Spark基础:(二)Spark RDD编程
1、RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在分区的不同节点上。
用户可以通过两种方式创建RDD:
(1)读取外部数据集====》 sc.textFile(inputfile)
(2)驱动器程序中对一个集合进行并行化===》sc.parallelize(List(“pandas”,”I like pandas”))
2、RDD操作
转化(Transformations)和行动*(Actions)操作
(1):转化操作
RDD 经过转化返回一个新的RDD,转化出来的RDD是惰性求值的,只有在行动操作才会进行计算的。
常见的转换操作如下图:
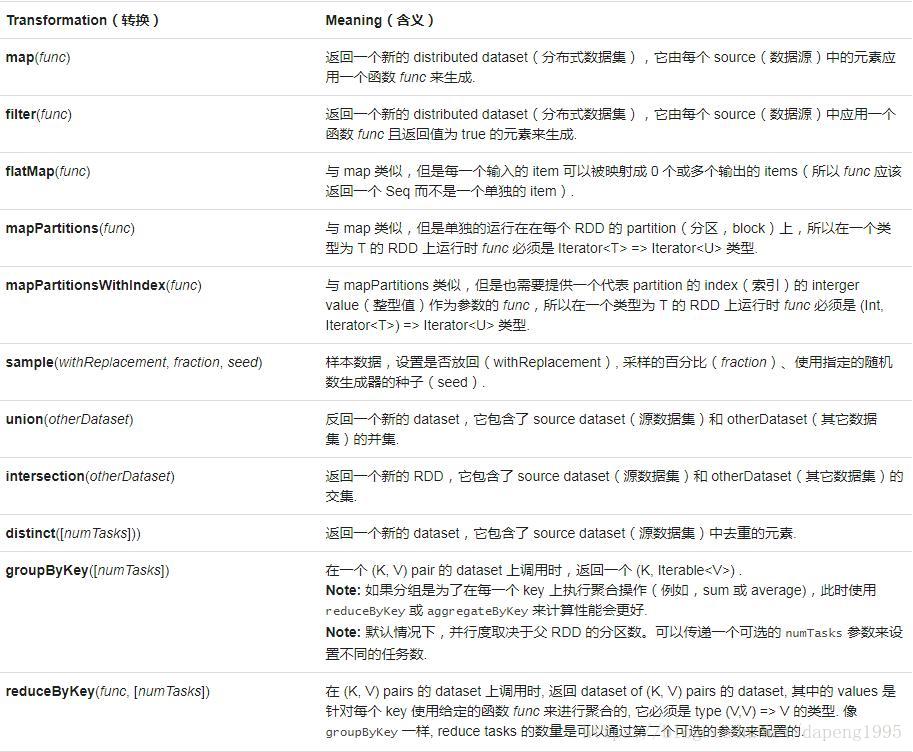
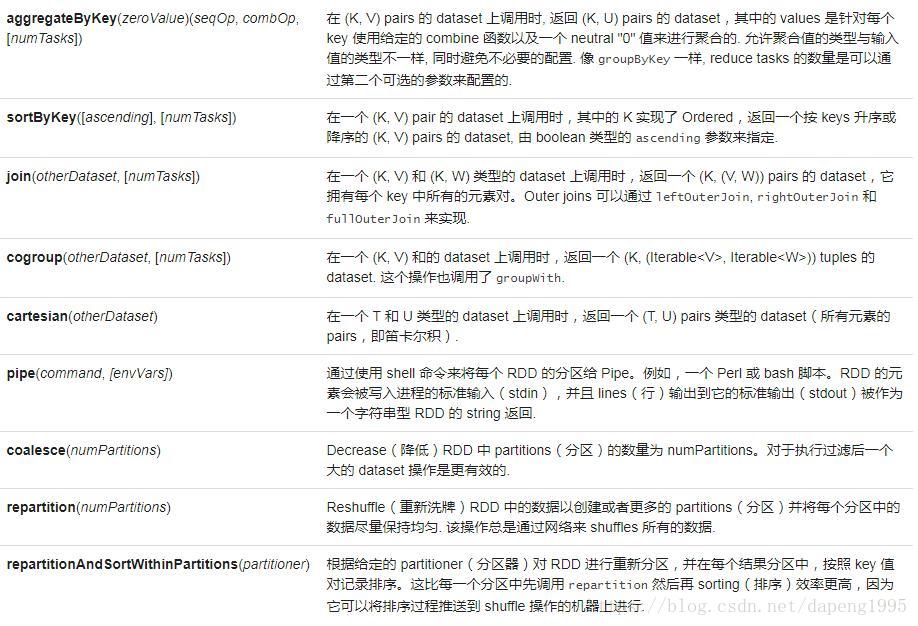
(2):行动操作
对数据集进行实际的计算,这最终求得的结果返回驱动器程序中,或者写入外部程序中。
下表列出了一些 Spark 常用的 actions 操作
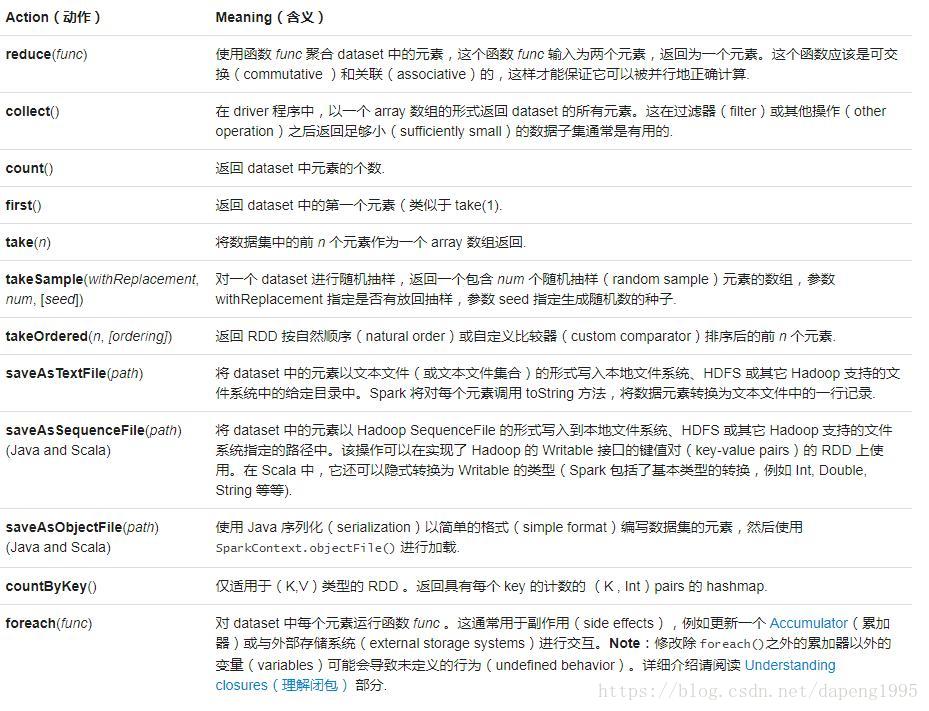
简单worldcount操作实现
object WordCountScala {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("WordCountScala")
//设置master属性
//conf.setMaster("local");
conf.setMaster("local[*]")
//通过conf创建sc
val sc = new SparkContext(conf);
print("hello world");
//加载文本文件
val rdd1 = sc.textFile("F:/spark/b.txt");
//压扁
val rdd2 = rdd1.flatMap(line => {
println("map :"+line)
line.split(" ")
}) ;
//映射w => (w,1)
val rdd3 = rdd2.map(word=>{
println("map :"+word)
(word,1)
})
val rdd4 = rdd3.reduceByKey(_ + _)
val r = rdd4.collect()
r.foreach(println)
}
}3、RDD的持久化
因为Spark RDD是惰性求值的,有时候我们希望能够多次使用同一个RDD。如果简单的对RDD调用行动操作,Spark会重算RDD以及它的所有的依赖。造成算法的开销很大。处于不同的目的,我们可以为RDD选择不同的持久化级别。RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。默认的存储级别是 StorageLevel.MEMORY_ONLY(将反序列化的对象存储到内存中) ,如果您想手动删除 RDD 而不是等待它掉出缓存,使用 RDD.unpersist() 方法。

例如: Scala中的两次执行
val result=input.map(x=>x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))Spark基础:(二)Spark RDD编程的更多相关文章
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 大数据入门第二十二天——spark(二)RDD算子(2)与spark其它特性
一.JdbcRDD与关系型数据库交互 虽然略显鸡肋,但这里还是记录一下(点开JdbcRDD可以看到限制比较死,基本是鸡肋.但好在我们可以通过自定义的JdbcRDD来帮助我们完成与关系型数据库的交互.这 ...
- 【Spark基础】:RDD
我的代码实践:https://github.com/wwcom614/Spark 1.RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式 ...
- 什么是spark(二) RDD
其实你会发现很多概念都是基于RDD提出来的,比如分区,缓存这些操作的对象其实都是RDD:所以不要讲spark的分区,这其实很不专业,分区其实是属于RDD的概念(只有pair RDD才有分区概念) RD ...
- spark(2.2) - spark-shell RDD编程
[基本操作] 1* 从文件系统中加载数据创建RDD -> 本地文件系统 ->HDFS 2* 转换操作 [ 会创建新的RDD ,没有真正计算 ] >> filter() > ...
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- spark入门(二)RDD基础操作
1 简述 spark中的RDD是一个分布式的元素集合. 在spark中,对数据的所有操作不外乎创建RDD,转化RDD以及调用RDD操作进行求值,而这些操作,spark会自动将RDD中的数据分发到集群上 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
随机推荐
- hdu 4288 Coder (线段树+离线)
题意: 刚开始有一个空集合.有三种操作: 1.往集合中加入一个集合中不存在的数 x 2.从集合中删除一个已经存在的数 x 3.计算集合的digest sum并输出. digest sum求 ...
- Git 极速上手(超简单)
前言:本文主要介绍了一种快速入门使用Git的方法,通过四步完成本地仓库构建和推送到远程仓库(Github.Gitee码云),简单说明最常用的命令,不需要明白Git的原理即可使用,本文不介绍具体原理. ...
- js和jq文档操作
JS文档操作 一.dom树结构 1.元素节点 2.文本节点 3.属性节点 不属于元素节点的子节点 4.文档节点(document) 二.处理元素节点 method 1.docu ...
- vue-router 4 你真的熟练吗?
虽然 vue-router 4 大多数 API 保持不变,但是在 vue3 中以插件形式存在,所以在使用时有一定的变化.接下来就学习学习它是如何使用的. 一.安装并创建实例 安装最新版本的 vue-r ...
- 什么是SimpleNVR流媒体服务器软件?
SimpleNVR是一款新兴流媒体服务器应用软件,占用内存少,无插件.跨平台,应用非常广泛,操作简单易上手,同时还支持一键观看,十分便捷.另外,跟其他一般流媒体服务器不同,SimpleNVR支持开发者 ...
- robot_framewok自动化测试--(3)测试项目与测试套件的概念
测试项目与测试套件的概念 如果你查看当前所创建的项目会发现,"test_project"是一个目录: "test_suit"则是一个 txt 文件: " ...
- centos7.2安装rabbitmq教程
环境: centos7.2 rabbitmq依赖erlang,需要先安装erlang 1 安装erlang rpm -Uvh https://download.fedoraproject.org/pu ...
- AppGallery Connect场景化开发实战—注册订阅通知
借助AppGallery Connect(以下简称AGC)的认证服务,云函数,短信服务等服务,当用户注册成功后,便可以在注册的手机号或者邮箱地址中收到一条应用的欢迎短信或者欢迎邮件.以便让开发者更快地 ...
- Python基础(获取对象信息)
import types print(type('abc') == str)#True print(type(123) == int)#True def f1(): pass print(type(f ...
- 菜鸡的Java笔记 第二十六 - java 内部类
/* innerClass 从实际的开发来看,真正写到内部类的时候是在很久以后了,短期内如果是自己编写代码,几乎是见不到内部类出现的 讲解它的目的第一个是为了解释概念 ...