Python格式处理
一.CVS表格
import csv
villains = [
['Doctor', 'No'],
['Rosa', 'Klebb'],
['Mister', 'Big'],
['Auric', 'Goldfinger'],
['Ernst', 'Blofeld'],
]
with open('villains', 'wt') as fout: # 一个上下文管理器
csvout = csv.writer(fout)
csvout.writerows(villains)
#读取cvs
with open('villains', 'rt') as fin: # 一个上下文管理器
cin = csv.reader(fin)
villains = [row for row in cin] # 使用列表推导式
print(villains)
#读取成字典方式
with open('villains', 'rt') as fin:
cin = csv.DictReader(fin, fieldnames=['first', 'last'])
villains = [row for row in cin]
#将字典写入成标题在上面的方式
villains = [
{'first': 'Doctor', 'last': 'No'},
{'first': 'Rosa', 'last': 'Klebb'},
{'first': 'Mister', 'last': 'Big'},
{'first': 'Auric', 'last': 'Goldfinger'},
{'first': 'Ernst', 'last': 'Blofeld'},
]
with open('villains', 'wt') as fout:
cout = csv.DictWriter(fout, ['first', 'last'])
cout.writeheader()
cout.writerows(villains)
with open('villains', 'rt') as fin: #重头读取文件
cin = csv.DictReader(fin)
villains = [row for row in cin]
二.xml
menu.xml
<?xml version="1.0"?>
<menu>
<breakfast hours="7-11">
<item price="$6.00">breakfast burritos</item>
<item price="$4.00">pancakes</item>
</breakfast>
<lunch hours="11-3">
<item price="$5.00">hamburger</item>
</lunch>
<dinner hours="3-10">
<item price="8.00">spaghetti</item>
</dinner>
</menu>
import xml.etree.ElementTree as et
tree = et.ElementTree(file='menu.xml')
root = tree.getroot()
root.tag
#tag是标签字符串,attrib是属性的一个字典
for child in root:
print('tag:', child.tag, 'attributes:', child.attrib)
for grandchild in child:
print('\ttag:', grandchild.tag, 'attributes:', grandchild.attrib)
len(root) #菜单选择数目
len(roo[0]) #早餐项的数目
三.json
json字符串
menu = \
{
"breakfast": {
"hours": "7-11",
"items": {
"breakfast burritos": "$6.00",
"pancakes": "$4.00"
}
},
"lunch" : {
"hours": "11-3",
"items": {
"hamburger": "$5.00"
}
},
"dinner": {
"hours": "3-10",
"items": {
"spaghetti": "$8.00"
}
}
}
import json
menu_json = json.dumps(menu)
menu_json
menu2 = json.loads(menu_json) #解析成python结构
import datetime
now = datetime.datetime.utcnow()
json.dumps(now) #无法转换,因为标准json没有定义日期
#转换
now_str = str(now)
json.dumps(now_str) #可以转换了
from time import mktime
now_epoch = int(mktime(now.timetuple()))
json.dumps(now_epoch) #可以转换epoch值
class DTEncoder(json.JSONEncoder): #继承重载default方法
def default(self, obj):
# isinstance()检查obj的类型
if isinstance(obj, datetime.datetime):
return int(mktime(obj.timetuple()))
# 否则是普通解码器知道的东西:
return json.JSONEncoder.default(self, obj)
json.dumps(now, cls=DTEncoder)
四.yml
import yaml
with open('mcintyre.yaml', 'rt') as fin:
text = fin.read()
data = yaml.load(text)
data['details']
len(data['poems'])
data['poems'][1]['title'] #获得第二行
五.配置文件
[english]
greeting = Hello
[french]
greeting = Bonjour
[files]
home = /usr/local
# 简单的插入:
bin = %(home)s/bin
import configparser
cfg = configparser.ConfigParser()
cfg.read('settings.cfg')
cfg['french']
cfg['french']['greeting']
cfg['files']['bin']
#返回节点列表
config.sections()
#指定节点下的
config.options(section)
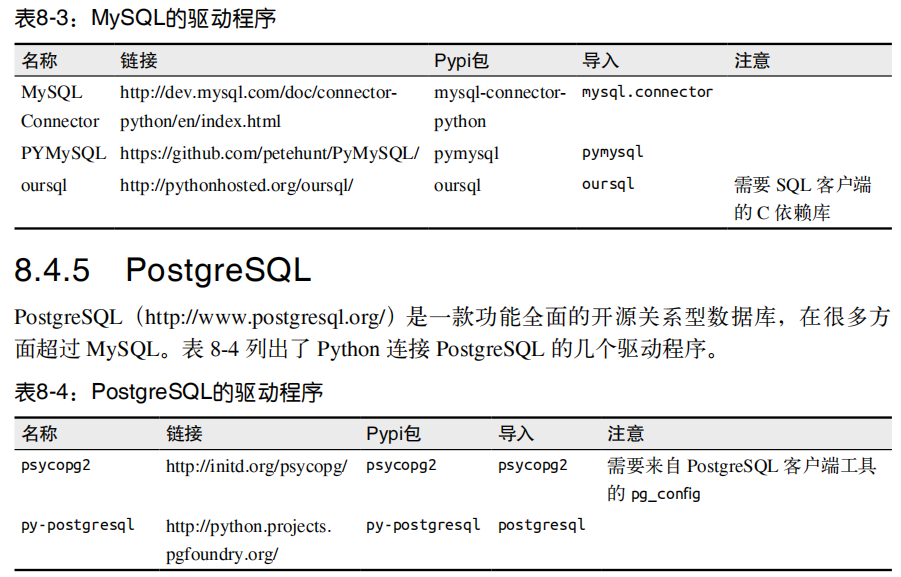
六.数据库
连接数据库,包含参数用户名、密码、服务器地址
connect()
创建一个cursor对象来管理查询
cursor()
对数据库执行一个或多个SQL命令
execute() 和 executemany()
得到execute之后的结果
fetchone()、fetchmany() 和 fetchall()
import sqlite3
conn = sqlite3.connect('enterprise.db')
curs = conn.cursor()
curs.execute('''CREATE TABLE zoo
(critter VARCHAR(20) PRIMARY KEY,
count INT,
damages FLOAT)''')
curs.execute('INSERT INTO zoo VALUES("duck", 5, 0.0)') #新增动物
curs.execute('INSERT INTO zoo VALUES("bear", 2, 1000.0)')
ins = 'INSERT INTO zoo (critter, count, damages) VALUES(?, ?, ?)'
curs.execute(ins, ('weasel', 1, 2000.0)) #更安全的插入数据方法
curs.execute('SELECT * FROM zoo') #获取数据
curs.fetchall()
curs.execute('SELECT * from zoo ORDER BY count') #按照count排序
curs.fetchall()
curs.execute('''SELECT * FROM zoo WHERE #哪种动物花费最多
damages = (SELECT MAX(damages) FROM zoo)''')
curs.close() #打开后要关闭
Python格式处理的更多相关文章
- python格式转换的记录
Python的格式转换太难了. 与其说是难,具体来说应该是"每次都会忘记该怎么处理".所以于此记录,总的来说是编码+格式转换的记录. 本文记录环境:python3.6 经常见到的格 ...
- PYTHON 格式字符串中的填充符
使用 %类型 来填充 常用的有:%s 填充字符串类型:%d 填充 int 类型:这里是沿用了 C语言中 printf() 函数中的格式,更多的信息请查看:完整列表 name = 'tommy' mes ...
- Python格式符说明
格式化输出 例如我想输出 我的名字是xxxx 年龄是xxxx name = "Lucy"age = 17print("我的名字是%s,年龄是%d"%(name, ...
- f-Strings:一种改进Python格式字符串的新方法
好消息是,F字符串在这里可以节省很多的时间.他们确实使格式化更容易.他们自Python 3.6开始加入标准库.您可以在PEP 498中阅读所有内容. 也称为“格式化字符串文字”,F字符串是开头有一个f ...
- Python——格式输出,基本数据
一.问题点(有待解决) 1.Python中只有浮点数,20和20.0是否一样? from decimal import Decimal a = Decimal('1.3') round() 参考文章 ...
- python 格式话-占位符
格式化输出:name = qjage = 30job = itsalary = 6000例1:字符串拼接方法,不建议,因为会在内存中开辟多块内存空间. info = '''---------- inf ...
- Python格式输出汇总
print ('%10s'%('test')) print ('{:<10}'.format('test'))#left-aligned print ('{:>10}'.format('t ...
- python格式字符
- Python web后端接收到的json数据有前端格式的布尔值 true false
最近在后端处理前端传过来的json数据,发现,因为数据是各种数据格式的嵌套,使用json.loads(),无法将内层的数据转换为原来格式的数据,所以需要使用eval( )函数进行转换,但是如果数据含有 ...
随机推荐
- OPPO 图数据库平台建设及业务落地
本文首发于 OPPO 数智技术公众号,WeChat ID: OPPO_tech 1.什么是图数据库 图数据库(Graph database)是以图这种数据结构存储和查询的数据库.与其他数据库不同,关系 ...
- 来了!公开揭密团队成员开发鸿蒙 OpenHarmony 的完整过程(收获官方7000奖金和开发板等,1w字用心总结)
背景 随着 OpenHarmony 组件开发大赛结果公布,我们的团队成员被告知获得了二等奖,在开心之余也想将我们这段时间宝贵的开发经验写下来与大家分享,当我们看到参赛通知的时候已经是 9 月中旬的时候 ...
- 为什么前端H5工程师工资那么高?
目前,企业对于html5前端开发人才需求量非常大,小到企业网站.个人主页,大到政府部门,都是通过网站向外界展示形象.传播信息,网站离不开HTML5前端开发人员,所以学习html5前端开发在当前社会非常 ...
- vue-cli的安装步骤
1.安装Node.js 在Node.js官网 https://nodejs.org/zh-cn/下载安装包,修改安装路径到其它盘,如 G:\Program Files 2.设置 cnpm的下载路径和缓 ...
- 彻底搞清楚 JavaScript 的原型和原型链
JavaScript真的挺无语的,怪不得看了那么多的介绍文章还是一头雾水,直到自己终于弄懂了一点点之后才深有体会: 先从整体说起吧,发现没有基础做依据,那都是空中楼阁: 先从基础开始介绍吧,又发现基础 ...
- Codeforces 1500F - Cupboards Jumps(set)
Codeforces 题面传送门 & 洛谷题面传送门 nb tea!!!111 首先很显然的一件事是对于三个数 \(a,b,c\),其最大值与最小值的差就是三个数之间两两绝对值的较大值,即 \ ...
- Codeforces 516D - Drazil and Morning Exercise(树的直径+并查集)
Codeforces 题目传送门 & 洛谷题目传送门 这是一道 jxd 的作业题,感觉难度不是特别大(虽然我并没有自己独立 AC,不过也可能是省选结束了我的脑子也没了罢(((,就随便写写罢 u ...
- NextPolish对基因组进行polish
NextPolish由未来组开发对基因组序列进行polish的工具,对三代以及二代均可进行polish. gituhp地址:https://github.com/Nextomics/NextPolis ...
- shell 脚本自动插入文件头
vim编辑shell脚本自动插入文件头部信息,将下面的代码写入home目录xia .vimrc 文件即可. shell 文件头: 1 autocmd BufNewFile *.sh exec &quo ...
- 10.Power of Two-Leetcode
Given an integer, write a function to determine if it is a power of two. class Solution { public: bo ...