python 并行计算
一、进程和线程
原文链接:https://zhuanlan.zhihu.com/p/356220352
进程是分配资源的最小单位,线程是系统调度的最小单位。当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态。
一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源。相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务。
二、多进程和多线程
对于一个CPU来说,在同一时刻只能运行一个进程或者一个线程,而单核CPU往往是在进程或者线程间切换执行,每个进程或者线程得到一定的CPU时间,由于切换的速度很快,在我们看来是多个任务在并行执行(同一时刻多个任务在执行),但实际上是在并发执行(一段时间内多个任务在执行)。
单核CPU的并发往往涉及到进程或者线程的切换,进程的切换比线程的切换消耗更多的时间与资源。在单核CPU下,CPU密集的任务采用多进程或多线程不会提升性能,而在IO密集的任务中可以提升(IO阻塞时CPU空闲)。可以给CPU密集型任务和IO密集型任务配置一些线程数。CPU密集型:线程个数为CPU核数。这几个线程可以并行执行,不存在线程切换到开销,提高了cpu的利用率的同时也减少了切换线程导致的性能损耗。IO密集型:线程个数为CPU核数的两倍。到其中的线程在IO操作的时候,其他线程可以继续用cpu,提高了cpu的利用率。
而多核CPU就可以做到同时执行多个进程或者多个进程,也就是并行运算。在拥有多个CPU的情况下,往往使用多进程或者多线程的模式执行多个任务。
三、python中的多进程和多线程
1、多进程
def Test(pid):
print("当前进程{}:{}".format(pid, os.getpid()))
for i in range(1000000000):
pass if __name__ == '__main__':
#单进程
start = time.time()
for i in range(2):
Test(i)
end = time.time()
print((end - start))
添加多线程之后
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
start = time.time()
pool = Pool(processes=2)
pid = [i for i in range(2)]
pool.map(Test, pid)
pool.close()
pool.join()
end = time.time()
print((end - start))
从输出结果可以看出都是执行两次for循环,多进程比单进程减少了近乎一半的时间(这里使用了两个进程),并且查看CPU情况可以看出多进程利用了多个CPU。
python中的多进程可以利用mulitiprocess模块的Pool类创建,利用Pool的map方法来运行子进程。一般多进程的执行如下代码:
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass
if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
pool = Pool(processes=2)
pid = [i for i in range(4)]
pool.map(Test, pid)
pool.close()
pool.join()
1、利用Pool类创建一个进程池,processes声明在进程池中最多可以运行几个子进程,不声明的情况下会自动根据CPU数量来设定,原则上进程池容量不超过CPU数量。(出于资源的考虑,不要创建过多的进程)
2、声明一个可迭代的变量,该变量的长度决定要执行多少次子进程。
3、利用map()方法执行多进程,map方法两个参数,第一个参数是多进程执行的方法名,第二个参数是第二步声明的可迭代变量,里面的每一个元素是方法所需的参数。 这里需要注意几个点:
- 进程池满的时候请求会等待,以上述代码为例,声明了一个容量为2的进程池,但是可迭代变量有4个,那么在执行的时候会先创建两个子进程,此时进程池已满,等待有子进程执行完成,才继续处理请求;
- 子进程处理完一个请求后,会利用已经创建好的子进程继续处理新的请求而不会重新创建进程。
- map会将每个子进程的返回值汇总成一个列表返回。
- 在所有请求处理结束后使用close()方法关闭进程池不再接受请求。
- 使用join()方法让主进程阻塞,等待子进程退出,join()方法要放在close()方法之后,防止主进程在子进程结束之前退出。
2、多线程
python的多线程模块用threading类进行创建
import time
import threading
import os count = 0 def change(n):
global count
count = count + n
count = count - n def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
change(n) if __name__ == '__main__': print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,)) thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join() print(count)
程序执行会创建一个进程,进程会默认启动一个主线程,使用threading.Thread()创建子线程;target为要执行的函数;args传入函数需要的参数;start()启动子线程,join()阻塞主线程先运行子线程。 由于变量由多个线程共享,任何一个线程都可以对于变量进行修改,如果同时多个线程修改变量就会出现错误。
上面的程序在理论上的结果应该为0,但运行结果如图4。
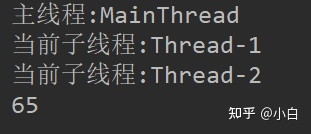
出现这个结果的原因就是多个线程同时对于变量修改,在赋值时出现错误,具体解释见多线程解决这个问题就是在修改变量的时候加锁,这样就可以避免出现多个线程同时修改变量。
import time
import threading
import os count = 0
lock = threading.Lock() def change(n):
global count
count = count + n
count = count - n def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
# lock.acquire()
# try:
change(n)
# finally:
# lock.release() if __name__ == '__main__': print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,)) thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join() print(count)
python中的线程需要先获取GIL(Global Interpreter Lock)锁才能继续运行,每一个进程仅有一个GIL,线程在获取到GIL之后执行100字节码或者遇到IO中断时才会释放GIL,这样在CPU密集的任务中,即使有多个CPU,多线程也是不能够利用多个CPU来提高速率,甚至可能会因为竞争GIL导致速率慢于单线程。所以对于CPU密集任务往往使用多进程,IO密集任务使用多线程。
四、多核并行计算
原文链接:https://blog.csdn.net/ctwy291314/article/details/89358144
1.多进程库 Multiprocessing
import math
import datetime
import multiprocessing as mp def train_on_parameter(name, param):
result = 0
for num in param:
result += math.sqrt(num * math.tanh(num) / math.log2(num) / math.log10(num))
return {name: result} if __name__ == '__main__': start_t = datetime.datetime.now() num_cores = int(mp.cpu_count())
print("本地计算机有: " + str(num_cores) + " 核心")
pool = mp.Pool(num_cores)
param_dict = {'task1': list(range(10, 30000000)),
'task2': list(range(30000000, 60000000)),
'task3': list(range(60000000, 90000000)),
'task4': list(range(90000000, 120000000)),
'task5': list(range(120000000, 150000000)),
'task6': list(range(150000000, 180000000)),
'task7': list(range(180000000, 210000000)),
'task8': list(range(210000000, 240000000))}
results = [pool.apply_async(train_on_parameter, args=(name, param)) for name, param in param_dict.items()]
results = [p.get() for p in results] end_t = datetime.datetime.now()
elapsed_sec = (end_t - start_t).total_seconds()
print("多进程计算 共消耗: " + "{:.2f}".format(elapsed_sec) + " 秒")
- 核心数量: cpu_count() 函数可以获得你的本地运行计算机的核心数量。如果你购买的是 Intel i7或者以上版本的芯片,你会得到一个乘以2的数字,得益于超线程 (Hyper-Threading) 结构,Python 可利用核心数量是真实数量的2倍!所以我在前文中会建议Python开发者购买 i7 而不是 第八代之前的 i5。
- 进程池: Pool() 函数创建了一个进程池类,用来管理多进程的生命周期和资源分配。这里进程池传入的参数是核心数量,意思是最多有多少个进程可以进行并行运算。
- 异步调度: apply_async() 是进程池的一个调度函数。第一个参数是计算函数,和 多多教Python:Python 基本功: 13. 多线程运算提速 里多线程计算教程里创建线程的参数 target 类似。第二个参数是需要传入计算函数的参数,这里传入了计算函数名字和计算调参。而异步的意义是在调度之后,虽然计算函数开始运行并且可能没有结束,异步调度都会返回一个临时结果,并且通过列表生成器 (参考: 多多教Python:Python 基本功: 12. 高纬运算的救星 Numpy) 临时的保存在一个列表里,这里就是 results。
- 调度结果: 如果你检查列表 results 里的类,你会发现 apply_async() 返回的是 ApplyResult,也就是调度结果类。这里用到了 Python 的异步功能,目前教程还没有讲到,简单的来说就是一个用来等待异步结果生成完毕的容器。
- 获取结果: 调度结果 ApplyResult 类可以调用函数 get(), 这是一个非异步函数,也就是说 get() 会等待计算函数处理完毕,并且返回结果。这里的结果就是计算函数的 return。
2.并行计算
多线程因为共享一个进程的内存,所以在并行计算的时候会出现资源竞争的问题,这个在多多教Python:Python 基本功: 13. 多线程运算提速 已经提到过。而多进程虽然避免了这个问题,但是无法像多线程一样轻易的调用一个内存的资源。为了能让多进程之间进行通讯 (IPC),Python 的 Multiprocessing 库提供了几种方案: Pipe, Queue 和 Manager。这里 Pipe 我就直接引用一个外部我觉得很简单明了的介绍,Queue 有兴趣的小伙伴可以在教程结尾找到外部的链接,然后我会在之前的例子中加入 Manager。
管道Pipe:
Pipe可以是单向(half-duplex),也可以是双向(duplex)。我们通过mutiprocessing.Pipe(duplex=False)创建单向管道 (默认为双向)。一个进程从PIPE一端输入对象,然后被PIPE另一端的进程接收,单向管道只允许管道一端的进程输入,而双向管道则允许从两端输入。
import multiprocessing as mul def proc1(pipe):
pipe.send('hello')
print('proc1 rec:', pipe.recv()) def proc2(pipe):
print('proc2 rec:', pipe.recv())
pipe.send('hello, too') # Build a pipe
pipe = mul.Pipe()
if __name__ == '__main__':
# Pass an end of the pipe to process 1
p1 = mul.Process(target=proc1, args=(pipe[0],))
# Pass the other end of the pipe to process 2
p2 = mul.Process(target=proc2, args=(pipe[1],))
p1.start()
p2.start()
p1.join()
p2.join()
管理员 Manager
Manager 是一个 Multiprocessing 库里的类,用来创建可以进行多进程共享的数据容器,容器种类包括了几乎所有 Python 自带的数据类。
import math
import datetime
import multiprocessing as mp def train_on_parameter(name, param, result_dict, result_lock):
result = 0
for num in param:
result += math.sqrt(num * math.tanh(num) / math.log2(num) / math.log10(num))
with result_lock:
result_dict[name] = result
return if __name__ == '__main__': start_t = datetime.datetime.now() num_cores = int(mp.cpu_count())
print("本地计算机有: " + str(num_cores) + " 核心")
pool = mp.Pool(num_cores)
param_dict = {'task1': list(range(10, 30000000)),
'task2': list(range(30000000, 60000000)),
'task3': list(range(60000000, 90000000)),
'task4': list(range(90000000, 120000000)),
'task5': list(range(120000000, 150000000)),
'task6': list(range(150000000, 180000000)),
'task7': list(range(180000000, 210000000)),
'task8': list(range(210000000, 240000000))}
manager = mp.Manager()
managed_locker = manager.Lock()
managed_dict = manager.dict()
results = [pool.apply_async(train_on_parameter, args=(name, param, managed_dict, managed_locker)) for name, param in param_dict.items()]
results = [p.get() for p in results] print(managed_dict) end_t = datetime.datetime.now()
elapsed_sec = (end_t - start_t).total_seconds()
print("多线程计算 共消耗: " + "{:.2f}".format(elapsed_sec) + " 秒")
这里我们用 Manager 来创建一个可以进行进程共享的字典类,随后作为第三个参数传入计算函数中。计算函数把计算好的结果保存在字典里,而不是直接返回。在并行运算结束之后,我们通过 print() 函数来查看字典里的结果。注意这里既然出现了可以共享的数据类,我们就要再次通过锁 (Lock) 来避免资源竞争,所以同时通过 Manager 创建了锁 Lock 类,以第四个参数传入计算函数,并且用 With 语境来锁住共享的字典类。
python 并行计算的更多相关文章
- Python 并行计算那点事 -- 译文 [原创]
Python 并行计算的那点事1(The Python Concurrency Story) 英文原文:https://powerfulpython.com/blog/python-concurren ...
- python并行计算之mpi4py的安装与基本使用
技术背景 在之前的博客中我们介绍过concurrent等python多进程任务的方案,而之所以我们又在考虑MPI等方案来实现python并行计算的原因,其实是将python的计算任务与并行计算的任务调 ...
- python并行计算(持续更新)
工作中需要对tensorflow 的一个predict结果加速,利用python中的线程池 def getPPLs(tester,datas): for line in datas: tester(l ...
- Python 官方文档解读(2):threading 模块
使用 Python 可以编写多线程程序,注意,这并不是说程序能在多个 CPU 核上跑.如果你想这么做,可以看看关于 Python 并行计算的,比如官方 Wiki. Python 线程的主要应用场景是一 ...
- Python实现代码统计工具——终极加速篇
Python实现代码统计工具--终极加速篇 声明 本文对于先前系列文章中实现的C/Python代码统计工具(CPLineCounter),通过C扩展接口重写核心算法加以优化,并与网上常见的统计工具做对 ...
- 快速掌握用python写并行程序
目录 一.大数据时代的现状 二.面对挑战的方法 2.1 并行计算 2.2 改用GPU处理计算密集型程序 3.3 分布式计算 三.用python写并行程序 3.1 进程与线程 3.2 全局解释器锁GIL ...
- MPI2 编程环境搭建 MPI4PY 编程环境搭建
最近发现了一门新语言 Julia , 这门编程语言据说大有取代 Python语言成为数据科学的大佬,但是细看发现最主要说的是这门编程语言运行速度比较快,并且在分布式和并行计算上比较有优势,这时候 ...
- 用Python实现多核心并行计算
平常写的程序,无论是单线程还是多线程,大多只有一个进程,而且只能在一个核心里工作.所以很多应用程序即使正在满载运行,在任务管理器中CPU使用量还是只有50%(双核CPU)或25%(四核CPU) 如果能 ...
- python加速包numba并行计算多线程
1.下面直接上代码需要注意的地方numba的官网找到 1)有一些坑自己去numba的官网找找看,下面是我的写的一个加速的程序,希望对你有帮助. #coding:utf-8 import time fr ...
随机推荐
- python aes pkcs7加密
# -*- coding: UTF-8 -*- from Crypto.Util.Padding import pad from Crypto.Cipher import AES import bas ...
- 用python将word转pdf、doc转docx等
word ==> pdf def doc2pdf(file_path): """ word格式转换doc|docx ==> pdf :return: &quo ...
- 【爬虫系列】1. 无事,Python验证码识别入门
最近在导入某站数据(正经需求),看到他们的登录需要验证码, 本来并不想折腾的,然而Cookie有效期只有一天. 已经收到了几次夜间报警推送之后,实在忍不住. 得嘞,还是得研究下模拟登录. 于是,秃头了 ...
- Sqlserver 关于varchar(max) 笔记
看SQL server的版本,SQLserver2005以上 的nvarchar(max) 可以存放2G的内容,所以要是 SQL2005以上的nvarchar(max)足够你用的了.用nvarchar ...
- 剑指 Offer 39. 数组中出现次数超过一半的数字
剑指 Offer 39. 数组中出现次数超过一半的数字 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字. 你可以假设数组是非空的,并且给定的数组总是存在多数元素. 示例 1: 输入: [ ...
- Android开发音视频方向学习路线及资源分享,学完还怕什么互联网寒冬?
接触Android音视频这一块已经有一段时间了,跟普通的应用层开发相比,的确更花费精力.期间为了学习音视频的录制,编码,处理也看过大大小小的几十个项目.总体感觉就是知识比较零散,对刚入门的朋友比较不友 ...
- HCNA Routing&Switching之STP端口状态、计时器以及拓扑变化
前文我们了解了STP选举规则相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15131999.html:今天我们来聊一聊STP的端口状态.计时器.端口状 ...
- How to build your custom release bazel version?
一般情况下用源代码编译,生成的都是开发版本,这种版本做版本号校验方面会有很多问题,所以需要编译自己的release版本. export USE_BAZEL_VERSION=1.2.1 # 选择使用版本 ...
- .NET 6 全新指标 System.Diagnostics.Metrics 介绍
前言 工友们, .NET 6 Preview 7 已经在8月10号发布了, 除了众多的功能更新和性能改进之外, 在 preview 7 版本中, 也新增了全新的指标API, System.Diagno ...
- 记一次Orika使用不当导致的内存溢出
hprof 文件分析 2021-08-24,订单中心的一个项目出现了 OOM 异常,使用 MemoryAnalyzer 打开 dump 出来的 hprof 文件,可以看到 91.27% 的内存被一个超 ...