【六】K8s-Pod 水平自动扩缩实践(简称HPA)
一、概述
Pod 水平自动扩缩(Horizontal Pod Autoscaler)简称 HPA,HPA 可以根据 CPU 利用率进行自动伸缩 Pod 副本数量,除了 CPU 利用率,也可以基于其他应程序提供的自定义度量指标来执行自动扩缩。
通过 HPA 可以达到某个时刻业务请求量很大的时候,不需要我们人工去干涉,它会根据我们设定的指标来进行自动伸缩 Pod 数量来应付访问量。
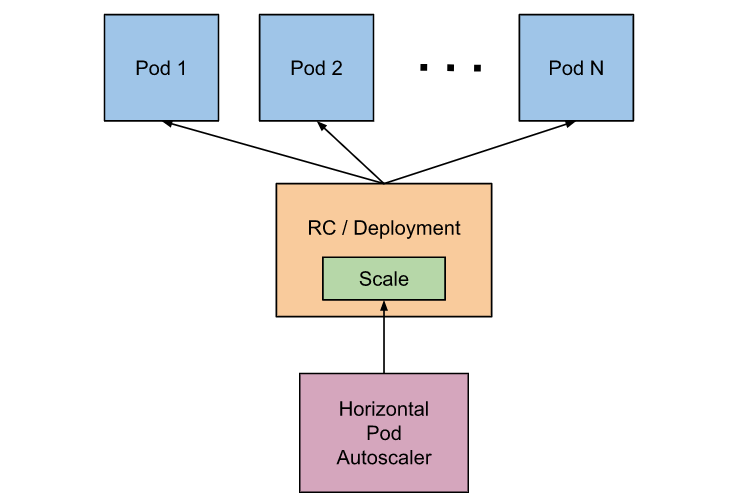
这是官方的图
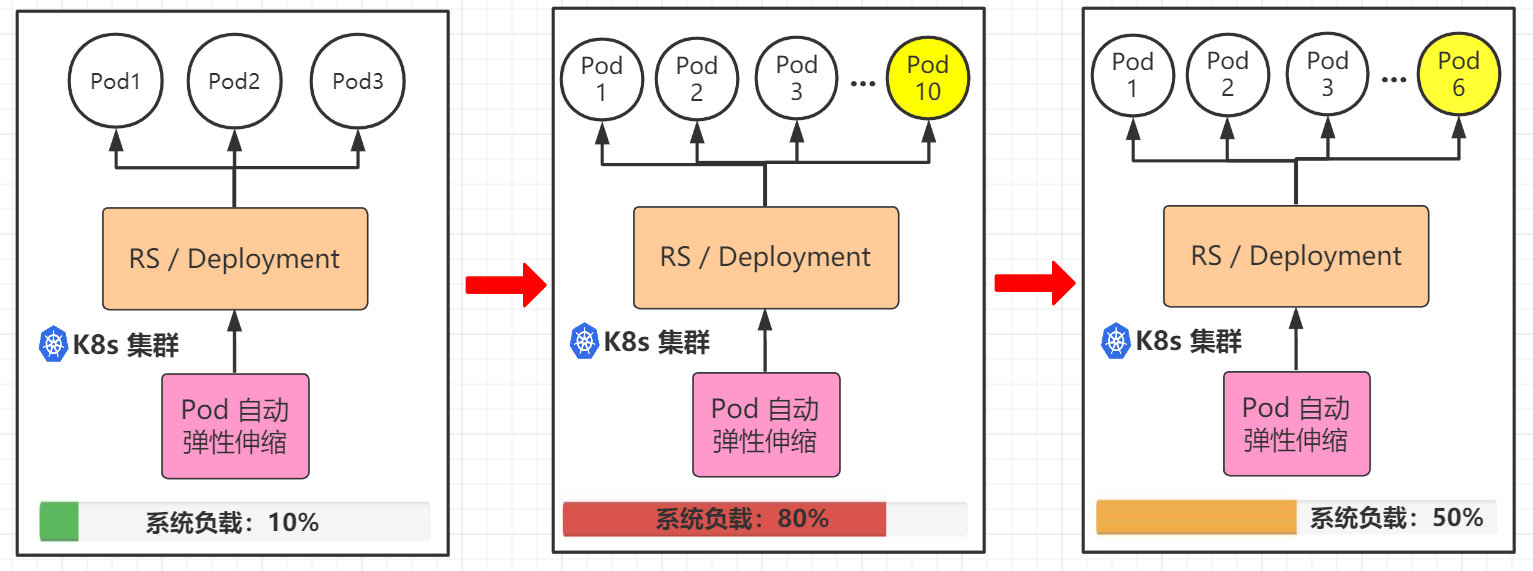
这是我画的图(勿喷)
二、安装Metrics-Server
Heapster 官方在v1.11中已经被废弃,Heapster 监控数据可用,但 HPA 不再从 Heapster 拿数据,所以就不能满足我们本次实验。
Kubernetes 版本为 v1.2 或更高采用 Metrics-Server 来获取监控数据, HPA 根据此 Metrics API 来获取度量数据,所以本次实验需要安装 Metrics-Server 插件。
1.1 下载YAML文件,修改配置
Metrics-Server GitHub 链接:
https://github.com/kubernetes-sigs/metrics-server
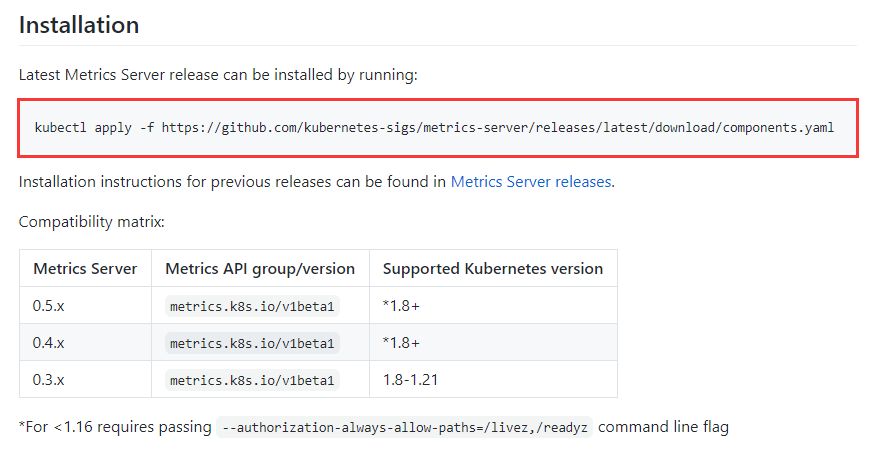
由于我的环境 K8s 版本是 1.21,直接安装最新的 Metrics-Server 即可。
我们需要下载components.yaml下载到本地,添加- --kubelet-insecure-tls到配置文件中,否则会报错
[root@k8s-master01 ]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
如果 Linux 操作系统一直无法下载,可以尝试在 Windows 上的迅雷下载好上传。
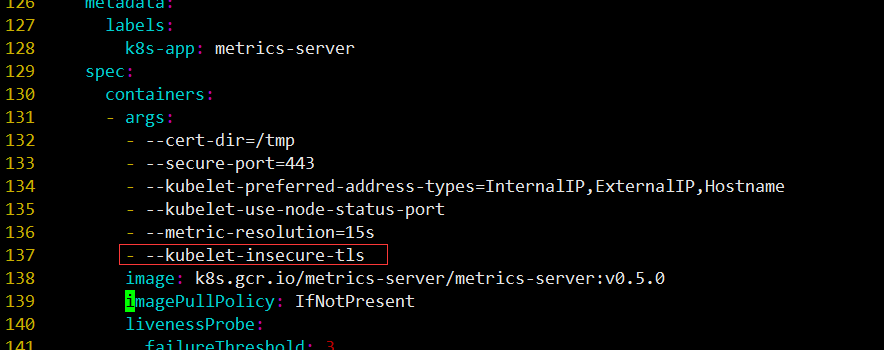
打开components.yaml添加如下配置:
- --kubelet-insecure-tls
# kubelet 的10250端口使用的是https协议,连接需要验证tls证书,--kubelet-insecure-tls不验证客户端证书。
1.2 注意事项
如果不添加- --kubelet-insecure-tls ,可能会出现如下报错
查看 metrics-server-xxx-xxx 详细事件时发现报错如下:
[root@k8s-master01 ~]# kubectl describe pod metrics-server-xxx-xxx -n kube-system

我们在查看该 Pod 详细日志,报错如下:
[root@k8s-master01 ~]# kubectl logs -n kube-system metrics-server-6dfddc5fb8-f8gnd
...
I0531 07:57:33.049547 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
I0531 07:57:43.049460 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E0531 07:57:44.458989 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.11:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.11 because it doesn't contain any IP SANs" node="k8s-master01"
E0531 07:57:44.472464 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.13:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.13 because it doesn't contain any IP SANs" node="k8s-node02"
E0531 07:57:44.478313 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.12:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.12 because it doesn't contain any IP SANs" node="k8s-node01"

1.3 手动下载镜像
由于k8s.gcr.io在国外,导致无法下载metrics-server镜像问题。
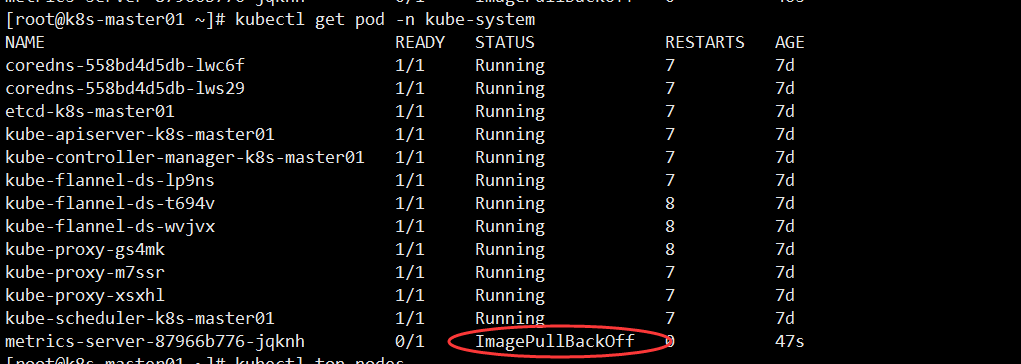
当我们查看 Pod 状态是发现为ImagePullBackOff
[root@k8s-master01 ~]# kubectl get pod -n kube-system
查看 metrics-server-xxx-xxx 详细事件时发现报错如下:
[root@k8s-master01 ~]# kubectl describe pod metrics-server-xxx-xxx -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m1s default-scheduler Successfully assigned kube-system/metrics-server-87966b776-jqknh to k8s-node01
Normal Pulling 106s (x4 over 4m) kubelet Pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0"
Warning Failed 91s (x4 over 3m45s) kubelet Failed to pull image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning Failed 91s (x4 over 3m45s) kubelet Error: ErrImagePull
Warning Failed 76s (x6 over 3m45s) kubelet Error: ImagePullBackOff
Normal BackOff 61s (x7 over 3m45s) kubelet Back-off pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0"

需要手动下载镜像再进行改名(每个节点都需要下载)
[root@k8s-master01 ~]# docker pull bitnami/metrics-server:0.5.0
[root@k8s-master01 ~]# docker tag bitnami/metrics-server:0.5.0 k8s.gcr.io/metrics-server/metrics-server:v0.5.0

注意:当你看到这篇笔记的时候,可能镜像已经更新了,根据报错提示来下载即可。
1.4 开始创建 Metrics-Server
只需要在 K8s-master 节点创建即可!
[root@k8s-master01 ~]# kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
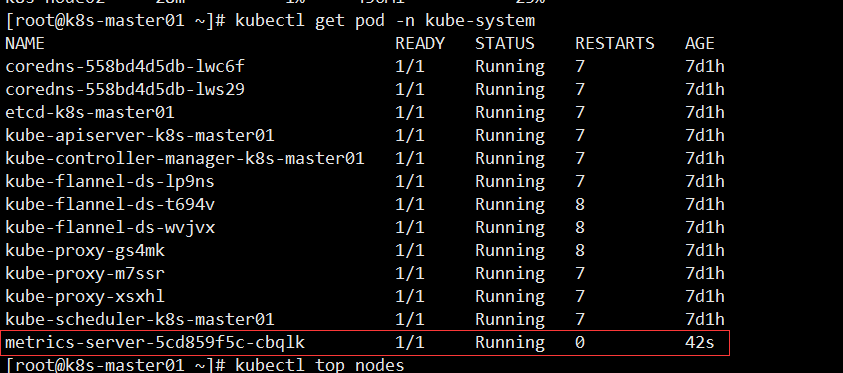
查看 Pod 状态发现已经 Running
[root@k8s-master01 ~]# kubectl get pod -n kube-system
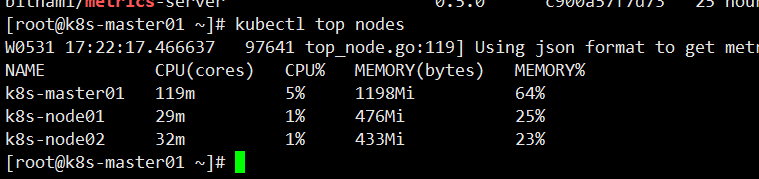
检查 Metrics Server
[root@k8s-master01 ~]# kubectl top nodesW0531 17:22:17.466637 97641 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flagNAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 119m 5% 1198Mi 64% k8s-node01 29m 1% 476Mi 25% k8s-node02 32m 1% 433Mi 23%
不知道为什么会出现这样的提示,Metrics Server 是正常的,也可以获取到资源使用情况,暂时不理它,后续再解决。
W0531 17:22:17.466637 97641 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
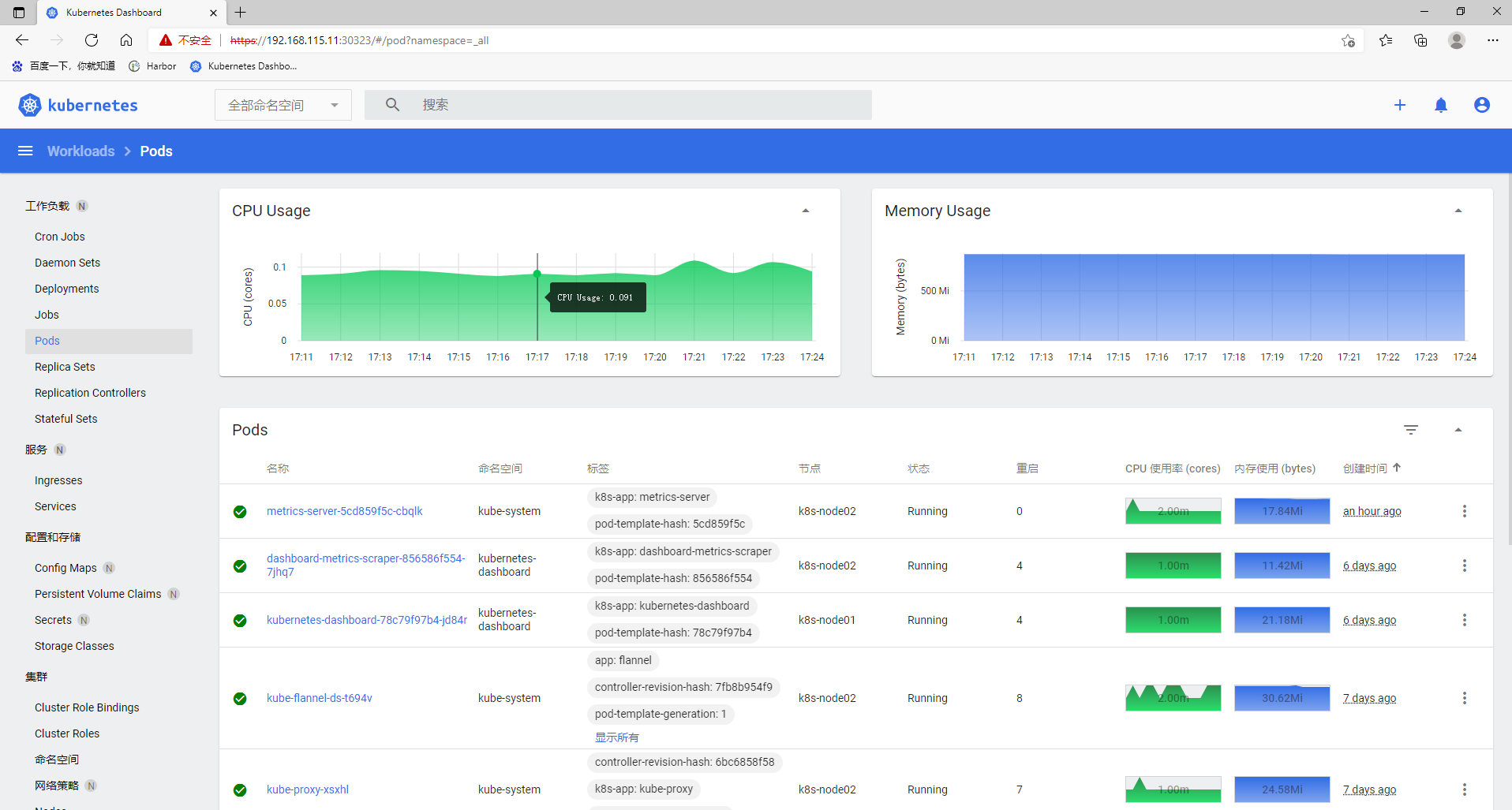
在 K8s Dashboard 界面查看资源使用情况
二、创建 HPA 测试案例
创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。
定义Deployment的YAML文件如下:(hap-deploy-demo.yaml)
apiVersion: apps/v1kind: Deploymentmetadata: name: hpa-nginx-deployspec: selector: matchLabels: run: hpa-nginx-deploy replicas: 1 template: metadata: labels: run: hpa-nginx-deploy spec: containers: - name: nginx image: hub.test.com/library/mynginx:v1 # 镜像地址 ports: - containerPort: 80 resources: limits: # 最大限制 cpu: 500m # CPU最大是500微核 requests: # 最低保证 cpu: 200m # CPU最小是200微核
在test命名空间创建Deployment:
[root@k8s-master01 hpa-test]# kubectl create -f hpa-deploy-demo.yaml -n testdeployment.apps/hpa-nginx-deploy created
-n test 指定命名空间
查看 Pod 、Deployment 状态
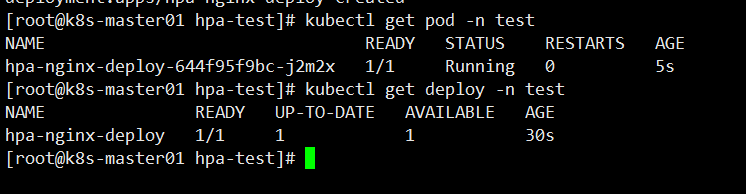
创建一个HPA,可以使用kubectl autoscale命令来创建:
[root@k8s-master01 ~]# kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=20 --min=1 --max=10 -n testhorizontalpodautoscaler.autoscaling/hpa-nginx-deploy autoscaled
--cpu-percent=20 HPA 会通过 Pod 伸缩保持平均 CPU 利用率在20%以内;
--min=1 --max=10 允许 Pod 伸缩范围,最小的 Pod 副本数为1,最大为10;
也可以使用 YAML 进行 HPA 编写更为详细的设置。
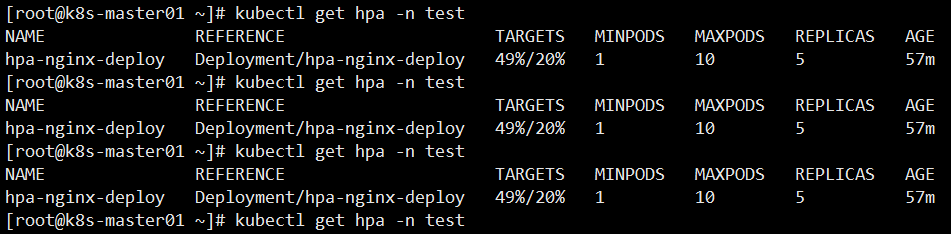
查看 HPA 当前状态
[root@k8s-master01 hpa-test]# kubectl get hpa -n testNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEhpa-nginx-deploy Deployment/hpa-nginx-deploy 0%/20% 1 10 1 37m

当前的 CPU 利用率是 0%,由于未发送任何请求到该 Pod。
查看 hpa-nginx-deployPod 的 IP地址
[root@k8s-master01 hpa-test]# kubectl get pod -n test -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATEShpa-nginx-deploy-9f8676f85-57kg8 1/1 Running 0 42m 10.244.1.23 k8s-node01 <none> <none>

2.1 增加负载测试
增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
[root@k8s-master01 ~]# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while true; do wget -q -O- http://10.244.1.23; done" -n test

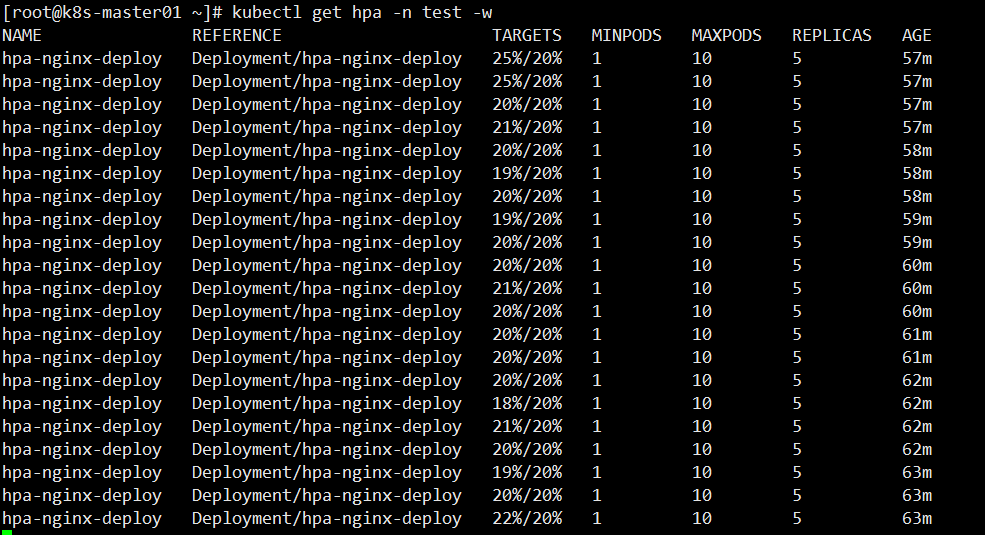
等待一小会,查看 HPA 负载情况,当前 CPU 使用率 49% 已经超出设置值
[root@k8s-master01 ~]# kubectl get hpa -n test -w
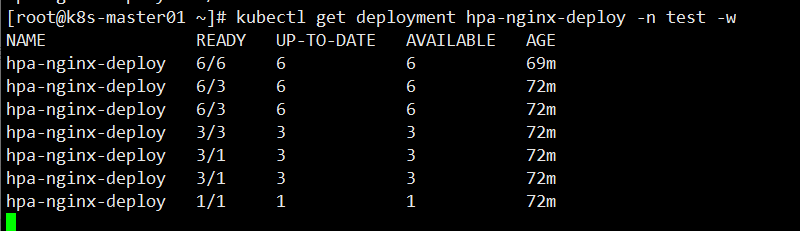
此时来查看deployment Pod 副本数量,由原来的1个自动扩容到5个
[root@k8s-master01 ~]# kubectl get deployment hpa-nginx-deploy -n test -w

再次查看 HPA 负载情况,可以看到一直保持在 20% 以内
2.2 停止负载测试
在刚刚创建 busybox 容器的终端中,输入<Ctrl> + C 来终止负载的测试即可。
等待一会,查看 HPA 负载情况和 Deployment Pod副本数是否到达收缩功能
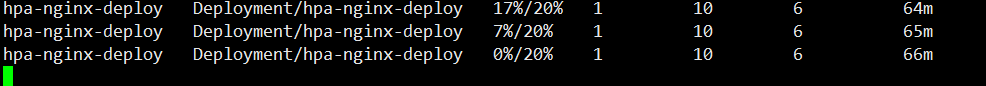
这是 Dashboard 界面情况,已经过去一两分钟了,还没见收缩,再等等
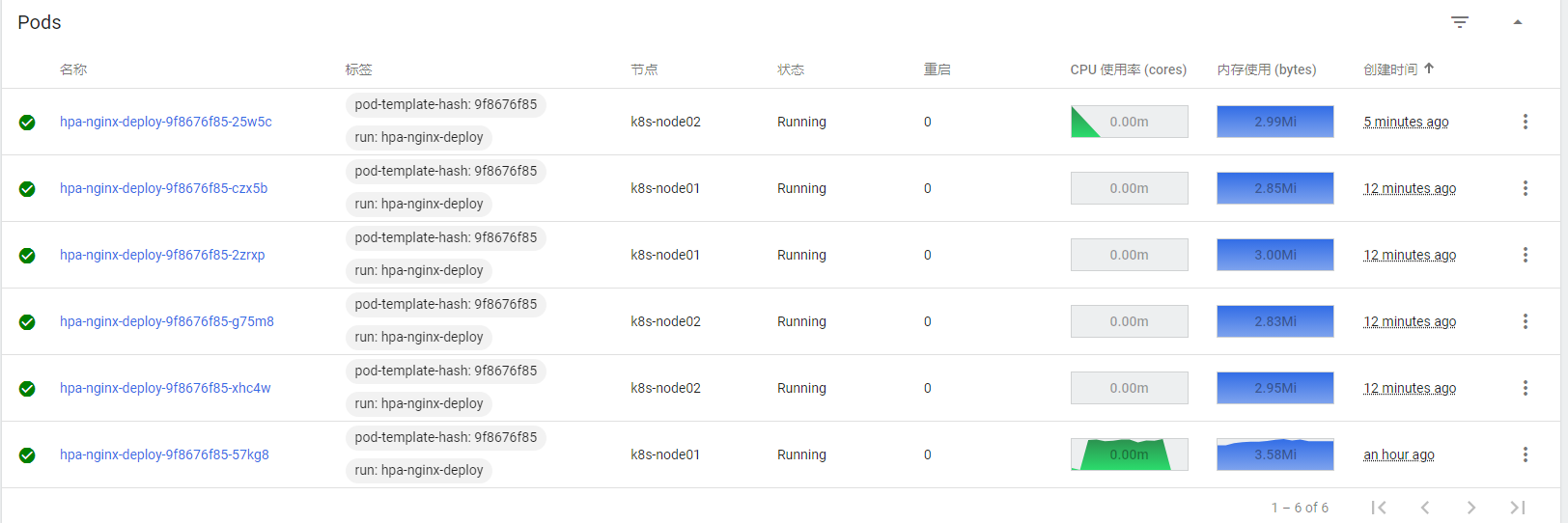
此时我们可以看到 Pod 副本数已经被收缩了,因为 CPU 使用率为 0,所以只保留最小副本数1个 Pod 对外提供服务

收缩的过程可能要等待几分钟;
通过上图可以看到,Pod 副本数不是一下子回收,而是逐步的回收机制。
这是 Dashboard 界面情况

到此 Pod 水平自动扩缩测试就到此结束了,HPA 不仅仅这些,还有多项度量指标和自定义度量指标自动扩缩等策略等着你去实践。
【六】K8s-Pod 水平自动扩缩实践(简称HPA)的更多相关文章
- 13.深入k8s:Pod 水平自动扩缩HPA及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 Pod 水平自动扩缩 Pod 水平自动扩缩工作原理 Pod 水平自动 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十一)——一步一步教你如何撸Dapr之自动扩/缩容
上一篇我们讲到了dapr提供的bindings,通过绑定可以让我们的程序轻装上阵,在极端情况下几乎不需要集成任何sdk,仅需要通过httpclient+text.json即可完成对外部组件的调用,这样 ...
- 三十三、HPA实现自动扩缩容
通过HPA实现业务应用的动态扩缩容 HPA控制器介绍 当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能 $ kubectl -n luffy scale deployment m ...
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- Knative 基本功能深入剖析:Knative Serving 自动扩缩容 Autoscaler
Knative Serving 默认情况下,提供了开箱即用的快速.基于请求的自动扩缩容功能 - Knative Pod Autoscaler(KPA).下面带你体验如何在 Knative 中玩转 Au ...
- k8s Pod的自动水平伸缩(HPA)
我们知道,当访问量或资源需求过高时,使用:kubectl scale命令可以实现对pod的快速伸缩功能 但是我们平时工作中我们并不能提前预知访问量有多少,资源需求多少. 这就很麻烦了,总不能为了需求总 ...
- Horizontal Pod Autoscaler(Pod水平自动伸缩)
Horizontal Pod Autoscaler 根据观察到的CPU利用率(或在支持自定义指标的情况下,根据其他一些应用程序提供的指标)自动伸缩 replication controller, de ...
- minikube metrics-server HPA 自动扩缩容错误
minikube metrics-server pod 错误 启动 minikube addons enable metrics-server 之后查看 metrics-server pod 会有如下 ...
- kubernetes之Pod水平自动伸缩(HPA)
https://k8smeetup.github.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ Horizon ...
随机推荐
- 浅谈synchronized和volatitle实现线程安全的策略
什么是线程不安全 我对线程安全的理解就是多个线程同时操作一个共享变量时会产生意料之外的情况,这种情况就是线程不安全.注意:只有写操作才可能出现线程不安全,对共享变量只进行读操作线程是绝对安全的. 具体 ...
- Methods
string.prototype.trim() The trim() method removes whitespace from both ends of a string. Whitespace ...
- 分享几个网址二维码生成api
分享几个网址二维码生成api 传入网址参数,或许二维码图片,扫二维码能直接跳转网址 http://b.bshare.cn/barCode?site=weixin&url=https://www ...
- Python3解决棋盘覆盖问题的方法示例
本文实例讲述了Python3解决棋盘覆盖问题的方法.分享给大家供大家参考,具体如下: 问题描述: 在2^k*2^k个方格组成的棋盘中,有一个方格被占用,用下图的4种L型骨牌覆盖所有棋盘上的其余所有方格 ...
- 【转】如何用MTR诊断网络问题
MTR 是一个强大的网络诊断工具,管理员能够用它诊断和隔离网络错误,并向上游提供商提供有关网络状态的有用报告.MTR 通过更大的采样来跟踪路由,就像 traceroute + ping 命令的组合.本 ...
- Python脚本暴力破解SSH口令以及构建僵尸网络(pxssh)
目录 暴力破解SSH口令 SSH远端执行命令 构建僵尸网络 环境:Kali Linux python 2.7.13 暴力破解SSH口令 Pxssh是pexpect库的ssh专用脚本,他能用预先写好的 ...
- POJ1703带权并查集(距离或者异或)
题意: 有两个黑社会帮派,有n个人,他们肯定属于两个帮派中的一个,然后有两种操作 1 D a b 给出a b 两个人不属于同一个帮派 2 A a b 问a b 两个人关系 输出 同一个帮派 ...
- Linux中的.bash_ 文件详解
目录 .bash_history .bash_logout .bash_profile .bashrc 每个用户的根目录下都有四个这样的 bash文件,他们是隐藏文件,需要使用-a参数才会显示出来 . ...
- 【Git】5. 远程库(GitHub)相关操作
之前也提到了,在整个协作的过程中,必不可少的就是远程库了.Github作为一个全球最大的同性交友网站,同样也是一个非常强大的远程库. 现在希望将本地的hello.txt文件也推到github上去,那首 ...
- JVM默认内存大小
堆(Heap)和非堆(Non-heap)内存 按照官方的说法:"Java虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在Java虚拟机启动时创建的." ...