Semi-supervised semantic segmentation needs strong, varied perturbations
论文阅读:
Semi-supervised semantic segmentation needs strong, varied perturbations
作者声明
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
原文链接:凤尘 》》https://www.cnblogs.com/phoenixash/p/15379232.html
基本信息
\1.标题:Semi-supervised semantic segmentation needs strong, varied perturbations
\2.作者:Geoff French, Samuli Laine, Timo Aila, Michal Mackiewicz, Graham Finlayson
\3.作者单位:\(^1School\ of\ Computing\ Sciences\ University\ of\ East\ Anglia\ Norwich,\ UK \\^2\ NVIDIA Helsinki,\ Finland\)
\4.发表期刊/会议:BMVC
\5.发表时间:2020
\6.原文链接:https://arxiv.org/abs/1906.01916
Abstract
一致性正则化描述了在半监督分类问题中产生突破性结果的一类方法。先前的工作已经建立了一类假设,在这种假设下,数据分布是由通过低密度区域分离的样本组成的均匀类聚类,这对其成功是非常重要的。我们分析了语义分割的问题,发现它的分布并没有显示出低密度的区域来区分类,这就解释了为什么半监督分割是一个具有挑战性的问题,只有很少的成功报告。然后,我们确定增强的选择是在没有这样的低密度区域的情况下获得可靠的性能的关键。我们发现,最近提出的CutOut和CutMix增强技术的改进变种在标准数据集中产生了最先进的半监督语义分割结果。此外,鉴于语义分割具有挑战性的本质,我们提出将语义分割作为评估半监督正则化器的有效acid test测试。 Implementation at: https://github.com/Britefury/cutmix-semisup-seg.
1.Introduction
半监督学习提供了一个诱人的前景,即使用只有一小部分样本有标签的数据集来训练机器学习模型。这些情况经常出现在实际的计算机视觉问题中,因为大量的图像是现成的,由于成本和劳动力的需要,真值标注成为一个瓶颈。一致性正则化[19,25,26,32]描述了一类半监督学习算法,这些算法在半监督分类中产生了最先进的结果,同时概念简单,通常易于实现。关键的想法是鼓励网络对以各种方式受到干扰的无标记输入给出一致的预测。
一致性正则化的有效性通常归因于平滑假设[23]或聚类假设[5,31,33,37]。平滑假设表明,彼此接近的样本可能具有相同的标签。聚类假设是平滑假设的一种特殊情况,认为决策曲面应该位于数据分布的低密度区域。这通常适用于分类任务,因为迄今为止大多数成功的一致性正则化方法已经被报道出来。
在较高的层次上,语义分割就是分类,每个像素根据其邻域进行分类。因此,有趣的是,在医学成像领域,只有两份一致性正则化成功应用于分割的报告[21,28],而没有一份应用于自然场景图像的报告。我们观察到,即使中心像素的类别发生变化,以相邻像素为中心的\(L^2\)像素含量距离之间的小块也会平滑变化,因此在类边界上不存在低密度区域。这一令人震惊的观察结果促使我们研究在这些情况下,允许一致性正则化操作的条件。
我们发现基于掩模的增强策略对半监督语义分割是有效的,一种适应的CutMix[45]变体实现了显著的收益。
本文的主要贡献在于分析了语义分割的数据分布和方法的简便性。我们利用了经过尝试和测试的半监督学习方法,并采用了CutMix一种监督分类的增强技术进行半监督学习和分割,取得了最先进的结果。
2.Background
我们的工作涉及三个领域的现有技术:最近的分类正则化技术,专注于一致性正则化的半监督分类,以及语义分割。
2.1 MixUp, Cutout, and CutMix
Zhang等人[40]的MixUp正则化器通过在训练过程中使用插值样本提高了有监督图像、语音和表格数据分类器的性能。两个随机选择的样本的输入和目标标签使用一个随机选择的因子进行混合。
Devries等人[11]的Cutout正则化器通过将矩形区域掩蔽为零来增强图像。Yun等人最近提出的[39]CutMix正则化器结合了MixUp和CutOut的各个方面,从图像B中切割出一个矩形区域,并将其粘贴到图像a上。MixUp、CutOut和CutMix提高了监督分类性能,其中CutMix优于其他两个。
2.2 Semi-supervised classification
文献中提出了多种基于一致性正则化的半监督分类方法。他们通常将标准监督损失项(例如交叉熵损失)与非监督一致性损失项结合起来,以鼓励对应用于非监督样本的扰动作出一致预测。
Laine等人[19]的Π-model将每个未标记样本通过分类器两次,应用随机增广过程的两种实现,并使所得到的类别概率预测之间的平方差最小。他们的时间模型和Sajjadi等人[32]的模型鼓励当前预测和历史预测之间的一致性。Miyato等人的[25]将随机增广替换为对抗方向,从而将扰动向决策边界瞄准。
Tarvainen等人[36]的平均教师模型鼓励学生网络预测和教师网络预测之间的一致性,其中教师网络的权重是学生网络的指数移动平均[29]。[13]采用均值教师进行域适应。
无监督数据增强(UDA)模型[38]和最先进的FixMatch模型[34]展示了丰富的数据增强的好处,因为它们都结合了CutOut[11]和RandAugment [10] (UDA)或CTAugment [3] (FixMatch)。RandAugment和CTAugment从14种图像增强中提取。
Verma等人[37]和MixMatch[4]的插值一致性训练(ICT)结合了MixUp[40]和一致性正则化。ICT使用平均教师模型,并将MixUp应用于无监督样本,将输入图像与教师类预测混合,产生混合输入和目标,以训练学生模型。
2.3 Semantic segmentation
大多数语义分割网络将图像分类器转换为一个完全卷积的网络,生成一组密集的预测,用于重叠输入窗口,分割任意大小[22]的输入图像。DeepLab v3[7]架构通过结合atrous卷积和空间金字塔池化来提高定位精度。解码器网络[2,20,30]使用跳跃连接将像编码器一样的图像分类器连接到解码器。编码器逐渐对输入进行向下采样,而解码器则向上采样,从而产生分辨率与输入相匹配的输出。
许多半监督语义分割方法使用额外的数据。Kalluri等人的[17]使用来自不同领域的两个数据集的数据,最大化每个数据集的类嵌入之间的相似性。Stekovic等人的[35]使用深度图像和三维场景的多个视图之间的强制几何约束。
在严格的半监督环境下操作的方法相对较少。Hung等人[16]和Mittal等人[24]采用基于GSN的对抗学习,使用鉴别器网络区分真实和预测的分割图来指导学习。
据我们所知,一致性正则化在分割中的唯一成功应用来自医学成像领域;Perone等人[28]和Li等人[21]分别对MRI体积数据集和皮肤病变应用一致性正则化。两种方法都使用标准增广来提供扰动。
3.Consistency regularization for semantic segmentation
一致性正则化将一致性损失项\(L_{cons}\)添加到在训练过程中被最小化[26]的损失中。在分类任务中,\(L_{cons}\)衡量了将神经网络\(f_θ\)应用于非监督样本\(x\)与同一样本的扰动版本\(\hat{x}\)的预测结果之间的距离\(d(·,·)\),即\(L_{cons} = d(f_θ (x), f_θ (\hat{x}))\)。用于生成\(\hat{x}\)的扰动依赖于所使用的一致性正则化的变体。使用了多种距离度量\(d(·,·)\),例如距离的平方[19]或交叉熵[25]。
Athiwaratkun等人[1]的形式分析支持了聚类假设的好处。他们分析了一个简化的Π-model[19](使用加性各向同性高斯噪声扰动(\(\hat{x} = x+εN(0,1)))\),发现\(L_{cons}\)的期望值与网络输出的雅可比矩阵\(J_{f_θ} (x)\)相对于输入的平方大小近似成正比。因此,最小化\(L_{cons}\)可以平滑无监督样本附近的决策函数,将决策边界及其周围的高梯度区域移动到低样本密度的区域。
3.1 Why semi-supervised semantic segmentation is challenging
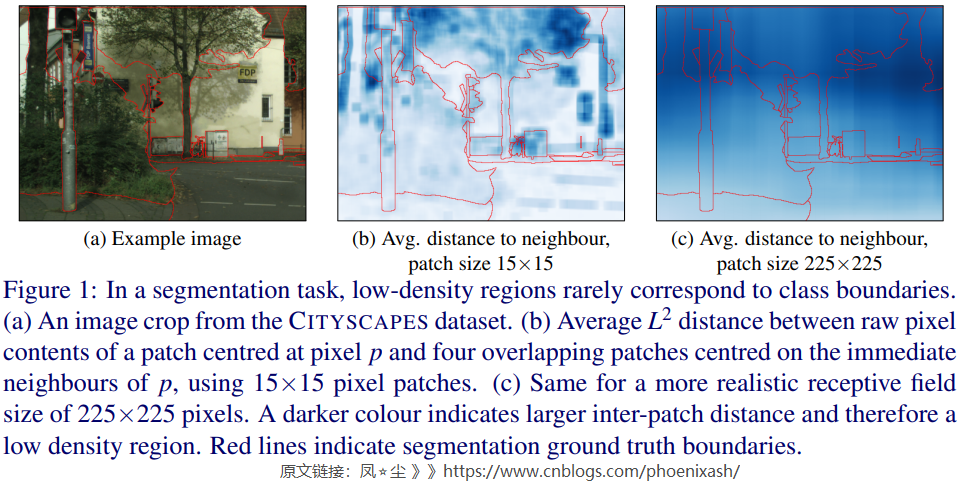
我们将语义分割视为滑动窗口patch分类,目标是识别patch中心像素的类别。鉴于之前的工作[19,25,34]对原始像素(输入)空间应用了扰动,我们对数据分布的分析集中在图像小块的原始像素内容,而不是来自网络内部的更高层次的特征。
我们将一致性正则化在自然图像语义分割问题上的罕见成功归因于输入数据中的低密度区域不能很好地与类边界对齐。这种低密度区域的存在将表现为局部地大于类边界两侧相邻像素为中心的patch之间的平均\(L^2\)距离。在图1中,我们可视化了相邻patch之间的\(L^2\) 距离。当使用一个合理的接受域如图1(c)所示我们可以看到集群假设显然是违反了:一个像素接受域的原始像素内容与相邻像素接受域内容的差异与patch中心像素是否属于同一类无关。
从信号处理的角度很容易解释patch级别距离的缺乏变化。大小HxW的patch,以所有水平相邻像素对为中心的重叠patch像素含量之间\(L^2\)距离的距离图可以写成\(\sqrt{\left(\Delta_{\mathrm{X}} I\right)^{\circ 2} * 1^{H \times W}}\),其中*表示卷积和\(\Delta_{\mathbf{x}}I\)表示水平梯度的输入图像\(I\)。因此,元素级别的平方梯度图像通过HxW盒形滤波器进行低通滤波,它抑制了图像高频成分中的精细细节,导致图像上平滑变化的样本密度。
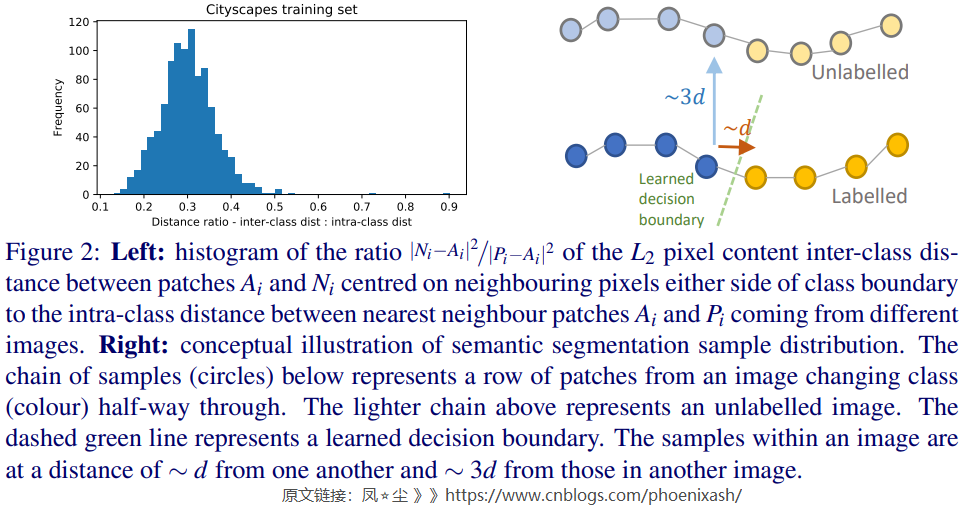
在归纳到其他图像时,我们对CITYSCAPES数据集的分析量化了在应该属于不同类别的两个相邻像素之间设置决策边界所涉及的挑战。我们发现,以类边界两边像素为中心的patch之间的\(L^2\) 距离大约是同一类在不同图像中最近patch距离的1/3(见图2)。这表明,精确定位和取向的决策边界对于良好的性能至关重要。我们在补充材料中进一步详细讨论我们的分析。

3.2 Consistency regularization without the cluster assumption
当考虑在我们上面分析的背景下,成功应用的几个报告的一致性正规化语义分割尤其是李et al。[21]的工作使我们得出这样的结论:低密度区域的存在对类分离是非常有益的,但不是必要的。因此,我们提出了一种替代机制:即使用非各向同性的自然扰动,如图像增强,来约束决策边界的方向,使其与扰动的方向平行(见Athiwaratkun等人[1]的附录)。我们现在将使用一个2D玩具的例子来探索这个问题。
图3a用一个简单的2D玩具均值教师实验说明了聚类假设的好处,在这个实验中,聚类假设成立是因为属于两个不同类别的无监督样本之间存在一个间隙。\(L_{conf}\)使用的扰动是对两个坐标的各向同性高斯偏移,正如预期的那样,学习到的决策边界在两个集群之间整齐地确定。在图3b中,无监督样本是均匀分布的,违反了聚类假设。在这种情况下,一致性的损失弊大于利;即使它成功地使决策函数的邻域变平,它也跨越了真正的类边界。
在图3c中,我们绘制了到真正类边界的距离的轮廓。如果我们约束应用于样本x的扰动,使扰动\(\hat{x}\)位于或非常接近通过x的距离轮廓上,得到的学习决策边界与真实的类边界很好地对齐,如图3d所示。当低密度区域不存在时,必须仔细选择扰动,使跨越类边界的概率最小化。
我们认为可靠的半监督分割是可以实现的,前提是增强/扰动机制遵循以下准则:1)扰动必须多样和高维的以充分约束自然图像的高维空间的边界的方向决定,2)与其他维度的探索相比,扰动跨越真实类边界的概率一定非常小,3)扰动输入应该是可信的;它们不应远远超出各种实际投入。
经典的基于增强的扰动,如裁剪、缩放、旋转和颜色变化,混淆输出类的几率很小,并且已被证明是对自然图像分类的有效方法[19,36]。尽管该方法在一些医学图像分割问题上取得了积极的结果[21,28],但令人惊讶的是,它在自然图像上却无效。这促使我们为半监督语义分割寻找更强、更多样化的增强方法。
3.3 CutOut and CutMix for semantic segmentation
在UDA[38]和FixMatch[34]中,Cutout[11]在半监督分类中产生了很强的结果。UDA消融研究表明,Cutout在半监督性能中贡献了大部分,而FixMatch消融表明,Cutout可以匹配CTAugment使用的14个图像操作组合的效果。DeVries等人[11]认为,Cutout鼓励网络利用更广泛的特征,以克服当前或屏蔽图像各部分的变化组合。这种由Cutout引入的多样性表明,它是一个很有前途的分割候选项。
鉴于MixUp已经成功地用于ICT[37]和MixMatch[4]的半监督分类,我们建议使用CutMix以类似的方式混合无监督样本和相应的预测。 如2.1节所述,CutMix结合了Cutout和MixUp,使用一个矩形蒙版来混合输入图像。鉴于MixUp已经成功地用于ICT[37]和MixMatch[4]的半监督分类,我们建议使用CutMix以类似的方式混合无监督样本和相应的预测。
对比Π-model[19]和均值教师模型[36]的初步实验表明,使用均值教师模型是提高语义切分性能的关键,因此本文的所有实验都使用均值教师框架。我们将学生网络表示为\(f_θ\),教师网络表示为\(g_φ\)。
Cutout. 在[11]中,我们用1初始化一个蒙版M,并将随机选择的矩形内的像素设置为0。为了在语义分割任务中应用cutout,我们用 M 屏蔽输入像素,并忽略被 M 屏蔽为 0 的像素的一致性损失。 FixMatch [34] 使用由裁剪和翻转组成的弱增强方案来预测用作使用强 CTAugment 方案增强的样本的目标的伪标签 。同样,我们认为Cutout是一种强增强形式,因此我们将教师网络\(g_φ\)应用于原始图像生成伪目标,用于训练学生\(f_θ\)。以距离的平方为度量,我们得到\(L_{cons} = ||M\odot(f_θ (M\odot x) g_φ (x))||^2\),其中\(\odot\)为元素积。
CutMix. CutMix 需要两个输入图像,我们将它们表示为 \(x_a\) 和 \(x_b\),我们将它们与掩码 M 混合。参照 ICT ([37]) ,我们混合了教师网络对输入图像的预测 \(g_φ (x_a),g_φ (x_b)\) 生成伪标签,用于学生网络对混合图像的预测。 为了简化符号,让我们定义函数 \(mix(a,b,M) = (1− M)\odot a+ M\odot b\) ,它根据掩码 M 选择输出像素。 我们现在可以将一致性损失写为:
\]
用于分类的Cutout[11]的原始公式使用一个固定尺寸和宽高比的矩形,其中心随机定位,允许部分矩形位于图像边界之外。CutMix[39]随机改变大小,但使用固定的纵横比。对于分割,我们使用CutOut获得了更好的性能,通过随机选择大小和宽高比,并定位矩形,使其完全位于图像内。相比之下,通过将矩形的面积固定为图像面积的一半,同时改变长宽比和位置,CutMix的性能得到了最大化。
虽然Cutout和CutMix应用的增强效果并不会出现在现实生活中的图像中,但从视觉角度来看,它们是合理的。分割网络通常使用图像crop而不是完整的图像来训练,所以用Cutout来分割图像的一段可以看作是逆操作。使用CutMix的效果是将一个矩形区域从一个图像粘贴到另一个图像上,类似地产生一个合理的分割任务。
在我们的补充材料中说明了基于Cutout和Cutmix的一致性损失。
Semi-supervised semantic segmentation needs strong, varied perturbations的更多相关文章
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
论文题目是STC,即Simple to Complex的一个框架,使用弱标签(image label)来解决密集估计(语义分割)问题. 2014年末以来,半监督的语义分割层出不穷,究其原因还是因为pi ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文笔记《Feedforward semantic segmentation with zoom-out features》
[论文信息] <Feedforward semantic segmentation with zoom-out features> CVPR 2015 superpixel-level,f ...
- [Papers] Semantic Segmentation Papers(1)
目录 FCN Abstract Introduction Related Work FCN Adapting classifiers for dense prediction Shift-and-st ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- CVPR2020论文解读:三维语义分割3D Semantic Segmentation
CVPR2020论文解读:三维语义分割3D Semantic Segmentation xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3 ...
- A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
论文阅读笔记: A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation 基本信息 \1.标题:A ...
随机推荐
- flex布局中flex属性运用在随机发红包的算法上
flex布局是现在前端基本上都会运用的一种布局,基本上用到比较多的是父元素设置display:flex,两个子元素,一个设置固定宽度,另一个设置为flex:1(这里都指flex-direction为r ...
- rabbitMq队列长度限制
x-max-length:队列最大容纳消息条数 大于设置条数的时候会把,消息队列头部(先进入消息)的消息移除 x-max-length-bytes:队列最大容量消息内存容量服务端限流内存控制流量:40 ...
- 关于ubuntu使用的那些事儿
时间:2019-04-09 整理:PangYuaner 标题:Ubuntu18.04安装微信(Linux通用) 地址:https://www.cnblogs.com/dotnetcrazy/p/912 ...
- mysql8.0----mysqldump抛出:Unknown table 'COLUMN_STATISTICS' in information_schema (1109)
问题:我尝试使用mysqldump时,得到以下错误: 复制 $> mysqldump --single-transaction --h -u user -p db > db.sql my ...
- 百闻不如一试——公式图片转Latex代码
写博客时,数学公式的编辑比较占用时间,在上一篇中详细介绍了如何在Markdown中编辑数学符号与公式. https://www.cnblogs.com/bytesfly/p/markdown-form ...
- LeetCode通关:通过排序一次秒杀五道题,舒服!
刷题路线参考:https://github.com/chefyuan/algorithm-base 大家好,我是拿输出博客督促自己刷题的老三,前面学习了十大排序:万字长文|十大基本排序,一次搞定!,接 ...
- 使用Keepalived实现Nginx的自动重启及双主热备高可用
1.概述 之前我们使用Keepalived实现了Nginx服务的双机主备高可用,但是有几个问题没有解决,今天一起探讨一下. 1)在双机主备机制中,Keepalived服务如果宕了,会自动启用备机进行服 ...
- WebService学习总结(五)--CXF的拦截器
拦截器是Cxf的基础,Cxf中很多的功能都是由内置的拦截器来实现的,拦截器在Cxf中由Interceptor表示.拦截器的作用类似axis2中handle.Cxf的拦截器包括入拦截器和出拦截器,所有的 ...
- 痞子衡嵌入式:MCUXpresso IDE下将关键函数重定向到RAM中执行的几种方法
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是MCUXpresso IDE下将关键函数重定向到RAM中执行的几种方法. 前段时间痞子衡写了一篇 <在IAR开发环境下将关键函数重 ...
- Hive的分桶表
[分桶概述] Hive表分区的实质是分目录(将超大表的数据按指定标准细分到指定目录),且分区的字段不属于Hive表中存在的字段:分桶的实质是分文件(将超大文件的数据按指定标准细分到分桶文件),且分桶的 ...