6.深入TiDB:乐观事务
本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本
事务模型概述
由于 TiDB 的事务模型沿用了 Percolator 的事务模型。所以先从 Percolator 开始,关于 Percolator 论文没看过的同学看这里:https://www.luozhiyun.com/archives/609 我已经翻译好了
Percolator 分布式事务
Percolator实现分布式事务主要基于3个实体:Client、TSO、BigTable。
- Client是事务的发起者和协调者
- TSO为分布式服务器提供一个精确的,严格单调递增的时间戳服务。
- BigTable 是Google实现的一个多维持久化Map。
Percolator存储一列数据的时候,会在BigTable中存储多列数据:
- data列(D列): 存储 value
- lock列(L列): 存储用于分布式事务的锁信息
- write列(W列):存储用于分布式事务的提交时间(commit_timestamp)
Percolator的分布式写事务是由2阶段提交(后称2PC)实现的。不过它对传统2PC做了一些修改。一个写事务事务开启时,Client 会从 TSO 处获取一个 timestamp 作为事务的开始时间(后称为start_ts)。在提交之前,所有的写操作都只是缓存在内存里。提交时会经过 prewrite 阶段和 commit阶段,一个写事务可以包含多个写操作。
写操作
Prewrite
- 在事务开启时会从 TSO 获取一个 timestamp 作为 start_ts;
- 在所有行的写操作中选出一个作为 primary,其他的为 secondaries;
- 对primary行写入L列,即上锁,上锁前会检查是否有冲突:
- 检查L列是否已经有别的客户端已经上锁,直接 Abort 整个事务;
- 检查W列是否在本次事务开始时间之后有事务已提交,检查 W列,是否有更新 [start_ts, +Inf) 之间是否存在相同 key 的数据 。如果存在,则说明存在 W列 conflict ,直接 Abort 整个事务;
- 如果没有冲突的话,则上锁,以 start_ts 作为 Bigtable 的 timestamp,将数据写入 data 列,由于此时 write 列尚未写入,因此数据对其它事务不可见;
Commit
如果 Prewrite 成功,则进入 Commit 阶段:
- 从TSO处获取一个timestamp作为事务的提交时间(后称为commit_ts);
- 提交primary, 如果失败,则abort事务;
- 检查primary上的lock是否还存在,如果不存在,则abort。(其他事务有可能会认为当前事务已经失败,从而清理掉当前事务的lock);
- 以commit_ts为timestamp, 写入W列,value为start_ts,清理L列的数据。注意,此时为Commit Point,“写W列”和“清理L列”由BigTable的单行事务保证ACID;
- 一旦primary提交成功,则整个事务成功。此时已经可以给客户端返回成功了,再异步的进行 secondary 提交。seconary 提交无需检测 lock 列锁是否还存在,一定不会失败;
读操作
- 检查该行是否有 L 列,时间戳为 [0, start_ts],如果有,表示目前有其他事务正占用此行,如果这个锁已经超时则尝试清除,否则等待超时或者其他事务主动解锁;
- 如果步骤 1 发现锁不存在,则可以安全的读取;
TiDB 乐观事务实现分析
begin 事务
每个 client connection 对应着一个 session , 事务相关数据的放在了 session 中, 它包含了对 KVStore 和 Txn 接口的引用。
func (s *session) NewTxn(ctx context.Context) error {if err := s.checkBeforeNewTxn(ctx); err != nil {return err}// 开启事务txn, err := s.store.BeginWithOption(tikv.DefaultStartTSOption().SetTxnScope(s.sessionVars.CheckAndGetTxnScope()))if err != nil {return err}...return nil}
KVStore 定义了Begin/BeginWithOption,用来创建开始一个事务。如上代码,session 的 NewTxn 方法中调用 KVStore 的 BeginWithOption 方法创建开始一个事务。
func (s *KVStore) Begin() (*KVTxn, error) {return s.BeginWithOption(DefaultStartTSOption())}func (s *KVStore) BeginWithOption(options StartTSOption) (*KVTxn, error) {return newTiKVTxnWithOptions(s, options)}
Begin/BeginWithOption调用图如下:
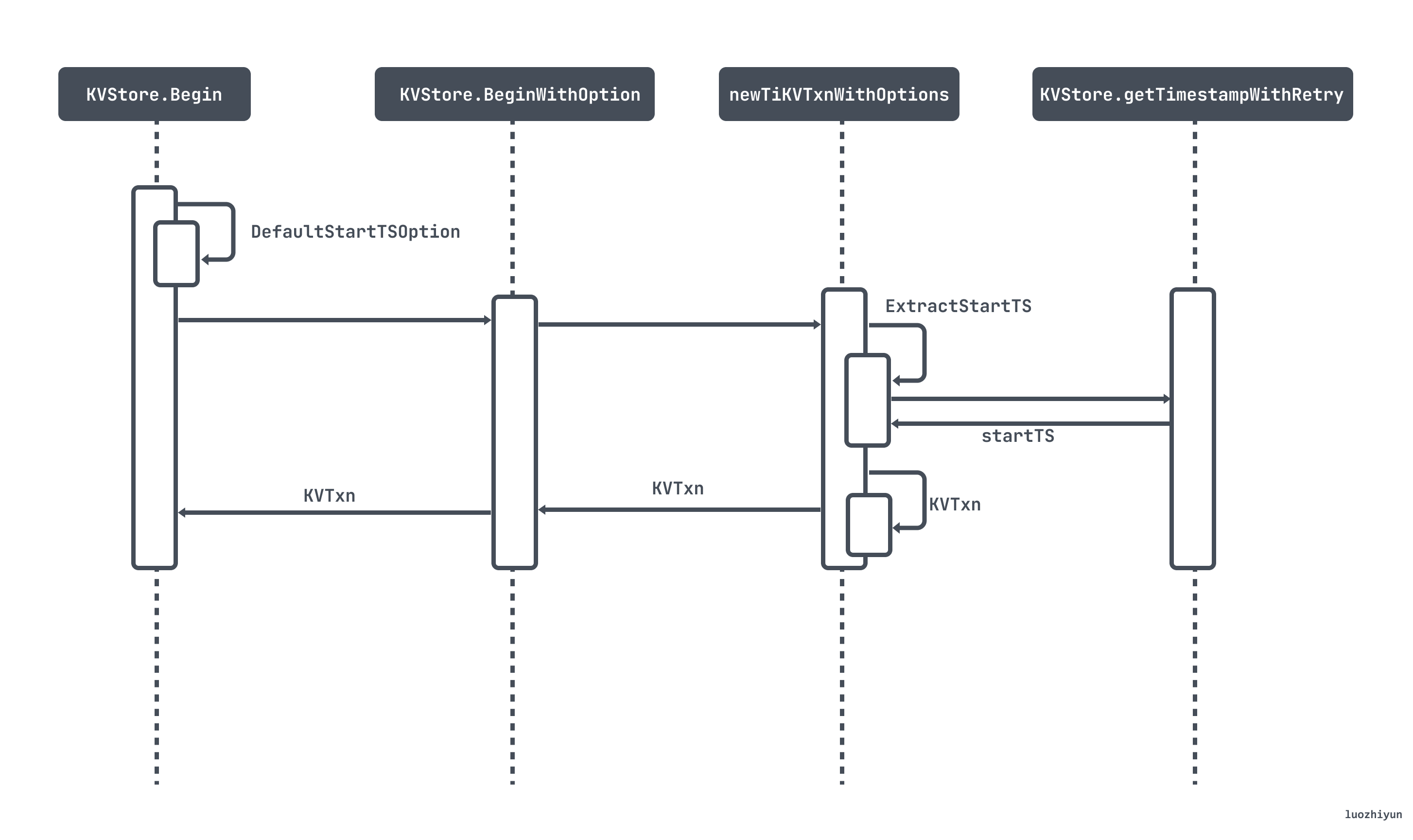
Begin/BeginWithOption最终都会调用到 newTiKVTxnWithOptions 函数中。如果 startTS 为 nil ,则会去 PD服务获取一个时间戳,作为事务的startTS,同时也是事务的唯一标识。
func newTiKVTxnWithOptions(store *KVStore, options StartTSOption) (*KVTxn, error) {if options.TxnScope == "" {options.TxnScope = oracle.GlobalTxnScope}// 去PD服务获取一个时间戳startTS, err := ExtractStartTS(store, options)if err != nil {return nil, errors.Trace(err)}snapshot := newTiKVSnapshot(store, startTS, store.nextReplicaReadSeed())newTiKVTxn := &KVTxn{snapshot: snapshot,us: unionstore.NewUnionStore(snapshot),store: store,startTS: startTS,startTime: time.Now(),valid: true,vars: tikv.DefaultVars,scope: options.TxnScope,}return newTiKVTxn, nil}
写入数据
TiDB 在执行 insert/update/delete 等 DML 时,会调用memBuffer.Set(key, value) 将数据放入到 kv.Transaction 的 memBuffer 里面,如果执行失败,就调 StmtRollback 将 TxnState里面的buf 清空 。具体实现可以看 tableCommon.AddRecord 函数:
func (t *TableCommon) AddRecord(sctx sessionctx.Context, r []types.Datum, opts ...table.AddRecordOption) (recordID kv.Handle, err error) {...var setPresume boolskipCheck := sctx.GetSessionVars().StmtCtx.BatchCheckif (t.meta.IsCommonHandle || t.meta.PKIsHandle) && !skipCheck && !opt.SkipHandleCheck {// 如果是 LazyCheck ,那么只读取本地缓存判断是否存在if sctx.GetSessionVars().LazyCheckKeyNotExists() {var v []byte//只读取本地缓存判断是否存在v, err = txn.GetMemBuffer().Get(ctx, key)if err != nil {setPresume = true}if err == nil && len(v) == 0 {err = kv.ErrNotExist}} else {//否则会通过rpc请求tikv从集群中校验数据是否存在_, err = txn.Get(ctx, key)}if err == nil {handleStr := getDuplicateErrorHandleString(t, recordID, r)return recordID, kv.ErrKeyExists.FastGenByArgs(handleStr, "PRIMARY")} else if !kv.ErrNotExist.Equal(err) {return recordID, err}}if setPresume {// 表示假定数据不存在err = memBuffer.SetWithFlags(key, value, kv.SetPresumeKeyNotExists)} else {//将 Key-Value 写到当前事务的缓存中err = memBuffer.Set(key, value)}if err != nil {return nil, err}...}
AddRecord 将数据写入的过程我在<5.深入TiDB:Insert 语句>分析过了,就不过多讲解。
两阶段提交事务
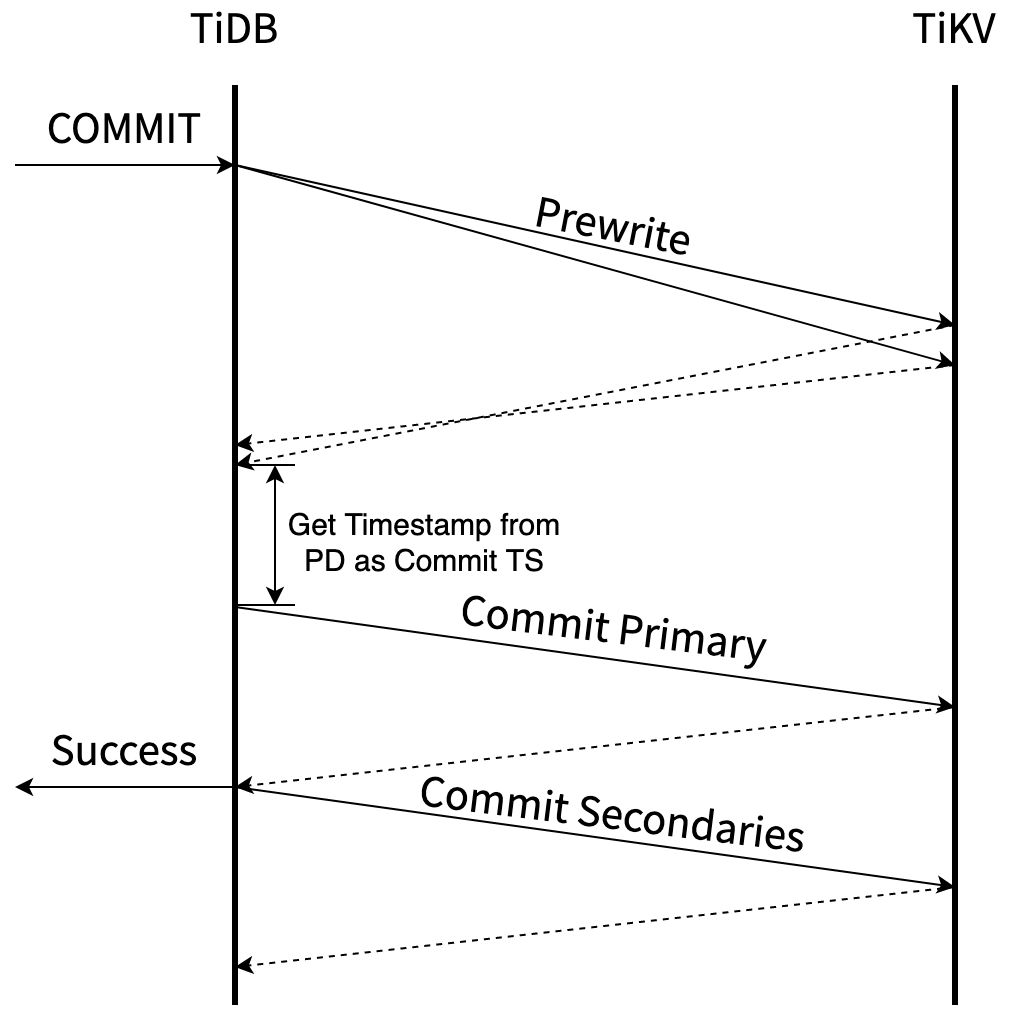
TiDB 提交事务是通过调用 KVTxn 的 Commit 方法进行的。像 pecolator 论文中描述的协议一样,这是一个两阶段提交的过程,Prewrite 阶段与 Commit 阶段。
Prewrite:
- TiDB 从当前要写入的数据中选择一个 Key 作为当前事务的 Primary Key。
- TiDB 从 PD 获取所有数据的写入路由信息,并将所有的 Key 按照所有的路由进行分类。
- TiDB 并发向所有涉及的 TiKV 发起 prewrite 请求,TiKV 收到 prewrite 数据后,检查数据版本信息是否存在冲突、过期,符合条件给数据加锁,锁中记录本次事务的开始时间戳 startTs。Prewrite 流程任何一步发生错误,都会进行回滚:删除锁标记 , 删除版本为 startTs 的数据;
- TiDB 收到所有的 prewrite 成功。
当 Prewrite 阶段完成以后,进入 Commit 阶段,当前时间戳为 commitTs,TSO 会保证 commitTs > startTs。
Commit:
- TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交 commit 操作,TiKV 收到 commit 操作后,检查数据合法性,清理 prewrite 阶段留下的锁。
twoPhaseCommitter
我们先看看整体的 twoPhaseCommitter 二阶段提交的调用时序图:
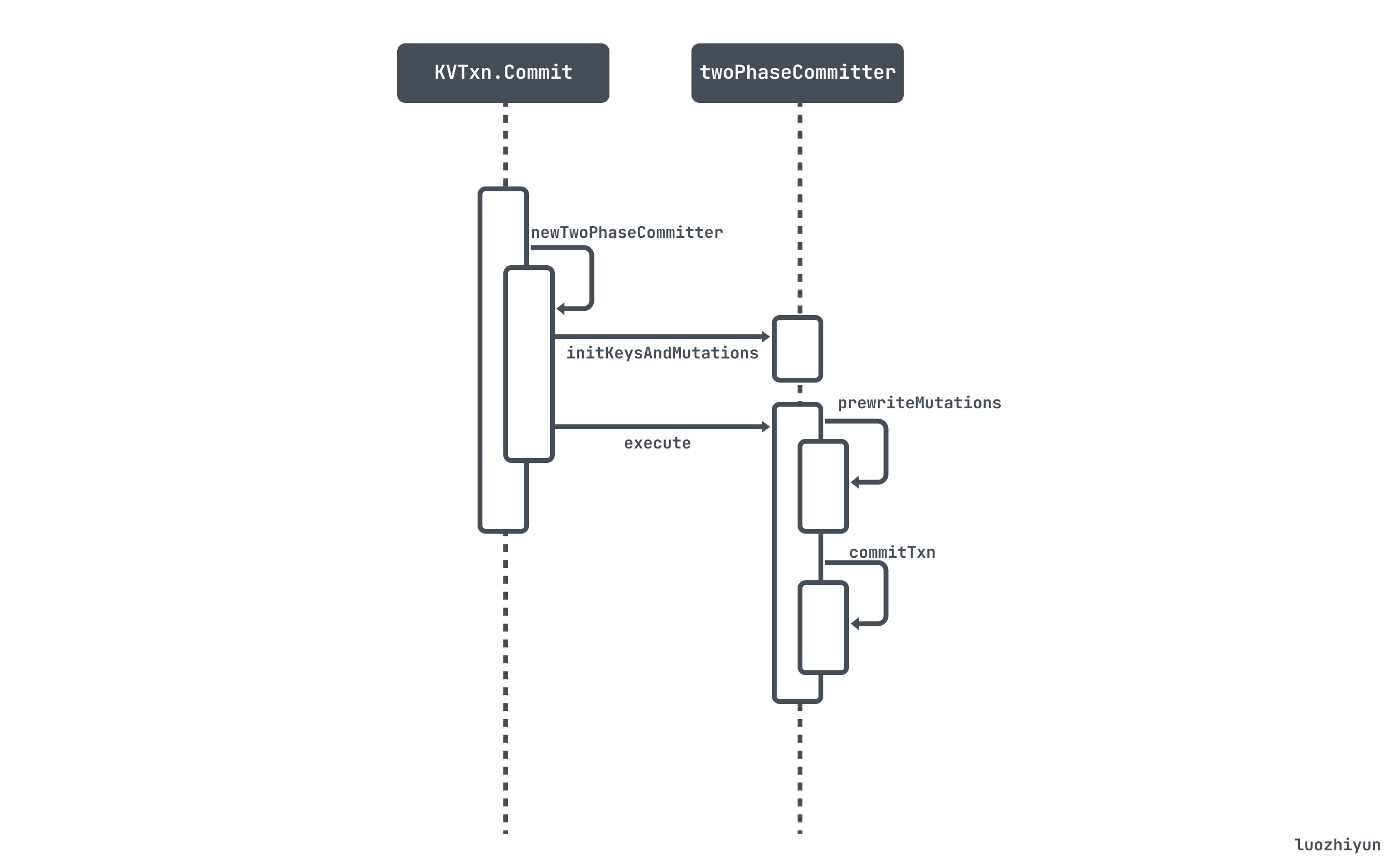
在代码实现上面首先会构建一个 twoPhaseCommitter,这个对象会用到在 begin 里面创建的 KVTxn 对象的字段:
func newTwoPhaseCommitter(txn *KVTxn, sessionID uint64) (*twoPhaseCommitter, error) {return &twoPhaseCommitter{store: txn.store,txn: txn,startTS: txn.StartTS(),sessionID: sessionID,regionTxnSize: map[uint64]int{},ttlManager: ttlManager{ch: make(chan struct{}),},isPessimistic: txn.IsPessimistic(),binlog: txn.binlog,}, nil}
mutations
由于事务数据都是存放在缓存中的,所以 twoPhaseCommitter 会通过 initKeysAndMutations 方法将当前事务的缓存中的数据转成 mutations:
func (c *twoPhaseCommitter) initKeysAndMutations() error {var size, putCnt, delCnt, lockCnt, checkCnt inttxn := c.txn// 当前事务的数据都存放在 memBuf 中// memBuffer里的 key 是有序排列memBuf := txn.GetMemBuffer()sizeHint := txn.us.GetMemBuffer().Len()c.mutations = newMemBufferMutations(sizeHint, memBuf)c.isPessimistic = txn.IsPessimistic()filter := txn.kvFiltervar err error// 遍历 memBuffer 可以顺序的收集到事务里需要修改的 keyfor it := memBuf.IterWithFlags(nil, nil); it.Valid(); err = it.Next() {_ = errkey := it.Key()flags := it.Flags()var value []bytevar op pb.Opif !it.HasValue() {...} else {value = it.Value()...}var isPessimistic boolif flags.HasLocked() {isPessimistic = c.isPessimistic}c.mutations.Push(op, isPessimistic, it.Handle())size += len(key) + len(value)if len(c.primaryKey) == 0 && op != pb.Op_CheckNotExists {c.primaryKey = key}}...commitDetail := &util.CommitDetails{WriteSize: size, WriteKeys: c.mutations.Len()}metrics.TiKVTxnWriteKVCountHistogram.Observe(float64(commitDetail.WriteKeys))metrics.TiKVTxnWriteSizeHistogram.Observe(float64(commitDetail.WriteSize))c.hasNoNeedCommitKeys = checkCnt > 0// 计算事务的 TTL 时间c.lockTTL = txnLockTTL(txn.startTime, size)c.priority = txn.priority.ToPB()c.syncLog = txn.syncLogc.resourceGroupTag = txn.resourceGroupTagc.setDetail(commitDetail)return nil}
当前事务的数据都存放在 memBuf 中,所以我们需要遍历 memBuf 可以顺序的收集到事务里需要修改的 key。
在这里还会调用 txnLockTTL 根据事务的大小计算事务的 TTL 时间。如果一个事务的 key 通过 prewrite加锁后,事务没有执行完,tidb-server 就挂掉了,这时候集群内其他 tidb-server 是无法读取这个 key 的,如果没有 TTL,就会死锁。设置了 TTL 之后,读请求就可以在 TTL 超时之后执行清锁,然后读取到数据。
func txnLockTTL(startTime time.Time, txnSize int) uint64 {lockTTL := defaultLockTTL// 当事务大小大于16KBif txnSize >= txnCommitBatchSize {sizeMiB := float64(txnSize) / bytesPerMiB// 6000 * 事务大小平方根lockTTL = uint64(float64(ttlFactor) * math.Sqrt(sizeMiB))//最小为3sif lockTTL < defaultLockTTL {lockTTL = defaultLockTTL}//最大为20sif lockTTL > ManagedLockTTL {lockTTL = ManagedLockTTL}}elapsed := time.Since(startTime) / time.Millisecondreturn lockTTL + uint64(elapsed)}
TTL 和事务的大小的平方根成正比,并控制在一个最小值和一个最大值之间,最大20s,最小3s。
prewrite
在执行 之前,先会调用 twoPhaseCommitter 的 prewriteMutations 方法进行一些预处理工作。
func (c *twoPhaseCommitter) prewriteMutations(bo *Backoffer, mutations CommitterMutations) error {...return c.doActionOnMutations(bo, actionPrewrite{}, mutations)}func (c *twoPhaseCommitter) doActionOnMutations(bo *Backoffer, action twoPhaseCommitAction, mutations CommitterMutations) error {if mutations.Len() == 0 {return nil}//按照region分组对mutations进行分组groups, err := c.groupMutations(bo, mutations)if err != nil {return errors.Trace(err)}...//进一步的分批处理return c.doActionOnGroupMutations(bo, action, groups)}
groupMutations
首先会调用 groupMutations 对 mutations 按照 region 分组。整个分组流程如下:
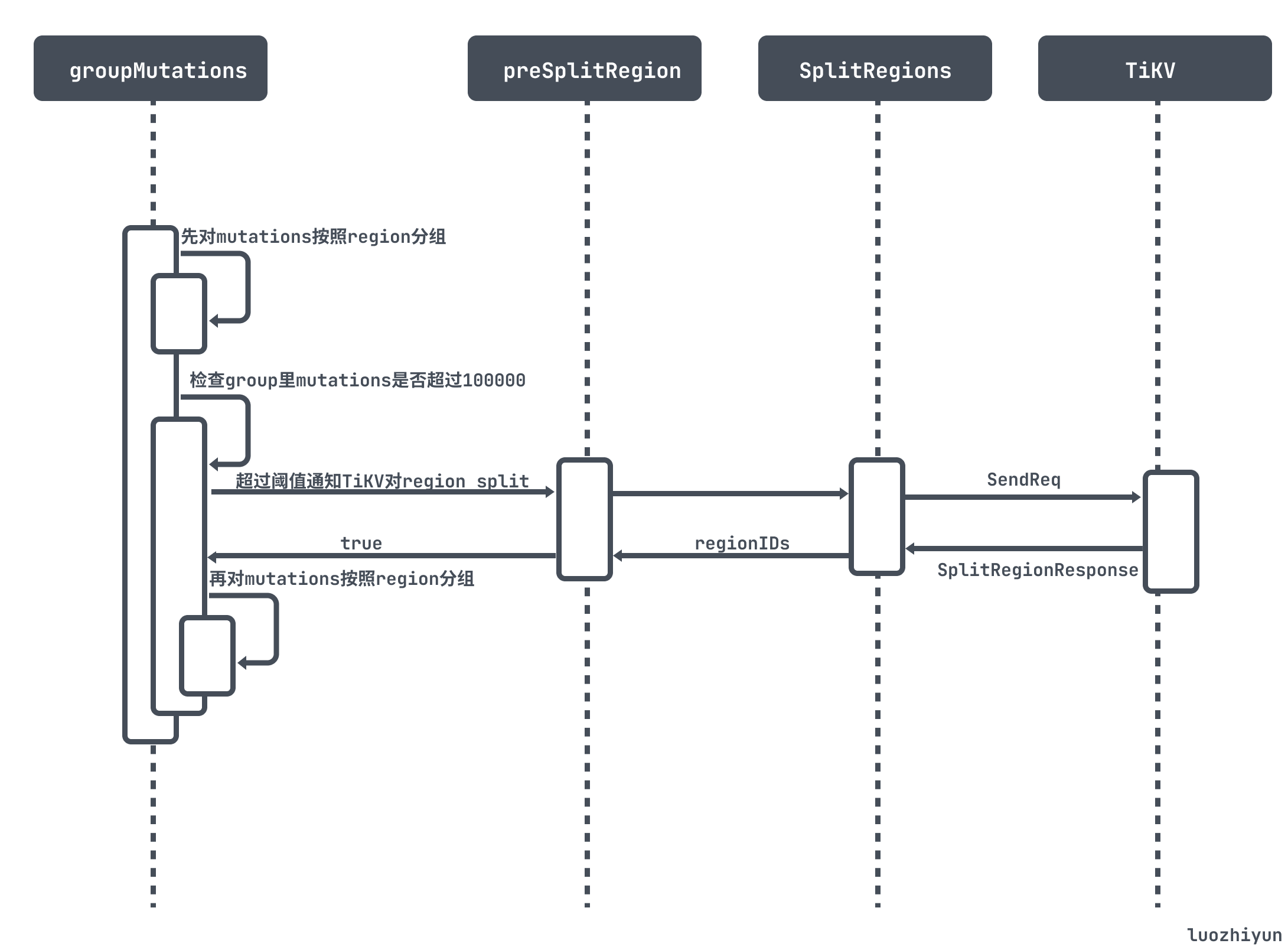
先对mutations按照region分组,如果某个region的mutations 太多, 则会先发送CmdSplitRegion命令给TiKV, TiKV对那个region先做个split, 然后再开始提交。
doActionOnGroupMutations
分组完之后会调用 doActionOnGroupMutations 会对每个group的 mutations 做进一步的分批处理。然后调用 doActionOnBatches 进行 prewrite 处理,整个调用图如下:
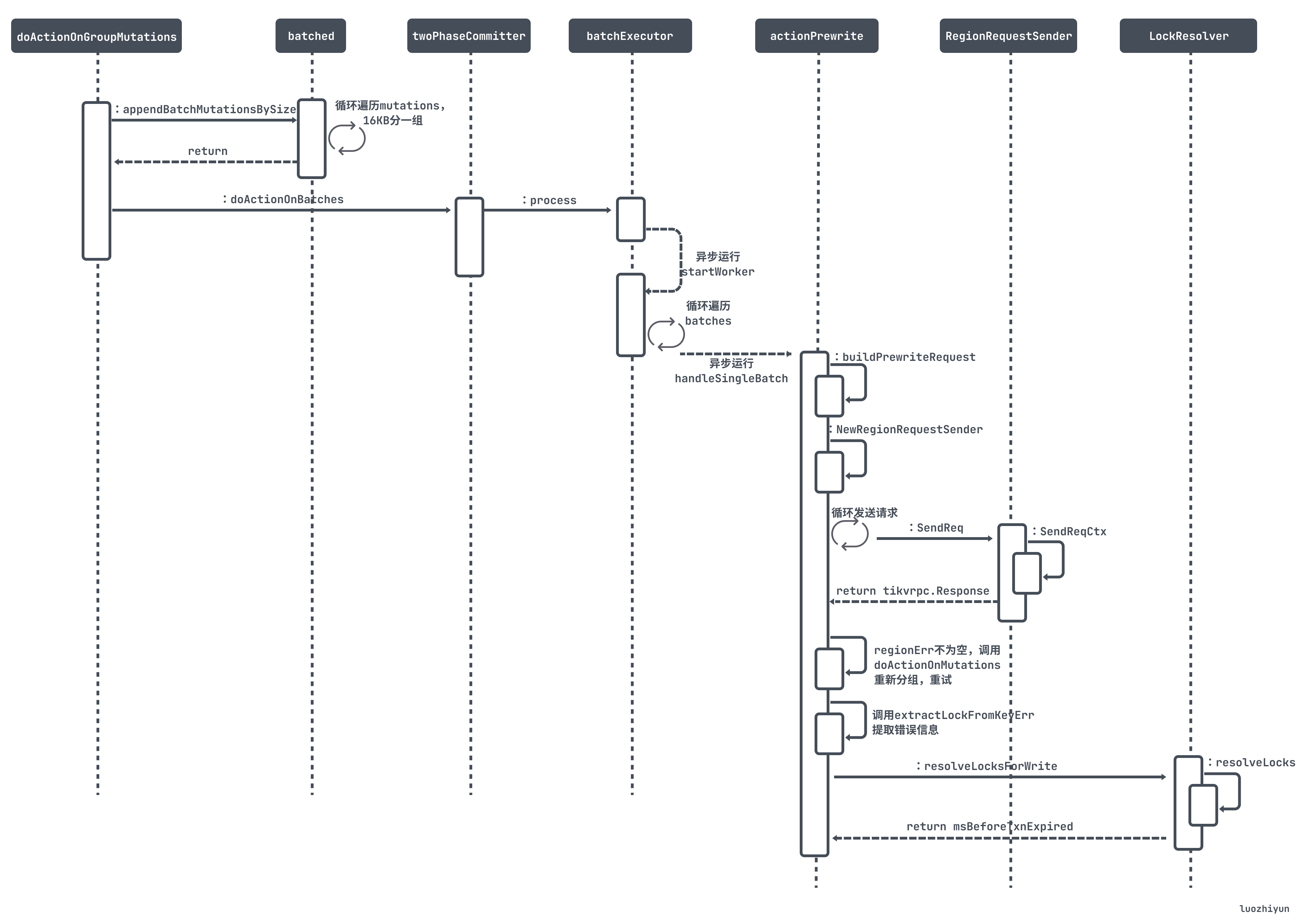
代码的主要执行逻辑如下:
func (c *twoPhaseCommitter) doActionOnGroupMutations(bo *Backoffer, action twoPhaseCommitAction, groups []groupedMutations) error {action.tiKVTxnRegionsNumHistogram().Observe(float64(len(groups)))...batchBuilder := newBatched(c.primary())//每个分组内按16KB大小再分批for _, group := range groups {batchBuilder.appendBatchMutationsBySize(group.region, group.mutations, sizeFunc, txnCommitBatchSize)}firstIsPrimary := batchBuilder.setPrimary()actionCommit, actionIsCommit := action.(actionCommit)...//commit先同步的提交primary key所在的batchif firstIsPrimary &&((actionIsCommit && !c.isAsyncCommit()) || actionIsCleanup || actionIsPessimiticLock) {// primary should be committed(not async commit)/cleanup/pessimistically locked firsterr = c.doActionOnBatches(bo, action, batchBuilder.primaryBatch())...//提交完之后将primary key所在的batch移除batchBuilder.forgetPrimary()}// Already spawned a goroutine for async commit transaction.// 其它的key由go routine后台异步的提交if actionIsCommit && !actionCommit.retry && !c.isAsyncCommit() {secondaryBo := retry.NewBackofferWithVars(context.Background(), CommitSecondaryMaxBackoff, c.txn.vars)go func() {...e := c.doActionOnBatches(secondaryBo, action, batchBuilder.allBatches())...}()} else {//执行 prewriteerr = c.doActionOnBatches(bo, action, batchBuilder.allBatches())}return errors.Trace(err)}
doActionOnGroupMutations 里面还参杂了 commit 代码,可以先忽略。
下面跟着上面的流程图 doActionOnGroupMutations 会进入到 actionPrewrite 的 handleSingleBatch 方法中详细说说这个方法。在讲这个方法之前先看看主要的执行逻辑:
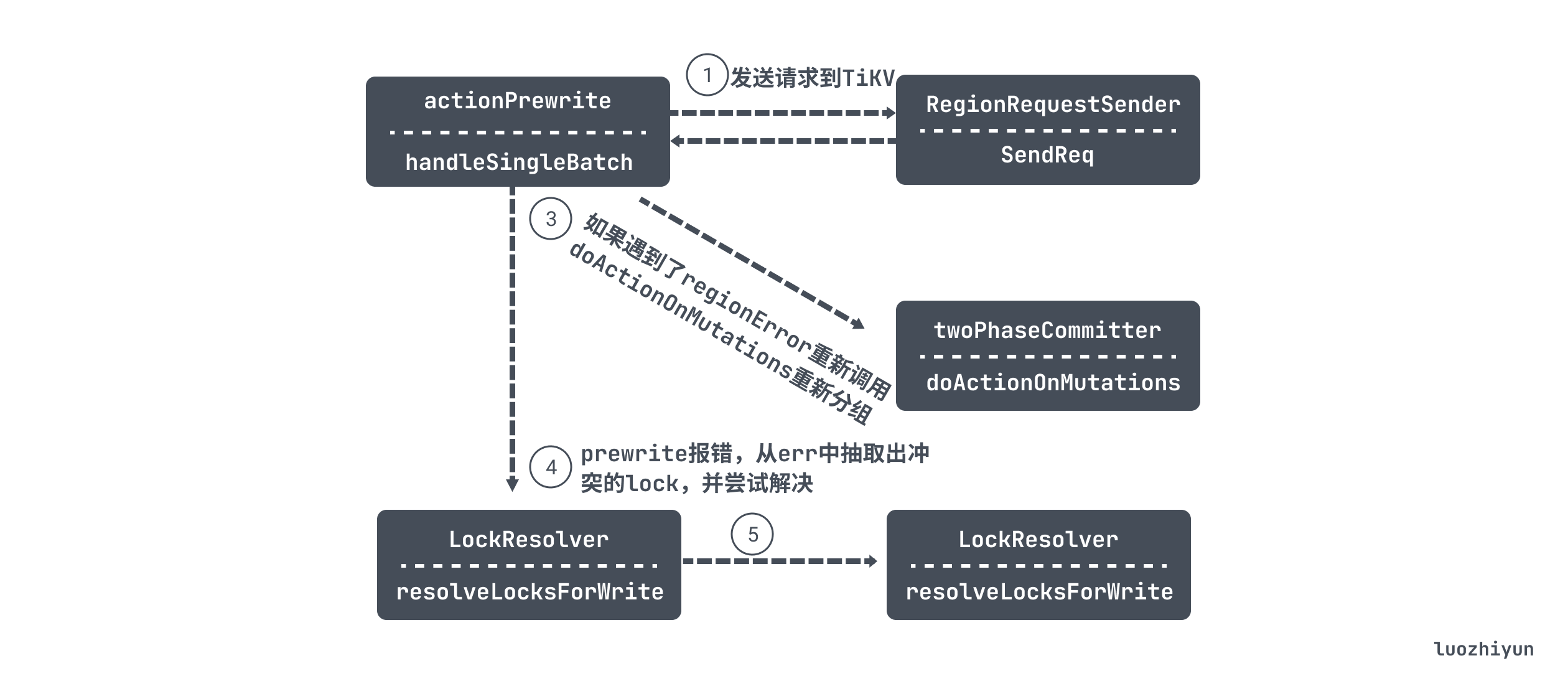
下面来看看代码的具体实现:
func (action actionPrewrite) handleSingleBatch(c *twoPhaseCommitter, bo *Backoffer, batch batchMutations) (err error) {...// 获取事务的大小txnSize := uint64(c.regionTxnSize[batch.region.id])// 因为region的缺失导致的重试,所以不知道事务大小,这里重置事务大小为最大值if action.retry {txnSize = math.MaxUint64}tBegin := time.Now()attempts := 0// 构建 Requestreq := c.buildPrewriteRequest(batch, txnSize)// 构建 RegionRequestSendersender := NewRegionRequestSender(c.store.regionCache, c.store.GetTiKVClient())for {//尝试次数attempts++// 如果请求超过了1分钟,那么打印一条日志if time.Since(tBegin) > slowRequestThreshold {logutil.BgLogger().Warn("slow prewrite request", zap.Uint64("startTS", c.startTS), zap.Stringer("region", &batch.region), zap.Int("attempts", attempts))tBegin = time.Now()}//发送请求resp, err := sender.SendReq(bo, req, batch.region, client.ReadTimeoutShort)// Unexpected error occurs, return itif err != nil {return errors.Trace(err)}regionErr, err := resp.GetRegionError()if err != nil {return errors.Trace(err)}// 如果遇到了regionError, 则需要重新调用doActionOnMutations重新分组,重新尝试if regionErr != nil {...err = c.doActionOnMutations(bo, actionPrewrite{true}, batch.mutations)return errors.Trace(err)}if resp.Resp == nil {return errors.Trace(tikverr.ErrBodyMissing)}prewriteResp := resp.Resp.(*pb.PrewriteResponse)keyErrs := prewriteResp.GetErrors()if len(keyErrs) == 0 {//如果没有keyError,并且Batch是primary,则启动一个tllManagerif batch.isPrimary {// 如果事务大于32M,那么开启ttlManager定时发送TxnHeartBeat心跳if int64(c.txnSize) > config.GetGlobalConfig().TiKVClient.TTLRefreshedTxnSize &&prewriteResp.OnePcCommitTs == 0 {c.run(c, nil)}}...return nil}var locks []*Lockfor _, keyErr := range keyErrs {// 该key已存在if alreadyExist := keyErr.GetAlreadyExist(); alreadyExist != nil {e := &tikverr.ErrKeyExist{AlreadyExist: alreadyExist}err = c.extractKeyExistsErr(e)if err != nil {atomic.StoreUint32(&c.prewriteFailed, 1)}return err}// 从 keyErr 中抽取出冲突的locklock, err1 := extractLockFromKeyErr(keyErr)if err1 != nil {atomic.StoreUint32(&c.prewriteFailed, 1)return errors.Trace(err1)}locks = append(locks, lock)}start := time.Now()//尝试解决这些locks,获取锁的过期时间msBeforeExpired, err := c.store.lockResolver.resolveLocksForWrite(bo, c.startTS, locks)if err != nil {return errors.Trace(err)}atomic.AddInt64(&c.getDetail().ResolveLockTime, int64(time.Since(start)))if msBeforeExpired > 0 {// 过期时间大于0,那么sleep等待err = bo.BackoffWithCfgAndMaxSleep(retry.BoTxnLock, int(msBeforeExpired), errors.Errorf("2PC prewrite lockedKeys: %d", len(locks)))if err != nil {return errors.Trace(err)}}}}
handleSingleBatch 里面有个循环会发请求到 TiKV,如果失败,那么会根据返回的错误来判断是否需要重试。需要注意的是,如果事务大于32M,那么开启ttlManager定时发送TxnHeartBeat心跳,因为大事务处理时间比较长。
commit
commit 和 上面的 prewrite 执行流程类似,在 twoPhaseCommitter 的 execute 方法中执行完 prewriteMutations 之后会调用到 commitTxn 方法中,最后在 doActionOnBatches 方法中进行分批处理。
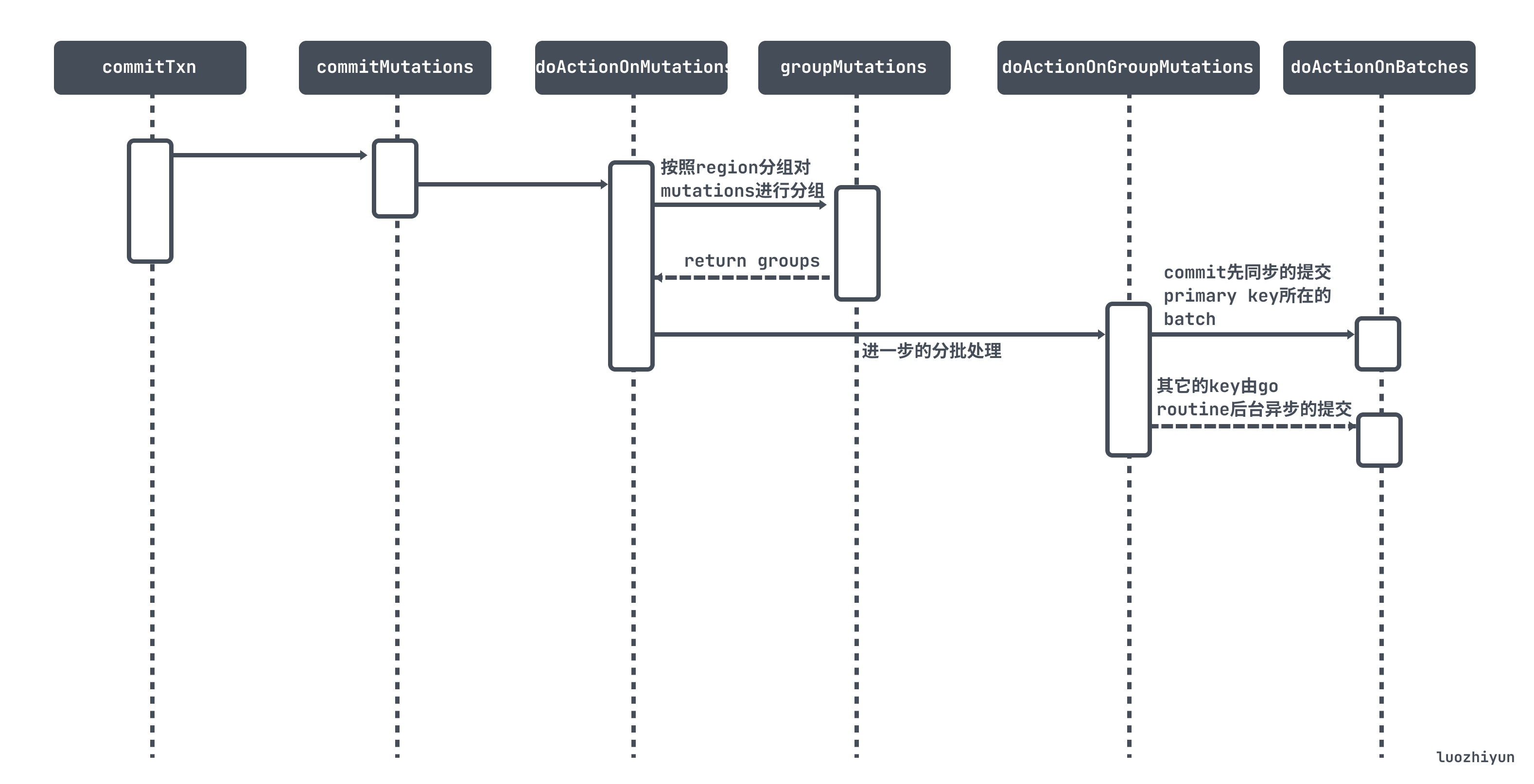
doActionOnBatches 方法会调用到 actionCommit 的 handleSingleBatch 方法进行事务的提交。
actionCommit 的 handleSingleBatch 执行流程其实和上面的 prewrite 也是类似的逻辑:
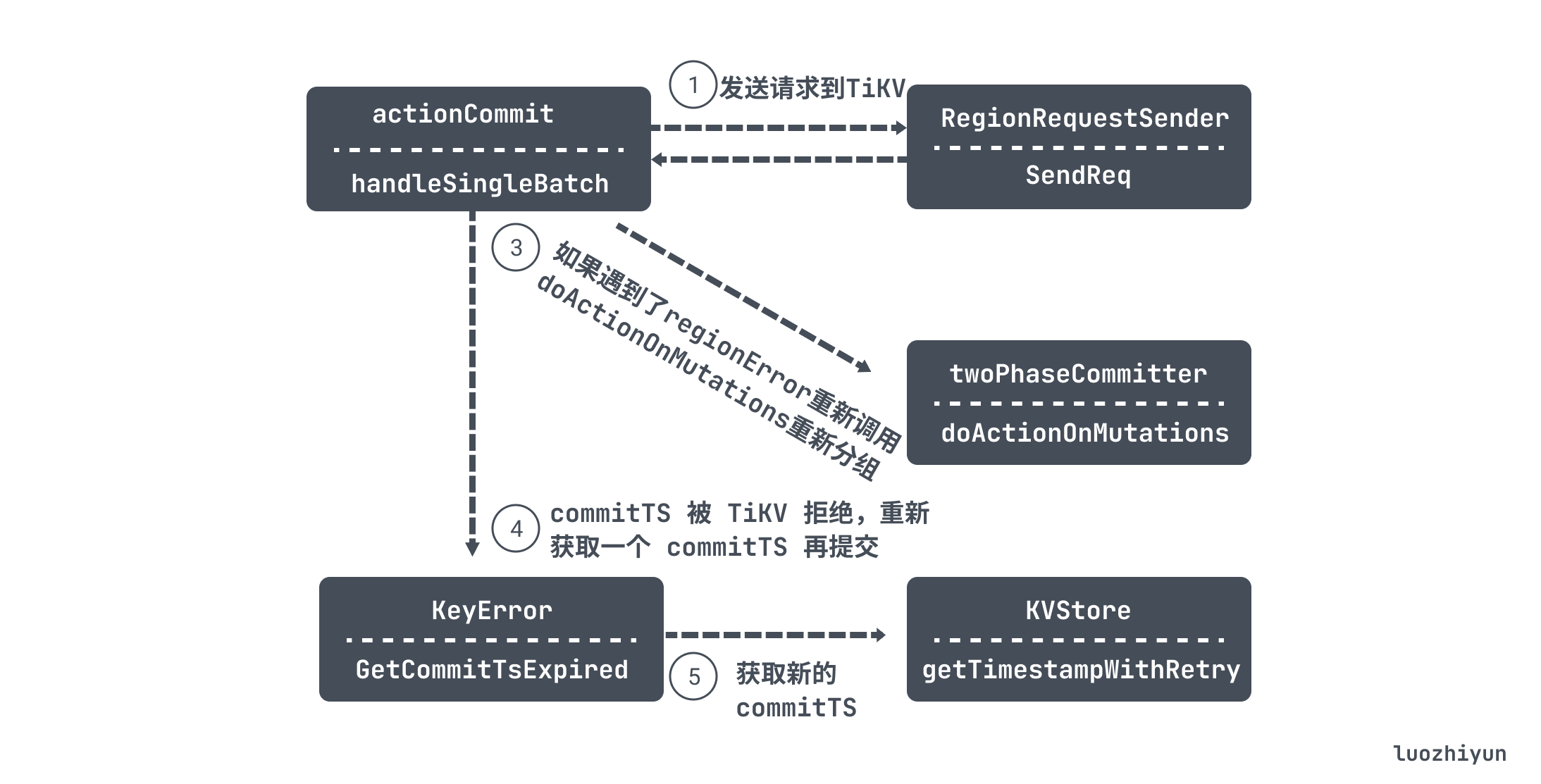
handleSingleBatch 首先也会调用 NewRequest 初始化一个 Request 结构体作为请求体,然后进入到循环结构中,调用 RegionRequestSender 的 SendReq 向 TiKV 发起请求;
如果返回 regionErr 错误,那么会重新调用 doActionOnMutations 重新分组之后再请求;如果返回的错误里面 GetCommitTsExpired 不为空,那么会调用 getTimestampWithRetry 方法重新获取 commitTS 之后再重试提交。
func (actionCommit) handleSingleBatch(c *twoPhaseCommitter, bo *Backoffer, batch batchMutations) error {req := tikvrpc.NewRequest(...)sender := NewRegionRequestSender(c.store.regionCache, c.store.GetTiKVClient())for {// 重试次数attempts++...//向 tikv 发起提交请求resp, err := sender.SendReq(bo, req, batch.region, client.ReadTimeoutShort)...// 如果遇到了regionError, 则需要重新调用doActionOnMutations重新分组,重新尝试regionErr, err := resp.GetRegionError()if err != nil {return errors.Trace(err)}if regionErr != nil {...// 重新分组err = c.doActionOnMutations(bo, actionCommit{true}, batch.mutations)return errors.Trace(err)}commitResp := resp.Resp.(*pb.CommitResponse)if keyErr := commitResp.GetError(); keyErr != nil {if rejected := keyErr.GetCommitTsExpired(); rejected != nil {// 重新获取 commitTScommitTS, err := c.store.getTimestampWithRetry(bo, c.txn.GetScope())...continue}...}break}return nil}
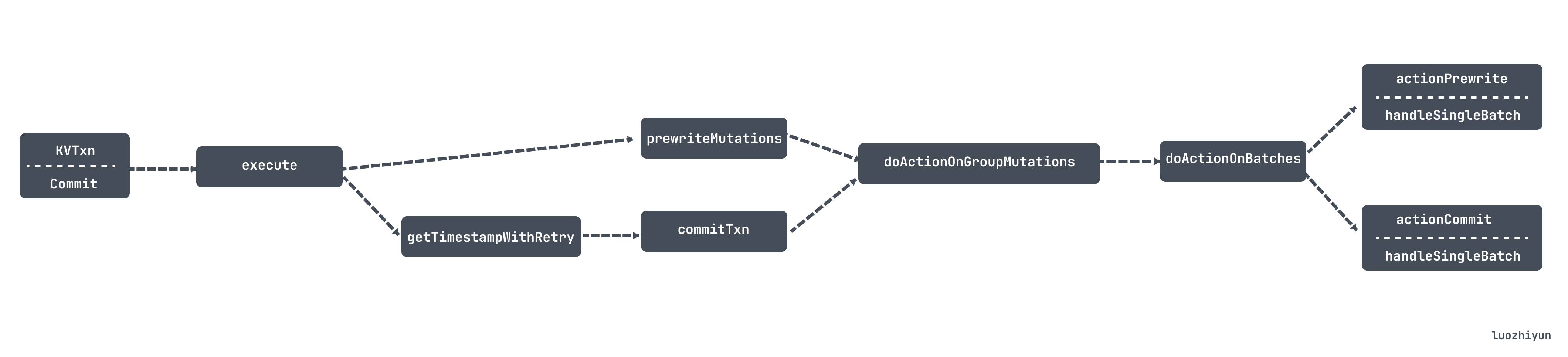
总结
由于TiDB的二阶段提交是通过 Percolator 分布式事务模型实现的,所以本篇文章首先从 Percolator 分布式事务模型给大家讲解一下它里面主要的写操作和读操作的实现步骤;
然后再带入到 TiDB 的二阶段提交中,从代码中和大家剖析实现原理。整个提交的过程大致如图所示:
Reference
https://pingcap.com/zh/blog/tidb-source-code-reading-19
https://asktug.com/t/topic/1495
https://pingcap.com/zh/blog/tidb-source-code-reading-19
https://pingcap.com/zh/blog/percolator-and-txn
https://www.luozhiyun.com/archives/609
https://pingcap.com/zh/blog/tikv-source-code-reading-12
https://github.com/tikv/sig-transaction/tree/master/design/async-commit
https://pingcap.com/zh/blog/async-commit-principle
https://zhuanlan.zhihu.com/p/59115828
http://mysql.taobao.org/monthly/2018/11/02/
https://pingcap.com/zh/blog/best-practice-optimistic-transaction
https://pingcap.com/zh/blog/tidb-transaction-model

6.深入TiDB:乐观事务的更多相关文章
- 如何进行TIDB优化之Grafana(TiDB 3.0)关注监控指标
前言 在对数据库进行优化前,我们先要思考一下数据库系统可能存在的瓶颈所在之外.数据库服务是运行在不同的硬件设备上的,优化即通过参数配置(不考虑应用客户端程序的情况下),而实现硬件资源的最大利用化.那么 ...
- 浅谈tidb事务与MySQL事务之间的区别
MySQL是我们日常生活中常见的数据库,他的innodb存储引擎尤为常见,在事务方面使用的是扁平事务,即要么都执行,要么都回滚.而tidb数据库则使用的是分布式事务.两者都能保证数据的高一致性,但是在 ...
- 论 大并发 下的 乐观锁定 Redis锁定 和 新时代事务
在 <企业应用架构模式> 中 提到了 乐观锁定, 用 时间戳 来 判定 交易 是否有效, 避免 传统事务 的 表锁定 造成 的 瓶颈 . 在 现在的 大并发 的 大环境下, 传统事务 及其 ...
- tidb 架构~tidb 理论学习(1)
一 简介:介绍新型NEW SQL数据库tidb 二 目的: tidb出现的目的,就是代替mysql+中间件,实现横向水平扩展 三 核心理论观点 1 MySQL 是单机数据库,只能通过 XA 来满足跨数 ...
- 世界级的开源项目:TiDB 如何重新定义下一代关系型数据库
著名的开源分布式缓存服务 Codis 的作者,PingCAP 联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神 ...
- TiKV事务实现浅析
TiKV事务实现浅析 Percolator事务的理论基础 Percolator的来源 Percolator事务来源于Google在设计更新网页索引的系统时提出的论文Large-scale Increm ...
- 使用TiDB把自己写分库分表方案推翻了
背景 在日益数据量增长的情况下,影响数据库的读写性能,我们一般会有分库分表的方案和使用newSql方案,newSql如TIDB.那么为什么需要使用TiDB呢?有什么情况下才用TiDB呢?解决传统分库分 ...
- 1.深入TiDB:初见TiDB
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/584 本篇文章应该是我研究的 TiDB 的第一篇文章,主要是介绍整个 ...
- 【数据库】mysql深入理解乐观锁与悲观锁
转载:http://www.hollischuang.com/archives/934 在数据库的锁机制中介绍过,数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时 ...
随机推荐
- 【第一篇】- Maven 系列教程之Spring Cloud直播商城 b2b2c电子商务技术总结
Maven 教程 Maven 翻译为"专家"."内行",是 Apache 下的一个纯 Java 开发的开源项目.基于项目对象模型(缩写:POM)概念,Maven ...
- php curl下载文件由于空格导致下载文件失败
<?php //$result=httpcopy('http://www.phpernote.com/image/logo.gif'); echo '<pre>';print_r($ ...
- Java面向对象系列(2)- 回顾方法的定义
方法的定义 修饰符 返回类型 break:跳出switch,结束循环和return的区别 方法名:注意规范,见名知意 参数列表:(参数类型,参数名) 异常抛出 package oop.demo01; ...
- Linux系列(21) - 光盘、U盘挂载
挂载光盘 mount命令.umount命令 step-1 建立挂载点 原理:相当于建立盘符,建个目录读取光盘内容 命令:[root@localhost ~]# mkdir /mnt/cdrom/ 备注 ...
- Probius+Kubernetes任务系统如虎添翼
Probius是一款自定义任务引擎,可以灵活方便的处理日常运维中的各种任务,我们所有的CI/CD任务都通过Probius来完成的,这篇文章Probius:一个功能强大的自定义任务系统对其有详细的介绍, ...
- Ubuntu18.04安装jenkins
官网参考指引:https://pkg.jenkins.io/debian-stable/ wget -q -O - https://pkg.jenkins.io/debian-stable/jenki ...
- python pip 安装使用国内镜像源
国内镜像源 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 ...
- Linux服务器时间同步配置
Linux服务器时间同步配置 以CentOS7 做时间服务器,其他服务器(Centos 6.RHEL7)同步该服务器时间 RHEL 7.CentOS 7 默认的网络时间协议 为Chrony 本教程 ...
- 华为云计算IE面试笔记-Fusionsphere架构及组件介绍(服务器虚拟化解决方案)
eDSK 最上层则是eDSK是我们FusionSphere服务器虚拟化解决方案中的虚拟化北向统一API接口,其他的第三方系统或者是其他运营平台(FC.VMware等)可以通过eDSK轻松完成无缝对 ...
- 鸿蒙源码分析系列(总目录) | 百万汉字注解 百篇博客分析 | 深入挖透OpenHarmony源码 | v8.23
百篇博客系列篇.本篇为: v08.xx 鸿蒙内核源码分析(总目录) | 百万汉字注解 百篇博客分析 | 51.c.h .o 百篇博客.往期回顾 在给OpenHarmony内核源码加注过程中,整理出以下 ...