Python算法-二叉树深度优先遍历
二叉树
组成:
1、根节点 BinaryTree:root
2、每一个节点,都有左子节点和右子节点(可以为空) TreeNode:value、left、right
二叉树的遍历:
遍历二叉树:深度优先遍历、广度优先遍历。
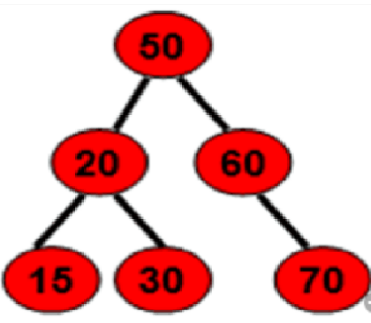
广度:先遍历兄弟节点,再遍历子节点
深度:先遍历子节点,再遍历兄弟节点
上图深度遍历结果:50/20/60/15/30/70
上图广度遍历结果:50/20/15/30/60/70
深度遍历又分为先序、中序、后序的遍历方式:
先序遍历:先根节点,再左子树,再右子树
上图先序遍历结果:50/20/ 15/ 30/ 60/ 70
中序遍历:先左子树,再根节点,再右子树
上图中序遍历结果:15/20/30/50/60/70
后序遍历:先左子树,再右子树,再根节点
上图后序遍历结果:15/30/20/70/60/50
代码实现:
# encoding=utf-8
class TreeNode(object): #定义二叉树类
def __init__(self,val,left=None,right=None):
self.val = val
self.left = left
self.right = right
class BinaryTree(object):
def __init__(self,root=None):
self.root = root
def preScan(self,retList, node): #先序遍历:先跟、再左、后右
if node != None:
retList.append(node.val)
self.preScan(retList, node.left)
self.preScan(retList, node.right)
return retList
def midScan(self, retList, node): #中序遍历:先左、再跟、后右
if node != None:
self.midScan(retList, node.left)
retList.append(node.val)
self.midScan(retList, node.right)
return retList
def postScan(self, retList, node): #后序遍历:先左、再右、后跟
if node != None:
self.postScan(retList, node.left)
self.postScan(retList, node.right)
retList.append(node.val)
return retList
if __name__ =='__main__':
root = TreeNode(50)
root.left = TreeNode(20,left=TreeNode(15),right=TreeNode(30,right=TreeNode(12)))
root.right = TreeNode(60,right=TreeNode(70))
bTree = BinaryTree(root)
retList = bTree.preScan([],bTree.root)
print retList
retList2 = bTree.midScan([],bTree.root)
print retList2
retList3 = bTree.postScan([],bTree.root)
print retList3
Python算法-二叉树深度优先遍历的更多相关文章
- python算法-二叉树广度优先遍历
广度优先遍历:优先遍历兄弟节点,再遍历子节点 算法:通过队列实现-->先进先出 广度优先遍历的结果: 50,20,60,15,30,70,12 程序遍历这个二叉树: # encoding=utf ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- C++ 二叉树深度优先遍历和广度优先遍历
二叉树的创建代码==>C++ 创建和遍历二叉树 深度优先遍历:是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. //深度优先遍历二叉树void depthFirstSearch(Tree r ...
- 05 (OC) 二叉树 深度优先遍历和广度优先遍历
总结深度优先与广度优先的区别 1.区别 1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列. 2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入 ...
- python实现二叉树的遍历以及基本操作
主要内容: 二叉树遍历(先序.中序.后序.宽度优先遍历)的迭代实现和递归实现: 二叉树的深度,二叉树到叶子节点的所有路径: 首先,先定义二叉树类(python3),代码如下: class TreeNo ...
- C++版 - 剑指Offer 面试题39:二叉树的深度(高度)(二叉树深度优先遍历dfs的应用) 题解
剑指Offer 面试题39:二叉树的深度(高度) 题目:输入一棵二叉树的根结点,求该树的深度.从根结点到叶结点依次经过的结点(含根.叶结点)形成树的一条路径,最长路径的长度为树的深度.例如:输入二叉树 ...
- java算法----------二叉树的遍历
二叉树的遍历分为前序.中序.后序和层序遍历四种方式 首先先定义一个二叉树的节点 //二叉树节点 public class BinaryTreeNode { private int data; priv ...
- 基于python实现二叉树的遍历
""" 二叉树实践: 用递归构建树的遍历 # 思路分析 -- 1.使用链式存储,一个Node表示一个数的节点 -- 2.节点考虑使用两个属性变量,分别表示左连接右连接 & ...
- Python算法——二叉树
一.二叉树 from collections import deque class BiTreeNode: def __init__(self, data): self.data = data sel ...
随机推荐
- zTree树插件动态加载
需求: 由于项目中家谱图数据量超大,而一般加载方式是通过,页面加载时 zTree.init方法进行数据加载,将所有数据一次性加载到页面中.而在项目中家谱级别又非常广而深,成千上万级,因此一次加载,完全 ...
- ASP.NET AJAX入门系列(5):使用UpdatePanel控件(二)
UpdatePanel可以用来创建丰富的局部更新Web应用程序,它是ASP.NET 2.0 AJAX Extensions中很重要的一个控件,其强大之处在于不用编写任何客户端脚本,只要在一个页面上添加 ...
- Windows下Apache+PHP+MySQL开发环境的搭建(WAMP)
准备工作: 1.下载apache服务器安装包,官网http://www.apache.org/,下载地址:http://httpd.apache.org/download.cgi 2.下载MySQL, ...
- postgresql 存储过程动态更新数据
-- 目标:动态更新表中数据 -- 老规矩上代码-----------------------------tablename 表名--feildname 字段名数组--feildvalue 字段值数组 ...
- 盒子模型--IE与标准
从上图可以看到标准 W3C 盒子模型的范围包括 margin.border.padding.content,并且 content 部分不包含其他部分. 从上图可以看到 IE 盒子模型的范围也包括 ma ...
- nconf修改密码
修改nconf登录界面密码 [root@Cnyunwei config]# vi .file_accounts.php <?php/*## User/Password file for simp ...
- 爬虫基本原理及requests,response详解
一.爬虫基本原理 1.爬虫是什么 #1.什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样. #2.互联网建立的目的? 互联网的核心价值在于数据 ...
- JS 操作内容 操作元素
操作内容:普通元素.innerHTML = "值": 会把标记执行渲染普通元素.innerText = "值": 将值原封不动的展示出来,即使里面有标记 var ...
- 洛谷 P2947 [USACO09MAR]仰望Look Up
题目描述 Farmer John's N (1 <= N <= 100,000) cows, conveniently numbered 1..N, are once again stan ...
- org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'requestMappingHandlerMapping' defined in class path resource
spring boot web项目运行时提示如下错误 org.springframework.beans.factory.BeanCreationException: Error creating b ...