【spark core学习---算子总结(java版本) (第1部分)】
- map算子
- flatMap算子
- mapParitions算子
- filter算子
- mapParttionsWithIndex算子
- sample算子
- distinct算子
- groupByKey算子
- reduceByKey算子
1、map算子
(1)任何类型的RDD都可以调用map算子;在java中,map算子接收的参数是Function对象,在Function中,需要设置第二个泛型类型为返回的新元素的类型;同时,call()方法的返回类型也需要与第二个泛型的返回类型一致。在call()方法中,对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素,所有新的元素组成一个新的RDD。
(2)map十分容易理解,他是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的JavaRDD。
举例:
package map.xls; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction; import java.util.Arrays;
import java.util.List; public class TransFormation_Map { public static void main(String[] args) {
// 例1:map算子案例,将集合中每一个元素都乘以2
map1(); // 例2:map算子案例,将集合中每一个元素进行累加
map2();
}
/*
* 我们可以通过2种方式创建RDD,一种方式是直接读取外部数据(比较常用),另一种是在驱动程序中分发驱动器中的对象集合(list或set),一般在调试中会使用
* */ public static void map1(){ //创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local"); //创建javaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); //构建集合
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); //并行化集合,parallelize对集合进行并行化处理(如果是在集群中,则会将list分配到集群的各个节点上),创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); //使用map算子,将集合中每个元素都乘以2 //map算子,是对于任何类型的RDD,都可以调用的
//在java中,map算子接收的参数是Function对象
//创建的function对象,一定会让你设置第二个泛型,这个泛型类型,并返回一个新的元素
//所有新的元素就会组成一个新的RDD JavaRDD<Integer> rdd = numberRDD.map(new Function<Integer, Integer>() {
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
}); rdd.foreach(new VoidFunction<Integer>() { public void call(Integer t) throws Exception {
System.out.println(t);
}
}); //关闭资源
sc.close(); }
public static void map2(){
// 创建sparkConf
SparkConf conf = new SparkConf().setAppName("map2").setMaster("local"); // 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 要通过并行化集合的方式创建RDD,就要调用sparkContext及其子类的parallelize()方法
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 执行reduce算子
// 相等于先进行1+2=3,然后再进行3+3=6...
int sum = numberRDD.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
}); // 输出累加和
System.out.println("1到10的累加和为:" + sum);
} }
2、flatMap算子
1、Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
flatMap类似于map,但是每一个输出元素可以被映射成0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
2、map是对RDD中元素逐一进行函数操作映射为另外一个RDD,而flatMap操作是将函数应用于RDD之中的每一个元素,将返回的迭代器的所有内容构成新的RDD。
flatMap与map区别在于map为“映射”,而flatMap“先映射,后扁平化”,map对每一次(func)都产生一个元素,返回一个对象,而flatMap多一步就是将所有对象合并为一个对象。
举例:
public static void main(String agrs[]){
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
int[] array=new int[]{1,2,3,4,5,6,7,8,9};
List<Integer> list=new ArrayList<Integer>();
for (Integer i : array) {
list.add(i);
}
JavaRDD<Integer> rdd=sc.parallelize(list,2);
//flatMap和map一样是一个一个的传,但是他可以在每一个传入的值新增多个参数
//list add方法:在指定位置插入元素,后面的元素都往后移一个元素。
JavaRDD<Integer> result=rdd.flatMap(new FlatMapFunction<Integer, Integer>() {
public java.util.Iterator<Integer> call(Integer t) throws Exception {
List<Integer> list = new ArrayList<Integer>();
for(int i = 0; i < t; i++){
list.add(t + i);
}
return list.iterator(); //返回的这个list就是传入的元素及新增的内容
}
});
System.out.println(result.collect());
}
输出结果:
[1, 2, 3, 3, 4, 5, 4, 5, 6, 7, 5, 6, 7, 8, 9, 6, 7, 8, 9, 10, 11, 7, 8, 9, 10, 11, 12, 13, 8, 9, 10, 11, 12, 13, 14, 15, 9, 10, 11, 12, 13, 14, 15, 16, 17]
3、mapParitions算子
(1)mapPartitions类似于map,但是独立的在RDD的每一个分片上运行,假设有N个元素,有M个分区,那么使用map将被调用N次,而mapPartitions被调用M次,即一次处理一个分区。
(2)
举例:
4、filter算子
(1)Return a new RDD containing only the elements that satisfy a predicate.返回一个新的过滤后的RDD,过滤规则:只返回条件为true的数据。
(2)函数原型:public JavaPairRDD<K,V> filter(Function<scala.Tuple2<K,V>,Boolean> f)
private static void filter01() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 模拟集合
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers);
// 对初始RDD执行filter算子,过滤出其中的偶数
JavaRDD<Integer> evenNumberRDD = numberRDD.filter(new Function<Integer, Boolean>() {
private static final long serialVersionUID = 1L;
//偶数会保留下来,放在新的RDD中
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
// 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() {
private static final long serialVersionUID = 1L;
public void call(Integer t) throws Exception {
System.out.println(t);
}
});
// 关闭JavaSparkContext
sc.close();
}
5、
6、
7、sample算子
1、JavaPairRDD<K,V> sample(boolean withReplacement,double fraction)
JavaPairRDD<K,V> sample(boolean withReplacement,double fraction,long seed)
2、sample算子可以对RDD进行抽样,其中参数withReplacement为true时表示抽样之后还放回,可以被多次抽样,false表示不放回;
fraction表示抽样比例;seed为随机数种子,比如当前时间戳。
3、sample应用的场景:在数据倾斜的时候,我们那么多数据如果想知道那个key倾斜了,就需要我们采样获取这些key,如果这些key数据不是很重要的话,可以过滤掉,这样就解决了数据倾斜。
例子:
package mapPartitions.xls; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext; import java.util.ArrayList;
import java.util.List; public class TransFormation07_sample {
public static void main(String args[]) {
sample01();
} public static void sample01(){ SparkConf conf = new SparkConf().setAppName("TransFormation04_flatMap").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); List<Integer> list=new ArrayList<Integer>(); for(int i = 1;i <= 100;i++){
list.add(i);
}
JavaRDD<Integer> any = sc.parallelize(list); //sample用来从RDD中抽取样本。他有三个参数
//withReplacement:表示样本是否放回 true放回
//fraction:抽取样本的比例
//seed:随机数生成种子
//由于样本的抽取其实是以一个固定的算法实现的,所以要达到随机抽样需用随机数生成seed JavaRDD<Integer> sample = any.sample(true, 0.1, 0);
System.out.println("seed=0:" + sample.collect());
sample = any.sample(true, 0.1, 0);
System.out.println("seed=0:"+ sample.collect()); //由于seed相同,所以抽出样本是相同的 //这里使用系统时间作为seed,发现抽出的样本是随机的
JavaRDD<Integer> sample1 = any.sample(true, 0.1, System.currentTimeMillis());
System.out.println("seed随机生成1" + sample1.collect());
sample1=any.sample(true, 0.1, System.currentTimeMillis());
System.out.println("seed随机生成2" + sample1.collect());
}
}
输出结果:
seed=0:[10, 23, 25, 35, 50, 68, 69, 79, 79, 85, 91, 91]
seed=0:[10, 23, 25, 35, 50, 68, 69, 79, 79, 85, 91, 91]
seed随机生成1[13, 28, 45, 46, 57, 63, 68, 92]
seed随机生成2[3, 9, 48, 57, 64, 65, 71, 86, 88, 92]
8、distinct算子
1、Return a new RDD containing the distinct elements in this RDD. 返回去重的一个新的RDD
2、public JavaPairRDD<K,V> distinct(); public JavaPairRDD<K,V> distinct(int numPartitions)
3、Distinct的操作其实是把原RDD进行MAP操作,根据原来的KEY-VALUE生成为KEY,value使用null来替换,并对新生成的RDD执行reduceByKey的操作,这个reduceByKey的操作中,传入的x,y都是null,这个地方执行reduceByKey的函数执行完成reducebykey的操作后,这个时候新的RDD就只相同的key就只包含一个结果值(其实就是一个null),最后执行下map操作,这个操作返回的是RDD的第一个值,第一个值就是原始rdd的key-value.执行reduceByKey操作的默认的分区算子是Hash.这个功能在执行时也需要做shuffle的操作.也就是说,Distinct的操作是根据key与value一起计算不重复的结果.只有两个记录中key与value都不重复才算是不重复的数据。
4、distinct不改变分区数,但是分区的数据会去重后改变,不是单独去重。而且参数numPartitions指定多少分区,就会生成多少分区。有可能会返回空数据的分区。
例子:
public static void distinct02(){
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("TransFormation08_distinct");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> javaPairRDD1 = sc.parallelizePairs(Lists.newArrayList(
new Tuple2<String, String>("cat", "11"),
new Tuple2<String, String>("dog", "22"),
new Tuple2<String, String>("cat", "11"),
new Tuple2<String, String>("pig", "44"),
new Tuple2<String, String>("duck", "55"),
new Tuple2<String, String>("cat", "11"),
new Tuple2<String, String>("cat", "12"),
new Tuple2<String, String>("dog", "23"),
new Tuple2<String, String>("cat", "11"),
new Tuple2<String, String>("pig", "22"),
new Tuple2<String, String>("duck", "55"),
new Tuple2<String, String>("cat", "15")), 2);
// 先输出一次创建的Tuple2
javaPairRDD1.foreach(new VoidFunction<Tuple2<String, String>>() {
public void call(Tuple2<String, String> stringStringTuple2) throws Exception {
System.out.println(stringStringTuple2);
}
});
// 去重操作
JavaPairRDD<String,String> javaPairRDD = javaPairRDD1.distinct();
// 输出去重后的结果
javaPairRDD.foreach(new VoidFunction<Tuple2<String, String>>() {
public void call(Tuple2<String, String> stringStringTuple2) throws Exception {
System.out.println(stringStringTuple2);
}
});
// 输出分区数---验证去重是否影响分区
System.out.println("分区的个数:"+javaPairRDD.partitions().size());
// 验证带有numPartitions参数的distinct
JavaPairRDD<String,String> javaPairRDD2 = javaPairRDD1.distinct(3);
javaPairRDD2.foreach(new VoidFunction<Tuple2<String, String>>() {
public void call(Tuple2<String, String> stringStringTuple2) throws Exception {
System.out.println("-->"+stringStringTuple2);
}
});
// 输出分区数
System.out.println("分区的个数:"+javaPairRDD2.partitions().size());
}
输出结果:
(cat,11)
(dog,22)
(cat,11)
(pig,44)
(duck,55)
(cat,11)
(cat,12)
(dog,23)
(cat,11)
(pig,22)
(duck,55)
(cat,15)
(cat,15)
(cat,12)
(cat,11)
(pig,22)
(pig,44)
(dog,23)
(dog,22)
(duck,55)
分区的个数:2
-->(cat,15)
-->(dog,22)
-->(duck,55)
-->(pig,22)
-->(pig,44)
-->(dog,23)
-->(cat,12)
-->(cat,11)
分区的个数:3
9、groupByKey
package mapPartitions.xls; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2; import java.util.Arrays;
import java.util.Iterator;
import java.util.List; public class TransFormation22_groupByKey {
public static void main(String args[]) {
groupByKey01();
} public static void groupByKey01(){
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("groupByKey").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", 80),
new Tuple2<String, Integer>("class2", 75),
new Tuple2<String, Integer>("class1", 90),
new Tuple2<String, Integer>("class2", 65),
new Tuple2<String, Integer>("class3", 55),
new Tuple2<String, Integer>("class3", 65),
new Tuple2<String, Integer>("class4", 75),
new Tuple2<String, Integer>("class5", 95)); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey(); // 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { private static final long serialVersionUID = 1L; public void call(Tuple2<String, Iterable<Integer>> t) throws Exception { System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
}
}); // 关闭JavaSparkContext
sc.close();
}
}
输出结果:
class: class5
95
==============================
class: class3
55
65
==============================
class: class1
80
90
==============================
class: class4
75
==============================
class: class2
75
65
==============================
10、groupByKey算子
/**
* reduceByKey案例:统计每个班级的总分
*/
private static void reduceByKey() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("reduceByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", 80),
new Tuple2<String, Integer>("class2", 75),
new Tuple2<String, Integer>("class1", 90),
new Tuple2<String, Integer>("class2", 65)); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行reduceByKey算子
JavaPairRDD<String, Integer> totalScores = scores.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
} }); // 打印totalScores RDD
totalScores.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
} }); // 关闭JavaSparkContext
sc.close();
}
总结groupByKey和reduceByKey的区别:
当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下: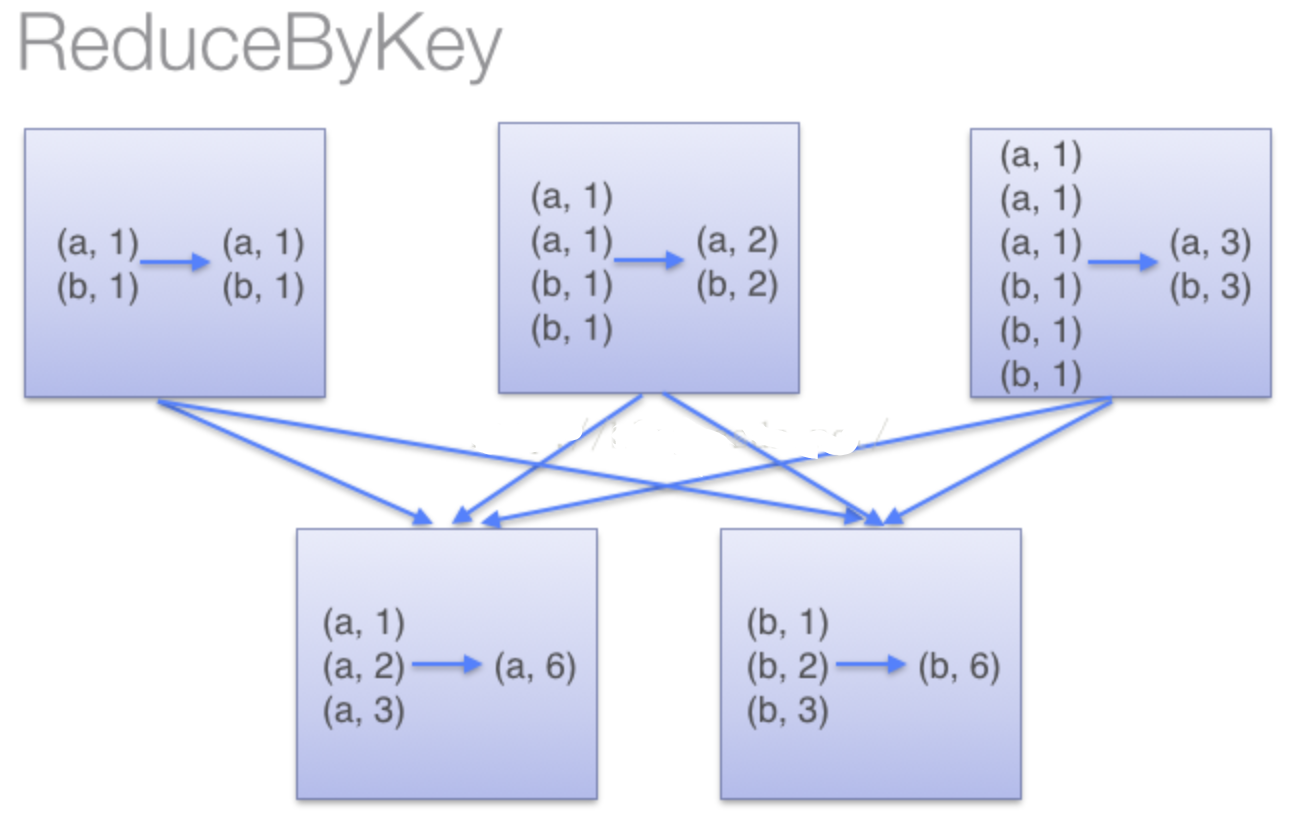
(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
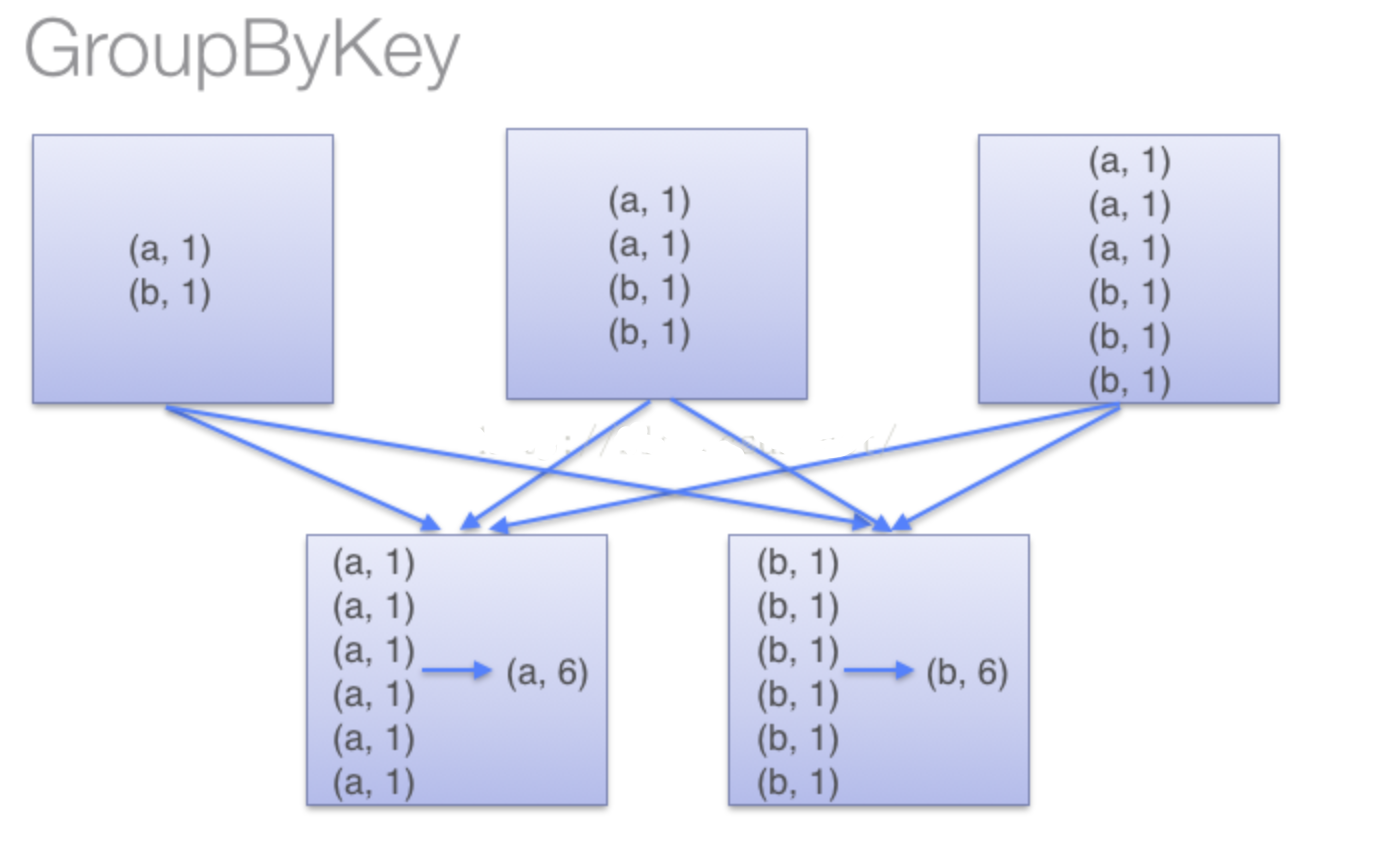
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
【spark core学习---算子总结(java版本) (第1部分)】的更多相关文章
- 31天重构学习笔记(java版本)
准备下周分享会的内容,无意间看到.net版本的重构31天,花了两个小时看了下,可以看成是Martin Fowler<重构>的精简版 原文地址:http://www.lostechies.c ...
- Java版本和功能指南
您可以使用本指南查找和安装最新的Java,了解Java发行版(AdoptOpenJdk,OpenJDK,OracleJDK等)之间的差异,以及获得Java语言功能的概述,包括Java版本8-13. J ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark的Straggler深入学习(1):如何在本地图形监控远程Spark的GC情况——使用java自带的jvisualvm
一.本文的目的 Straggler是目前研究的热点,Spark中也存在Straggler的问题.GC问题是总所周知的导致Straggler的重要因素之一,为了了解GC导致的Straggle ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- [学习日志]2018-11-18 主要: idea更改java版本
idea更改java版本 问题: 解决办法:
- 【Spark深入学习 -14】Spark应用经验与程序调优
----本节内容------- 1.遗留问题解答 2.Spark调优初体验 2.1 利用WebUI分析程序瓶颈 2.2 设置合适的资源 2.3 调整任务的并发度 2.4 修改存储格式 3.Spark调 ...
随机推荐
- 【转载】C#使用Except方法求取两个List集合的差集数据
在C#语言的编程开发中,针对List集合的运算有时候需要计算两个List集合的差集数据,集合的差集是取在该集合中而不在另一集合中的所有的项.A集合针对B集合的差集数据指的是所有在A集合但不在B集合的元 ...
- alt和title的区别
alt是html标签的属性,而title既是html标签,又是html属性. 在图像标签img中,除了常用的宽度width和高度height属性之外,还有两个比较重要并且也会用到的属性,就是alt和t ...
- 四:MySQL系列之Python交互(四)
该篇主要介绍MySQL数据库的分表.以及与Python的交互的基本操作等. 一.拆分表操作 1.1 准备工作 创建数据库 --> 使用数据库 --> 创建数据表 --- 添加记录 -- ...
- JS在浏览器中输出各种三角形
直角三角形 <script type="text/javascript"> for(var i=1;i<=8;i++){ for(var j=1;j<=i; ...
- zabbix 3.2.2 server web展示如何显示中文 (三)
1.确认zabbix是否开启了中文支持功能(/var/www/html/zabbix/include/locales.inc.php) 2.登录zabbix后,点击可爱的小公主吧 Admin(zabb ...
- javascript reduce 前端交互 总计
sum(){ return this.products.reduce((total,next)=>{ return total + next.price * next.aumout},0) } ...
- 【转】Lombok Pojo默认初始值问题
Lombok以注解形式来简化java代码,提高开发效率.比如我们常用的@Builder.@Data.@AllArgsConstructor.@NoArgsConstructor.@ToString等. ...
- JVM学习总结
JVM指令执行流程架构图:
- 【记忆化搜索】[NOIP-2017--普及组] -- 棋盘
[题目描述] 原题目链接地址: 有一个m × m的棋盘,棋盘上每一个格子可能是红色.黄色或没有任何颜色的.你现在要从棋盘的最左上角走到棋盘的最右下角. 任何一个时刻,你所站在的位置必须是有颜色的( ...
- Mac系统上,Firefox和Selenium不兼容的情况
解决办法,检查环境: Python 2.7.10 Firefox 46版本 Selenium 2.53.6 注意:将Firefox自动更新关闭,否则可能会出现自动升级以后无法执行Selenium用例的 ...