1.7-1.12 MapReduce Wordflow
一、案例运行MapReduce Workflow
1、准备examples
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# pwd
/opt/cdh-5.3.6/oozie-4.0.0-cdh5.3.6 [root@hadoop-senior oozie-4.0.0-cdh5.3.6]# tar zxf oozie-examples.tar.gz //此压缩包默认存在 [root@hadoop-senior oozie-4.0.0-cdh5.3.6]# cd examples/ [root@hadoop-senior examples]# ls
apps input-data src
2、将examples目录上传到hdfs
##上传
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# /opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put examples examples ##查看
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -ls /user/root |grep examples
drwxr-xr-x - root supergroup 0 2019-05-10 14:01 /user/root/examples
3、修改配置
##先启动yarn、historyserver
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start resourcemanager [root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start nodemanager
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# sbin/mr-jobhistory-daemon.sh start historyserver
##看一下hdfs上examples里的目录结构
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -ls /user/root/examples/apps/map-reduce
Found 5 items
-rw-r--r-- 1 root supergroup 1028 2019-05-10 14:01 /user/root/examples/apps/map-reduce/job-with-config-class.properties
-rw-r--r-- 1 root supergroup 1012 2019-05-10 14:01 /user/root/examples/apps/map-reduce/job.properties
drwxr-xr-x - root supergroup 0 2019-05-10 14:01 /user/root/examples/apps/map-reduce/lib
-rw-r--r-- 1 root supergroup 2274 2019-05-10 14:01 /user/root/examples/apps/map-reduce/workflow-with-config-class.xml
-rw-r--r-- 1 root supergroup 2559 2019-05-10 14:01 /user/root/examples/apps/map-reduce/workflow.xml 说明:workflow.xml文件必须在hdfs上; job.properties文件在本地有也可以 ####修改 job.properties nameNode=hdfs://hadoop-senior.ibeifeng.com:8020
jobTracker=hadoop-senior.ibeifeng.com:8032
queueName=default
examplesRoot=examples oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce/workflow.xml
outputDir=map-reduce
##更新一下hdfs的文件内容,不更新应该也可以
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# /opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -rm examples/apps/map-reduce/job.properties [root@hadoop-senior oozie-4.0.0-cdh5.3.6]# /opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put examples/apps/map-reduce/job.properties examples/apps/map-reduce/
4、
##
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# bin/oozie help ##运行一个MapReduce job
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run
job: 0000000-190510134749297-oozie-root-W ##
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -ls /user/root/examples/output-data/map-reduce
Found 2 items
-rw-r--r-- 1 root supergroup 0 2019-05-10 16:27 /user/root/examples/output-data/map-reduce/_SUCCESS
-rw-r--r-- 1 root supergroup 1547 2019-05-10 16:27 /user/root/examples/output-data/map-reduce/part-00000 oozie其实就是一个MapReduce,可以在yarn的web页面中看见,在oozie的页面中也可以看见; ##用命令行查看命令运行结果
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# bin/oozie job -oozie http://localhost:11000/oozie -info 0000000-190510134749297-oozie-root-W
二、自定义Workflow
1、关于workflow
工作流引擎Oozie(驭象者),用于管理Hadoop任务(支持MapReduce、Spark、Pig、Hive),把这些任务以DAG(有向无环图)方式串接起来。
Oozie任务流包括:coordinator、workflow;workflow描述任务执行顺序的DAG,而coordinator则用于定时任务触发,相当于workflow的定时管理器,其触发条件包括两类:
1. 数据文件生成
2. 时间条件
workflow定义语言是基于XML的,它被称为hPDL(Hadoop过程定义语言)。 workflow节点:
控制流节点(Control Flow Nodes)
动作节点(Action Nodes) 其中,控制流节点定义了流程的开始和结束(start、end),以及控制流程的执行路径(Execution Path),如decision、fork、join等;
而动作节点包括Hadoop任务、SSH、HTTP、eMail和Oozie子流程等。 节点名称和转换必须符合以下模式=[a-zA-Z][\-_a-zA-Z0-0]*=,最多20个字符。
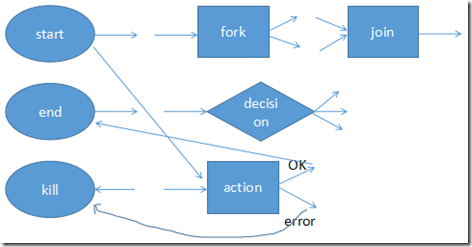
start—>action—(ok)-->end
start—>action—(error)-->end
2、Workflow Action Nodes
Action Computation/Processing Is Always Remote Actions Are Asynchronous Actions Have 2 Transitions, ok and error Action Recovery
三、MapReduce action
1、workflow
Oozie中WorkFlow包括job.properties、workflow.xml 、lib 目录(依赖jar包)三部分组成。
job.properties配置文件中包括nameNode、jobTracker、queueName、oozieAppsRoot、oozieDataRoot、oozie.wf.application.path、inputDir、outputDir,
其关键点是指向workflow.xml文件所在的HDFS位置。 ##############
job.properties 关键点:指向workflow.xml文件所在的HDFS位置 workflow.xml (该文件需存放在HDFS上)
包含几点:
*start
*action
*MapReduce、Hive、Sqoop、Shell
ok
error
*kill
*end lib 目录 (该目录需存放在HDFS上) 依赖jar包
2、MapReduce action
可以将map-reduce操作配置为在启动map reduce作业之前执行文件系统清理和目录创建,MapReduce的输入目录不能存在; 工作流作业将等待Hadoop map/reduce作业完成,然后继续工作流执行路径中的下一个操作。 Hadoop作业的计数器和作业退出状态(=FAILED=、kill或succeed)必须在Hadoop作业结束后对工作流作业可用。 map-reduce操作必须配置所有必要的Hadoop JobConf属性来运行Hadoop map/reduce作业。
四、新API中MapReduce Action
1、准备目录
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# mkdir -p oozie-apps/mr-wordcount-wf/lib [root@hadoop-senior oozie-4.0.0-cdh5.3.6]# ls oozie-apps/mr-wordcount-wf/
job.properties lib workflow.xml //job.properties workflow.xml这两个文件可以从其他地方copy过来再修改
2、job.properties
nameNode=hdfs://hadoop-senior.ibeifeng.com:8020
jobTracker=hadoop-senior.ibeifeng.com:8032
queueName=default
oozieAppsRoot=user/root/oozie-apps
oozieDataRoot=user/root/oozie/datas oozie.wf.application.path=${nameNode}/${oozieAppsRoot}/mr-wordcount-wf/workflow.xml inputDir=mr-wordcount-wf/input
outputDir=mr-wordcount-wf/output

3、workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.5" name="mr-wordcount-wf">
<start to="mr-node-wordcount"/>
<action name="mr-node-wordcount">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${oozieDataRoot}/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.queuename</name>
<value>${queueName}</value>
</property>
<property>
<name>mapreduce.job.map.class</name>
<value>com.ibeifeng.hadoop.senior.mapreduce.WordCount$WordCountMapper</value>
</property>
<property>
<name>mapreduce.job.reduce.class</name>
<value>com.ibeifeng.hadoop.senior.mapreduce.WordCount$WordCountReducer</value>
</property> <property>
<name>mapreduce.map.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.map.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.inputdir</name>
<value>${nameNode}/${oozieDataRoot}/${inputDir}</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.outputdir</name>
<value>${nameNode}/${oozieDataRoot}/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
4、创建hdfs目录和数据,并运行
##
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -mkdir -p /user/root/oozie/datas/mr-wordcount-wf/input
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -put /opt/datas/wc.input /user/root/oozie/datas/mr-wordcount-wf/input ##把oozie-apps目录上传到hdfs上
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# /opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put oozie-apps/ oozie-apps ##执行oozie job
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# export OOZIE_URL=http://hadoop-senior.ibeifeng.com:11000/oozie/
[root@hadoop-senior oozie-4.0.0-cdh5.3.6]# bin/oozie job -config oozie-apps/mr-wordcount-wf/job.properties -run 此时可以在oozie 和yarn的web上看到job
##运行成功,查看运行结果
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -text /user/root/oozie/datas/mr-wordcount-wf/output/part-r-00000
hadoop 4
hdfs 1
hive 1
hue 1
mapreduce 1
五、workflow编程要点
如何定义一个WorkFlow:
*job.properties
关键点:指向workflow.xml文件所在的HDFS位置
*workflow.xml
定义文件
XML文件
包含几点
*start
*action
MapReduce、Hive、Sqoop、Shelll
*ok
*fail
*kil1
*end *1ib目录
依赖的jar包 workflow.xml编写:
*流程控制节点
*Action节点 MapReduce Action:
如何使用ooize调度MapReduce程序
关键点:
将以前Java MapReduce程序中的【Driver】部分
||
configuration
##使用新API的配置
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
1.7-1.12 MapReduce Wordflow的更多相关文章
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 大数据入门第九天——MapReduce详解(六)MR其他补充
一.自定义in/outputFormat 1.需求 现有一些原始日志需要做增强解析处理,流程: 1. 从原始日志文件中读取数据 2. 根据日志中的一个URL字段到外部知识库中获取信息增强到原始日志 3 ...
- 运行mapreduce - java.lang.InterruptedException
错误日志: 2018-11-19 05:23:51,686 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit> ...
- [转] hadoop MapReduce实例解析-非常不错,讲解清晰
来源:http://blog.csdn.net/liuxiaochen123/article/details/8786715?utm_source=tuicool 2013-04-11 10:15 4 ...
- MapReduce On Yarn的配置详解和日常维护
MapReduce On Yarn的配置详解和日常维护 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce运维概述 MapReduce on YARN的运维主要是 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- C语言--函数篇
1-1.函数简单调用 1 #include<stdio.h> 2 #include<string.h> 3 #include<windows.h> 4 int ...
- uboot下载地址
非常奇怪百度搜索都搜不到一个好的uboot下载的说明,仅此标记 HOME http://www.denx.de/wiki/U-Boot/SourceCode sourcecode http://www ...
- div和img之间的缝隙问题
这次做的项目,客户说.banner图的上下之间不要留有空隙,细致一看才发现,上下居然都有空隙.审查元素,发现全部的div,img的padding和margin都是0,对于这个间隙到底是假设产生的真的是 ...
- websotrom 2016.2 license Server
license server” 输入:http://114.215.133.70:41017 仅供学习测试使用,支持正版.
- Fakeapp2.2安装,使用简记
1,硬件和操作系统,支持cuda的Nvidia显卡,8G及以上的内存,Windows10 x64(推荐,Windows7 x64亲测可行),可以使用gpu-z查看你的显卡详情 我的笔记本是双显卡(都是 ...
- forEach for for in for of性能问题
var arr = new Array(1000); console.time('forEach'); arr.forEach(data => { }); console.timeEnd('fo ...
- IOS AFNETWORKING POST
IOS AFNETWORKING POST 请求 #pragma mark post 请求 // 获取 url 路劲,不带参数 NSString *requestUrl = [[url compone ...
- Java基础知识查漏 一
Java基础知识查漏 一 Jdk和jre Jdk是java程序设计师的开发工具,只要包含编译程序,jvm和java函数库 Jre中只有jvm和java函数库,没有编译程序的相关工具,适合只运行不撰写j ...
- Apache JServ Protocol
ajp_百度百科 https://baike.baidu.com/item/ajp/1187933 AJP(Apache JServ Protocol)是定向包协议.因为性能原因,使用二进制格式来传输 ...
- HDFS HBase Solr Which one?
从访问模式角度决策 HDFS 压缩性能最优.扫描速度最快:不支持随机访问,仅支持昂贵.复杂的文件查询 HBase适合随机访问 Solr 适合检索需求 HBase访问单个记录的时间为毫秒级别,而HDFS ...