c++ concurrency serial 1: introduction
platform: vs2012
Code#include <iostream>
#include <thread>
using namespace std;
void Fun()
{
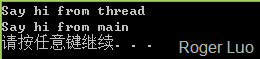
cout<<"Say hi from thread\n";
}
int main()
{
std::thread th(Fun);
cout<<"Say hi from main\n";
th.join();
return 0;
}

输出结果
使用C++11的lambda语法
#include <thread>
using namespace std;
int main()
{
std::thread th([](){
cout<<"Sai hi from thread\n";
});
cout<<"Say hi from main\n";
th.join();
return 0;
}
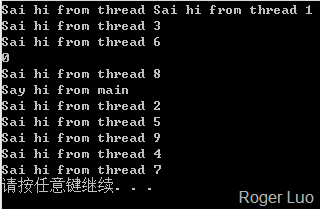
创建多个线程运行
#include <thread>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<thread> workers;
for (int i = 0; i < 10; ++i)
{
workers.push_back(std::thread([i](){
cout<<"Sai hi from thread "<<i<<endl;
}));
}
cout<<"Say hi from main\n";
for_each(workers.begin(), workers.end(), [](std::thread& th){
th.join();
});
return 0;
}
注意thread不具备copy constructor所以不能使用如下代码,否则会获取C2248错误
{
thread th([i](){
cout<<"Sai hi from thread "<<i<<endl;
});
workers.push_back(th);
}
只能使用move semantics或者称为rvalue reference
{
thread th([i](){
cout<<"Sai hi from thread "<<i<<endl;
});
workers.push_back(std::move(th));
}
#include <thread>
#include <vector>
#include <algorithm>
#include <cctype>
#include <string>
#include <iterator>
#include <ctime>
#include <functional>
using namespace std;
using namespace std::placeholders; // for _1, _2
#define LENGTH 10000
vector<int> doubleValues (vector<int>& v)
{
vector<int> new_values( v.size() );
for (vector<int>::iterator itr = v.begin(), end_itr = v .end(); itr != end_itr; ++itr )
{
new_values.push_back( 2 * *itr );
}
return new_values;
}
string upperString(const string& s)
{
string temp;
//temp.reserve(s.length());
std::transform(s.begin(), s.end(), std::back_inserter(temp), [](const int c){
return std::toupper(c);
});
return temp;
}
vector<string> upperStrings(const vector<string>& v)
{
vector<string> temp(v.size());
transform(v.begin(), v.end(), back_inserter(temp), std::bind(upperString, _1));
return temp;
}
vector<string> upperStringsR(const vector<string>& v)
{
vector<string> temp(v.size());
transform(v.begin(), v.end(), back_inserter(temp), move(std::bind(upperString, _1)));
return temp;
}
int main()
{
vector<string> in(LENGTH, "abc*def=ghi"); //cout<<"===Copy Sample==="<<endl;
//std::clock_t bgn = clock();
//vector<string> out = upperStrings(in);
//cout<<"Using "<<(clock() - bgn)<<" mini seconds"<<endl; //cout<<"===Move Semantics==="<<endl;
//bgn = clock();
//vector<string> out2 = move(upperStringsR(in));
//cout<<"Using "<<(clock() - bgn)<<" mini seconds"<<endl;
//copy(out2.begin(), out2.end(), ostream_iterator<string>(cout, "\n")); vector<int> v;
for ( int i = 0; i < LENGTH; i++ )
{
v.push_back( i );
}
cout<<"===Copy Sample==="<<endl;
std::clock_t bgn = clock();
v = doubleValues( v );
cout<<"Using "<<(clock() - bgn)<<" mini seconds"<<endl; cout<<"===Move Sample==="<<endl;
bgn = clock();
v = move(doubleValues( v ));
cout<<"Using "<<(clock() - bgn)<<" mini seconds"<<endl; return 0;
} //vector<thread> workers;
//for (int i = 0; i < 10; ++i)
//{
// thread th([i](){
// cout<<"Sai hi from thread "<<i<<endl;
// });
// workers.push_back(std::move(th));
//}
//cout<<"Say hi from main\n";
//for_each(workers.begin(), workers.end(), [](std::thread& th){
// th.join();
//});
#include <iostream>
#include <time.h>
#include <set>
#include <algorithm> const unsigned N = 3001; extern bool some_test; std::set<int>
get_set(int)
{
std::set<int> s;
for (int i = 0; i < N; ++i)
while (!s.insert(std::rand()).second)
;
if (some_test)
return s;
return std::set<int>();
} std::vector<std::set<int> >
generate()
{
std::vector<std::set<int> > v;
for (int i = 0; i < N; ++i)
v.push_back(get_set(i));
if (some_test)
return v;
return std::vector<std::set<int> >();
} float time_it()
{
clock_t t1, t2, t3, t4;
clock_t t0 = clock();
{
std::vector<std::set<int> > v = generate();
t1 = clock();
std::cout << "construction took " << (float)((t1 - t0)/(double)CLOCKS_PER_SEC) << std::endl;
std::sort(v.begin(), v.end());
t2 = clock();
std::cout << "sort took " << (float)((t2 - t1)/(double)CLOCKS_PER_SEC) << std::endl;
std::rotate(v.begin(), v.begin() + v.size()/2, v.end());
t3 = clock();
std::cout << "rotate took " << (float)((t3 - t2)/(double)CLOCKS_PER_SEC) << std::endl;
}
t4 = clock();
std::cout << "destruction took " << (float)((t4 - t3)/(double)CLOCKS_PER_SEC) << std::endl;
std::cout << "done" << std::endl;
return (float)((t4-t0)/(double)CLOCKS_PER_SEC);
} int main()
{
std::cout << "N = " << N << '\n';
float t = time_it();
std::cout << "Total time = " << t << '\n';
} bool some_test = true;
同一段代码在vs2012与gcc4.8.1中表现不一样
#include <iostream>
#include <thread>
#include <memory>
#include <vector>
#include <cassert>
#include <algorithm>
using namespace std;
void thFun(int &i)
{
cout<<"Hi from worker "<<i<<"!\n";
}
void Init(vector<thread> &workers)
{
for (int i = 0; i < 8; i++)
{
//auto th = std::thread(&thFun, std::ref(i));
auto th = std::thread(&thFun, std::ref(i));
workers.push_back(std::move(th));
assert(!th.joinable());
}
}
int main()
{
vector<thread> workers;
Init(workers); cout<<"Hi from main!\n"<<endl;
for_each(workers.begin(), workers.end(), [](std::thread&th){
assert(th.joinable());
th.join();
}); return 0;
}
前者是不管使用std::ref还是不使用都能编译通过且运行正确,后者是则必须使用std::ref才能编译通过,且运行不正确。
typedef std::vector<std::string> StringVector;
typedef StringVector::iterator StringVectorIter; enum EPackageNodeType
{
NodeUnKnown = 0,
NodeNew,
NodeDownloaded,
NodeFinished,
NodeFailed,
}; enum CapsuleAnalyzeResult
{
ANALYZE_OK = 0,
INVALID_FILTER,
INVALID_CLOSE,
OTHER_ERROR
}; struct ISATZipFile
{
trwfUInt64 Size; // compress size
trwfUInt8 Tries; // tries downloaad times
trwfUInt8 State; // donwload state
std::string Name; // name of rictable
std::string File; // full path
std::string URL; // full url
ISATZipFile(): Size(0), Tries(0), State(NodeUnKnown){}
}; //typedef std::vector<ISATZipFile*, Framework::MFAlloc<ISATZipFile*> > ISATPackageVector;
typedef std::vector<ISATZipFile*> ISATPackageVector;
typedef ISATPackageVector::iterator ISATPackageVecotrIter;
typedef ISATPackageVector* PISATPackageVector; inline void ReleaseISATPackageVector(ISATPackageVector& coll)
{
ISATPackageVecotrIter itEnd = coll.end();
for (ISATPackageVecotrIter itPos = coll.begin(); itPos != itEnd; itPos++)
{
if (*itPos)
{
delete (*itPos);
*itPos = nullptr;
}
}
coll.clear();
} inline void ReleaseISATPackageVector(PISATPackageVector& pcoll)
{
if (pcoll)
{
ReleaseISATPackageVector(*pcoll);
delete pcoll;
pcoll = nullptr;
}
} struct ISATIncrement
{
ISATPackageVector* Inserts;
ISATPackageVector* Deletes;
ISATPackageVector* Updates;
ISATPackageVector* AliasInserts;
ISATPackageVector* AliasDeletes;
ISATPackageVector* AliasUpdates;
ISATIncrement()
: Inserts(new ISATPackageVector)
, Deletes(new ISATPackageVector)
, Updates(new ISATPackageVector)
, AliasInserts(new ISATPackageVector)
, AliasDeletes(new ISATPackageVector)
, AliasUpdates(new ISATPackageVector)
{}
~ISATIncrement()
{
ReleaseISATPackageVector(Inserts);
ReleaseISATPackageVector(Deletes);
ReleaseISATPackageVector(Updates);
ReleaseISATPackageVector(AliasInserts);
ReleaseISATPackageVector(AliasDeletes);
ReleaseISATPackageVector(AliasUpdates);
}
};
//typedef std::vector<ISATIncrement*, Framework::MFAlloc<ISATIncrement*> > ISATIncrementBuilds;
typedef std::vector<ISATIncrement*> ISATIncrementBuilds;
typedef ISATIncrementBuilds::iterator ISATIncrementBuildsIter;
typedef ISATIncrementBuilds * PISATIncrementBuilds; inline void ReleaseISATIncrementBuilds(PISATIncrementBuilds pcoll)
{
BOOST_FOREACH(ISATIncrement*& elem, *pcoll)
{
if (elem->Inserts) ReleaseISATPackageVector(*(elem->Inserts));
if (elem->Deletes) ReleaseISATPackageVector(*(elem->Deletes));
if (elem->Updates) ReleaseISATPackageVector(*(elem->Updates));
if (elem->AliasInserts) ReleaseISATPackageVector(*(elem->AliasInserts));
if (elem->AliasDeletes) ReleaseISATPackageVector(*(elem->AliasDeletes));
if (elem->AliasUpdates) ReleaseISATPackageVector(*(elem->AliasUpdates));
}
} typedef struct _isatSummary
{
std::string strTimeStamp;
ISATPackageVector* Image;
ISATPackageVector* AliasImage;
ISATIncrementBuilds* Increments;
bool IsWeeklyBuild;
_isatSummary():IsWeeklyBuild(false), Image(new ISATPackageVector), AliasImage(new ISATPackageVector),Increments(new ISATIncrementBuilds){
Increments->reserve(7 * 24 * 60);
}
~_isatSummary(){
ReleaseISATPackageVector(Image);
ReleaseISATPackageVector(AliasImage);
if (Increments)
{
delete Increments;
Increments = nullptr;
}
}
} ISATSummary; #include "stdafx.h"
#include "SummaryParser.h"
#include <sstream>
#include <boost/regex.hpp>
#include <boost/foreach.hpp>
#include <boost/algorithm/string.hpp>
#include <ctime>
namespace IDH
{
CSummaryParser::CSummaryParser(void)
: m_iCurPos(0)
, m_iTotalIncrement(0)
, m_pszFileRoot(0)
, m_pszURLRoot(0)
{
m_Elements.reserve(400000);
} CSummaryParser::~CSummaryParser(void)
{
} int CSummaryParser::Parse(const char * pBuffer, const char * pszURLRoot, const char * pszFileRoot, ISATSummary* pSummary)
{
_ASSERT(pBuffer && pszURLRoot && pszFileRoot &&pSummary);
if (!pBuffer || !pszURLRoot || !pszFileRoot ||!pSummary) return 1; m_pszFileRoot = pszFileRoot;
m_pszURLRoot = pszURLRoot; if (0 != RetrieveElements(pBuffer))
{
cerr<<"Failed to retrieve elements from summary buffer."<<endl;
return 1;
} if (0 != ParseElements(pSummary))
{
cerr<<"Failed to parse elements from summary buffer."<<endl;
return 1;
} return 0;
} int CSummaryParser::RetrieveElements(const char * pBuffer)
{
_ASSERT(pBuffer);
PERFORMANCE_BEGIN
clock_t _bgn = clock();
static boost::regex rex("([^\\s=]*)", boost::regex::icase|boost::regex::perl); boost::cmatch what; boost::cregex_iterator itBgn = boost::make_regex_iterator(pBuffer, rex);
boost::cregex_iterator itEnd; m_Elements.clear();
m_iCurPos = 0;
m_iTotalIncrement = 0; for_each(itBgn, itEnd, [this](const boost::cmatch& what){
if (what[1].str().length() > 0)
this->m_Elements.push_back((what[1].str()));
}); BOOST_FOREACH(std::string& elem, m_Elements)
{
boost::trim(elem);
}
cout<<__FUNCTION__<<"using "<<clock()-_bgn<<" mini seconds"<<endl;
PERFORMANCE_END
return 0;
} int CSummaryParser::ParseElements(ISATSummary* pSummary)
{
int ret = 0;
PERFORMANCE_BEGIN
for (;m_iCurPos < m_Elements.size();)
{
if (boost::iequals(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_FULLBUILD) == true)
{
if (ParseFullBuildElement(*pSummary) != 0)
{
wcout<<L"Fail to parse [FullBuild]"<<endl;
ret = 1;
break;
}
}
else if (boost::iequals(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_TABLES) == true)
{
if (ParseTablesElement(*(pSummary->Image)) != 0)
{
wcout<<L"Fail to parse [Tables]"<<endl;
ret = 1;
break;
}
}
else if (boost::iequals(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_RAWALIASTABLES) == true)
{
if (ParseTablesElement(*(pSummary->AliasImage)) != 0)
{
wcout<<L"Fail to parse [RawAliasTables]"<<endl;
ret = 1;
break;
}
}
else if (boost::iequals(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_INCREMENTALBUILD) == true)
{
if (ParseIncrementalBuildElement(*pSummary) != 0)
{
wcout<<L"Fail to parse [IncrementalBuild]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_INCREMENTALBUILDEACH) == true)
{
if (ParseIncrementalBuildEachElement(*pSummary) != 0)
{
wcout<<L"Fail to parse [IncrementalBuild_Each]"<<endl;
ret = 1;
break;
}
}
else
{
cerr<<"Detect unknown node: "<<m_Elements[m_iCurPos]<<": at "<<m_iCurPos<<endl;
m_iCurPos++;
} }
PERFORMANCE_END
return ret;
} int CSummaryParser::ParseFullBuildElement(ISATSummary& full)
{
if (m_iCurPos + ISATGRABBERCONST::SUM_FULLBUILDLENGTH >= m_Elements.size())
return 1;
if (boost::iequals(m_Elements[++m_iCurPos], ISATGRABBERCONST::SUM_LATEST) == false)
return 1; if (full.strTimeStamp.compare(m_Elements[++m_iCurPos]) != 0)
{
// new full build
ReleaseISATPackageVector(*(full.Image));
ReleaseISATPackageVector(*(full.AliasImage));
ReleaseISATIncrementBuilds(full.Increments);
full.strTimeStamp = m_Elements[m_iCurPos];
full.IsWeeklyBuild = true;
} m_iCurPos++;
return 0;
} int CSummaryParser::ParseTablesElement(ISATPackageVector& coll)
{
if (m_iCurPos + ISATGRABBERCONST::SUM_TABLESLENGTH >= m_Elements.size())
return 1;
if (boost::iequals(m_Elements[++m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFTABLES) == false)
return 1;
int number = atoi(m_Elements[++m_iCurPos].c_str()); // get all tables
for (int i = 1; i <= number && m_iCurPos + ISATGRABBERCONST::SUM_GERNERICLENGTH < m_Elements.size(); i++)
{
int numFile = 0, numSize = 0;
numFile = atoi(m_Elements[++m_iCurPos].c_str() + strlen(ISATGRABBERCONST::SUM_TABLE));
std::string name = m_Elements[++m_iCurPos];
numSize = atoi(m_Elements[++m_iCurPos].c_str() + strlen(ISATGRABBERCONST::SUM_CMPSIZETABLE));
int size = atoi(m_Elements[++m_iCurPos].c_str());
if (numFile != numSize ||
numFile != i)
return 1;
ReplaceFileName(name, ISATGRABBERCONST::SUM_FILE_TXT, ISATGRABBERCONST::SUM_FILE_Z);
if (coll.size() < i)
{
ISATZipFile* ptable = new ISATZipFile;
ptable->State = NodeNew;
ptable->Name = name;
ptable->Size = size;
coll.push_back(ptable);
}
else
{
if (coll[i-1]->Size != size ||
boost::iequals(coll[i-1]->Name, name) == false)
{
}
}
}
m_iCurPos++;
return 0;
} int CSummaryParser::ParseIncrementalBuildElement(ISATSummary& full)
{
if (m_iCurPos + ISATGRABBERCONST::SUM_INCREMENTALBUILDLENGTH > m_Elements.size())
return 1;
if (boost::iequals(m_Elements[++m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFBUILDS) == false)
return 1; m_iTotalIncrement = atoi(m_Elements[++m_iCurPos].c_str());
m_iCurPos++;
return 0;
} int CSummaryParser::ParseIncrementalBuildEachElement(ISATSummary& full)
{
int iIncrementtalNumber = atoi(m_Elements[m_iCurPos].c_str() + strlen(ISATGRABBERCONST::SUM_INCREMENTALBUILDEACH));
if (iIncrementtalNumber > m_iTotalIncrement)
return 1;
if (iIncrementtalNumber > full.Increments->size())
full.Increments->push_back(new ISATIncrement());
while (++m_iCurPos < m_Elements.size() && m_Elements[m_iCurPos][0] != ISATGRABBERCONST::SUM_PREFIX_PATTERN)
{
if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFUPDATETABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_UPDATETABLE, ISATGRABBERCONST::SUM_CMPSIZEUPDATETABLE, (*(full.Increments))[iIncrementtalNumber-1]->Updates) != 0)
{
wcout<<L"Fail to parse [UPDATETABLE]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFADDTABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_ADDTABLE, ISATGRABBERCONST::SUM_CMPSIZEADDTABLE, (*(full.Increments))[iIncrementtalNumber-1]->Inserts) != 0)
{
wcout<<L"Fail to parse [ADDTABLE]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFDELETETABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_DELETETABLE, ISATGRABBERCONST::SUM_CMPSIZEDELETETABLE, (*(full.Increments))[iIncrementtalNumber-1]->Deletes) != 0)
{
wcout<<L"Fail to parse [DELETETABLE]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFRAWALIASUPDATETABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_RAWALIASUPDATETABLE, ISATGRABBERCONST::SUM_CMPSIZERAWALIASUPDATETABLE, (*(full.Increments))[iIncrementtalNumber-1]->AliasUpdates) != 0)
{
wcout<<L"Fail to parse [RAWALIASUPDATETABLE]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFRAWALIASADDTABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_RAWALIASADDTABLE, ISATGRABBERCONST::SUM_CMPSIZERAWALIASADDTABLE, (*(full.Increments))[iIncrementtalNumber-1]->AliasInserts) != 0)
{
wcout<<L"Fail to parse [RAWALIASADDTABLE]"<<endl;
return 1;
}
}
else if (boost::istarts_with(m_Elements[m_iCurPos], ISATGRABBERCONST::SUM_NUMBEROFRAWALIASDELETETABLES) == true)
{
if (ParseIncremental(ISATGRABBERCONST::SUM_RAWALIASDELETETABLE, ISATGRABBERCONST::SUM_CMPSIZERAWALIASDELETETABLE, (*(full.Increments))[iIncrementtalNumber-1]->AliasDeletes) != 0)
{
wcout<<L"Fail to parse [RAWALIASDELETETABLE]"<<endl;
return 1;
}
}
else
{
cerr<<"Invalide line:"<<m_Elements[m_iCurPos]<<endl;
}
}
return 0;
} int CSummaryParser::ParseIncremental(std::string namepattern, std::string sizepattern, PISATPackageVector& pcoll)
{
if (++m_iCurPos >= m_Elements.size())
return 1;
int number = atoi(m_Elements[m_iCurPos].c_str()); if (number == 0)
return 0; for (int i = 1; i <= number && m_iCurPos + ISATGRABBERCONST::SUM_GERNERICLENGTH < m_Elements.size(); i++)
{
int numFile = 0, numSize = 0;
numFile = atoi(m_Elements[++m_iCurPos].c_str() + namepattern.size());
std::string name = m_Elements[++m_iCurPos];
numSize = atoi(m_Elements[++m_iCurPos].c_str() + sizepattern.size());
int size = atoi(m_Elements[++m_iCurPos].c_str());
if (numFile != numSize ||
numFile != i)
return 1;
ReplaceFileName(name, ISATGRABBERCONST::SUM_FILE_TXT, ISATGRABBERCONST::SUM_FILE_Z);
if (pcoll->size() < i)
{
ISATZipFile * pnode = new ISATZipFile;
pnode->Name = name;
pnode->Size = size;
pnode->State = NodeNew;
pcoll->push_back(pnode);
}
else
{
if ((*pcoll)[i-1]->Size != size ||
boost::iequals((*pcoll)[i-1]->Name, name) == false)
return 1;
}
} return 0;
} void CSummaryParser::ReplaceFileName(std::string& inout, const std::string& s1, const std::string& s2)
{
boost::to_lower(inout);
size_t pos = inout.rfind(s1);
if (pos != std::string::npos)
inout.replace(pos, s1.length(), s2);
} int CSummaryParser::RetrieveElements2(string& buffer)
{
clock_t _bgn=clock();
m_Elements.clear();
list<boost::iterator_range<string::iterator> > l;
boost::split(l, buffer, boost::is_any_of("\n="), boost::token_compress_on);
for (auto pos = l.begin(); pos != l.end(); pos++)
{
m_Elements.push_back(string(pos->begin(), pos->end()));
}
cout<<__FUNCTION__<<"using "<<clock()-_bgn<<" mini seconds"<<endl;
return 0;
}
}
c++ concurrency serial 1: introduction的更多相关文章
- RFID 读写器 Reader Writer Cloner
RFID读写器的工作原理 RFID的数据采集以读写器为主导,RFID读写器是一种通过无线通信,实现对标签识别和内存数据的读出和写入操作的装置. 读写器又称为阅读器或读头(Reader).查询器(Int ...
- Java并发(一)并发编程的挑战
目录 一.上下文切换 1. 多线程一定快吗 2. 测试上下文切换次数和时长 3. 如何减少上下文切换 4. 减少上下文切换实战 二.死锁 三.资源限制的挑战 四.本章小结 并发编程的目的是为了让程序运 ...
- java(9)并发编程
整理自<java 并发编程的艺术> 1. 上下文切换 即使是单核处理器也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制.时间片是CPU分配给各个线程的时间,因为时间 ...
- 【java并发编程艺术学习】(二)第一章 java并发编程的挑战
章节介绍 主要介绍并发编程时间中可能遇到的问题,以及如何解决. 主要问题 1.上下文切换问题 时间片是cpu分配给每个线程的时间,时间片非常短. cpu通过时间片分配算法来循环执行任务,当前任务执行一 ...
- Introduction to Cortex Serial Wire Debugging
Serial Wire Debug (SWD) provides a debug port for severely pin limited packages, often the case for ...
- Java Concurrency In Practice - Chapter 1 Introduction
1.1. A (Very) Brief History of Concurrency motivating factors for multiple programs to execute simul ...
- [译]Introduction to Concurrency in Spring Boot
当我们使用springboot构建服务的时候需要处理并发.一种错误的观念认为由于使用了Servlets,它对于每个请求都分配一个线程来处理,所以就没有必要考虑并发.在这篇文章中,我将提供一些建议,用于 ...
- Introduction to Parallel Computing
Copied From:https://computing.llnl.gov/tutorials/parallel_comp/ Author: Blaise Barney, Lawrence Live ...
- Go Concurrency Patterns: Pipelines and cancellation
https://blog.golang.org/pipelines Go Concurrency Patterns: Pipelines and cancellation Sameer Ajmani1 ...
随机推荐
- 新线程 handler
class CalculateThread extends Thread { private Handler handler; @Override public void run() { super. ...
- 小米手机安装 charles 证书,提示“没有可安装的证书”
错误环境: 1. Mac 下的 charles 2. 小米手机(MI 6 MUI 9.6 ,Android 8.x) 错误提示: 安装 charles 证书时,提示“没有可安装的证书” 解决方法: 1 ...
- 反射的妙用-类名方法名做参数进行方法调用实例demo
首先声明一点,大家都会说反射的效率低下,但是大多数的框架能少了反射吗?当反射能为我们带来代码上的方便就可以用,如有不当之处还望大家指出 1,项目结构图如下所示:一个ClassLb类库项目,一个为测试用 ...
- 静态代码扫描工具使用教程 - SonarQube+SonarScanner
预置条件: Jdk已安装 Mysql已安装 1. 下载 SonarQube和Sonar scanner. SonarQube: http://www.sonarqube.org/downloads/ ...
- Flowerpot(单调队列)
描述 Farmer John has been having trouble making his plants grow, and needs your help to water them pro ...
- hdu图论题目分类
=============================以下是最小生成树+并查集====================================== [HDU] 1213 How Many ...
- 在Ubuntu中,用mvn打包hadoop源代码时报错,正在解决中!!!
报错信息如下: (各种配置在最后面) hadoop@administrator-virtual-machine:~/Downloads/tar/hadoop-3.0.0-alpha1-src$ mvn ...
- BZOJ-1036 [ZJOI2008]树的统计
树链剖分模版题. #include <cstdlib> #include <cstdio> #include <cstring> #include <algo ...
- cssText批量修改样式
cssText所有浏览器都支持. cssText 的使用 obj.style.cssText = " width:200px;position:absolute;left:100px;&qu ...
- 刷题总结——doing homework again(hdu1789)
题目: Problem Description Ignatius has just come back school from the 30th ACM/ICPC. Now he has a lot ...