pipeline input步骤
一.简介
执行imput步骤会暂停pipeline,直到用户输入参数。这是一种特殊的参数化pipeline的方法。
我们可以利用input步骤实现以下两种场景:
1.实现简易的审批流程。例如,pipeline暂停在部署前的阶段,由负责人点击确认后,才能部署。
2.实现手动测试阶段。在pipeline中增加一个手动测试阶段,该阶段中只有一个input步骤,当手动测试通过后,测试人员才可以通过这个unput步骤
在Jenkinsfile中加入input步骤
steps {
input message:"发布或者停止"
}
若只有message参数,则 input"发布或停止",需要点击按钮,才可以继续。
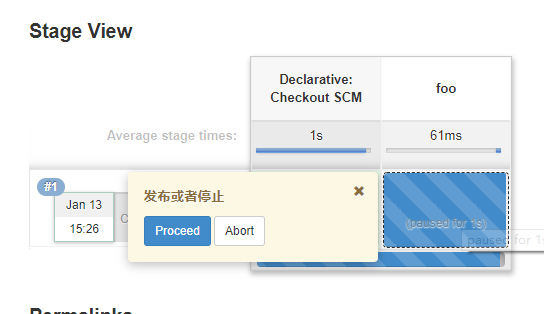
不管是哪个选项,日志都会记录是谁操作的,对审计很友好

二.input步骤复杂用法
//变量名,用于存储input步骤的返回值
def approvalMap
pipeline {
agent any
stages {
stage('pre deploy') {
steps {
script {
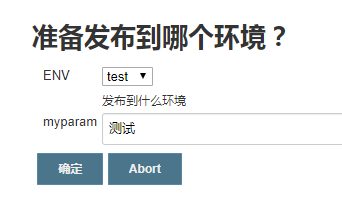
approvalMap = input(
message: '准备发布到哪个环境?',
ok:'确定',
parameters: [
choice(choices:'dev\ntest\nprod', description:'发布到什么环境?', name:'ENV'),
string(defaultValue:'', description:'', name:'myparam')
],
submitter:'admin,admin2,releaseGroup',
submutterParameter:'APPROVER'
)
}
}
}
stage('deploy') {
steps {
echo "操作者是 ${approvalMap['APPROVER']}"
echo "发布到什么环境? ${approvalMap['ENV']}"
echo "自定义参数: ${approvalMap['myparam']}"
}
}
}
}
在pipeline外定义了一个变量approvalMap。这是因为定义在阶段内的变量的作用域只在这个阶段中,而input步骤的返回值需要跨阶段使用,所以需要将其定义在pipeline外。
同时,由于在pipeline中直接使用了Groovy语法赋值表达式,所以需要将approvalMap=input(..) 放到script块中。
input步骤的返回值类型取决于要返回的值的个数。如果只有一个值,返回值类型就是这个值的类型。如果有多个值,返回值类型为Map类型。本实例返回的approvalMap就是一个map。Map的key就是每个参数的name属性,比如EVN,myparam都是key。
除了可以在返回的map中放手动输入的值,还可以放其他数据,比如submintterParameter:'APPROVER'代表将key APPROVER放到返回的map中。
步骤的参数:
- message: input步骤的提示信息
- submitter(可选) 字符串类型,可以进行操作的用户ID或用户组名,使用逗号分隔,在逗号左右不允许有空格。者在做input步骤的权限控制方面很实用。
- submitterParameter(可选):字符串类型,保存input步骤的实际操作者的用户名的变量名。
- ok(可选):自定义确定按钮的文本。
- parameters(可选):手动输入的参数列表。
- parameters指令支持的参数类型,input步骤都支持,写法一样
approvalMap还有一种定义方式,放在environment中。这样不需要定义顶部变量了。
environment {
approvalMap = ''
}
三.获取上游pipeline信息
上游pipeline触发下游pipeline时,并没有自动带上自身的信息。所以,当下游pipeline需要使用上游pipeline的信息时,上游pipeline信息就要以参数的方式传给下游pipeline。比如在上游pipeline中调用下游pipeline时,可以采用以下做法。
build job: 'all-in-one-deploy', parameters: [
string(name:'DEPLOY_ENV', value: "${deploy_env}"),
string(name:'triggerJobName', value:"${env.JOB_NAME}"),
string(name:'triggerJobBuildNumber', value:"${env.BUILD_NUMBER}")
]
四.超时中止
input步骤可以与timeout步骤实现超时自动中止pipeline,防止无限等待。以下pipeline一小时不处理就自动终止
steps{
timeout(time:1,unit:'HOURS') {
inout message:"发布或停止"
}
}
pipeline input步骤的更多相关文章
- 效验pipeline语法
目录 一.简介 二.配置 一.简介 因为jenkins pipeline不像JAVA之类的语言那样应用广泛,所以没有相关的代码检测插件. 2018年11月初,Jenkins官方博客介绍了一个VS Co ...
- Jenkins系列之pipeline语法介绍与案例
Jenkins Pipeline 的核心概念: Pipeline 是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化. ...
- Docker的Jenkins Pipeline工作流
原文地址:http://www.youruncloud.com/blog/127.html 分享主题 一个软件产品的开发周期中,尤其是敏捷开发,持续集成和持续部署是必不可少的环节,而随着产品的丰富,模 ...
- 管道式编程(Pipeline Style programming)
受 F# 中的管道运算符和 C# 中的 LINQ 语法,管道式编程为 C# 提供了更加灵活性的功能性编程.通过使用 扩展函数 可以将多个功能连接起来构建成一个管道. 前言 在 C# 编程中,管道式编程 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
- pipeline 共享库
目录 一.简介 二.共享库扩展 共享库使用 共享库结构 pipeline模板 一些小问题 三.共享库例子 使用公共变量 使用共享库的src方法 使用共享库的vars方法 四.插件实现pipeline ...
- Tcl与Design Compiler (八)——DC的逻辑综合与优化
本文属于原创手打(有参考文献),如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 对进行时序路径.工作环 ...
- linux实训
目 录 Unit 1 操作系统安装.... 3 1.1 多操作系统安装... 3 1.1.1 VMware简介... 3 1.1.2 VMWare基本使用... 4 1.2 安装Red Hat Li ...
- 美团店铺评价语言处理以及文本分类(logistic regression)
美团店铺评价语言处理以及分类(LogisticRegression) 第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 本文是该系列的第四篇 主要讨论逻辑回归分类算法的参数 ...
随机推荐
- Django笔记&教程 4-2 模型(models)中的Field(字段)
Django 自学笔记兼学习教程第4章第2节--模型(models)中的Field(字段) 点击查看教程总目录 参考:https://docs.djangoproject.com/en/2.2/ref ...
- 手把手教你学Dapr - 7. Actors
上一篇:手把手教你学Dapr - 6. 发布订阅 介绍 Actor模式将Actor描述为最低级别的"计算单元".换句话说,您在一个独立的单元(称为actor)中编写代码,该单元接收 ...
- python-变量&底层存储原理
目录 1.变量 1.变量如何使用 2.变量存储的原理 --[ 重点 ] 3.变量存储要遵循印射关系 4.变量三要素 2.常量 3.底层优化 4.垃圾回收机制 1.变量 1.变量如何使用 1.什么是变量 ...
- win10让人愤怒的磁盘占用100%问题
升级win10以后其他还好.但是系统经常响应非常非常慢,后来观察发现每次非常卡的时候我的磁盘占用就是100%的. 我是技嘉的B85主板. 1盘是128g的东芝SSD(GPT), 2盘是WD的3TB H ...
- 『学了就忘』Linux用户管理 — 51、用户管理相关命令
目录 1.添加用户(useradd命令) 2.设定密码(passwd命令) 3.用户信息修改(usermod命令) 4.删除用户(userdel命令) 5.切换用户身份(su命令) 1.添加用户(us ...
- idea给类增加注释
File-->Settings-->Editor-->File and Code Templates 找到class #if (${PACKAGE_NAME} && ...
- Python实战:截图识别文字,过万使用量版本!(附源码!!)
前人栽树后人乘凉,以不造轮子为由 使用百度的图片识字功能,实现了一个上万次使用量的脚本. 系统:win10 Python版本:python3.8.6 pycharm版本:pycharm 2021.1. ...
- nvm安装以及管理多版本node教程
安装nvm.node.npm 下载nvm安装包,推荐使用1.1.7,我个人使用1.1.8会有中文乱码的报错 点击exe文件,注意修改nvm的安装根目录以及node的安装根目录,后者是以后管理多版本no ...
- 模数不超过 long long 范围时的快速乘
笔者的话:使用前请确保评测系统的long double严格为16B ! 模数不在 int 范围内的乘法在 OI 中运用广泛,例如Millar-Rabin,Pollard-Rho等等.这样的乘法,直接乘 ...
- 除了GO基因本体论,还有PO、TO、CO等各种Ontology?
目录 PO/TO CO 后记 我们最常用最熟悉的功能数据库之一:GO(gene onotology),基因本体论.其实是一套标准词汇术语,目的是从不同角度来描述某个基因的特点和功能,三大本体如生物学进 ...