【转】Twitter-Snowflake,64位自增ID算法详解
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。
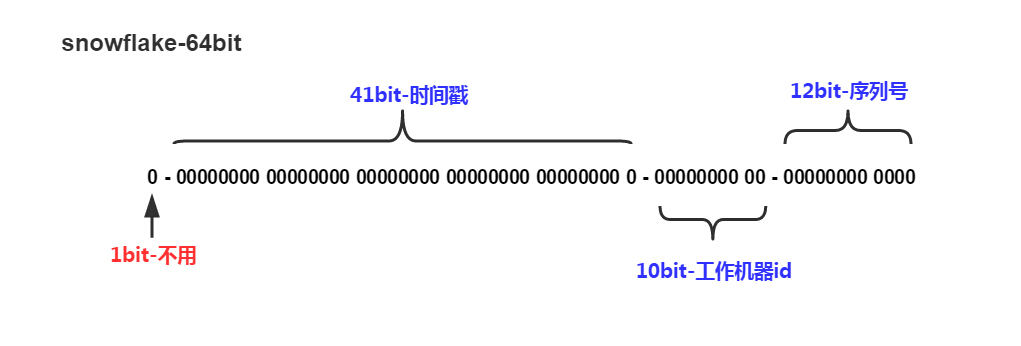
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
Snowflake – 时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
|
1
2
3
4
5
6
|
uint64_t generateStamp(){ timeval tv; gettimeofday(&tv, 0); return (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;} |
默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。如果你只给时间戳分配39个bit使用,那么根据同样的算法最后年份 = 17.4年。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
这里的解决方案是需要一个工作id分配的进程,可以使用自己编写一个简单进程来记录分配id,或者利用Mysql auto_increment机制也可以达到效果。

工作进程与工作id分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的id数据落文件,下一次启动直接读取文件里的id使用。
PS:这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记进程id,后5个bit标记线程id之类:D
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
|
1
2
3
4
5
6
7
8
|
uint64_t waitNextMs(uint64_t lastStamp){ uint64_t cur = 0; do { cur = generateStamp(); } while (cur <= lastStamp); return cur;} |
总体来说,是一个很高效很方便的GUID产生算法,一个int64_t字段就可以胜任,不像现在主流128bit的GUID算法,即使无法保证严格的id序列性,但是对于特定的业务,比如用做游戏服务器端的GUID产生会很方便。另外,在多线程的环境下,序列号使用atomic可以在代码实现上有效减少锁的密度。
参考资料:https://github.com/twitter/snowflake
(全文结束)
原文链接:http://www.lanindex.com/twitter-snowflake%EF%BC%8C64%E4%BD%8D%E8%87%AA%E5%A2%9Eid%E7%AE%97%E6%B3%95%E8%AF%A6%E8%A7%A3/
【转】Twitter-Snowflake,64位自增ID算法详解的更多相关文章
- Twitter-Snowflake,64位自增ID算法详解
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统 ...
- windows 64位下,React-Native环境搭建详解 (Android)
React-Native环境搭建需要: 1.安装Java JDK 2.安装Android Studio 3.安装node.js 4.安装git 5.安装Python 2.x (注意目前不支持Pytho ...
- DonkeyID---php扩展-64位自增ID生成器
##原理 参考Twitter-Snowflake 算法,扩展了其中的细节.具体组成如下图: 如图所示,64bits 咱们分成了4个部分. 毫秒级的时间戳,有42个bit.能够使用139年,从1970年 ...
- Twitter-Snowflake:自增ID算法
简介 Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,后来团队就研究如何产生完美的自增ID,以满足两个基本的要求: 每秒能生成几十万条 ID ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- 分布式自增ID算法-Snowflake详解
1.Snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并 ...
- 服务端捡起或丢弃指定物品ID触发详解
传奇服务端捡起或丢弃指定物品ID触发详解: @PickUpItemsX X是物品数据库中对应的IDX@DropItemsX X是物品数据库中对应的IDX@H.PickUpItemsX X是物品数据库中 ...
随机推荐
- 在TreeView控件节点中显示图片
实现效果: 知识运用: TreeView控件中Nodes集合的Add方法 //创建节点并将节点放入集合中 public virtual TreeNode Add (string key,string ...
- kubernetes-服务发现service(九)
service •防止Pod失联 •定义一组Pod的访问策略 •支持ClusterIP,NodePort以及LoadBalancer三种类型 •Service的底层实现主要有ipta ...
- vue学习之路 - 4.基本操作(下)
vue学习之路 - 4.基本操作(下) 简述:本章节主要介绍 vue 的一些其他常用指令. Vue 指令 这里将 vue 的指令分为系统内部指令(vue 自带指令)和用户自定义指令两种. 系统内部指令 ...
- Oracle10g安装过程中的Configuration Assistant配置失败的问题。
前几天安装Oracle的时候碰到了一个小问题,是在最后配置的时候,出现失败提示如下 失败提示:一些 Configuration Assistant 失败.强烈建议您此时重试这些 Configurati ...
- JS - 箭头函数与 () {} 的作用域
foo () { // ... } 等价于 foo: function () { // ... } foo: () => { // ... } 范例: // 全局 name = 'zhangsa ...
- (82)zabbix如何选择适合的监控类型
zabbix提供十几种监控类型,包括:Zabbix agent, Simple checks, SNMP, Zabbix internal, IPMI, JMX monitoring等等,那我们应该如 ...
- python 使用uuid 出现重复
同时保存入数据库时候 ,使用 uuid.uuid1() 后出现 重复的 id , 现在 修改为 (uuid.uuid5(uuid.NAMESPACE_DNS, str(uuid.uuid1()) ...
- 九、MySQL 创建数据表
MySQL 创建数据表 创建MySQL数据表需要以下信息: 表名 表字段名 定义每个表字段 语法 以下为创建MySQL数据表的SQL通用语法: CREATE TABLE table_name (col ...
- Install Jenkins 2.1.36 and openjdk 1.7.0 on centos 7
#!/bin/bash## Copyright (c) 2014-2015 Michael Dichirico (https://github.com/mdichirico)# This softwa ...
- pandas库Series类型与基本操作
pandas读取excel的类型是dataFrame,然后提取每一列是一个Series类型 Series类型包括index和values两部分 a = pd.Series({'a':1,'b':5}) ...