的read( byte[ ] b )————这个方法其实调用了2中的三参方法。它得到的int值取决于两个方面
- 如果我们读取的数据长度 比 我们用来装读取出来的数据 的 容器要大,则:得到的这个int值就是这个容器的大小
- 如果我们读取的数据长度 比 我们用来装读取出来的数据 的 容器要小,则:得到的这个int值就是我们读取的数据的字节长度————对于这里所说的容器不懂的话,那就等到这个流技术最后写整个流程知识那里,就懂这里说的容器是什么了
- 同样的,如果是在文件的最后,返回的也是-1
- 对这个方法返回值类型是 int 类型的解释————这是一个反人类的设计——以前的返回值都是指:我们传递进去的数据类型参数(如:这里的int)参与计算得出的值,即:输入型参数————而这里的int不再是我们传进去的数据类型参数参与计算得到的,而是一种输出型参数
- int count = available()————查看流管道中还有多少字节
- long = skip( Long n )————就是跳过n个字节,然后再从n之后读取文件————和read( byte[ ] b , int off , int len )达到的效果一样,看情况——哪个适合用哪个
- 这个方法可以用在多线程中
- 利用几个线程同时读取一个文件
- 如:文件中有10000个字节,就可以通过5个线程去进行读取——这样效率不就很快了吗
- 1线程读取1——2000
- 2线程读取2001——4000
- 3线程读取4001——6000
- 4线程读取6001——8000
- 5线程读取8001——10000
- 如:文件中有10000个字节,就可以通过5个线程去进行读取——这样效率不就很快了吗
- 利用几个线程同时读取一个文件
- 这个方法可以用在多线程中
- long = skip( Long n )————就是跳过n个字节,然后再从n之后读取文件————和read( byte[ ] b , int off , int len )达到的效果一样,看情况——哪个适合用哪个
- void = close()————将流管道关闭————这一步在文件操作中是必须要的
- 故:这个方法就可以放在finally结构中
- 注:在把close()放在finally结构中时,应注意:代码的健壮性,所以判断要严谨
- 如:判断文件是否操作完毕了,完成了才关闭流管道,否则:就如:打开了一个文件(没关闭),但是执行删除操作一样———删不了,同理:流管道能够关闭吗?——流管道不关闭很耗内存的
- void = close()————将流管道关闭————这一步在文件操作中是必须要的
- FileInputStream流技术的操作流程的三步骤(死流程)————三板斧^ _ ^
- 创建流
- 读数据
- 关闭流管道
- 实例
import java.io.FileInputStream;
import java.io.IOException; public class Test { public static void main(String[] args) { // 1、创建流
FileInputStream fis = null;
try {
fis = new FileInputStream("D:\\InatallationPackage\\Maven\\pom.xml"); // 2、读数据
// 准备一个容器————用来装读取出来的数据
byte[] data = new byte[1024]; // 大小可以任意取,建议用这个大小
int len; // 这len是为了给read()读取的int结果 同时为了判断————注:别把这个len放在while那个判断力,会出问题
while ( ( len = fis.read( data ) ) != -1 ){ // read()读取文件
// 同时把读取出来的结果放到新建的data数组容器里。另外:这里的判断可以不写成 != -1,还可以写成 > 0 System.out.println( new String( data , 0,len ) ); // 这里可以看需求弄成其他方式,我只是为了看效果,所以打印了而已
} } catch (IOException e) { e.printStackTrace(); }finally { // 关闭流管道 // 保证代码健壮性
if ( fis != null ){ // 判断一手儿,为什么是 != nul才关闭流管道?看起来应该是fis中为null了,才说明没有内容需要读写了涩
// 别忘了 真正去进行映射操作文件的是哪个吊毛————File对象,所以这里的fis只是一个对象,它指向的是File
// 所以要是fis为null了,那不就说明fis没有引用了吗,这不就没有一个指向者了————最后也就会导致空指针异常
// 后续另外的流也是这么一个原因 try { fis.close(); // 再关闭流管道 } catch (IOException e) { e.printStackTrace();
}
}
} }
}
- 2、字节型文件输出流——FileOutputStream
- 将一些数据写入到一个指定的文件中
- 也在java.io包下
- FileOutputStream继承了OutputStream
- FileOutputStream怎么创建对象?
- 和FileInputStream一样
- 和FileInputStream一样
- FileOutputStream怎么创建对象?
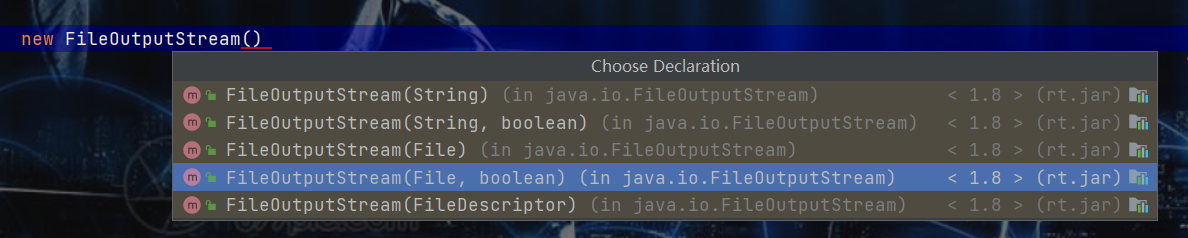
- 只是有一个地方需要注意:就是这个输出流是可以操控 是否可以追加内容的,即:上图中的第2和第4种创建方式,参数中有一个boolean类型的参数,这个参数就是表示:是否需要追加,默认是false
- 追加是什么意思?
- 就是下一次添加内容到同一个文件的时候,可以追加的话,就表示:从文件的后面接着添加内容。不可以追加的话,就表示:系统把原文件删了,然后重新创建一个和原文件名字一模一样的文件,最后再添加本次的内容
- 追加是什么意思?
- 只是有一个地方需要注意:就是这个输出流是可以操控 是否可以追加内容的,即:上图中的第2和第4种创建方式,参数中有一个boolean类型的参数,这个参数就是表示:是否需要追加,默认是false
- FileOutputStream中的常用方法
- 和FileInputStream一样,所以:不再玩儿了
- 但有一个额外的方法需要说明:
- flush()————刷新( 指的其实就是:将流管道中的数据推入【刷新】文件中去 ),这一步必须有,不然数据无法添加进文件中
- 另外:close()在这里既有关闭流管道,又有刷新的功能
- flush()————刷新( 指的其实就是:将流管道中的数据推入【刷新】文件中去 ),这一步必须有,不然数据无法添加进文件中
- FileOutputStream的使用流程是怎么样的?——还是三板斧
- 创建流
- 写数据
- 关闭流管道
实例:
import java.io.FileOutputStream;
import java.io.IOException; // 字节型文件输出流
public class TestFileOutputStream { public static void main(String[] args) { // 1、创建流
FileOutputStream fos = null;
try { fos = new FileOutputStream("d:/test/demo.txt",true); // true为:可以追加内容 // 2、写数据————想要向上面的文件中写入什么内容————利用write()方法————但是这个方法的参数是int 或 byte[]
fos.write( "这是想要写入的String类型的内容".getBytes() ); // 利用String中的getBytes()方法就把String转为 byte[]字节数组了 // 也可以在这里加上flush()————即:把2中的数据从流管道中推入文件中
fos.flush(); // 但是:不用加也可以,因为:close()在这里面有关闭流管道、刷新文件中数据的功能
} catch (IOException e) { e.printStackTrace();
}finally { // 3、关闭流管道
if ( fos != null ){ // 为了代码的健壮性,严谨判断一手儿
try { fos.close(); // 关闭流管道
} catch (IOException e) { e.printStackTrace();
}
}
}
}
}
- 利用FileInputStream 和 FileOutputStream实操一手儿
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Date;
import java.util.Scanner; /**
* 有这么一个需求:
* 1、从控制台输入
* 日记标题
* 输入正文
* 然后保存到一个文件中————要求每一篇的日记名字都不一样
*
* 2、从日记文件中读取指定名字的日记,从而在控制台显示出对应的日记内容
*/
public class Note { public static void main(String[] args) { writeNote();
readNote();
} // 录入日记
public static void writeNote() { System.out.println("请输入日记的标题:");
Scanner input = new Scanner(System.in);
String title = input.next(); System.out.println("请输入日记的正文:");
String text = input.next(); // 把控制台输入的东西 放到指定文件中去 // 1、创建输出流
FileOutputStream fos = null;
try { fos = new FileOutputStream("d:/test/note/" + new Date().getTime() + ".txt");
// 2、写数据
// 把标题写入文件中去
fos.write( "标题:".getBytes() );
fos.write(title.getBytes() );
fos.write( "\n".getBytes() ); // 换行 // 把输入的正文写入到文件中去
fos.write( "正文:".getBytes() );
fos.write( text.getBytes() ); } catch (IOException e) {
e.printStackTrace();
}finally {
// 3、关闭流管道
if ( fos != null ){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println( "录入成功" );
}
} // 读取指定名字的日记
public static void readNote() { System.out.println("请输入你想要查看的日记名:");
Scanner input = new Scanner(System.in);
String noteName = input.next();
String realName = noteName + ".txt"; // 创建输入流
FileInputStream fis = null;
try {
fis = new FileInputStream("d:/test/note/" + realName); // 读数据
byte[] text = new byte[1024];
int len;
while ( ( len = fis.read(text) ) != -1 ){ System.out.println( new String( text,0,len ) );
}
} catch (IOException e) {
e.printStackTrace();
}finally { // 关闭流管道
if ( fis != null ){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
效果图如下:

2、字符型文件流
- 1、字符型文件流——以字符的形式读取文件,通常是纯文本文件(如:txt文件)——excel、doc这种不是纯文本,它是一种软件
- 为什么要有字符型文件流?
- 假设有这么一个文件————里面有中文和英文
- 如果想要去读取这个文件,而用来装读取内容的容器大小刚好是16呢?————即:大小位置为“你”这个字哪里,“你"之前的 , 逗号那里为15,空格也是一个字符
- 这种情况继续用字节型文件流来读取会怎么样?———— 一个中文占2个字节
- 那这样,想要把“你”字完全读出来,理论上应该是容器大小为17,这样才可以装得下“你”这个字涩
- 但是:容器大小是16————所以会导致:中文读取失败( 即:无法完整读取 )
- 同时:以字符的形式读取 比 字节的形式更快一点
- 因此:有了字符型文件流
- 这种情况继续用字节型文件流来读取会怎么样?———— 一个中文占2个字节
- 假设有这么一个文件————里面有中文和英文
- 为什么要有字符型文件流?

- 字符型文件流的分类
- FileReader 字符输入流————核心方法就:read()
- FileWriter 字符输出流————核心方法就:write()
- 怎么创建对象?

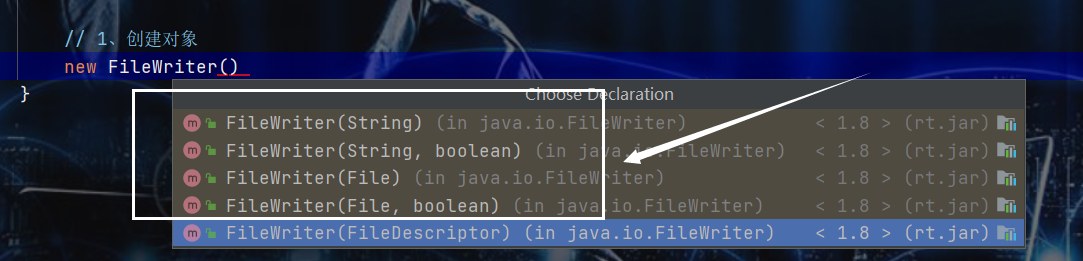
- 实例使用——三板斧———流的使用都是这样,后续不再说明了
package cn.xieGongZi.testFileReaderAndFileWriter; import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException; public class Demo { public static void main(String[] args) throws IOException { readData();
writeData();
} // 读数据
public static void readData() throws IOException { // 创建流管道
FileReader fr = new FileReader("D:\\InatallationPackage\\Maven\\pom.xml"); // 读数据
char[] data = new char[1024];
int len;
while ( (len = fr.read(data)) != -1 ){ System.out.println( new String( data,0,len) );
} if ( fr != null ){ fr.close();
}
} // 写数据
public static void writeData() throws IOException { // 创建流管道
FileWriter fw = new FileWriter("d:/test/play.txt", true); // 写数据
fw.write("天王盖地fu,宝塔镇huo妖"); // 关闭流管道
if ( fw != null ){
fw.close();
System.out.println("数据写入完毕");
}
}
}
学了字节型和字符型文件流操作,其实其他的流操作都已经会了,因为一样的,分类也一样,只是有细微的区别而已
缓冲流————也可以叫包装流——照样不断套娃嘛
- 就是在流管道中增加缓存数据,从而让我们的数据读写更快,更加流畅,就好比:在文件流的基础上把一部分的流管道容量加大了
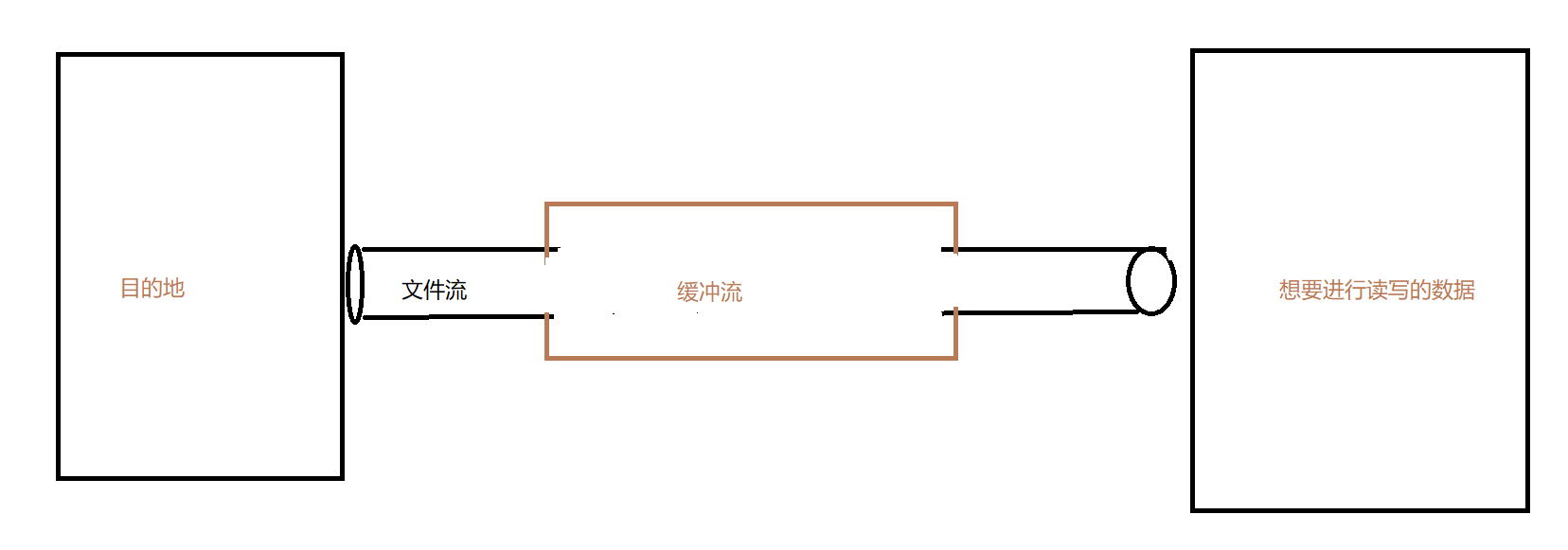
1、字节型缓冲流
- 字节型输入缓冲流————BufferedInputStream

- 字节型输出缓冲流————BufferOutputStream

这两个没啥好说的,对照字节型文件流就可以了
2、字符型缓冲流
- 字符输入流——BufferedReader————对照FileReader
- 但是:这个有一个需要注意的地方————BufferedReader的一个方法
- nextLine()————读取纯文本中一行的内容——很重要啊,用这个流读数据就用这个方法,不再用read()
- 但是:这个有一个需要注意的地方————BufferedReader的一个方法

- 字符输出流——BufferedWriter———对照FileWriter
- 这个流也有一个特殊的地方————BufferedWriter的一个方法
- newLine()————这个方法就相当于是换行
- 这个流也有一个特殊的地方————BufferedWriter的一个方法

实操一手儿
package cn.xieGongZi.buffer; import java.io.*; public class Demo { public static void main(String[] args) throws IOException { readData();
writeData(); } // 读数据
public static void readData() throws IOException { BufferedReader br = new BufferedReader(new FileReader("D:\\IntallationPackage\\Maven\\pom.xml")); String data = null; while ( ( data = br.readLine()) != null ){ // readline()一行一行的读取内容 System.out.println(data);
} } // 写数据
public static void writeData() throws IOException { // 创建输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("d:/test/play.txt",true)); // 写要录入文件的数据
bw.newLine(); // 换行————在新的一行中开始添加内容
bw.write("老衲来自西方极乐世界,到南方来享受金乌施主的温柔阳光"); // 关闭流管道
if ( bw != null ){ bw.close();
System.out.println("数据写入成功");
} }
}
转换流(重点)
转换流的作用:
- 有时读写文件的时候,用字节的方式来读写太慢了,利用字符的形式读写要快得多涩,所以这个时候就需要把字节型流 转换为 字符型流,这样读写的效率就快得多了
- 根据上面的理论,好像也可以套儿子嘛,因为是字节型转为字符型,所以直接在字符型中再套一个字节型就可以了涩( 因为字符流 就是 基于字节流实现的嘛 )。如下所示(字节文件输入 转 字符文件输入):
FileReader fr = new FileReader( new FileInputStream("d:/test/play.txt") ); // 这样看起来貌似就是想要的效果嘛
麻嘞个巴子咧~~别乱玩儿啊,看一下创建FileReader对象的时候,传递的参数是啥类型?————是字符串 / File类啊————所以上面的那种创建就是乱弹琴

1、字节输入流 转 字符输入流( InputStreamReader ——— 看名字记嘛,inputStream是字节输入流涩,Reader是字符流里面的啊,所以就是字节输入流 转 字符输入流咯)

- InputStreamReader流的使用
// 创建流
InputStreamReader isr = new InputStreamReader(new FileInputStream("d:/test/play.txt")); // 读数据
isr.read(????); // 但是这里传递的参数是一个char[] / charBuffer,而read()读出来之后的返回值又是int类型的,咋个办?
// 强转?char————>int确定没问题?转不转得了是一回事,重要的是:不会造成数据丢失吗? // 那就给这个字符流再找个爹儿,变一下嘛.........- 套个爹儿的玩法
// 创建流
BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream("d:/test/play.txt") ) ); // 读数据————读出来了得有个容器接一下嘛
String buffer;
while ( ( buffer = br.readLine() ) != null ){
System.out.println( buffer );
} // 关闭流管道
if ( br != null ){
br.close();
}
2、字节型输出流 转 字符型输出流———和1一样,所以直接上实例
// 字节型输出流——————>字符型输出流 // 创建流
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("d:/test/play.txt",true))); // 写数据
bw.newLine(); // 换行再录入数据
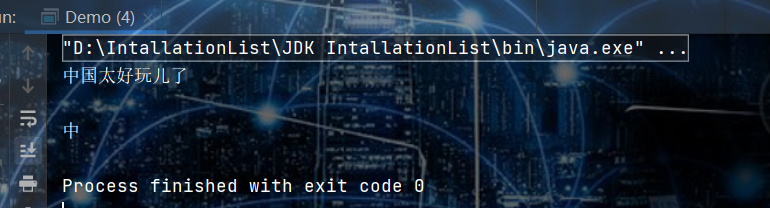
bw.write("贫道突然不知道录入个啥子数据进去好了"); // 关闭流管道
if ( bw != null ){
bw.close();
System.out.println("数据录入成功");
}
对象流(重点)——ObjectStream
为什么要搞对象流这个东西?
- 在面向对象编程篇的特征修饰符中见过一个修饰符了涩————transient,即:瞬时的(通俗讲就是:不把对象序列化)
- 这个猫玩意儿就需要用到这里来了
- 另外就是:分布式开发的时候,这个鸟儿东西就很有用了,因为:可以跨服务器调用彼此之间的东西,如:在A服务器上,调用B服务器的属性和方法,就可以利用这个骚东西知识(配合transient修饰符)来整了
1、序列化对象流————ObjectOutputStream
- 指的是:把一个完整的对象(这个对象保存的就是自己要录入的数据) 拆分成 字节碎片(这种东西人看都看球不懂,但计算机懂就行),然后存入到指定的文件中去
- ObjectOutputStream流如何创建对象?
- ObjectOutputStream = new ObjectOutputStream( OutputStream os )
- 序列化的实现方式
- 让对象实现Serializable接口(序列化接口),这就是一个标志接口,里面啥子都没有(在面向对象的接口知识中已说明)————另外:让对象实现这个接口之后,对对象本身没有任何影响,就是给这个对象做了一个标志而已
- 实例走起
- 创建一个对象————先创建一个类(用其他对象也可以)
package cn.xieGongZi.objectStream.test; import java.io.Serializable; public class Person implements Serializable { // 让这个类实现Serializable接口,表明这个类是可序列化的 private String name;
private char sex;
private Integer age; @Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", sex=" + sex +
", age=" + age +
'}';
} public Person() {
} public Person(String name, char sex, Integer age) {
this.name = name;
this.sex = sex;
this.age = age;
} public String getName() {
return name;
} public void setName(String name) {
this.name = name;
} public char getSex() {
return sex;
} public void setSex(char sex) {
this.sex = sex;
} public Integer getAge() {
return age;
} public void setAge(Integer age) {
this.age = age;
}
}
- 进行序列化
// 序列化流 // 创建流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/test/ObjectOutputStream.txt")); // 写数据
oos.writeObject(new Person("邪公子", '女', 18)); // 注意:这里是使用WriteObject()
oos.writeObject(new Person("紫邪情", '女', 30));
oos.writeObject(new Person("小紫", '女', 150));
oos.writeObject(new Person("韩非", '男', 100)); // 关闭流管道
if (oos != null ){
oos.close();
System.out.println("对象序列化完毕");
}- 效果如下:看不懂就对了,这就是字节碎片,是计算机底层的东西,这个内容是计算机强行显示出来的内容,在底层也就是二进制存储的
- 创建一个对象————先创建一个类(用其他对象也可以)

把对象序列化到文件中去,这都是计算机语言,看都看球不懂,咋个整?反序列化回来嘛
2、反序列化对象流
- 指的是:把字节碎片 还原回 一个完整的对象
- 直接上实例
// 反序列化 // 创建流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/test/ObjectOutputStream.txt")); // 读数据
try { Object person1 = ois.readObject(); // 在这里:反序列化的顺序就是前面序列化的顺序,不能把顺序搞乱了,不然反序列化出来的数据不一样 / 出错
System.out.println( person1 ); // 看效果 Object person2 = ois.readObject();
System.out.println( person2 ); Object person3 = ois.readObject();
System.out.println( person3 ); Object person4 = ois.readObject();
System.out.println( person4 ); } catch (ClassNotFoundException e) {
e.printStackTrace();
}finally { // 关闭流管道
if (ois != null ){
ois.close();
}
}- 效果如下:

至此:需要用的流技术知识已经完毕
后续为装墨水儿知识,知不知道都无所谓
编码与字符集————这里也就来解决乱码的问题
编码
- 指的是:把字符与数字对应的过程
字符集
- 指的是:一张记录了对应关系的信息表
- 这种有很多,如:
- GBK ———— 我国的国标码
- ISO-8859-1 ———— 西欧语言
- Big5 ———— 香港台湾语言(繁体字)
- Unicode ———— 联合编码(多个国家的语言字符都包含在这张表里面)————里面还分为:UTF-8(三串数字存一个中文字符)、UTF-16.......
- 这种有很多,如:
- 理论整起来贼没意思,来上实例
- 假如:我存了这么一个数据,然后采用了ANSI编码(不懂门道的,可以简单理解为GBK)
- 假如:我存了这么一个数据,然后采用了ANSI编码(不懂门道的,可以简单理解为GBK)

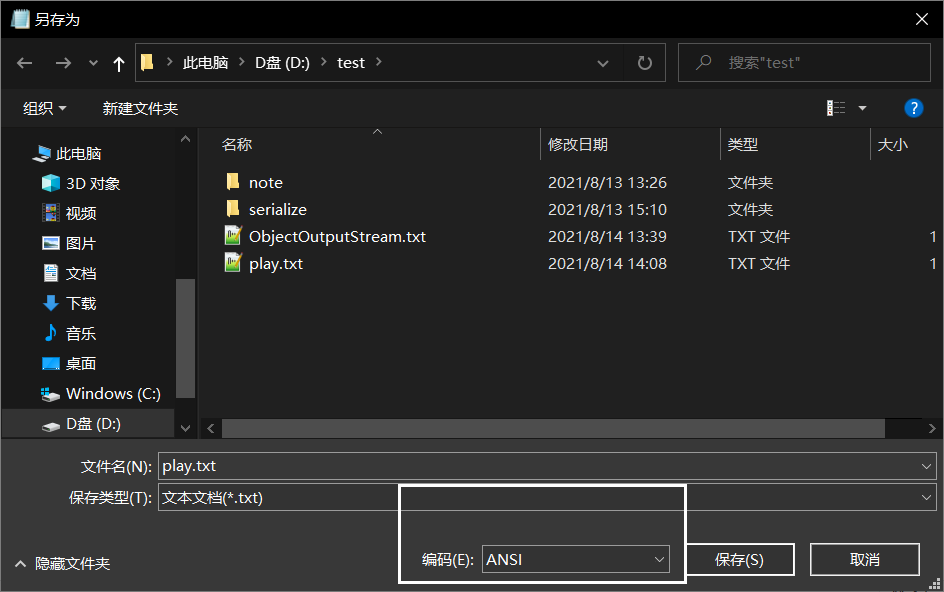
- 然后去读取这个文件
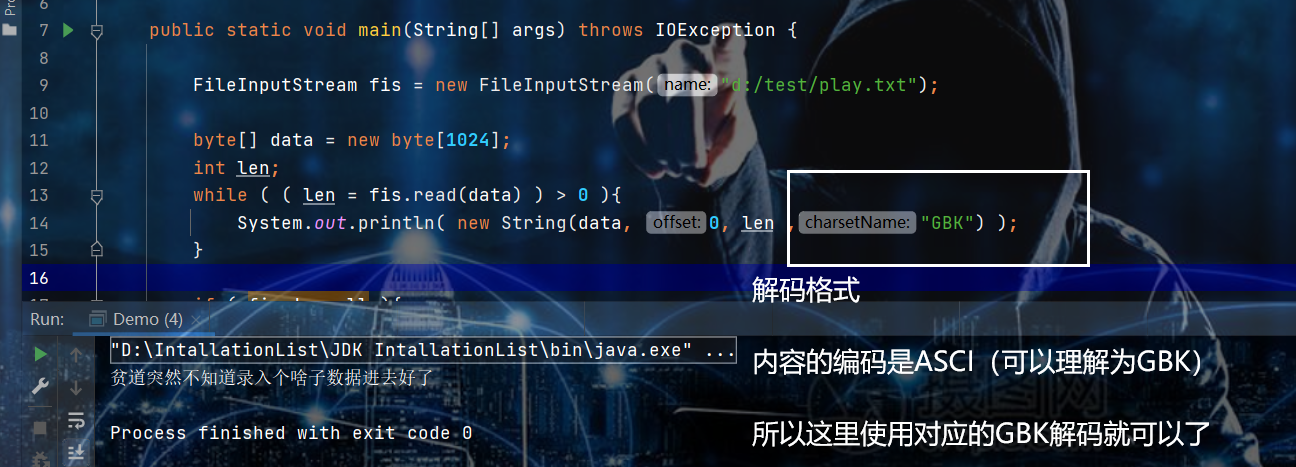
FileInputStream fis = new FileInputStream("d:/test/play.txt"); byte[] data = new byte[1024];
int len;
while ( ( len = fis.read(data) ) > 0 ){
System.out.println( new String(data, 0, len) );
} if ( fis != null ){
fis.close();
}- 读取出来的效果是这样的————即:发生乱码了————怎么解决?
- 只需要把编码格式改一下————因为:保存的时候是使用的ANSI编码,那解码用GBK就可以了( 即:charSet )
- 然后去读取这个文件
- 再来了解一下:前面说的UTF-8是三串数字存一个中文字符是不是真的
- 测试一下
// UTF-8是不是采用三串数字保存的一个中文字符?
String data = "中国太好玩儿了"; // 把这个内容采用UTF-8的解码格式读出来看一下
byte[] newData = data.getBytes(); // 这个采用的是系统的默认字符集,而我的字符集就是UTF-8 // 打印出来看一下
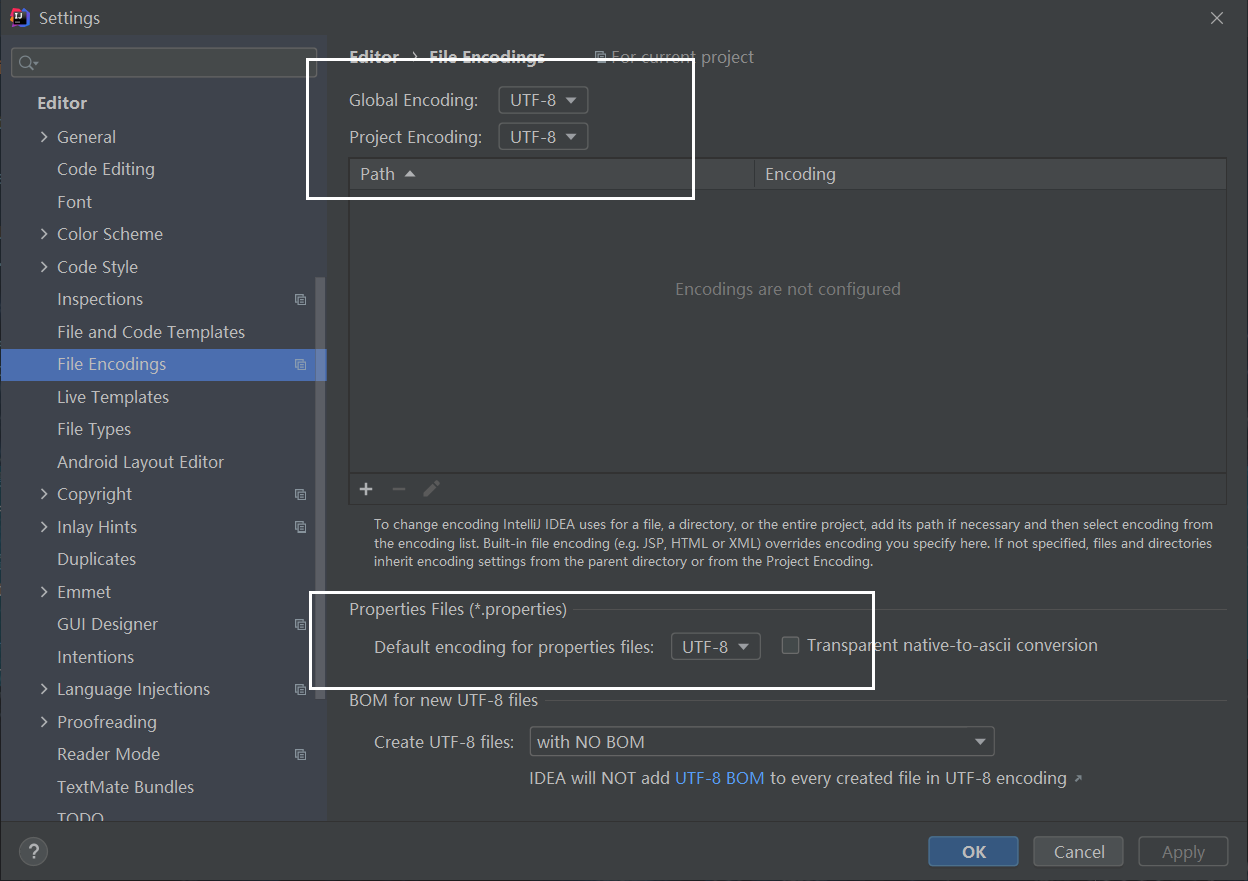
System.out.println( Arrays.toString(newData) );- 我的idea编码解码格式如下:
- 我的idea编码解码格式如下:
- 最后看一下效果

-28, -72, -83 ———— 中
-27, -101, -67 ———— 国
-27, -92, -86 —————— 太
-27, -91, -67 —————— 好
-25, -114, -87 —————— 玩
-27, -124, -65 —————— 儿
-28, -70, -122 —————— 了
- 测试一下
- 再验证一下嘛:拿这串数字反编译一下,看是不是这几个字
// 整体反编译测试
byte[] data = {-28, -72, -83, -27, -101, -67, -27, -92, -86, -27, -91, -67, -25, -114, -87, -27, -124, -65, -28, -70, -122};
String chineseData = new String(data, "UTF-8");
System.out.println( chineseData );
System.out.println();
// 单个反编译测试
byte[] byteText = {-28, -72, -83};
System.out.println( new String(byteText, "UTF-8") );- 效果如下:
- 再验证一下嘛:拿这串数字反编译一下,看是不是这几个字
其他的那些编码也可以这么玩儿
同时:由以上的测试就得出一个结论:
- 只要产生了乱码,那么必定是编码格式和解码格式不一致导致的
打印流———printStream(没啥好玩儿的)
这个东西最常见了,一直都在用,只是不知道它具体的名字而已
- System.out.println()———龟儿嘞舅舅滴,这就是属于打印流^ _ ^,只不过这是属于System下的而已
1、字节打印流
- 直接看实例
// 字节打印流
PrintStream ps = new PrintStream("d:/test/play.txt");
ps.println("what are you 弄啥嘞?"); // 这是向指定文件打印数据
ps.close(); // 字符型打印流
PrintWriter pw = new PrintWriter("d:/test/play.txt");
pw.print("这玩意儿也不好玩儿啊");
pw.close();
任意文件访问类——RandomAcessFile(更没什么好玩儿的)
支持三种模式
r 只读
w 只写
rw 读写————这个比前面两个用有一点儿
- 直接看实例咯,懒球整这个类其他的屁东西
// 随机访问文件类
RandomAccessFile raf = new RandomAccessFile("d:/test/play.txt","rw");
// 移动光标到 末尾位置 写数据
raf.seek( raf.length() );
raf.writeBytes( "mysql" ); // 移动光标到 开始位置 读操作
raf.seek(0);
String line = raf.readLine();
System.out.println( line );
raf.close();
流技术的东西就搞完了,在这个阶段没什么写的了
javaSE高级篇2 — 流技术 — 更新完毕的更多相关文章
- javaSE高级篇3 — 网络编程 — 更新完毕
网络编程基础知识 先来思考两个问题( 在这里先不解决 ) 如何准确的找到一台 或 多台主机? 找到之后如何进行通讯? 网络编程中的几个要素 IP 和 端口号 网络通讯协议:TCP / UDP 最后一句 ...
- 4 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 续 ) - 更新完毕
0.前言 这里面一些理论和前面的知识点挂钩的,所以:建议看一下另外3篇知识内容 基础篇:https://www.cnblogs.com/xiegongzi/p/15684307.html java操作 ...
- javaSE高级篇4 — 反射机制( 含类加载器 ) — 更新完毕
反射机制 1.反射机制是什么?----英文单词是:reflect.在java.lang包下---这才是java最牛逼的技术 首先提前知道一句话----在java中,有了对象,于是有了类,那么有了类之后 ...
- javaSE高级篇6 — 注解( 附:注解底层解析 ) —— 更新完毕
注解 ---- 英文:annotation 1.注解长什么样子? @xxxxxxx( 一些信息 ) ----- 这个信息可有可无 2.注解可以放在什么地方? 类本身的上面.属性的上面.方法的上面.参数 ...
- javaSE高级篇5 — java8新特性详解———更新完毕
java8新特性 在前面已经见过一些东西了,但是:挖得有坑儿 1.lambda表达式 lambda表达式是jdk1.8引入的全新语法特性 它支持的是:只有单个抽象方法的函数式接口.什么意思? 就是说: ...
- javaSE高级篇7 — 设计原则和设计模式 — 设计模式慢慢更( 这是思想层次篇 )
1.什么是设计原则? 设计原则就是面向对象的原则嘛,即:OOP原则 换句话说:就是为了处理类与类之间的关系( 包括接口.类中的方法 ) 2.OOP设计原则有哪些? 1).开闭原则:就是指对拓展开放.对 ...
- javaSE高级篇1 — 异常与多线程基础
1.异常的体系结构 注:Throwable是一个类,不是一个接口,这个类里面是描述的一些Error和Exception的共性,如图所示: 异常 / 错误是什么意思? 定义:指的是程序运行过程中,可能 ...
- javaWeb - 1 — servlet — 更新完毕
1.先来聊一些javaWeb相关的知识 简单了解一下:web的发展史 1).web就是网页的意思嘛 2).web的分类 (1).静态web 使用HTML.CSS技术,主要包括图片和文本 优点:简单,只 ...
- Vue2技术整理3 - 高级篇 - 更新完毕
3.高级篇 前言 基础篇链接:https://www.cnblogs.com/xiegongzi/p/15782921.html 组件化开发篇链接:https://www.cnblogs.com/xi ...
随机推荐
- 我的一些JAVA基础见解
这个学期学习JAVA基础课,虽说之前都自学过,但在学习时仍可以思考一些模糊不清的问题,可以更深一步的思考.在这里写下一些需要深入的知识点,对小白们也很友好~ 一.Java数据类型 1.基本数据类型 这 ...
- hdfs基本操作命令
hdfs文件的相关操作主要使用hadoop fs.hadoop dfs.hdfs dfs 命令,以下对最常用的相关命令进行简要说明. hadoop fs -ls 显示当前目录结构,-ls -R 递归 ...
- Ubuntu14.04安装ia32-libs报错
安装编译环境的时候报错 sudo apt-get install ia32-libs Reading package lists... Done Building dependency tree Re ...
- Ubuntu virtualenv 创建 python2 虚拟环境 激活 退出
首先默认安装了virtualenv 创建python2虚拟环境 your-name@node-name:~/virtual_env$ virtualenv -p /usr/bin/python2 py ...
- CSS学习笔记:浮动属性
目录 一.浮动流是什么 二.通过代码实例了解浮动特点 1. 搭建测试框架 2. 添加浮动 3. 浮动元素的排布 4. 给行内元素添加浮动效果 5. 子元素浮动后对父元素的影响 5.1 在父元素中添加o ...
- 【java+selenium3】多窗口window切换及句柄handle获取(四)
一 .页面准备 1.html <html> <head> <title>主页面 1</title> </head> <body> ...
- Qt5 C++ GUI界面 开发环境配置 详细教程
本博客已暂停更新,需要请转新博客http://www.whbwiki.com/333.html Qt 下载 Qt 体积很大,有 1GB~3GB,官方下载通道非常慢,相信很多读者会崩溃,所以建议大家使用 ...
- LeetCode 78. 子集 C++(位运算和回溯法)
位运算 class Solution { public: vector<vector<int>> subsets(vector<int>& nums) { ...
- 连接url
celery broker redis with password broker_url = 'redis://user:password@redishost:6379/0' tooz zookeep ...
- Python-Unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...