HDFS中NameNode工作机制
引言
NameNode:
- 存储元数据
- 管理整个HDFS集群
DataNode:
存储数据的block
SecondaryNameNode:
辅助HDFS完成一些事情
NameNode和SecondaryNameNode工作流程
编辑日志文件:edits
记载客户端对HDFS的增删改查的操作日志
镜像文件:fsimage
记载元数据(HDFS上存储的文件目录)及操作日志
NameNode和SecondaryNameNode工作机制
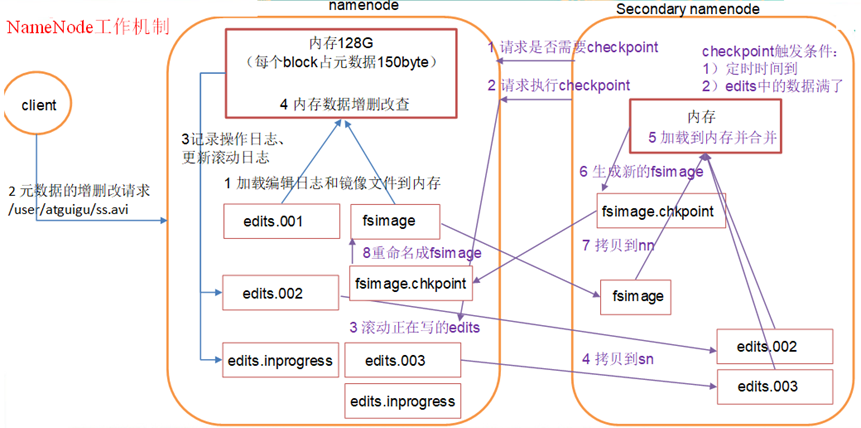
工作流程详解
- 第一阶段:namenode启动
- 第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求。
- namenode记录操作日志,更新滚动日志。
- namenode在内存中对数据进行增删改查。
- 第二阶段:Secondary NameNode工作
- Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
- Secondary NameNode请求执行checkpoint。
- namenode滚动正在写的edits日志。
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint到namenode。
- namenode将fsimage.chkpoint重新命名成fsimage。
chkpoint检查的两种触发条件
- 通常情况下,SecondaryNameNode每隔一小时执行一次检查点操作。
[hdfs-default.xml]
<!--两次检查点创建之间的固定时间间隔,默认3600,即1小时。所以去ann snn 看到的fsimage 相隔1个小时。--> <property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
- 一分钟检查namenode的事务数量。若检查事务数达到这个值1,000,000,也触发一次SecondaryNameNode的checkpoint操作。
<!--hdfs-site.xml文件设置-->
<!--事务数量配置-->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<!--检查是否满足数量的时间间隔周期-->
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
<!--在namenode上保存的fsimage的数目,超出的会被删除。默认保存2个。-->
<property>
<name>dfs.namenode.num.checkpoints.retained</name>
<value>2</value>
</property>
镜像文件和编辑日志文件
namenode被格式化之后,将在/opt/app/hadoop/data/tmp/dfs/name/current目录中产生如下文件:
由于我的NameNode没有格式化,只格式化了hadoop,并且将temp文件夹作为存储日志文件的文件夹,所以以下文件的访问目录均为:/opt/app/hadoop/temp/dfs/name/current
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
- Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
- seentxid文件:保存的是一个数字,就是最后一个edits的数字
- 每次Namenode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成Namenode启动的时候就将fsimage和edits文件进行了合并。
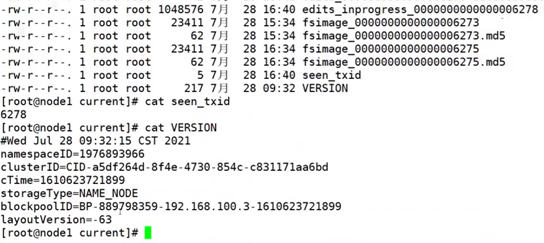
Notes:这些文件被意外删除后将无法恢复,需谨慎!
NameNode版本号
如上图:在/opt/app/hadoop/data/tmp/dfs/name/current这个目录下查看VERSION
namenode版本号具体解释:
- namespaceID:在HDFS上,会有多个Namenode,所以不同Namenode的namespaceID是不同的(主从架构:一个NameNode多个DataNode),分别管理一组blockpoolID。
- clusterID:集群id,全局唯一
- cTime:属性标记了NameNode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
- storageType:属性说明该存储目录包含的是NameNode的数据结构。
- blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。其针对每一个Namespace所对应blockpool的ID,该ID包括了其对应的NameNode节点的ip地址。
- layoutVersion:是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
SecondaryNameNode详解
SecondaryNameNode目录结构
SecondaryNameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
查看路径:/opt/app/hadoop/data/tmp/dfs/namesecondary/current
SecondaryNameNode的namesecondary/current目录和主NameNode的current目录的布局相同。好处:在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
NameNode恢复数据的方法
首先模拟NameNode损坏,即杀死NameNode进程:
kill -9 进程ID:强制将某进程杀死
方法一:将SecondaryNameNode中数据拷贝到namenode存储数据的目录;
方法二:使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode中数据拷贝到namenode目录中。
- 案例实操(一):模拟namenode故障,并采用方法一,恢复namenode数据
- kill -9 namenode进程/opt/app/hadoop/data/tmp/dfs/name)
rm -rf /opt/app/hadoop/data/tmp/dfs/name/*
拷贝SecondaryNameNode中数据到原namenode存储数据目录
cp -R /opt/app/hadoop/data/tmp/dfs/namesecondary/* /opt/app/hadoop/data/tmp/dfs/name/
重新启动namenode:
sbin/hadoop-daemon.sh start namenode
- 案例实操(二):模拟namenode故障,并采用方法二,恢复namenode数据
- 修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/bigdata/hadoop-2.8.5/data/tmp/dfs/name</value>
</property>
- kill -9 namenode进程
- 删除namenode存储的数据(/opt/app/hadoop/data/tmp/dfs/name)
rm -rf /opt/app/hadoop//data/tmp/dfs/name/*
- 如果SecondaryNameNode不和Namenode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到Namenode存储数据的平级目录
[uek@node2 dfs]$ pwd
/opt/app/hadoop/data/tmp/dfs
[uek@node2 dfs]$ ls
data name namesecondary
- 导入检查点数据(等待一会ctrl+c结束掉)
bin/hdfs namenode -importCheckpoint
- 启动namenode
sbin/hadoop-daemon.sh start namenode
- 如果提示文件锁了,可以删除in_use.lock
rm -rf /opt/app/hadoop/data/tmp/dfs/namesecondary/in_use.lock
Namenode多目录配置实现单机节点数据安全性问题
- namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
- 具体配置如下:
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>opt/app/hadoop/data/dfs/name1,opt/app/hadoop/data/dfs/name2</value>
</property>
集群安全模式操作
概述
Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。但是此刻,namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,namenode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。
在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以namenode不会进入安全模式。
基本语法
- 集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
- bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
- bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
- bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
- bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
案例
- 模拟等待安全模式
- 先进入安全模式:bin/hdfs dfsadmin -safemode enter
- 执行下面的脚本
编辑一个脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs -put ~/hello.txt /root/hello.txt
- 再打开一个窗口,执行:bin/hdfs dfsadmin -safemode leave
HDFS中NameNode工作机制的更多相关文章
- HDFS中DataNode工作机制
1.DataNode工作机制 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳). 2)DataNod ...
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
- NameNode&Secondary NameNode 工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- HDFS成员的工作机制
NameNode工作机制 nn负责管理块的元数据信息,元数据信息为fsimage和edits预写日志,通过edits预写日志来更新fsimage中的元数据信息,每次namenode启动时,都会将磁盘中 ...
- NameNode工作机制
NameNode工作机制
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- HDFS中NameNode管理元数据机制
NameNode职责 响应客户端请求 维护目录树 管理元数据(查询,修改) HDFS元数据存储 内存中有一份完整的元数据(特定数据结构) 磁盘有一个“准完整”的元数据的镜像文件 当客户端对HDFS中的 ...
- Hadoop_09_HDFS 的 NameNode工作机制
理解NameNode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优” “NameNode”故障问题的分析解决能力 1.NameNode职责: H ...
随机推荐
- Elasticsearch查询文档总数
前言 在使用ES搜索的时候,或多或少都会面临查询数据总量的情况,下面介绍三种查询数据总量的方式. 其中,方案二解决了当结果数据总量超过1w时,由于ES默认设置(max_result_window:10 ...
- POJ 1410 判断线段与矩形交点或在矩形内
这个题目要注意的是:给出的矩形坐标不一定是按照左上,右下这个顺序的 #include <iostream> #include <cstdio> #include <cst ...
- Octal Fractions java秒 C++
Octal Fractions 题目抽象: 将八进制小数转换成十进制小树.小数的为数很大. 可以用java 中的BigDeciaml 秒掉. time:297ms 1 import java. ...
- centos下nodejs,npm的安装和nodejs的升级
安装: sudo yum install epel-release sudo yum install nodejs node -v yum install -y npm --enablerepo=ep ...
- HGAME_easyVM
64位的exe,拖入ida64静态分析一波. 一.先是一大堆的赋值语句,有点懵,后面在分析handler的时候,也直接导致了我卡壳,这里还是得注意一下这些局部变量都是临近的,所以可以直接看成一个连续数 ...
- 两个有序数组合并为一个有序数组---python
def merge(a, b): """ 合并2个有序数组,默认a,b都是从小到大的有序数组 """ # 1.临时变量 i, j = 0, ...
- RWLock——一种细粒度的Mutex互斥锁
RWMutex -- 细粒度的读写锁 我们之前有讲过 Mutex 互斥锁.这是在任何时刻下只允许一个 goroutine 执行的串行化的锁.而现在这个 RWMutex 就是在 Mutex 的基础上进行 ...
- 4.Java基础
为了项目方便管理,创建空项目 一.注释 平时编写代码,在代码量比较少的时候,还可以看懂自己写的,但是当项目结构一复杂起来,我们就需要用到注释了 注释并不会被执行,是给写代码的人看的 书写注释是一个非常 ...
- Java之注解与反射
Java之注解与反射 注解(Annotation)简介 注解(Annotation)是从JDK5.0引入的新技术 Annotation作用:注解(Annotation)可以被其他程序如编译器等读取 A ...
- HTML5-CSS(四)
一.CSS3 渐变效果 (1)CSS3 提供了 linear-gradient 属性实现背景颜色的渐变功能.首先,我们先看一下它的样式表,如下: //两个必须参数background-image: l ...