Serverless 在大规模数据处理的实践
作者 | 西流 阿里云技术专家
前言
当您第一次接触 Serverless 的时候,有一个不那么明显的新使用方式:与传统的基于服务器的方法相比,Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效。这主要是因为 Serverless 可以不必为闲置的资源付费,不用担心预留的资源不够。而在传统的使用范式中,用户必须预留成百上千的服务器来做一些高度并行化但执行时长较短的任务,而且必须为每一台服务器买单,即使有的服务器已经不再工作了。
以阿里云 Serverless 产品——函数计算为例,便可以完美解决您上述所有顾虑:
如果您的任务本身计算量不是很大,但是有大量的并发任务请求需要并行处理, 比如多媒体文件处理、文档转换等;
一个任务本身计算量很大,要求单个任务很快处理完,并且还能支持并行处理多个任务。
在这种场景下,用户唯一关注的就是:您的任务是可以分治拆解并且子任务是可以并行处理的,一个需要一个小时才能处理完的长任务,可以分解成 360 个独立的 10 秒长的子任务并行处理,这样,以前您要花一个小时才能处理完的任务,现在只需要 10 秒就可以搞定。由于采用的是按量计费的模型,完成的计算量和成本是大致相当的,而传统模型则因为预留资源肯定会存在浪费,浪费的费用也是需要您去承担的。
接下来,将详细阐述 Serverless 在大规模数据处理上的实践。
极致弹性扩缩容应对计算波动
在介绍相关的大规模数据处理示例之前, 这里先简单介绍一下函数计算。
1. 函数计算简介
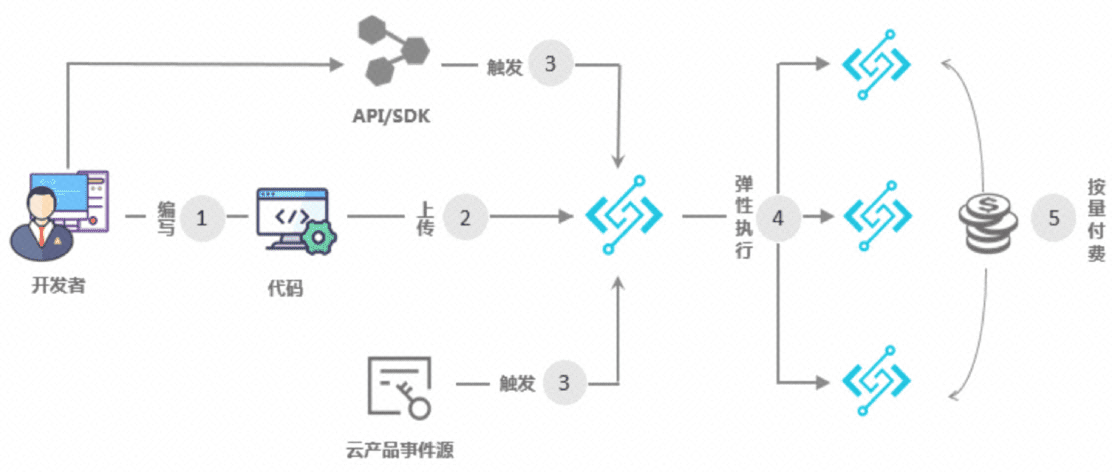
开发者使用编程语言编写应用和服务,函数计算支持的开发语言请参见开发语言列表;
开发者上传应用到函数计算;
触发函数执行:触发方式包括 OSS、API 网关、日志服务、表格存储以及函数计算 API、SDK 等;
动态扩容以响应请求:函数计算可以根据用户请求量自动扩容,该过程对您和您的用户均透明无感知;
根据函数的实际执行时间按量计费:函数执行结束后,可以通过账单来查看执行费用,收费粒度精确到 100 毫秒。
详情:函数计算官网
至此,您大约可以简单理解到函数计算是怎么运作的,接下来以大量视频并行转码的案例来阐述:假设一家在家教育或娱乐相关的企业,老师授课视频或者新的片源一般是集中式产生,而您希望这些视频被快速转码处理完以便能让客户快速看到视频回放。比如在当下疫情中,在线教育产生的课程激增,而出课高峰一般是 10 点、12 点、16 点、18 点等明显的峰值段,特定的时间内(比如半个小时)处理完所有新上传的视频是一个通用而且普遍的需求。
2. 弹性高可用的音视频处理系统
- OSS 触发器

如上图所示,用户上传一个视频到 OSS,OSS 触发器自动触发函数执行,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码,并且将转码后的视频保存回 OSS。
- 消息触发器

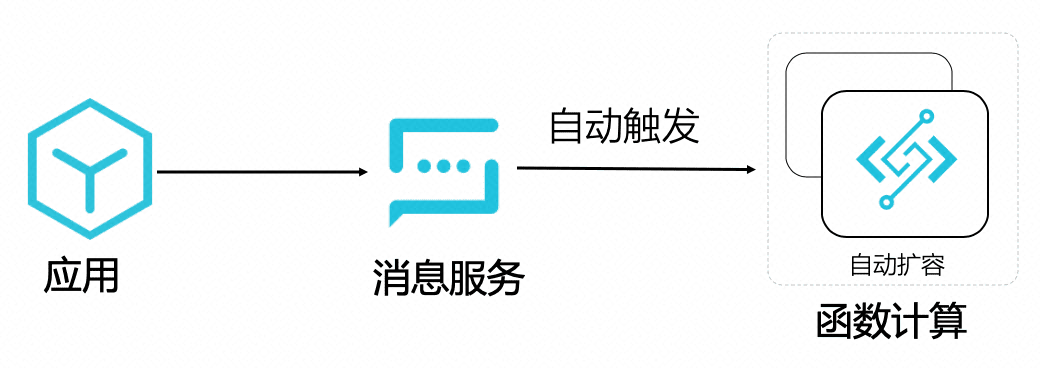
如上图所示,应用只需要发一个消息,自动触发函数执行音视频处理的任务即可,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码, 并且将转码后的视频保存回 OSS。
- 直接手动调用 SDK 执行音视频处理任务
以 python 为例,大致如下:
python # -- coding: utf-8 -- import fc2 import json client = fc2.Client(endpoint="http://123456.cn-hangzhou.fc.aliyuncs.com",accessKeyID="xxxxxxxx",accessKeySecret="yyyyyy") # 可选择同步/异步调用 resp = client.invoke_function("FcOssFFmpeg", "transcode", payload=json.dumps( { "bucket_name" : "test-bucket", "object_key" : "video/inputs/a.flv", "output_dir" : "video/output/a_out.mp4" })).data print(resp)
从上面我们也可以看出,触发函数执行的方式也很多,同时简单配置下 SLS 日志,就可以很快实现一个弹性高可用、按量付费的音视频处理系统,同时能提供免运维、具体业务数据可视化、强大自定义监控报警等超强功能的 dashboard。
目前已经落地的音视频案例有 UC、语雀、躺平设计之家、虎扑以及几家在线教育的头部客户等,其中有些客户高峰期间,弹性使用到了万核以上 CPU 计算资源,并行处理的视频达到 1700+,同时提供了极高的性价比。
详情可以参考:
任务分治,并行加速
这种将任务分而治之的思想应用在函数计算上是一件有趣的事情,在这里举一个例子,比如您有一个超大的 20G 的 1080P 高清视频需要转码,即使您使用一台高配机器,需要的时间可能还是要按小时计,如果中途出问题中断转码,您只能重新开始再重复一遍转码的过程,如果您使用分治的思想+函数计算,转码的过程衍变为 分片-> 并行转码分片-> 合并分片,这样就可以解决您上述的两个痛点:
分片和合成分片是内存级别的拷贝,需要的计算量极小,真正消耗计算量的转码,拆分成了很多子任务并行处理,在这个模型中,分片转码的最大时间基本等同于整个大视频的转码时间;
即使中途某个分片转码出现异常,只需要重试这个分片的转码即可,不需要整个大任务推倒重来。
通过将大任务合理的分解,配合使用函数计算,编写一点 code,就可以快速完成一个弹性高可用、并行加速、按量付费的大型数据处理系统。
在介绍这个方案之前,我们先简单介绍一下 Serverless 工作流,Serverless 工作流可以很好地将函数和其他云服务和自建服务有组织地编排起来。
1. Serverless 工作流简介
Serverless 工作流(Serverless Workflow)是一个用来协调多个分布式任务执行的全托管云服务。在 Serverless 工作流中,您可以用顺序、分支、并行等方式来编排分布式任务,Serverless 工作流会按照设定好的步骤可靠地协调任务执行,跟踪每个任务的状态转换,并在必要时执行用户定义的重试逻辑,以确保工作流顺利完成。Serverless 工作流简化了开发和运行业务流程所需要的任务协调、状态管理以及错误处理等繁琐工作,让您聚焦业务逻辑开发。
接下来以一个大视频快速转码的案例来阐述 Serverless 工作编排函数,实现大计算任务的分解,并行处理子任务,最终达到快速完成单个大任务的目的。
2. 大视频的快速多目标格式转码
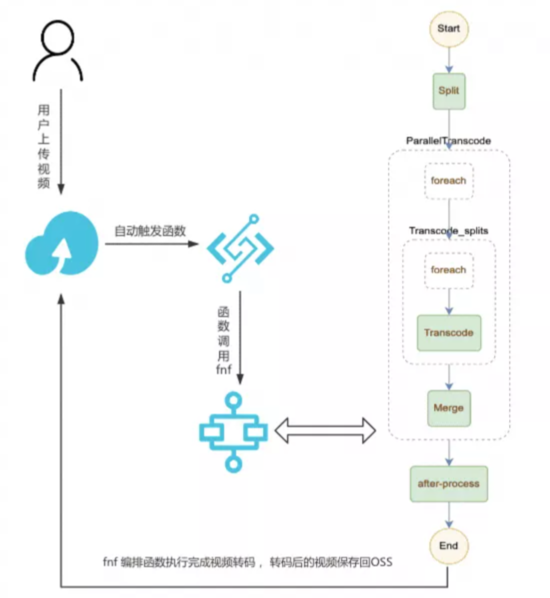
如下图所示,假设用户上传一个 mov 格式的视频到 OSS,OSS 触发器自动触发函数执行,函数调用 FnF 执行,FnF 同时进行 1 种或者多种格式的转码(由 template.yml 中的 DST_FORMATS 参数控制),假设配置的是同时进行 mp4 和 flv 格式的转码。
一个视频文件可以同时被转码成各种格式以及其他各种自定义处理,比如增加水印处理或者在 after-process 更新信息到数据库等;
当有多个文件同时上传到 OSS,函数计算会自动伸缩,并行处理多个文件,同时每次文件转码成多种格式也是并行;
结合 NAS + 视频切片,可以解决超大视频的转码,对于每一个视频,先进行切片处理,然后并行转码切片,最后合成,通过设置合理的切片时间,可以大大加快较大视频的转码速度;
fnf 可以跟踪每一步执行情况,并且可以自定义每一个步骤的重试,提高任务系统的鲁棒性,如:retry-example
详情可以参考:fc-fnf-video-processing
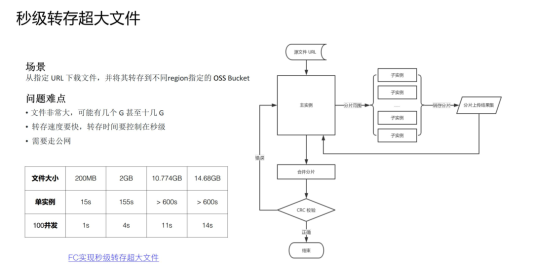
在任务分治,并行加速具体的案例中,上面分享的是 CPU 密集型任务分解,但也可以进行 IO 密集型任务分解,比如这个需求:上海的 region 的 OSS bucket 中的一个 20G 大文件,秒级转存回杭州的 OSS Bucket 中。这里也可以采用分治的思路,Master 函数在接到转存任务之后,将超大文件进行分片的 range 分配给每个 Worker 子函数,Worker 子函数并行转存属于自己那部分的分片,Master 函数待所有子 Worker 运行完毕之后,提交合并分片请求,完成整个转存任务。
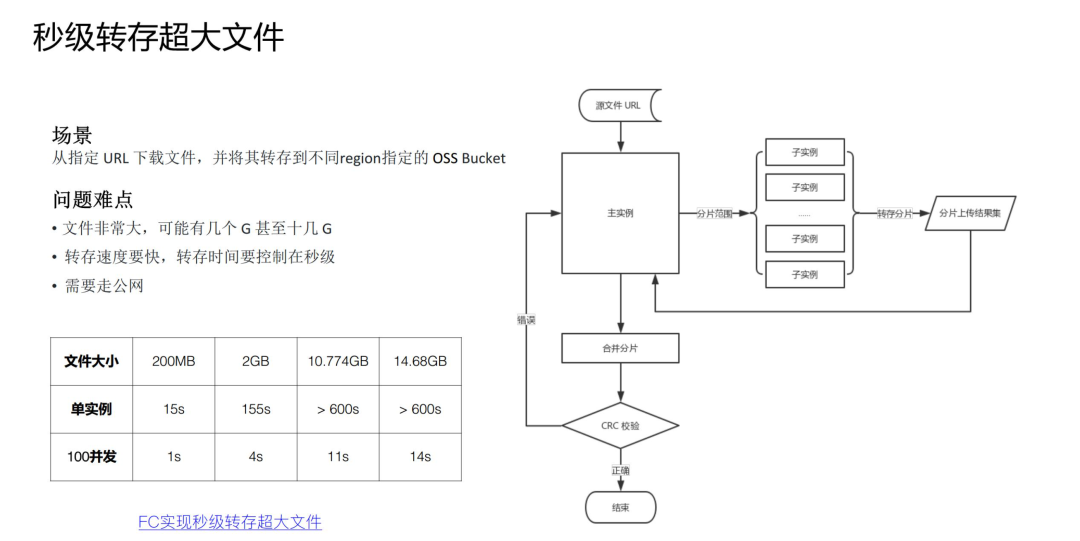
详情可以参考:利用函数计算多实例并发实现秒级转存超大文件
总结
本文探讨了 Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效,并给出了具体的实践案例,无论在 CPU 密集型还是 IO 密集型场景,函数计算 + Serverless 都能完美解决您以下顾虑:
不必为闲置的资源付费
不用担心计算资源预留不够
大计算量的任务需要快速处理完毕
更好的任务流程跟踪
完善的监控报警、免运维、业务数据可视化等
....
本文中对于 Serverless 音视频处理只是一个示例,它展示的是函数计算配合 Serverless 工作流在离线计算场景中的能力和独一无二的优势。我们可以用发散的方式去拓展 Serverless 在大规模数据处理实践的边界,比如AI、基因计算、科学仿真等。希望本篇文章能吸引您,开启您的 Serverless 奇妙之旅。
Serverless 在大规模数据处理的实践的更多相关文章
- BloomFilter–大规模数据处理利器(转)
BloomFilter–大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求1 ...
- 微软开源大规模数据处理项目 Data Accelerator
微软开源了一个原为内部使用的大规模数据处理项目 Data Accelerator.自 2017 年开发以来,该项目已经大规模应用在各种微软产品工作管道上. 据微软官方开源博客介绍,Data Accel ...
- BloomFilter–大规模数据处理利器
转自: http://www.dbafree.net/?p=36 BloomFilter–大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法. ...
- BloomFilter ——大规模数据处理利器
BloomFilter——大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求 ...
- arcpy模块下的并行计算与大规模数据处理
一个多星期的时间,忍着胃痛一直在做GIS 540: Spatial Programming的课程项目,导致其他方面均毫无进展,可惜可惜.在这个过程当中临时抱佛脚学习了很多Python相关的其他内容,并 ...
- 大规模数据处理Apache Spark开发
大规模数据处理Apache Spark开发 Spark是用于大规模数据处理的统一分析引擎.它提供了Scala.Java.Python和R的高级api,以及一个支持用于数据分析的通用计算图的优化引擎.它 ...
- python大规模数据处理技巧之一:数据常用操作
面对读取上G的数据,python不能像做简单代码验证那样随意,必须考虑到相应的代码的实现形式将对效率的影响.如下所示,对pandas对象的行计数实现方式不同,运行的效率差别非常大.虽然时间看起来都微不 ...
- Serverless 实战 —— 函数计算 + Typescript 实践
前言 首先介绍下在本文出现的几个比较重要的概念: 函数计算(Function Compute):函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传.函数计算准 ...
- Serverless 下的微服务实践
作者:弈川 审核&校对:筱姜.潇航 编辑&排版:雯燕 微服务架构介绍 微服务架构诞生背景 在互联网早期即 Web 1.0 的时代,当时流行的是单体应用,研发团队比较小,主要是外部网页, ...
随机推荐
- Linux云服务部署Spring boot项目
Linux云服务部署Spring boot项目 背景: 之前经过两个周的时间,做了一个简单的博客网站,网址:点击进入,在本地可以正常使用以后,想着部署到服务器上,给大家伙看个乐呵,于是有了这篇部署文章 ...
- Redis笔记(一)
redis:1.什么是缓存? mybatis一级缓存和二级缓存 mybatis的一级缓存存在哪? SqlSession,就不会再走数据库 什么情况下一级缓存会失效? 当被更新,删除的时候sqlsess ...
- Mysql 5.6 编译报错
编译安装 mysql(下面是编译参数) /usr/local/bin/cmake . -DCMAKE_INSTALL_PREFIX=/application/mysql-5.6.36 \ -DMYSQ ...
- 【Spring 5.x】学习笔记汇总
Spring 工厂 工厂设计模式.第一个Spring程序细节分析.整合日志框架 注入详解 - Set注入(JDK内置类型,用户自定义类型).构造注入(重载) 反转控制与依赖注入.Spring工厂创建复 ...
- Cookie在哪里看
更多java学习请进: https://zhangjzm.gitee.io/self_study
- xxs攻击
1 XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中.比如这些代码包括HTML代码和客户端脚本.攻击者利用XSS漏洞旁路掉访问控制--例如 ...
- C#多线程开发-任务并行库04
你好,我是阿辉. 之前学习了线程池,知道了它有很多好处. 使用线程池可以使我们在减少并行度花销时节省操作系统资源.可认为线程池是一个抽象层,其向程序员隐藏了使用线程的细节,使我们可以专心处理程序逻辑, ...
- Redis哨兵机制的实现及与SpringBoot的整合
1. 概述 前面我们聊过Redis的读写分离机制,这个机制有个致命的弱点,就是主节点(Master)是个单点,如果主节点宕掉,整个Redis的写操作就无法进行服务了. 为了解决这个问题,就需要依靠&q ...
- NAT-T下的端口浮动
1. IKE端口浮动 IPsec在隧道建立第一第二阶段主要进行加密方式.加密策略等信息的协商,这部分功能是通过IKE协议来实现的. IKE协议默认端口为500,但是如果IPsec隧道传输路径上存在NA ...
- C# AutoMaper使用自定义主键
有时候实际业务中主键不一定叫Id,比如示例数据库Northwind中的RegionID,TerritoryID等,本示例用Abp框架并以Northwind数据库Region表为数据依据 一.在Core ...