Pearson product-moment correlation coefficient in java(java的简单相关系数算法)
一、什么是Pearson product-moment correlation coefficient(简单相关系数)?
相关表和相关图可反映两个变量之间的相互关系及其相关方向,但无法确切地表明两个变量之间相关的程度。
于是,著名统计学家卡尔·皮尔逊设计了统计指标——相关系数(Correlation
coefficient)。
相关系数是用以反映变量之间相关关系密切程度的统计指标。
相关系数是按积差方法计算,相同以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
百度百科:http://baike.baidu.com/view/172091.htm
在统计学中,皮尔逊积矩相关系数(英语:Pearson
product-moment correlation coefficient。又称作 PPMCC或PCCs[1],
文章中经常使用r或Pearson's r表示)用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。
它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。
Wikipedia:http://zh.wikipedia.org/zh/皮尔逊积矩相关系数
二、简单相关系数的公式
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:

以上方程定义了整体相关系数, 一般表示成希腊字母ρ(rho)。基于样本对协方差和标准差进行预计,能够得到样本相关系数,
一般表示成r:
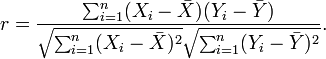
一种等价表达式的是表示成标准分的均值。
基于(Xi, Yi)的样本点。样本皮尔逊系数是

当中
-
 、
、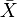 及
及 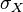
Wikipedia:http://zh.wikipedia.org/zh/皮尔逊积矩相关系数

相关系数公式
简单相关系数:又叫相关系数或线性相关系数。一般用字母P 表示。用来度量两个变量间的线性关系。
百度百科:http://baike.baidu.com/view/172091.htm
三、代码实现:
/**
*
*/
package numerator.pearson.conefficient; import java.util.ArrayList;
import java.util.List;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader; /**
* @author alan-king
*
* the class is going to calculate the numerator;
*
*
*/
public class NumeratorCalculate { //add global varieties
protected List<String> xList , yList; public NumeratorCalculate(List<String> xList ,List<String> yList){
this.xList = xList;
this.yList = yList;
} /**
* add operate method
*/
public double calcuteNumerator(){
double result =0.0;
double xAverage = 0.0;
double temp = 0.0; int xSize = xList.size();
for(int x=0;x<xSize;x++){
temp += Double.parseDouble(xList.get(x));
}
xAverage = temp/xSize; double yAverage = 0.0;
temp = 0.0;
int ySize = yList.size();
for(int x=0;x<ySize;x++){
temp += Double.parseDouble(yList.get(x));
}
yAverage = temp/ySize; //double sum = 0.0;
for(int x=0;x<xSize;x++){
result+=(Double.parseDouble(xList.get(x))-xAverage)*(Double.parseDouble(yList.get(x))-yAverage);
}
return result;
}
}
代码二:DenominatorCalculate类
/**
*
*/
package numerator.pearson.conefficient; import java.util.List; /**
* @author alan-king
*
*/
public class DenominatorCalculate { //add denominatorCalculate method
public double calculateDenominator(List<String> xList,List<String> yList){
double standardDifference = 0.0;
int size = xList.size();
double xAverage = 0.0;
double yAverage = 0.0;
double xException = 0.0;
double yException = 0.0;
double temp = 0.0;
for(int i=0;i<size;i++){
temp += Double.parseDouble(xList.get(i));
}
xAverage = temp/size; for(int i=0;i<size;i++){
temp += Double.parseDouble(yList.get(i));
}
yAverage = temp/size; for(int i=0;i<size;i++){
xException += Math.pow(Double.parseDouble(xList.get(i))-xAverage,2);
yException += Math.pow(Double.parseDouble(yList.get(i))-yAverage, 2);
}
//calculate denominator of
return standardDifference = Math.sqrt(xException*yException);
}
}
代码三:CallClass类
/**
*
*/
package numerator.pearson.conefficient; import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List; /**
* @author alan-king
*
*/
public class CallClass { public static void main(String[] args) throws IOException{
double CORR = 0.0;
List<String> xList = new ArrayList<String>();;
List<String> yList = new ArrayList<String>(); System.out.println("Please input your X's varieties and Y's varieties\r"+
"differnt line,then you should key into \"s\" to end the inputing operator!"); //initial varieties for xList,yList;
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str =null;
boolean flag = false;
while(!(str=br.readLine()).equals("s")){
String[] vStr = str.split(",");
int size = vStr.length;
if(flag == false){
for(int i=0;i<size;i++){
xList.add(i, vStr[i]);
}
flag = true;
}else if(flag == true){
for(int i=0;i<size;i++){
yList.add(i, vStr[i]);
}
flag = false;
} } NumeratorCalculate nc = new NumeratorCalculate(xList,yList);
double numerator = nc.calcuteNumerator();
DenominatorCalculate dc = new DenominatorCalculate();
double denominator = dc.calculateDenominator(xList, yList);
CORR = numerator/denominator;
System.out.println("We got the result by Calculating:");
System.out.printf("CORR = "+CORR);
}
}
四、输出结果:例如以下图

Pearson product-moment correlation coefficient in java(java的简单相关系数算法)的更多相关文章
- Java实现三大简单排序算法
一.选择排序 public static void main(String[] args) { int[] nums = {1,2,8,4,6,7,3,6,4,9}; for (int i=0; i& ...
- [Statistics] Comparison of Three Correlation Coefficient: Pearson, Kendall, Spearman
There are three popular metrics to measure the correlation between two random variables: Pearson's c ...
- 皮尔逊相关系数与余弦相似度(Pearson Correlation Coefficient & Cosine Similarity)
之前<皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)>一文介绍了皮尔逊相关系数.那么,皮尔逊相关系数(Pearson Corre ...
- 皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)
Pearson's r,称为皮尔逊相关系数(Pearson correlation coefficient),用来反映两个随机变量之间的线性相关程度. 用于总体(population)时记作ρ (rh ...
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- Java设计模式学习——简单工厂
一. 定义与类型 定义:有工程对象决定创建出哪一种产品类的实例 类型:创建型,但不属于GOF23中设计模式 二. 适用场景 工厂类负责创建的对象比较少 客户端(应用层)只知道传入工厂类的参数,对于如何 ...
- Java判断回文数算法简单实现
好久没写java的代码了, 今天闲来无事写段java的代码,算是为新的一年磨磨刀,开个头,算法是Java判断回文数算法简单实现,基本思想是利用字符串对应位置比较,如果所有可能位置都满足要求,则输入的是 ...
- Java中常用的查找算法——顺序查找和二分查找
Java中常用的查找算法——顺序查找和二分查找 神话丿小王子的博客 一.顺序查找: a) 原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数据最后一位 ...
- Java 异步处理简单实践
Java 异步处理简单实践 http://www.cnblogs.com/fangfan/p/4047932.html 同步与异步 通常同步意味着一个任务的某个处理过程会对多个线程在用串行化处理,而异 ...
随机推荐
- Python ORM
本章内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 多对多关系 表结构设计作业 ORM介绍 如果写程序用pymysql和程序交互,那是不是要写原生sql语句.如果 ...
- 学习boundingRectWithSize:options:attributes:context:计算文本尺寸
oundingRectWithSize:options:context: 返回文本绘制所占据的矩形空间. - (CGRect)boundingRectWithSize:(CGSize)size opt ...
- 深入了解SEO
为什么要SEO,SEO的作用是什么?SEO(Search Engine Optimization)是为了让自己的IT产品优先能被搜索引擎找到,通过搜索引擎搜索推荐给网民浏览(特点就是精准找到用户群体) ...
- 零基础学 HTML5+CSS3 全彩版 明日科技 编著
第1章 基础知识 1.1 HTML概述 1.1.1 什么是HTML 1.1.2 HTML的发展历程 1.2 HTML文件的基本结构 1.2.1 HTML的基本结构 1.2.2 HTML的基本标记 1. ...
- 算法理论——Linear SVM
问题引入 下面的三个超平面都起到分类的效果,哪个最好? 答案显然是第三个.为什么? 直觉上,如果现在我们有个测试点,非常靠近右下角的那个红叉叉,也就是说这个点的特征与那个红叉叉非常接近,这时候,我们希 ...
- poj2135最小费用最大流经典模板题
Farm Tour Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 13509 Accepted: 5125 Descri ...
- c/c++内存泄露的检测方法
此文内容摘自 https://zhuanlan.zhihu.com/p/22664202 作为 从零开始的 JSON 库教程(三):解析字符串解答篇 的笔记 1A. Windows 下的内存泄漏 ...
- P3919 (模板)可持久化数组 (主席树)
题目链接 Solution 主席树水题,连差分的部分都不需要用到. 直接用主席树的结构去存一下就好了. Code #include<bits/stdc++.h> #define mid ( ...
- 转载 关于malloc
1.函数原型及说明: void *malloc(long NumBytes):该函数分配了NumBytes个字节,并返回了指向这块内存的指针.如果分配失败,则返回一个空指针(NULL). 关于分配失败 ...
- Scrapy学习-20-数据收集
Scrapy的数据收集功能 定义 Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数值. 该机制叫做数据收集器(Stats Collector),可以通过 Craw ...