第四期coding_group笔记_用CRF实现分词-词性标注
一、背景知识
1.1 什么是分词?
NLP的基础任务分为三个部分,词法分析、句法分析和语义分析,其中词法分析中有一种方法叫Tokenization,对汉字以字为单位进行处理叫做分词。
Example : 我 去 北 京
S S B E
注:S代表一个单独词,B代表一个词的开始,E表示一个词的结束(北京是一个词)。
1.2 什么是词性标注?
句法分析中有一种方法叫词性标注(pos tagging),词性标注的目标是使用类似PN、VB等的标签对句子(一连串的词或短语)进行打签。
Example : I can open this can .
Pos tagging -> PN MD VV PN NN PU
注:PN代词 MD情态动词 VV 动词 NN名词 PU标点符号
1.3 什么是分词-词性标注?
分词-词性标注就是将分词和词性标注两个任务同时进行,在一个模型里完成,可以减少错误传播。
Example : 我 去 北 京
S-PN S-VV B-NN E-NN
注:如果想理解更多关于nlp基础任务的知识,可参看我整理的张岳老师暑期班的第一天的笔记。
1.4 什么是CRF?
条件随机场(conditional random field)是一种用来标记和切分序列化数据的统计模型。在NLP领域可以用来做序列标注任务。
注:更多关于条件随机场的理论知识,可以参考以下内容:
条件随机场介绍(译)Introduction to Conditional Random Fields
二、CRF序列标注
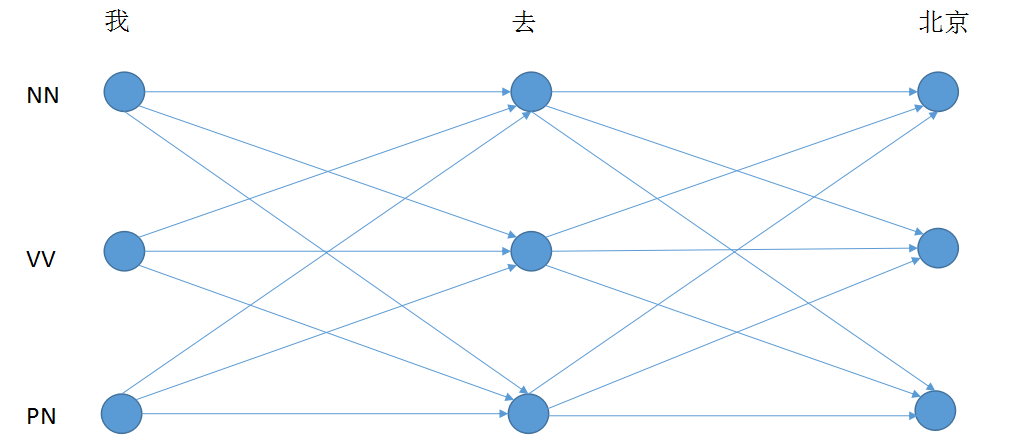
2.1 模型结构图
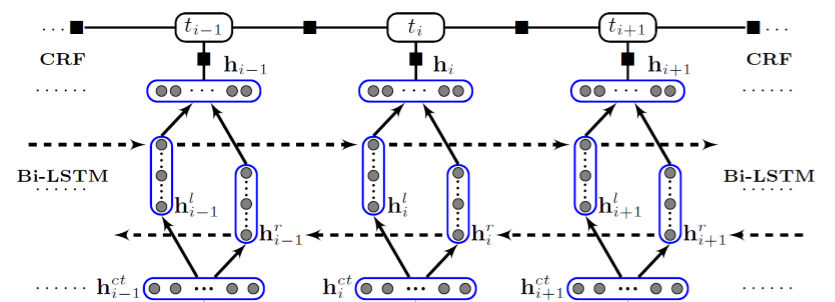
最底下的词向量层,上两层是Bi-LSTM层,最上面一层是CRF层。数据流程是从下层向上层计算。
2.2 CRF部分
2.2.1 理论
Point 1: 在CRF中,每个特征函数以下列信息作为输入,输出是一个实数值。
(1)一个句子s
(2)词在句子中的位置i
(3)当前词的标签
(4)前一个词的标签
注:通过限制特征只依赖于当前与之前词的标签,而不是句子中的任意标签,实际上是建立了一种特殊的线性CRF,而不是广义上的CRF。
Point 2: CRF的训练参数
(1)Input: x = {我,去,北京}
(2)Answer: ygold = {PN, VV, NN}
(3)y'是CRF标注的所有可能值,有3*3*3=27个;
(4)T矩阵存储转移分数,T[yiyi-1]是上个标签是的情况下,下个标签是yi的分数;
(5)hi是向量序列,通过神经网络Bi-LSTM得到,hi[yi]是被标成的发射分数;
(6)score(x,y)是模型对x被标注成y所打出的分数,是一个实数值;

Example : 我 去 北京
PN VV NN
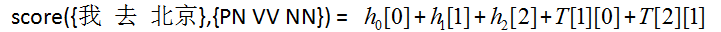
(7)P(ygold|x)是模型x对标注出ygold的概率;
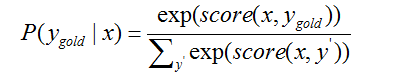
Point 3: CRF的训练目标:训练模型使得变大
Step 1: 对P(ygold|x)进行转化,取对数
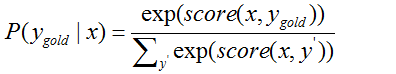
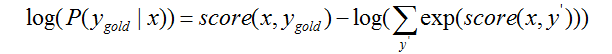
Step 2: 最终目标函数,使用梯度下降法
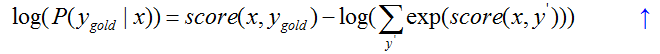

Step 3: 编程实现
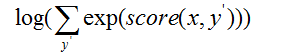
def _forward_alg(self, feats):
# do the forward algorithm to compute the partition function
init_alphas = torch.Tensor(1, self.labelSize).fill_(0)
# Wrap in a variable so that we will get automatic backprop
forward_var = autograd.Variable(init_alphas) # Iterate through the sentence
for idx in range(len(feats)):
feat = feats[idx]
alphas_t = [] # The forward variables at this timestep
for next_tag in range(self.labelSize):
# broadcast the emission score: it is the same regardless of the previous tag
if idx == 0:
alphas_t.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
# the ith entry of trans_score is the score of transitioning to next_tag from i
trans_score = self.T[next_tag]
# The ith entry of next_tag_var is the value for the edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the scores.
alphas_t.append(self.log_sum_exp(next_tag_var))
forward_var = torch.cat(alphas_t).view(1, -1)
alpha_score = self.log_sum_exp(forward_var)
return alpha_score
# Compute log sum exp in a numerically stable way for the forward algorithm
def log_sum_exp(self, vec):
max_score = vec[0, self.argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
def neg_log_likelihood(self, feats, tags):
forward_score = self._forward_alg(feats) # calculate denominator
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score # calculate loss
train()中的训练部分:
for iter in range(self.hyperParams.maxIter):
print('###Iteration' + str(iter) + "###")
random.shuffle(indexes)
for idx in range(len(trainExamples)):
# Step 1. Remember that Pytorch accumulates gradients. We need to clear them out before each instance
self.model.zero_grad()
# Step 2. Get our inputs ready for the network, that is, turn them into Variables of word indices.
self.model.LSTMHidden = self.model.init_hidden()
exam = trainExamples[indexes[idx]]
# Step 3. Run our forward pass. Compute the loss, gradients, and update the parameters by calling optimizer.step()
lstm_feats = self.model(exam.feat)
loss = self.model.crf.neg_log_likelihood(lstm_feats, exam.labelIndexs)
loss.backward()
optimizer.step()
if (idx + 1) % self.hyperParams.verboseIter == 0:
print('current: ', idx + 1, ", cost:", loss.data[0])
Point 4: 使用模型预测序列
使用维特比解码算法,解决篱笆图中的最短路径问题
step 1: 初始节点没有转移值
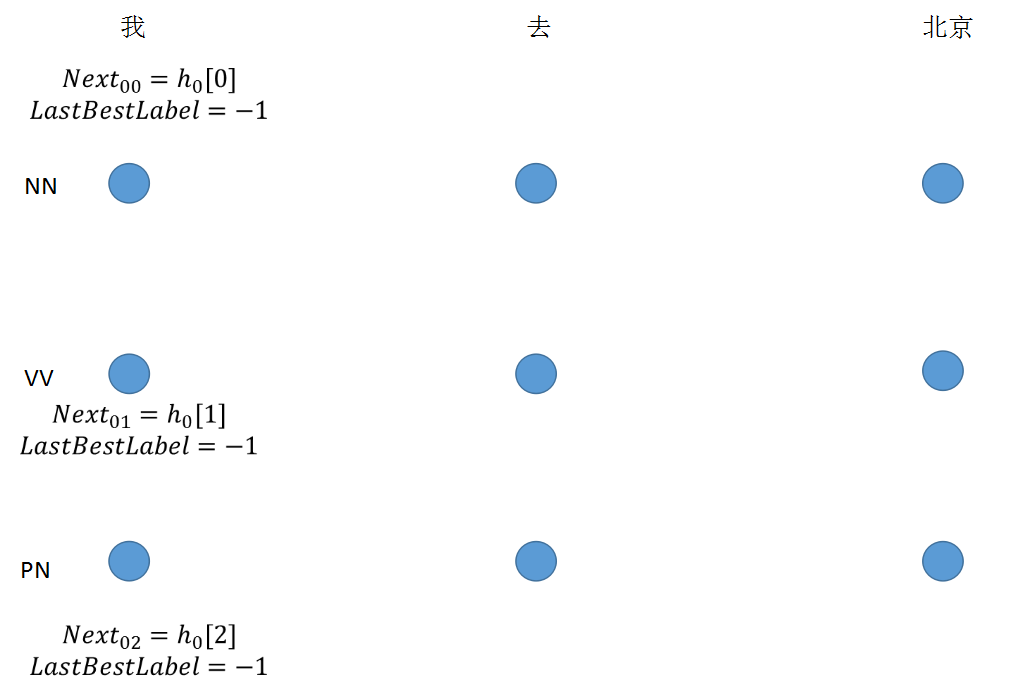
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
step 2: 节点值由三部分组成,最后求取最大值,得到lastbestlabel的下标
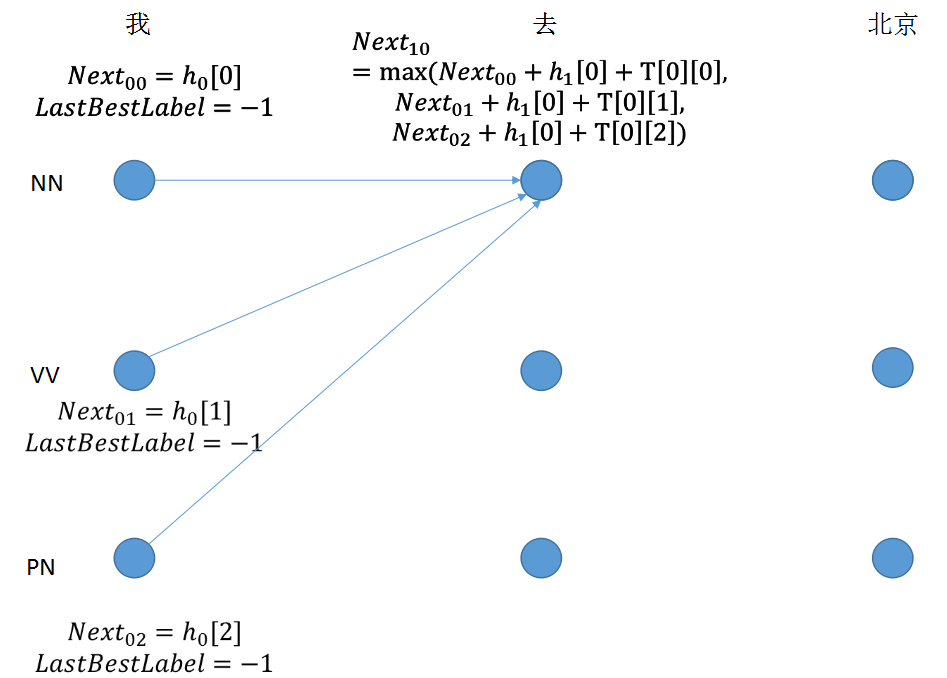
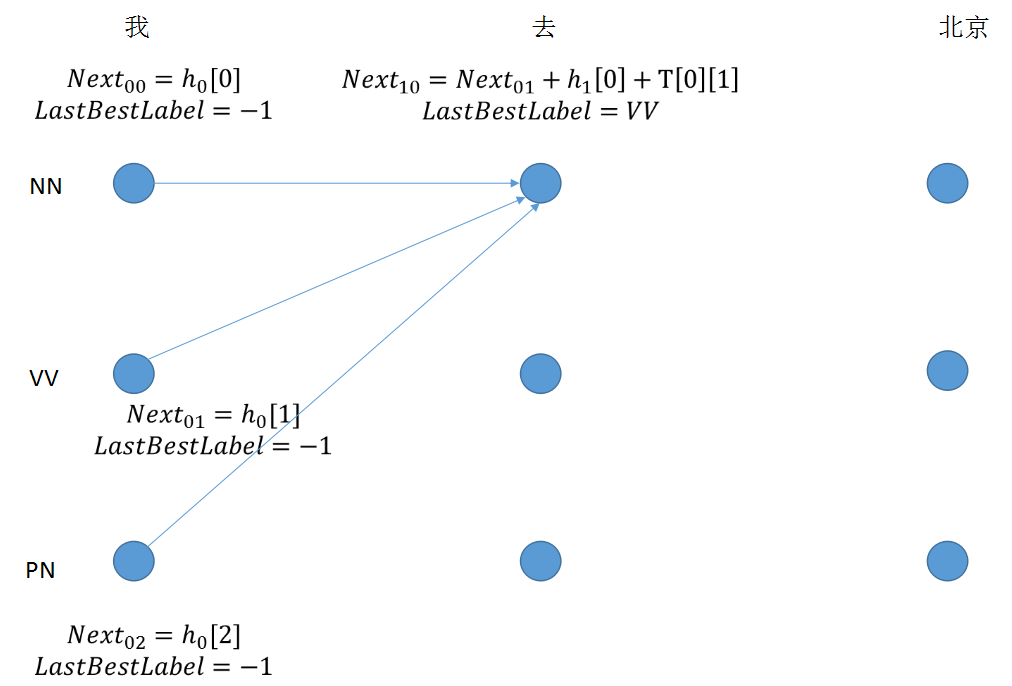
for next_tag in range(self.labelSize):
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
trans_score = self.T[next_tag]
next_tag_var = forward_var + trans_score + emit_score
best_label_id = self.argmax(next_tag_var)
bptrs_t.append(best_label_id)
viterbi_var.append(next_tag_var[0][best_label_id])
step 3: 计算出所有节点,比较最后一个词的值,求取最大值之后,向前推出最佳序列。
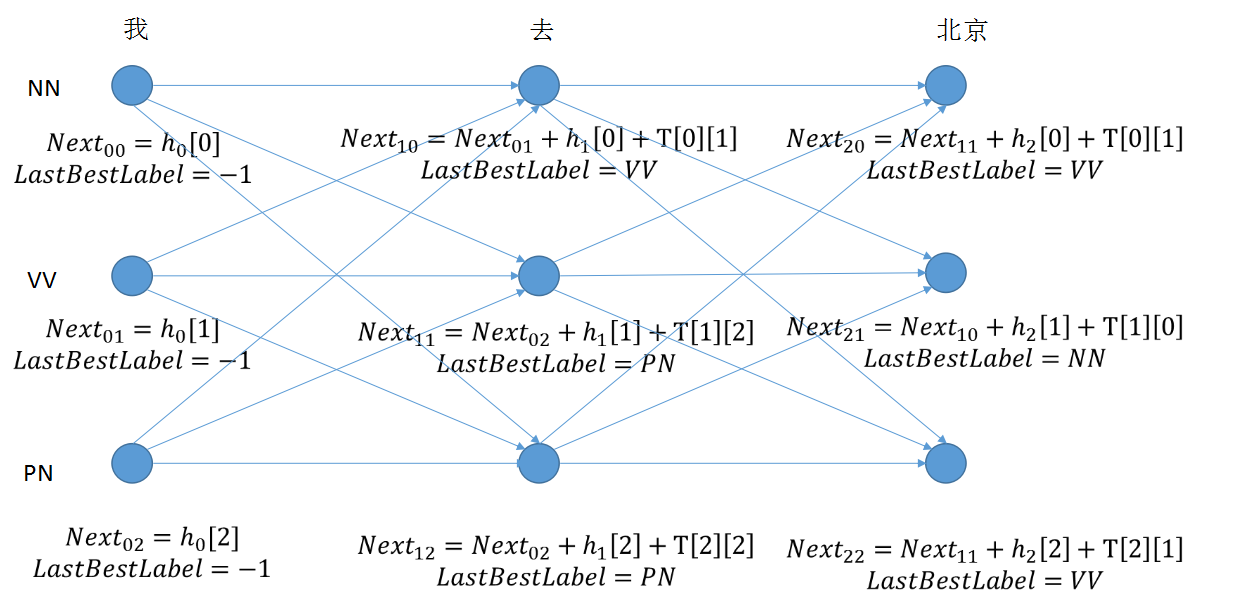

维特比解码算法实现预测序列
def _viterbi_decode(self, feats):
init_score = torch.Tensor(1, self.labelSize).fill_(0)
# forward_var at step i holds the viterbi variables for step i-1
forward_var = autograd.Variable(init_score)
back = []
for idx in range(len(feats)):
feat = feats[idx]
bptrs_t = [] # holds the backpointers for this step
viterbi_var = [] # holds the viterbi variables for this step
for next_tag in range(self.labelSize):
# next_tag_var[i] holds the viterbi variable for tag i at the previous step,
# plus the score of transitioning from tag i to next_tag.
# We don't include the emission scores here because the max does not
# depend on them (we add them in below)
if idx == 0:
viterbi_var.append(feat[next_tag].view(1, -1))
else:
emit_score = feat[next_tag].view(1, -1).expand(1, self.labelSize)
trans_score = self.T[next_tag]
next_tag_var = forward_var + trans_score + emit_score
best_label_id = self.argmax(next_tag_var)
bptrs_t.append(best_label_id)
viterbi_var.append(next_tag_var[0][best_label_id])
# Now add in the emission scores, and assign forward_var to the set of viterbi variables we just computed
forward_var = (torch.cat(viterbi_var)).view(1, -1)
if idx > 0:
back.append(bptrs_t)
best_label_id = self.argmax(forward_var)
# Follow the back pointers to decode the best path.
best_path = [best_label_id]
path_score = forward_var[0][best_label_id]
for bptrs_t in reversed(back):
best_label_id = bptrs_t[best_label_id]
best_path.append(best_label_id)
best_path.reverse()
return path_score, best_path
train()函数中的预测部分
# Check predictions after training
eval_dev = Eval()
for idx in range(len(devExamples)):
predictLabels = self.predict(devExamples[idx])
devInsts[idx].evalPRF(predictLabels, eval_dev)
print('Dev: ', end="")
eval_dev.getFscore() eval_test = Eval()
for idx in range(len(testExamples)):
predictLabels = self.predict(testExamples[idx])
testInsts[idx].evalPRF(predictLabels, eval_test)
print('Test: ', end="")
eval_test.getFscore()
def predict(self, exam):
tag_hiddens = self.model(exam.feat)
_, best_path = self.model.crf._viterbi_decode(tag_hiddens)
predictLabels = []
for idx in range(len(best_path)):
predictLabels.append(self.hyperParams.labelAlpha.from_id(best_path[idx]))
return predictLabels
Point 5 : 使用F1分数测量精度,最佳值为1,最差为0
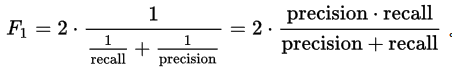
def getFscore(self):
if self.predict_num == 0:
self.precision = 0
else:
self.precision = self.correct_num / self.predict_num if self.gold_num == 0:
self.recall = 0
else:
self.recall = self.correct_num / self.gold_num if self.precision + self.recall == 0:
self.fscore = 0
else:
self.fscore = 2 * (self.precision * self.recall) / (self.precision + self.recall)
print("precision: ", self.precision, ", recall: ", self.recall, ", fscore: ", self.fscore)
注:全部代码和注释链接
扩展:可将数据中第二列和第一列一起放入Bi-LSTM中提取特征,这次只用到数据的第一列和第三列。
第四期coding_group笔记_用CRF实现分词-词性标注的更多相关文章
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- 《Linux内核设计与实现》课本第四章自学笔记——20135203齐岳
<Linux内核设计与实现>课本第四章自学笔记 进程调度 By20135203齐岳 4.1 多任务 多任务操作系统就是能同时并发的交互执行多个进程的操作系统.多任务操作系统使多个进程处于堵 ...
- 读经典——《CLR via C#》(Jeffrey Richter著) 笔记_发布者策略控制
在 读经典——<CLR via C#>(Jeffrey Richter著) 笔记_高级管理控制(配置)中,是由程序集的发布者将程序集的一个新版本发送给管理员,后者安装程序集,并手动编辑应用 ...
- 老男孩python3.5全栈开发第9期+课件笔记(1-15部全 共125天完整无加密)
点击了解更多Python课程>>> 老男孩python3.5全栈开发第9期+课件笔记(1-15部全 共125天完整无加密)大小:236G 此课程为老男孩全栈开发最新完结课程,适合零基 ...
- React笔记_(3)_react语法2
React笔记_(3)_react语法2 state和refs props就是在render渲染时,向组件内传递的变量,这个传递是单向的,只能继承下来读取. 如何进行双向传递呢? state (状态机 ...
- [置顶] CSDN博客第四期移动开发最佳博主评选
CSDN博客第三期最佳移动开发博主评选圆满结束,恭喜所有上榜用户,为继续展示移动开发方向优秀博主,发掘潜力新星,为移动开发方向的博客用户提供平台,CSDN博客第四期移动开发最佳博主评选开始.同时,获奖 ...
- 计算机爱好者协会技术贴markdown第四期
首先先让爱酱用CSDN自带的数学公式方法来闪瞎大家的钛合金狗眼: 有没有感觉到Markdown的强大!!!!! ## KaTeX数学公式 您可以使用渲染LaTeX数学表达式 [KaTeX](https ...
- 《Linux内核设计与实现》第四章学习笔记
<Linux内核设计与实现>第四章学习笔记 ——进程调度 姓名:王玮怡 学号:20135116 一.多任务 1.多任务操作系统的含义 多任务操作系统就是能同时并发地交 ...
- Linux内核分析第四章 读书笔记
Linux内核分析第四章 读书笔记 第一部分--进程调度 进程调度:操作系统规定下的进程选取模式 面临问题:多任务选择问题 多任务操作系统就是能同时并发地交互执行多个进程的操作系统,在单处理器机器上这 ...
随机推荐
- POJ:1330-Nearest Common Ancestors(LCA在线、离线、优化算法)
传送门:http://poj.org/problem?id=1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K ...
- JavaSE——Java对象导论
一.抽象过程 人们所能够解决问题的复杂性直接取决于抽象的类型和质量.所谓抽象的类型指的是抽象的是什么,汇编语言是对底层机器的轻微抽象,命令式语言(FORTRAN.BASIC.C)是对汇编语言的抽象.这 ...
- Ubuntu下安装anaconda和pycharm
折腾了一上午,终于装好了,如下:Python环境的安装: 安装anaconda 建议去https://www.anaconda.com/download/#linux直接用Ubuntu界面的搜狐浏览器 ...
- day05_04 数据类型-数值、布尔值、字符串简介
数据运算 数据类型初识 数字 整数 int(integer) 整型 长整型 在python3里面已经不区分整型和长整型了,统一都叫整型 在32位机器上,整数的位数为32位,取值范围为-2**31-2* ...
- php isset()与empty()详解
bool isset(mixed var);[;mixed var[,...]] 这个函数需要一个变量名称作为参数,如果这个变量存在,则返回true,否则返回false. 也可以传递一个由逗号间隔的变 ...
- csrf 攻击及防御
1.什么是CSRF攻击: CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:C ...
- Android内存使用——垃圾回收LOG,GC_CONCURRENT等的意义的说明
在调试程序的时候,经常发现GC_CONCURRENT之类的打印.在网上搜了一下,感觉说法各式各样.最后,在Google的官方网站上发现了详细介绍. Every time a garbage colle ...
- Struts has detected an unhandled exception异常
近期在写struts框架的时候会时不时的出现这个异常,多次实验以后发现,目前解决的方法只能通过重新部署项目再重新启动服务器解决,通常这个异常会出现在DMI即动态方法调用过程中.
- Linux Shell系列教程之(六)Shell数组
本文是Linux Shell系列教程的第(六)篇,更多shell教程请看:Linux Shell系列教程 Shell在编程方面非常强大,其数组功能也非常的完善,今天就为大家介绍下Shell数组的用法. ...
- 【bzoj2225】[Spoj 2371]Another Longest Increasing CDQ分治+树状数组
题目描述 给定N个数对(xi, yi),求最长上升子序列的长度.上升序列定义为{(xi, yi)}满足对i<j有xi<xj且yi<yj. 样例输入 8 1 3 3 2 1 1 4 5 ...