Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例:
今天就来实战下,用他们来抓取酷狗音乐网上的 Top500排行榜音乐。接下来的代码中除了会用到HttpClient和Jsoup之外,还会用到log4j和ehcache,分别用来记录日志和实现缓存,如果看官对这两个不是很熟悉的话,请自行百度,现在网上的入门实例有很多,我就不专门记笔记了。
那为什么会想到爬取酷狗音乐网呢?其实也不是我想到的,而是不久前看过某位大神的博客就是爬取酷狗的(具体哪位大神不记得了,见谅哈~~~),我也想用自己的代码试试,并且我看的博客里面好像没有用到缓存,也没有用到代理ip这种反反爬虫的工具,我会在我的爬虫程序里面补上,亲测能自动处理全部23页的歌曲(但是付费歌曲由于必须登录购买才能访问,因此未能下载到,只有其他的400+首非付费歌曲可以正常下载),所以酷狗网的工作人员不要担心哦~~~
话有又说回来了,在那篇博客出来后,也没见酷狗音乐去专门处理下,还能给我留下写这段代码的机会,说明人家酷狗不在乎,毕竟付费歌曲是不能爬取的,而且网站已经有了一定的反爬虫机制。
***************************************************************************
声明:
本爬虫程序和程序爬取到的内容仅限个人学习交流使用,
请勿用于商业用途,否则后果自负
***************************************************************************
好,废话不多说,该上干货了~~
================很华丽的分割线=================
一、设计思路
首先说下思路,我看过的那篇博客没有把过程写详细,我就把它补充下吧:
1.点进去Top500排行榜,它的地址栏里面是:https://www.kugou.com/yy/rank/home/1-8888.html?from=homepage,而这个1其实就是页码,访问第N页就把1改成N就行,这个是我爬取的基础
2.点具体某首歌曲,比如《你的酒馆对我打了烊》,新打开页面:https://www.kugou.com/song/#hash=BE1E1D3C2A46B4CBD259ACA7FF050CD3&album_id=14913769,
3.我们F12分析下网络请求(啥?打开F12没东西?大哥呀你不会再刷新下吗),
你会发现有个耗时很长的请求,而且类型是media,它很可能就是真正获取mp3的请求
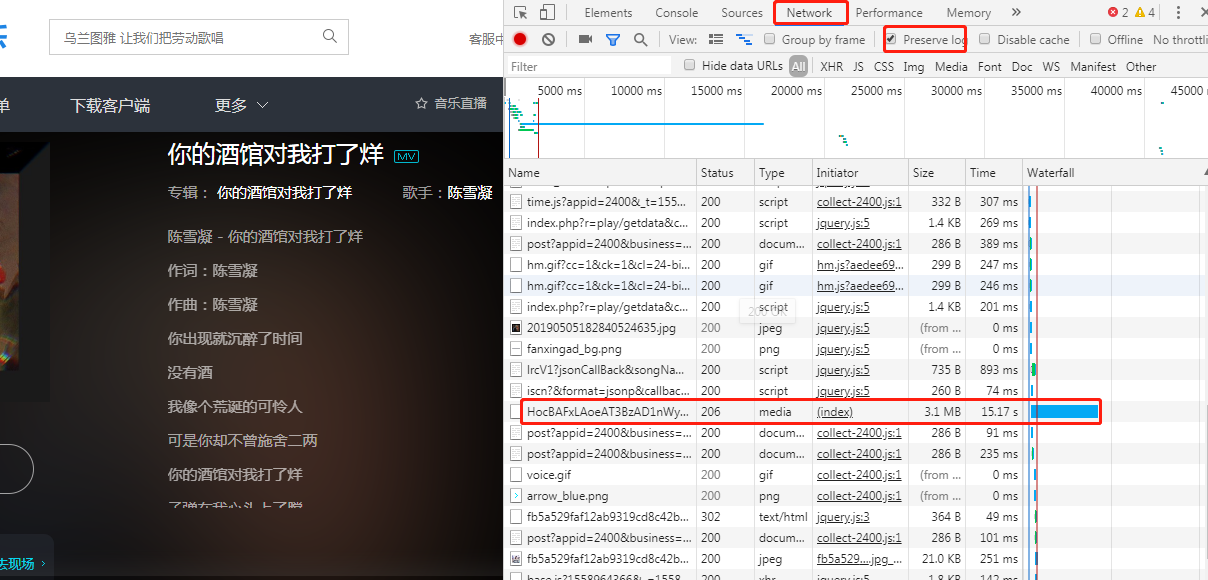
仔细看,果然是的,mp3的真实地址是:http://fs.w.kugou.com/201905272134/9d4d81230e6f5c759df51618b03961a7/G126/M00/05/09/HocBAFxLAoeAT3BzAD1nWyW7V5M814.mp3

关掉页面,重新进入该页面,MP3的真是地址是:http://fs.w.kugou.com/201905272139/2897cc9816b82f4cda304d927187b282/G126/M00/05/09/HocBAFxLAoeAT3BzAD1nWyW7V5M814.mp3
根据这个看不出来啥

继续分析,那它是怎么找到这个真实地址的呢?应该是前面的某个请求里面获取到了真实地址,找前面的请求:
这个请求的response里面含有MP3的真实地址,
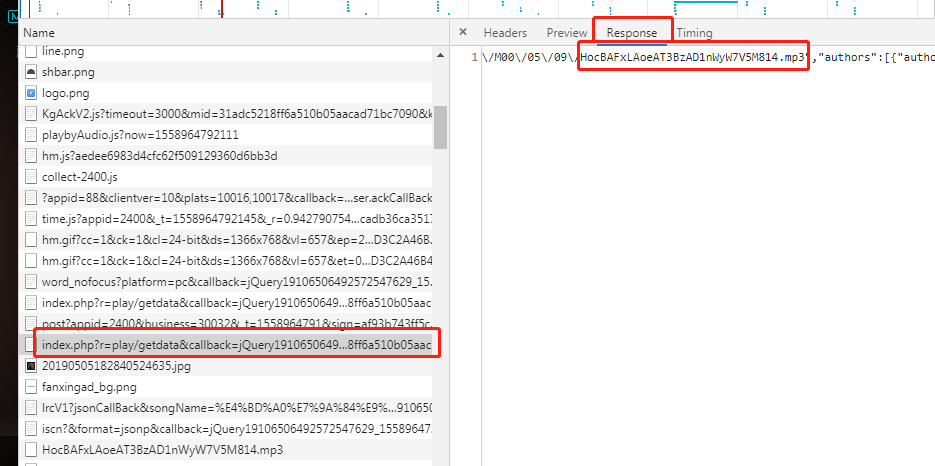
请求的request为:
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19106506492572547629_1558964792005&hash=BE1E1D3C2A46B4CBD259ACA7FF050CD3&album_id=14913769&dfid=3LWatj1PQwvn09grkH3FbFAF&mid=31adc5218ff6a510b05aacad71bc7090&platid=4&_=1558964792007
退出重新获取一次,然后再退出换首歌再获取一下这个request,你会发现一些规律:
粉红色是歌曲播放页面地址栏里面的内容,加粗部分是日期的long值,其他的都可以不变(“jQuery19106506492572547629_1558964792005”虽然每次有变化,但是经过尝试,其实没有影响),
所以我们就可以通过请求这个链接来获取带有MP3真实地址的json,然后请求真实地址,从而获取音乐文件。
4.那粉红色部分的值怎么获取呢?查看top500的列表页的源码会发现有段内容,这个里面记录的第N页所有歌曲的hash值、歌曲名、id等基本信息
// 列表数据
global.features = [{"Hash":"BE1E1D3C2A46B4CBD259ACA7FF050CD3","FileName":"\u9648\u96ea\u51dd - \u4f60\u7684\u9152\u9986\u5bf9\u6211\u6253\u4e86\u70ca","timeLen":251.048,"privilege":10,"size":4024155,"album_id":14913769,"encrypt_id":"tlk6517"},{"Hash":"9198B18815EE8CE42AE368AE29276F78","FileName":"\u9648\u96ea\u51dd - \u7eff\u8272","timeLen":269.064,"privilege":10,"size":4314636,"album_id":15270740,"encrypt_id":"txskm8f"},{"Hash":"458E9B9F362277AC37E9EEF1CB80B535","FileName":"\u738b\u742a - \u4e07\u7231\u5343\u6069","timeLen":322.011,"privilege":10,"size":5152644,"album_id":18712576,"encrypt_id":"vsdz726"},{"Hash":"7E91FDE7E8D33E8ED11C6DB4620917E2","FileName":"\u5b64\u72ec\u8bd7\u4eba - \u6e21\u6211\u4e0d\u6e21\u5979","timeLen":182.23,"privilege":10,"size":2916145,"album_id":14624971,"encrypt_id":"th6cka5"},{"Hash":"9681F4CCD830B8436DB5F8218C7DF0C7","FileName":"\u864e\u4e8c - \u4f60\u4e00\u5b9a\u8981\u5e78\u798f","timeLen":259.066,"privilege":10,"size":4155201,"album_id":12249679,"encrypt_id":"rniv71f"},{"Hash":"44ABEAA9CCE29AFB5C947D4FBD2C567F","FileName":"\u5927\u58ee - \u4f2a\u88c5","timeLen":301.004,"privilege":10,"size":4817151,"album_id":15999493,"encrypt_id":"u6n6i28"},{"Hash":"5FCE4CBCB96D6025033BCE2025FC3943","FileName":"\u5468\u6770\u4f26 - \u544a\u767d\u6c14\u7403","timeLen":215,"privilege":10,"size":3443771,"album_id":1645030,"encrypt_id":"d5c5m23"},{"Hash":"0A62227CAAB66F54D43EC084B4BDD81F","FileName":"\u5468\u6770\u4f26 - \u7a3b\u9999","timeLen":223.582,"privilege":10,"size":3577344,"album_id":960399,"encrypt_id":"74itc7"},{"Hash":"A11F7A8BD2EA5BBDB32F58A9081F27B4","FileName":"\u82b1\u59d0 - \u72c2\u6d6a","timeLen":181.037,"privilege":10,"size":2902317,"album_id":13476703,"encrypt_id":"sfzob9f"},{"Hash":"33EB8FE0DC9F70D9F7FE4CB77305D5A8","FileName":"\u6d77\u6765\u963f\u6728\u3001\u963f\u5477\u62c9\u53e4\u3001\u66f2\u6bd4\u963f\u4e14 - \u522b\u77e5\u5df1","timeLen":280.111,"privilege":10,"size":4482365,"album_id":16324799,"encrypt_id":"uajki71"},{"Hash":"76D04F195C1F081CC0CD027A310A7D9A","FileName":"\u738b\u742a - \u7ad9\u7740\u7b49\u4f60\u4e09\u5343\u5e74","timeLen":381.083,"privilege":10,"size":6109771,"album_id":13886090,"encrypt_id":"sunkg88"},{"Hash":"9C00A468D2658487DB2DE4ED16A12B5A","FileName":"\u738b\u8d30\u6d6a - \u50cf\u9c7c","timeLen":285.031,"privilege":10,"size":4565459,"album_id":13621986,"encrypt_id":"smhia84"},{"Hash":"4F76587A5B0B93EEF15883E54DD3E2DB","FileName":"\u6bdb\u4e0d\u6613 - \u6d88\u6101 (Live)","timeLen":179,"privilege":10,"size":2870658,"album_id":2900867,"encrypt_id":"gf96d56"},{"Hash":"8B7DF540F77042FB76DA1EE3A79EAE0A","FileName":"NCF-\u827e\u529b - \u9ece\u660e\u524d\u7684\u9ed1\u6697 (\u5973\u58f0\u7248)","timeLen":145.058,"privilege":10,"size":2329748,"album_id":17997426,"encrypt_id":"twhgf05"},{"Hash":"7A3269C36D07E88A24FB35D246856FA4","FileName":"Yusee\u897f - \u5fc3\u5982\u6b62\u6c34","timeLen":182.883,"privilege":10,"size":2926594,"album_id":19692772,"encrypt_id":"wd07h77"},{"Hash":"7995A2173ED0914868BB860F93C3D642","FileName":"\u9b4f\u65b0\u96e8 - \u4f59\u60c5\u672a\u4e86","timeLen":216.189,"privilege":10,"size":3459539,"album_id":20709823,"encrypt_id":"wnru4c8"},{"Hash":"D8E40DA7F51C0486224E008A3B6ABD45","FileName":"\u5154\u5b50\u7259 - \u5c0f\u767d\u5154\u9047\u4e0a\u5361\u5e03\u5947\u8bfa","timeLen":163.087,"privilege":10,"size":2622454,"album_id":12492325,"encrypt_id":"rrrbccf"},{"Hash":"D2462B148305FF7D990F3B6EB3F90D66","FileName":"\u5f20\u656c\u8f69 - \u53ea\u662f\u592a\u7231\u4f60","timeLen":254.302,"privilege":10,"size":4080941,"album_id":558311,"encrypt_id":"3f65bd"},{"Hash":"03FE01457005CEEF8627BE5E5313D230","FileName":"\u84dd\u4e03\u4e03 - \u9ece\u660e\u524d\u7684\u9ed1\u6697 (\u5973\u58f0\u7248)","timeLen":111.986,"privilege":10,"size":1792253,"album_id":19842582,"encrypt_id":"w8lwi96"},{"Hash":"96E064A41AB84EBE4C03C6AAE3CB9334","FileName":"\u5f20\u7d2b\u8c6a - \u53ef\u4e0d\u53ef\u4ee5","timeLen":240.093,"privilege":10,"size":3855453,"album_id":9618875,"encrypt_id":"mkt6v7f"},{"Hash":"5D6CCE061BD65404BF5669FDD26C40B1","FileName":"\u4e01\u8299\u59ae - \u53ea\u662f\u592a\u7231\u4f60","timeLen":247.797,"privilege":10,"size":3965342,"album_id":18231730,"encrypt_id":"vhrxi30"},{"Hash":"95B48A0894FC2198B6E2B93C034AAC72","FileName":"\u5468\u6770\u4f26 - \u9752\u82b1\u74f7","timeLen":239.046,"privilege":10,"size":3825206,"album_id":979856,"encrypt_id":"7a6sd6"}];
把这些信息获取后放到ehcache缓存,hash为key,album_id为value,循环单个歌曲的时候播放页也能获取到hash,然后根据hash到缓存里面取值即可
5.根据以上获取的信息就可以正常爬取文件了,但是在爬取了一段时间后会发现无法正常下载了,在log中看到请求不到MP3的真实地址, 返回的json报文里面error_code不为0,这个就是爬虫程序被网站识别了,这就要用到代理ip了,当被识别出后就换个代理ip,如此循环下去直到歌曲轮询完或代理ip被用完为止。
二、核心代码展示
有了思路之后,就可以写代码了,由于篇幅原因,这里只贴出部分核心代码,完整代码请在下面的gitee上获取
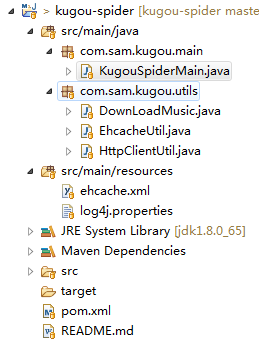
代码结构:
- 需要的依赖
<!-- httpclient 抓取html --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.8</version> </dependency> <!-- Jsoup 解析html--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency> <!-- 用来下载歌曲,就不用自己写流操作了 --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.6</version> </dependency> <!-- fastjson用来处理json --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.58</version> </dependency> <!-- ehcache用作缓存 --> <dependency> <groupId>net.sf.ehcache</groupId> <artifactId>ehcache</artifactId> <version>2.10.6</version> </dependency> <!-- 引入slf4j-nop 纯粹是防止ehcache执行报错 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-nop</artifactId> <version>1.7.2</version> </dependency> <!-- log4j作为日志系统 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> - 主类
package com.sam.kugou.main; import java.util.List; import org.apache.log4j.Logger; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.alibaba.fastjson.JSONObject; import com.sam.kugou.utils.DownLoadMusic; import com.sam.kugou.utils.EhcacheUtil; import com.sam.kugou.utils.HttpClientUtil; public class KugouSpiderMain { static final Logger logger = Logger.getLogger(KugouSpiderMain.class); static String URL_TEMP = "https://www.kugou.com/yy/rank/home/PAGE_NUM-8888.html?from=homepage"; public static final int SLEEP_TIME_WHEN_DENY = 1000*60*60;//被网站识别后睡眠时间 public static final int SPIDER_DURING = 1;//隔多久爬取下一首,单位:ms public static final String DIR_NAME = "E:\\personal\\音乐\\酷狗\\";//音乐下载地址 public static void main(String[] args) { //酷狗TOP500页面 try { for (int i = 1; i <= 23; i++) { String url = URL_TEMP; url = url.replace("PAGE_NUM", i + ""); /** * 1.请求歌曲列表 */ logger.info(url); String html = HttpClientUtil.getHtml(url); logger.debug(html); /** * 2.获取该页的hash和id 放到缓存 */ int beginIdx = html.indexOf("global.features = "); int endIdx = html.indexOf("];", beginIdx); String features = html.substring(beginIdx, endIdx + 1).replace("global.features = ", ""); logger.info("containingOwnText >>>>>> " + features); List<JSONObject> list = JSONObject.parseArray(features, JSONObject.class); for (JSONObject jsonObject : list) { String hash = (String) jsonObject.get("Hash"); Integer albumId = (Integer) jsonObject.get("album_id"); EhcacheUtil.setCache(hash, albumId); } /** * 3.解析列表内容 */ Document doc = Jsoup.parse(html); Elements songList = doc.select(".pc_temp_songlist ul li a"); for (Element element : songList) { String title = element.attr("title"); String href = element.attr("href"); if(href.contains("https")) { try { Thread.sleep(SPIDER_DURING); } catch (InterruptedException e) { logger.error(e.getMessage()); } logger.info("title " + title +" >>> href " + href); DownLoadMusic.requestMusic(title, href); } } } } catch(Exception ex) { logger.error(ex.getMessage(), ex); } finally { /*** * 4.关闭 */ EhcacheUtil.shutDownManager(); } } } - 获取真实地址
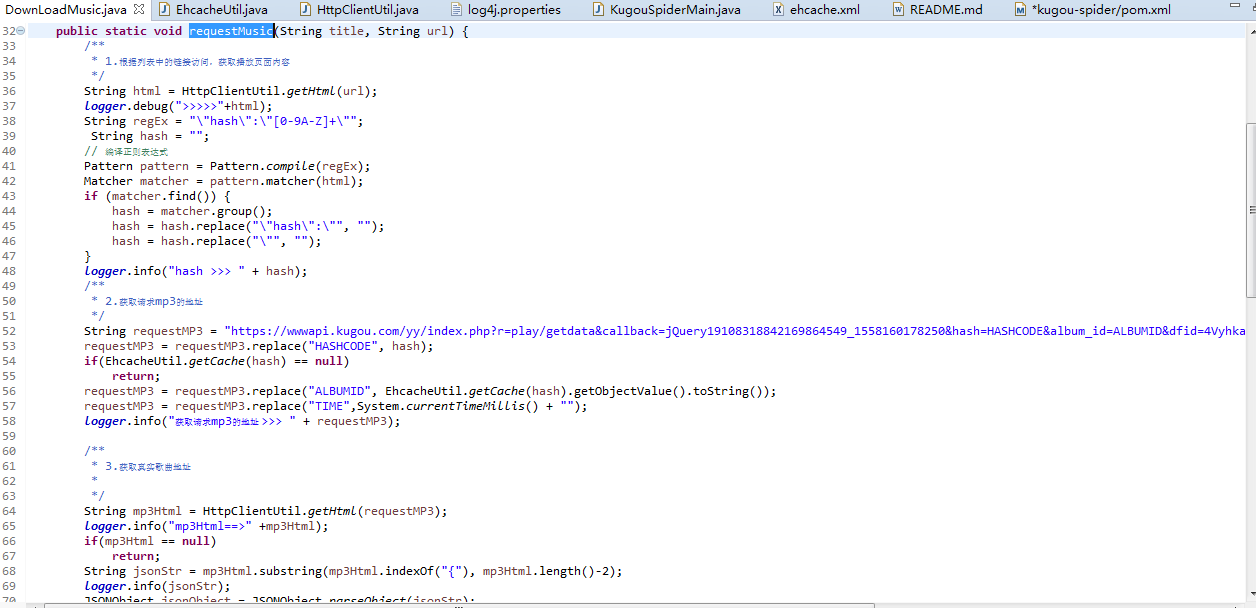
- 执行下载
public static void downLoad(String title, String url) { if(url == null || url.equals("")) { return ; } //已经完成的就不再重新下载 Element finishedCache = EhcacheUtil.getFinishedCache(title); logger.debug("finishedCache >>>>> " + finishedCache); if(finishedCache != null) { logger.info("歌曲已经存在!!!"); return; } String suffix = url.substring(url.lastIndexOf(".")); try { HttpEntity httpEntity = HttpClientUtil.getHttpEntity(url); InputStream inputStream = httpEntity.getContent(); String filePath = KugouSpiderMain.DIR_NAME+title+suffix; FileUtils.copyToFile(inputStream, new File(filePath)); logger.info("***完成下载:***"+title+suffix); logger.info("***总歌曲数量:***"+(new File(KugouSpiderMain.DIR_NAME)).list().length); EhcacheUtil.setFinishedCache(url, title); } catch (IOException e) { logger.error(e.getMessage()); } } - 设置代理ip
public static boolean setProxy() { // 1.创建一个httpClient CloseableHttpClient httpClient = HttpClients.createDefault(); CloseableHttpResponse response = null; String url = "https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list"; try { response = doRequest(httpClient, url); logger.debug("getHtml " + url + "**处理结果:**" + response.getStatusLine()); // 5.判断返回结果,200, 成功 if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) { HttpEntity httpEntity = response.getEntity(); String html = EntityUtils.toString(httpEntity, "utf-8"); html = "["+html+"]"; List<JSONObject> list = JSONArray.parseArray(html, JSONObject.class); for (JSONObject jsonObject : list) { int port = Integer.valueOf(jsonObject.get("port").toString()); String host = jsonObject.get("host").toString(); logger.info(host + ":"+port); if(isHostConnectable(host, port)) {//代理ip可以连接 Element ipsCache = EhcacheUtil.getProxyIpsCache(host, port);//代理ip未使用过 if(ipsCache == null) { proxyIp = host; proxyPort = port; EhcacheUtil.setProxyIpsCache(host, port); break; } else { logger.info("该代理ip已经使用过,切换下一个"); } } } } } catch (Exception e) { logger.error(e.getMessage(),e); return false; } finally { // 关闭 HttpClientUtils.closeQuietly(response); HttpClientUtils.closeQuietly(httpClient); } logger.info("切换代理ip成功:>>>" + proxyIp + ":" + proxyPort); return true; }
三、源码下载
源码已经上传到我的gitee:
https://gitee.com/sam-uncle/kugou-spider
欢迎下载~~
四、遗留问题
1.只能抓取到免费歌曲,对于收费歌曲不能抓取,其实我们也不该抓取
2.代码中为了方便用了很多static,不能支持多线程或并发抓取
3.其实代理IP那里可以优化的
声明:
本爬虫程序和程序爬取到的内容仅限个人学习交流使用,请勿用于商业用途,否则后果自负!!!谢谢
Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)的更多相关文章
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
- 【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客 import requests import time from bs4 import BeautifulSoup def get_html(url): ''' 获得 HTML ' ...
- python多线程爬取-今日头条的街拍数据(附源码加思路注释)
这里用的是json+re+requests+beautifulsoup+多线程 1 import json import re from multiprocessing.pool import Poo ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
随机推荐
- C语言用一维数组打印杨辉三角(原:无意中想到)
本贴地址 ] = { }; a[] = , a[] = ; int i, j,m; ; i <= ; i++) //2-11 输出10行 { ; j > ; j--) //关键在这句,倒着 ...
- hashlib加密模块
python hashlib密码加密 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/dss_dssssd/article/details/828 ...
- WampServer配置说明
注意:所有的修改操作都要重启WampServer服务器,部分需要重启WampServer软件 1.修改默认端口 1)打开文件:C:\wamp\bin\apache\apache2.4.9\conf\h ...
- Hive jdbc连接出现java.sql.SQLException: enabling autocommit is not supported
1.代码如下 String url = "jdbc:hive2://master135:10000/default"; String user = "root" ...
- git+jenkins持续集成三-定时构建语法
构建位置:选择或创建工程_设置_构建触发器 1. 定时构建语法:* * * * * (五颗星,多个时间点,中间用逗号隔开)第一个*表示分钟,取值0~59第二个*表示小时,取值0~23第三个*表示一个月 ...
- C# 序列化和反序列化 详解
什么是序列化以及如何实现序列化? 如何将对象数据写入 XML 文件? 如何从 XML 文件读取对象数据? 什么是序列化以及如何实现序列化? 序列化是通过将对象转换为字节流,从而存储对象或将对象传输到内 ...
- [转] linux中 参数命令 -- 和 - 的区别
在 Linux 的 shell 中,我们把 - 和 -- 加上一个字符(字符串)叫做命令行参数. 主流的有下面几种风格Unix 风格参数 前面加单破折线 -BSD 风格参数 前面不加破折线GNU 风格 ...
- redis linux 安装
安装 1): wget http://download.redis.io/releases/redis-5.0.2.tar.gz 2): tar xzf redis-5.0.2.tar.gz 3):c ...
- Could not connect to Redis at 127.0.0.1:6379: Connection refused
启动redis: redis-server ../redis.conf redis启动成功后 执行命令行redis-cli报:Could not connect to Redis at 127.0. ...
- Python脚本获取Linux系统信息
# -*- coding:utf-8 -*- import os import subprocess import re import hashlib #对字典取子集 def sub_dict(for ...