python操作MySQL数据库的三个模块
python使用MySQL主要有两个模块,pymysql(MySQLdb)和SQLAchemy。
pymysql(MySQLdb)为原生模块,直接执行sql语句,其中pymysql模块支持python 2和python3,MySQLdb只支持python2,两者使用起来几乎一样。
SQLAchemy为一个ORM框架,将数据对象转换成SQL,然后使用数据API执行SQL并获取执行结果
另外DBUtils模块提供了一个数据库连接池,方便多线程场景中python操作数据库。
1.pymysql模块
安装:pip install pymysql
创建表格操作: (注意中文格式设置)
#coding:utf-
import pymysql #关于中文问题
#. mysql命令行创建数据库,设置编码为gbk:create databse demo2 character set utf8;
#. python代码中连接时设置charset="gbk"
#. 创建表格时设置default charset=utf8 #连接数据库
conn = pymysql.connect(host="localhost", user="root", passwd="", db='learningsql', charset='utf8', port=) #和mysql服务端设置格式一样(还可设置为gbk, gb2312)
#创建游标
cursor = conn.cursor()
#执行sql语句
cursor.execute("""create table if not exists t_sales(
id int primary key auto_increment not null,
nickName varchar() not null,
color varchar() not null,
size varchar() not null,
comment text not null,
saledate varchar() not null)engine=InnoDB default charset=utf8;""") # cursor.execute("""insert into t_sales(nickName,color,size,comment,saledate)
# values('%s','%s','%s','%s','%s');""" % ("zack", "黑色", "L", "大小合适", "--")) cursor.execute("""insert into t_sales(nickName,color,size,comment,saledate)
values(%s,%s,%s,%s,%s);""" , ("zack", "黑色", "L", "大小合适", "--"))
#提交
conn.commit()
#关闭游标
cursor.close()
#关闭连接
conn.close()
创建表格操作
增删改查:
注意execute执行sql语句参数的两种情况:
execute( "insert into t_sales(nickName, size) values('%s','%s');" % ("zack","L") ) #此时的%s为字符窜拼接占位符,需要引号加'%s' (有sql注入风险)
execute( "insert into t_sales(nickName, size) values(%s,%s);" , ("zack","L") ) #此时的%s为sql语句占位符,不需要引号%s
#***************************增删改查******************************************************
conn = pymysql.connect(host="localhost", user="root", passwd="", db='learningsql', charset='utf8', port=) #和mysql服务端设置格式一样(还可设置为gbk, gb2312)
#创建游标
cursor = conn.cursor() insert_sql = "insert into t_sales(nickName,color,size,comment,saledate) values(%s,%s,%s,%s,%s);"
#返回受影响的行数
row1 = cursor.execute(insert_sql,("Bob", "黑色", "XL", "便宜实惠", "2019-04-20")) update_sql = "update t_sales set color='白色' where id=%s;"
#返回受影响的行数
row2 = cursor.execute(update_sql,(,)) select_sql = "select * from t_sales where id>%s;"
#返回受影响的行数
row3 = cursor.execute(select_sql,(,)) delete_sql = "delete from t_sales where id=%s;"
#返回受影响的行数
row4 = cursor.execute(delete_sql,(,)) #提交,不然无法保存新建或者修改的数据(增删改得提交)
conn.commit()
cursor.close()
conn.close()
增删改查语句
批量插入和自增id:
#***************************批量插入******************************************************
conn = pymysql.connect(host="localhost", user="root", passwd="", db='learningsql', charset='utf8', port=) #和mysql服务端设置格式一样(还可设置为gbk, gb2312)
#创建游标
cursor = conn.cursor() insert_sql = "insert into t_sales(nickName,color,size,comment,saledate) values(%s,%s,%s,%s,%s);"
data = [("Bob", "黑色", "XL", "便宜实惠", "2019-04-20"),("Ted", "黄色", "M", "便宜实惠", "2019-04-20"),("Gary", "黑色", "M", "穿着舒服", "2019-04-20")]
row1 = cursor.executemany(insert_sql, data) conn.commit()
#为插入的第一条数据的id,即插入的为5,,,new_id=
new_id = cursor.lastrowid
print(new_id)
cursor.close()
conn.close()
批量插入
获取查询数据:
#***************************获取查找sql的查询数据******************************************************
conn = pymysql.connect(host="localhost", user="root", passwd="", db='learningsql', charset='utf8', port=) #和mysql服务端设置格式一样(还可设置为gbk, gb2312)
#创建游标
cursor = conn.cursor() select_sql = "select id,nickname,size from t_sales where id>%s;"
cursor.execute(select_sql, (,)) row1 = cursor.fetchone() #获取第一条数据,获取后游标会向下移动一行
row_n = cursor.fetchmany() #获取前n条数据,获取后游标会向下移动n行
row_all = cursor.fetchall() #获取所有数据,获取后游标会向下移动到末尾
print(row1)
print(row_n)
print(row_all)
#conn.commit()
cursor.close()
conn.close()
查询数据获取
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode='relative') # 相对当前位置移动
- cursor.scroll(2,mode='absolute') # 相对绝对位置移动
fetch获取数据类型
fetch获取的数据默认为元组格式,还可以获取字典类型的,如下:
#***************************获取字典格式数据******************************************************
conn = pymysql.connect(host="localhost", user="root", passwd="", db='learningsql', charset='utf8', port=) #和mysql服务端设置格式一样(还可设置为gbk, gb2312)
#创建游标
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) select_sql = "select id,nickname,size from t_sales where id>%s;"
cursor.execute(select_sql, (,)) row1 = cursor.fetchall() print(row1) conn.commit()
cursor.close()
conn.close()
2.SQLAlchmy框架
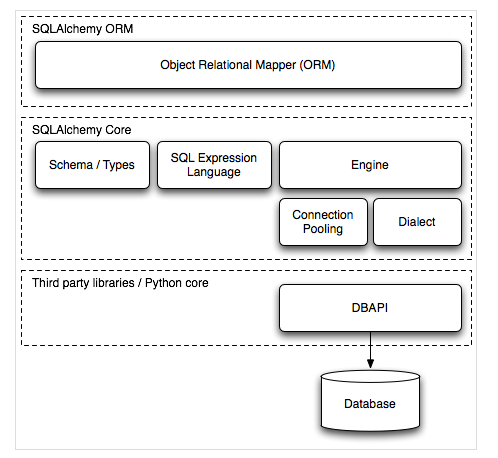
SQLAlchemy的整体架构如下,建立在第三方的DB API上,将类和对象操作转换为数据库sql,然后利用DB API执sql语句得到结果。其适用于多种数据库。另外其内部实现了数据库连接池,方便进行多线程操作。
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类,(pymysql,mysqldb等)
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
- DB API: Python Database API Specification
2.1 执行原生sql
安装:pip install sqlalchemy
SQLAlchmy也可以不利用ORM,使用数据库连接池,类似pymysql模块执行原生sql
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer
import threading engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8",
max_overflow = , #超过连接池大小外最多创建的连接,为0表示超过5个连接后,其他连接请求会阻塞 (默认为10)
pool_size = , #连接池大小(默认为5)
pool_timeout = , #连接线程池中,没有连接时最多等待的时间,不设置无连接时直接报错 (默认为30)
pool_recycle = -) #多久之后对线程池中的线程进行一次连接的回收(重置) (默认为-) # def task():
# conn= engine.raw_connection() #建立原生连接,和pymysql的连接一样
# cur = conn.cursor()
# cur.execute("select * from t_sales where id>%s",(,))
# result = cur.fetchone()
# cur.close()
# conn.close()
# print(result) # def task():
# conn = engine.contextual_connect() #建立上下文管理器连接,自动打开和关闭
# with conn:
# cur = conn.execute("select * from t_sales where id>%s",(,))
# result = cur.fetchone()
# print(result) def task():
cur =engine.execute("select * from t_sales where id>%s",(,)) #engine直接执行
result = cur.fetchone()
cur.close()
print(result) if __name__=="__main__":
for i in range():
t = threading.Thread(target=task)
t.start()
三种方式执行原生sql
create_engine()方法的所有可选参数见下面源码:
def create_engine(*args, **kwargs):
"""Create a new :class:`.Engine` instance. The standard calling form is to send the URL as the
first positional argument, usually a string
that indicates database dialect and connection arguments:: engine = create_engine("postgresql://scott:tiger@localhost/test") Additional keyword arguments may then follow it which
establish various options on the resulting :class:`.Engine`
and its underlying :class:`.Dialect` and :class:`.Pool`
constructs:: engine = create_engine("mysql://scott:tiger@hostname/dbname",
encoding='latin1', echo=True) The string form of the URL is
``dialect[+driver]://user:password@host/dbname[?key=value..]``, where
``dialect`` is a database name such as ``mysql``, ``oracle``,
``postgresql``, etc., and ``driver`` the name of a DBAPI, such as
``psycopg2``, ``pyodbc``, ``cx_oracle``, etc. Alternatively,
the URL can be an instance of :class:`~sqlalchemy.engine.url.URL`. ``**kwargs`` takes a wide variety of options which are routed
towards their appropriate components. Arguments may be specific to
the :class:`.Engine`, the underlying :class:`.Dialect`, as well as the
:class:`.Pool`. Specific dialects also accept keyword arguments that
are unique to that dialect. Here, we describe the parameters
that are common to most :func:`.create_engine()` usage. Once established, the newly resulting :class:`.Engine` will
request a connection from the underlying :class:`.Pool` once
:meth:`.Engine.connect` is called, or a method which depends on it
such as :meth:`.Engine.execute` is invoked. The :class:`.Pool` in turn
will establish the first actual DBAPI connection when this request
is received. The :func:`.create_engine` call itself does **not**
establish any actual DBAPI connections directly. .. seealso:: :doc:`/core/engines` :doc:`/dialects/index` :ref:`connections_toplevel` :param case_sensitive=True: if False, result column names
will match in a case-insensitive fashion, that is,
``row['SomeColumn']``. .. versionchanged:: 0.8
By default, result row names match case-sensitively.
In version 0.7 and prior, all matches were case-insensitive. :param connect_args: a dictionary of options which will be
passed directly to the DBAPI's ``connect()`` method as
additional keyword arguments. See the example
at :ref:`custom_dbapi_args`. :param convert_unicode=False: if set to True, sets
the default behavior of ``convert_unicode`` on the
:class:`.String` type to ``True``, regardless
of a setting of ``False`` on an individual
:class:`.String` type, thus causing all :class:`.String`
-based columns
to accommodate Python ``unicode`` objects. This flag
is useful as an engine-wide setting when using a
DBAPI that does not natively support Python
``unicode`` objects and raises an error when
one is received (such as pyodbc with FreeTDS). See :class:`.String` for further details on
what this flag indicates. :param creator: a callable which returns a DBAPI connection.
This creation function will be passed to the underlying
connection pool and will be used to create all new database
connections. Usage of this function causes connection
parameters specified in the URL argument to be bypassed. :param echo=False: if True, the Engine will log all statements
as well as a repr() of their parameter lists to the engines
logger, which defaults to sys.stdout. The ``echo`` attribute of
``Engine`` can be modified at any time to turn logging on and
off. If set to the string ``"debug"``, result rows will be
printed to the standard output as well. This flag ultimately
controls a Python logger; see :ref:`dbengine_logging` for
information on how to configure logging directly. :param echo_pool=False: if True, the connection pool will log
all checkouts/checkins to the logging stream, which defaults to
sys.stdout. This flag ultimately controls a Python logger; see
:ref:`dbengine_logging` for information on how to configure logging
directly. :param empty_in_strategy: The SQL compilation strategy to use when
rendering an IN or NOT IN expression for :meth:`.ColumnOperators.in_`
where the right-hand side
is an empty set. This is a string value that may be one of
``static``, ``dynamic``, or ``dynamic_warn``. The ``static``
strategy is the default, and an IN comparison to an empty set
will generate a simple false expression "1 != 1". The ``dynamic``
strategy behaves like that of SQLAlchemy 1.1 and earlier, emitting
a false expression of the form "expr != expr", which has the effect
of evaluting to NULL in the case of a null expression.
``dynamic_warn`` is the same as ``dynamic``, however also emits a
warning when an empty set is encountered; this because the "dynamic"
comparison is typically poorly performing on most databases. .. versionadded:: 1.2 Added the ``empty_in_strategy`` setting and
additionally defaulted the behavior for empty-set IN comparisons
to a static boolean expression. :param encoding: Defaults to ``utf-``. This is the string
encoding used by SQLAlchemy for string encode/decode
operations which occur within SQLAlchemy, **outside of
the DBAPI.** Most modern DBAPIs feature some degree of
direct support for Python ``unicode`` objects,
what you see in Python as a string of the form
``u'some string'``. For those scenarios where the
DBAPI is detected as not supporting a Python ``unicode``
object, this encoding is used to determine the
source/destination encoding. It is **not used**
for those cases where the DBAPI handles unicode
directly. To properly configure a system to accommodate Python
``unicode`` objects, the DBAPI should be
configured to handle unicode to the greatest
degree as is appropriate - see
the notes on unicode pertaining to the specific
target database in use at :ref:`dialect_toplevel`. Areas where string encoding may need to be accommodated
outside of the DBAPI include zero or more of: * the values passed to bound parameters, corresponding to
the :class:`.Unicode` type or the :class:`.String` type
when ``convert_unicode`` is ``True``;
* the values returned in result set columns corresponding
to the :class:`.Unicode` type or the :class:`.String`
type when ``convert_unicode`` is ``True``;
* the string SQL statement passed to the DBAPI's
``cursor.execute()`` method;
* the string names of the keys in the bound parameter
dictionary passed to the DBAPI's ``cursor.execute()``
as well as ``cursor.setinputsizes()`` methods;
* the string column names retrieved from the DBAPI's
``cursor.description`` attribute. When using Python , the DBAPI is required to support
*all* of the above values as Python ``unicode`` objects,
which in Python are just known as ``str``. In Python ,
the DBAPI does not specify unicode behavior at all,
so SQLAlchemy must make decisions for each of the above
values on a per-DBAPI basis - implementations are
completely inconsistent in their behavior. :param execution_options: Dictionary execution options which will
be applied to all connections. See
:meth:`~sqlalchemy.engine.Connection.execution_options` :param implicit_returning=True: When ``True``, a RETURNING-
compatible construct, if available, will be used to
fetch newly generated primary key values when a single row
INSERT statement is emitted with no existing returning()
clause. This applies to those backends which support RETURNING
or a compatible construct, including PostgreSQL, Firebird, Oracle,
Microsoft SQL Server. Set this to ``False`` to disable
the automatic usage of RETURNING. :param isolation_level: this string parameter is interpreted by various
dialects in order to affect the transaction isolation level of the
database connection. The parameter essentially accepts some subset of
these string arguments: ``"SERIALIZABLE"``, ``"REPEATABLE_READ"``,
``"READ_COMMITTED"``, ``"READ_UNCOMMITTED"`` and ``"AUTOCOMMIT"``.
Behavior here varies per backend, and
individual dialects should be consulted directly. Note that the isolation level can also be set on a per-:class:`.Connection`
basis as well, using the
:paramref:`.Connection.execution_options.isolation_level`
feature. .. seealso:: :attr:`.Connection.default_isolation_level` - view default level :paramref:`.Connection.execution_options.isolation_level`
- set per :class:`.Connection` isolation level :ref:`SQLite Transaction Isolation <sqlite_isolation_level>` :ref:`PostgreSQL Transaction Isolation <postgresql_isolation_level>` :ref:`MySQL Transaction Isolation <mysql_isolation_level>` :ref:`session_transaction_isolation` - for the ORM :param label_length=None: optional integer value which limits
the size of dynamically generated column labels to that many
characters. If less than , labels are generated as
"_(counter)". If ``None``, the value of
``dialect.max_identifier_length`` is used instead. :param listeners: A list of one or more
:class:`~sqlalchemy.interfaces.PoolListener` objects which will
receive connection pool events. :param logging_name: String identifier which will be used within
the "name" field of logging records generated within the
"sqlalchemy.engine" logger. Defaults to a hexstring of the
object's id. :param max_overflow=: the number of connections to allow in
connection pool "overflow", that is connections that can be
opened above and beyond the pool_size setting, which defaults
to five. this is only used with :class:`~sqlalchemy.pool.QueuePool`. :param module=None: reference to a Python module object (the module
itself, not its string name). Specifies an alternate DBAPI module to
be used by the engine's dialect. Each sub-dialect references a
specific DBAPI which will be imported before first connect. This
parameter causes the import to be bypassed, and the given module to
be used instead. Can be used for testing of DBAPIs as well as to
inject "mock" DBAPI implementations into the :class:`.Engine`. :param paramstyle=None: The `paramstyle <http://legacy.python.org/dev/peps/pep-0249/#paramstyle>`_
to use when rendering bound parameters. This style defaults to the
one recommended by the DBAPI itself, which is retrieved from the
``.paramstyle`` attribute of the DBAPI. However, most DBAPIs accept
more than one paramstyle, and in particular it may be desirable
to change a "named" paramstyle into a "positional" one, or vice versa.
When this attribute is passed, it should be one of the values
``"qmark"``, ``"numeric"``, ``"named"``, ``"format"`` or
``"pyformat"``, and should correspond to a parameter style known
to be supported by the DBAPI in use. :param pool=None: an already-constructed instance of
:class:`~sqlalchemy.pool.Pool`, such as a
:class:`~sqlalchemy.pool.QueuePool` instance. If non-None, this
pool will be used directly as the underlying connection pool
for the engine, bypassing whatever connection parameters are
present in the URL argument. For information on constructing
connection pools manually, see :ref:`pooling_toplevel`. :param poolclass=None: a :class:`~sqlalchemy.pool.Pool`
subclass, which will be used to create a connection pool
instance using the connection parameters given in the URL. Note
this differs from ``pool`` in that you don't actually
instantiate the pool in this case, you just indicate what type
of pool to be used. :param pool_logging_name: String identifier which will be used within
the "name" field of logging records generated within the
"sqlalchemy.pool" logger. Defaults to a hexstring of the object's
id. :param pool_pre_ping: boolean, if True will enable the connection pool
"pre-ping" feature that tests connections for liveness upon
each checkout. .. versionadded:: 1.2 .. seealso:: :ref:`pool_disconnects_pessimistic` :param pool_size=: the number of connections to keep open
inside the connection pool. This used with
:class:`~sqlalchemy.pool.QueuePool` as
well as :class:`~sqlalchemy.pool.SingletonThreadPool`. With
:class:`~sqlalchemy.pool.QueuePool`, a ``pool_size`` setting
of indicates no limit; to disable pooling, set ``poolclass`` to
:class:`~sqlalchemy.pool.NullPool` instead. :param pool_recycle=-: this setting causes the pool to recycle
connections after the given number of seconds has passed. It
defaults to -, or no timeout. For example, setting to
means connections will be recycled after one hour. Note that
MySQL in particular will disconnect automatically if no
activity is detected on a connection for eight hours (although
this is configurable with the MySQLDB connection itself and the
server configuration as well). .. seealso:: :ref:`pool_setting_recycle` :param pool_reset_on_return='rollback': set the
:paramref:`.Pool.reset_on_return` parameter of the underlying
:class:`.Pool` object, which can be set to the values
``"rollback"``, ``"commit"``, or ``None``. .. seealso:: :paramref:`.Pool.reset_on_return` :param pool_timeout=: number of seconds to wait before giving
up on getting a connection from the pool. This is only used
with :class:`~sqlalchemy.pool.QueuePool`. :param plugins: string list of plugin names to load. See
:class:`.CreateEnginePlugin` for background. .. versionadded:: 1.2. :param strategy='plain': selects alternate engine implementations.
Currently available are: * the ``threadlocal`` strategy, which is described in
:ref:`threadlocal_strategy`;
* the ``mock`` strategy, which dispatches all statement
execution to a function passed as the argument ``executor``.
See `example in the FAQ
<http://docs.sqlalchemy.org/en/latest/faq/metadata_schema.html#how-can-i-get-the-create-table-drop-table-output-as-a-string>`_. :param executor=None: a function taking arguments
``(sql, *multiparams, **params)``, to which the ``mock`` strategy will
dispatch all statement execution. Used only by ``strategy='mock'``. """ strategy = kwargs.pop('strategy', default_strategy)
strategy = strategies.strategies[strategy]
return strategy.create(*args, **kwargs)
create_engine源码
2.2 执行ORM语句
A. 创建和删除表
#coding:utf- import datetime
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer, DateTime, Text Base = declarative_base() class User(Base):
__tablename__="users"
id = Column(Integer,primary_key=True)
name = Column(String(),index=True, nullable=False) #创建索引,不为空
email = Column(String(),unique=True)
ctime = Column(DateTime, default = datetime.datetime.now) #传入方法名datetime.datetime.now
extra = Column(Text,nullable=True) __table_args__ = { # UniqueConstraint('id', 'name', name='uix_id_name'), #设置联合唯一约束
# Index('ix_id_name', 'name', 'email'), # 创建索引
} def create_tbs():
engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8",max_overflow=,pool_size=)
Base.metadata.create_all(engine) #创建所有定义的表 def drop_dbs():
engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8",max_overflow=,pool_size=)
Base.metadata.drop_all(engine) #删除所有创建的表 if __name__=="__main__":
create_tbs() #创建表
#drop_dbs() #删除表
创建和删除表格
B.表中定义外键关系(一对多,多对多)
(思考:下面代码中的一对多关系,relationship定义在了customer表中,应该定义在PurchaseOrder更合理?)
(注意:mysql数据库中避免使用order做为表的名字,order为一个mysql关键字,做为表名字时必须用反引号`order` (键盘数字1旁边的符号))
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,Text,DateTime,ForeignKey,Float
from sqlalchemy.orm import relationship
import datetime engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8") #数据库有密码时,//root:12345678@127.0.0.1:3306/
Base = declarative_base() class Customer(Base):
__tablename__="customer" #数据库中保存的表名字 id = Column(Integer,primary_key=True)
name = Column(String(),index=True,nullable=False)
phone = Column(String(),nullable=False)
address = Column(String(),nullable=False)
purchase_order_id = Column(Integer,ForeignKey("purchase_order.id")) #关键关系,关联表的__tablename__="purchase_order" # 和建立表结构无关,方便外键关系查询,backref反向查询时使用order_obj.customer
purchase_order = relationship("PurchaseOrder",backref="customer") class PurchaseOrder(Base):
__tablename__ = "purchase_order" #mysql数据库中表的名字避免使用order,order为一个关键字,使用时必须用反引号`order` (键盘数字1旁边的符号)
id=Column(Integer,primary_key=True)
cost = Column(Float,nullable=True)
ctime = Column(DateTime,default =datetime.datetime.now)
desc = Column(String()) #多对多关系时,secondary为中间表
product = relationship("Product",secondary="order_to_product",backref="purchase_order") class Product(Base):
__tablename__ = "product"
id = Column(Integer,primary_key=True)
name = Column(String())
price = Column(Float,nullable=False) class OrdertoProduct(Base):
__tablename__ = "order_to_product"
id = Column(Integer,primary_key=True)
product_id = Column(Integer,ForeignKey("product.id"))
purchase_order_id = Column(Integer,ForeignKey("purchase_order.id")) if __name__ == "__main__":
Base.metadata.create_all(engine)
#Base.metadata.drop_all(engine)
外键关系
C.增删改查操作
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,Text,DateTime,ForeignKey,Float
from sqlalchemy.orm import relationship,sessionmaker
from sqlalchemy.sql import text
import datetime engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8") #数据库有密码时,//root:12345678@127.0.0.1:3306/, 设置utf8防止中文乱码
Base = declarative_base() class Customer(Base):
__tablename__="customer" #数据库中保存的表名字 id = Column(Integer,primary_key=True)
name = Column(String(),index=True,nullable=False)
phone = Column(String(),nullable=False)
address = Column(String(),nullable=False)
purchase_order_id = Column(Integer,ForeignKey("purchase_order.id")) #关键关系,关联表的__tablename__="purchase_order" # 和建立表结构无关,方便外键关系查询,backref反向查询时使用order_obj.customer
purchase_order = relationship("PurchaseOrder",backref="customer") class PurchaseOrder(Base):
__tablename__ = "purchase_order" #mysql数据库中表的名字避免使用order,order为一个关键字,使用时必须用反引号`order` (键盘数字1旁边的符号)
id=Column(Integer,primary_key=True)
cost = Column(Float,nullable=True)
ctime = Column(DateTime,default =datetime.datetime.now)
desc = Column(String()) #多对多关系时,secondary为中间表
product = relationship("Product",secondary="order_to_product",backref="purchase_order") class Product(Base):
__tablename__ = "product"
id = Column(Integer,primary_key=True)
name = Column(String())
price = Column(Float,nullable=False) class OrdertoProduct(Base):
__tablename__ = "order_to_product"
id = Column(Integer,primary_key=True)
product_id = Column(Integer,ForeignKey("product.id"))
purchase_order_id = Column(Integer,ForeignKey("purchase_order.id")) if __name__ == "__main__":
#Base.metadata.create_all(engine)
#Base.metadata.drop_all(engine) Session = sessionmaker(bind=engine) #每次进行数据库操作时都要创建session
session = Session() #*****************增加数据********************
# pur_order = PurchaseOrder(cost=19.7,desc="python编程之路") # session.add(pur_order)
# session.add_all(
# [PurchaseOrder(cost=39.7,desc="linux操作系统"),
# PurchaseOrder(cost=59.6,desc="python cookbook")])
# session.commit() #*****************修改数据******************** #session.query(PurchaseOrder).filter(PurchaseOrder.id>).update({"cost":29.7})
#session.query(PurchaseOrder).filter(PurchaseOrder.id==).update({"cost":PurchaseOrder.cost+40.1},synchronize_session=False) #synchronize_session用于query在进行delete or update操作时,对session的同步策略。
#session.commit() #*****************删除数据********************
#session.query(PurchaseOrder).filter(PurchaseOrder.id==).delete()
#session.commit() #*****************查询数据********************
#ret = session.query(PurchaseOrder).all()
# ret = session.query(PurchaseOrder).filter(PurchaseOrder.id==).all() #包含对象的列表
# ret = session.query(PurchaseOrder).filter(PurchaseOrder.id==).first() #单个对象
# ret = session.query(PurchaseOrder).filter_by(id=).all() #通过列名字的表达式
# ret = session.query(PurchaseOrder).filter_by(id=).first()
#ret = session.query(PurchaseOrder).filter(text("id<:value and cost>:price")).params(value=,price=).order_by(PurchaseOrder.cost).all()
#ret = session.query(PurchaseOrder).from_statement(text("SELECT * FROM purchase_order WHERE cost>:price")).params(price=).all()
# print ret
# for i in ret:
# print i.id, i.cost, i.ctime,i.desc #ret2 = session.query(PurchaseOrder.id,PurchaseOrder.cost.label('totalcost')).all() #只查询两列,ret2为列表
#print ret2 #关闭session
session.close()
增删改查
# 条件
ret = session.query(Users).filter_by(name='alex').all()
ret = session.query(Users).filter(Users.id > , Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(, ), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([,,])).all()
ret = session.query(Users).filter(~Users.id.in_([,,])).all()
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > , Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < , Users.name == 'eric')).all()
ret = session.query(Users).filter(
or_(
Users.id < ,
and_(Users.name == 'eric', Users.id > ),
Users.extra != ""
)).all() # 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all() # 限制
ret = session.query(Users)[:] # 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组
from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all() ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >).all() # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all() ret = session.query(Person).join(Favor, isouter=True).all() # 组合
q1 = session.query(Users.name).filter(Users.id > )
q2 = session.query(Favor.caption).filter(Favor.nid < )
ret = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > )
q2 = session.query(Favor.caption).filter(Favor.nid < )
ret = q1.union_all(q2).all()
查询语句
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text, func
from sqlalchemy_orm2 import PurchaseOrder #导入定义的PurchaseOrder表格类 engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8")
Session = sessionmaker(bind=engine)
session = Session()
#查询
ret = session.execute("select * from purchase_order where id=:value",params={"value":})
print ret
for i in ret:
print i.id, i.cost, i.ctime,i.desc #插入
purchase_order = PurchaseOrder.__table__ #拿到PurchaseOrder表格对象
ret=session.execute(purchase_order.insert(),
[{"cost":46.3,"desc":'python2'},
{"cost":43.3,"desc":'python3'}])
session.commit()
print(ret.lastrowid) session.close() # 关联子查询
subqry = session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id).correlate(Group).as_scalar()
result = session.query(Group.name, subqry)
"""
SELECT `group`.name AS group_name, (SELECT count(server.id) AS sid
FROM server
WHERE server.id = `group`.id) AS anon_1
FROM `group`
"""
补充
D.多线程操作
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy_orm2 import Product
from threading import Thread engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8",max_overflow=,pool_size=)
Session = sessionmaker(bind=engine) def task(name,price):
session = Session()
pro = Product(name=name,price=price)
session.add(pro)
session.commit()
session.close() if __name__=="__main__":
for i in range():
t = Thread(target=task,args=("pro"+str(i),i*))
t.start()
多线程
E. 通过relationship操纵一对多和多对多关系
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text, func
from sqlalchemy_orm2 import PurchaseOrder,Product,OrdertoProduct,Customer #导入定义的表格类 engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8")
Session = sessionmaker(bind=engine)
session = Session() # #通过定义的关键关系添加(id值)
# cus1 = Customer(name="zack",phone="",address="Nanjing",purchase_order_id=)
# session.add(cus1) # #通过relationship正向添加
# cus2 = Customer(name="zack2",phone="",address="Nanjing",purchase_order=PurchaseOrder(cost=,desc="java"))
# session.add(cus2)
# session.commit() #通过relationship反向添加
# purchase_order=PurchaseOrder(cost=,desc="php")
# cus3 = Customer(name="zack3",phone="",address="Nanjing")
# cus4 = Customer(name="zack4",phone="",address="Nanjing")
# purchase_order.customer=[cus3,cus4] #cus3,cus4的purchase_order_id都是purchase_order.id值,即同时添加了两组外键关系
# session.add(purchase_order)
# session.commit() ##通过relationship正向查询
cus = session.query(Customer).first()
print(cus.purchase_order_id)
print(cus.purchase_order.desc) #通过relationship反向查询
pur = session.query(PurchaseOrder).filter(PurchaseOrder.id==).first()
print(pur.desc)
print(pur.customer) #返回一个list
一对多
#coding:utf- from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text, func
from sqlalchemy_orm2 import PurchaseOrder,Product,OrdertoProduct,Customer #导入定义的表格类 engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/learningsql?charset=utf8")
Session = sessionmaker(bind=engine)
session = Session() # session.add_all([Product(name="java",price=),
# Product(name="python",price=),
# Product(name="php",price=)])
# session.commit() # #通过定义的关键关系添加(id值)
# op = OrdertoProduct(product_id=,purchase_order_id=)
# session.add(op)
# session.commit() # #通过relationship添加
# pur = PurchaseOrder(cost=,desc="xxxx")
# pur.product = [Product(name="C++",price=),] #正向
# session.add(pur) # pro = Product(name="C",price=)
# pro.purchase_order=[PurchaseOrder(cost=,desc="xxxx"),] #反向
# session.add(pro)
# session.commit() #通过relationship正向查询
pur = session.query(PurchaseOrder).filter(PurchaseOrder.id==).first()
print(pur.desc)
print(pur.product) #结果为列表 #通过relationship反向查询
pro = session.query(Product).filter(Product.id==).first()
print(pro.name)
print(pro.purchase_order) #结果为列表 session.close()
多对多
3.数据库连接池
对于ORM框架,其内部维护了链接池,可以直接通过多线程操控数据库。对于pymysql模块,通过多线程操控数据库容易出错,得加锁串行执行。进行并发时,可以利用DBUtils模块来维护数据库连接池。
3.1 多线程操控pymysql
不采用DBUtils连接池时, pymysql多线程代码如下:
import pymysql
import threadind #**************************无连接池*******************************
#每个线程都要创立一次连接,线程并发操作间可能有问题?
def func():
conn = pymysql.connect(host="127.0.0.1",port=,db="learningsql",user="root",passwd="",charset="utf8")
cursor = conn.cursor()
cursor.execute("select * from user where nid>1;")
result = cursor.fetchone()
print(result)
cursor.close()
conn.close() if __name__=="__main__":
for i in range():
t = threading.Thread(target=func,name="thread-%s"%i)
t.start()
每个线程创建连接
#**************************无连接池*******************************
#创建一个连接,加锁串行执行
from threading import Lock
import pymysql
import threading
conn = pymysql.connect(host="127.0.0.1",port=,db="learningsql",user="root",passwd="",charset="utf8") lock = Lock()
def func():
with lock:
cursor = conn.cursor()
cursor.execute("select * from user where nid>1;")
result = cursor.fetchone()
print(result)
cursor.close() #conn.close()不能在线程中关闭连接,否则其他线程不可用了 if __name__=="__main__":
threads = []
for i in range():
t = threading.Thread(target=func,name="thread-%s"%i)
threads.append(t)
t.start() for t in threads:
t.join() conn.close()
一个连接串行执行
3.2 DBUtils连接池
DBUtils连接池有两种连接模式:PersistentDB和PooledDB (官网文档:https://cito.github.io/DBUtils/UsersGuide.html)
模式一(DBUtils.PersistentDB):为每个线程创建一个连接,线程即使调用了close方法,也不会关闭,只是把连接重新放到连接池,供自己线程再次使用。当线程终止时,连接自动关闭。
PersistentDB使用代码如下:
#coding:utf- from DBUtils.PersistentDB import PersistentDB
import pymysql
import threading pool = PersistentDB(
creator = pymysql, # 使用链接数据库的模块
maxusage = None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping = , # ping MySQL服务端,检查是否服务可用。# 如: = None = never, = default = whenever it is requested, = when a cursor is created, = when a query is executed, = always
closeable = False, # 如果为False时, conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接)
threadlocal = None, # 本线程独享值得对象,用于保存链接对象,如果链接对象被重置
host="127.0.0.1",
port = ,
user = "root",
password="",
database="learningsql",
charset = "utf8"
) def func():
conn = pool.connection()
cursor = conn.cursor()
cursor.execute("select * from user where nid>1;")
result = cursor.fetchone()
print(result)
cursor.close()
conn.close() if __name__ == "__main__":
for i in range():
t = threading.Thread(target=func,name="thread-%s"%i)
t.start()
PersistentDB 使用
模式二(DBUtils.PooledDB):创建一批连接到连接池,供所有线程共享使用。
(由于pymysql、MySQLdb等threadsafety值为1,所以该模式连接池中的线程会被所有线程共享。)
PooledDB使用代码如下:
from DBUtils.PooledDB import PooledDB
import pymysql
import threading
import time pool = PooledDB(
creator = pymysql, # 使用链接数据库的模块
maxconnections = , # 连接池允许的最大连接数,0和None表示不限制连接数
mincached = , # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached = , # 链接池中最多闲置的链接,0和None不限制
maxshared = , # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking = True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage = None, # 一个链接最多被重复使用的次数,None表示无限制
setsession = [], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping = , # ping MySQL服务端,检查是否服务可用。# 如: = None = never, = default = whenever it is requested, = when a cursor is created, = when a query is executed, = always
host="127.0.0.1",
port = ,
user="root",
password="",
database = "learningsql",
charset = "utf8"
) def func():
conn = pool.connection()
cursor = conn.cursor()
cursor.execute("select * from user where nid>1;")
result = cursor.fetchone()
print(result)
time.sleep() #为了查看mysql端的线程数量
cursor.close()
conn.close() if __name__=="__main__":
for i in range():
t = threading.Thread(target=func,name="thread-%s"%i)
t.start()
PooledDB使用
上述代码中加入了sleep(5)使线程连接数据库时间延长,方便查看mysql数据库连接线程情况,下图分别为代码执行中和执行后的线程连接情况,可以发现,代码执行时,同时有6个线程连接上了数据库(有一个为mysql命令客户端),代码执行后,只有一个线程连接数据库,但仍有5个线程等待连接。
(show status like "Threads%" 查看线程连接情况)
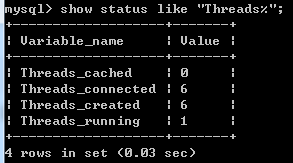
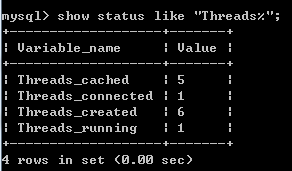
参考: http://www.cnblogs.com/wupeiqi/articles/8184686.html
http://nettee.github.io/posts/2016/SQLAlchemy-Architecture-Note/
http://www.cnblogs.com/wupeiqi/articles/8259356.html
python操作MySQL数据库的三个模块的更多相关文章
- Python操作MySQL数据库的三种方法
https://blog.csdn.net/Oscer2016/article/details/70257024 1. MySQLdb 的使用 (1) 什么是MySQLdb? MySQLdb 是用 ...
- python接口自动化(三十八)-python操作mysql数据库(详解)
简介 现在的招聘要求对QA人员的要求越来越高,测试的一些基础知识就不必说了,来说测试知识以外的,会不会一门或者多门开发与语言,能不能读懂代码,会不会Linux,会不会搭建测试系统,会不会常用的数据库, ...
- python操作三大主流数据库(1)python操作mysql①windows环境中安装python操作mysql数据库的MySQLdb模块mysql-client
windows安装python操作mysql数据库的MySQLdb模块mysql-client 正常情况下应该是cmd下直接运行 pip install mysql-client 命令即可,试了很多台 ...
- Python操作MySQL数据库9个实用实例
用python连接mysql的时候,需要用的安装版本,源码版本容易有错误提示.下边是打包了32与64版本. MySQL-python-1.2.3.win32-py2.7.exe MySQL-pytho ...
- Python操作MySQL数据库(步骤教程)
我们经常需要将大量数据保存起来以备后续使用,数据库是一个很好的解决方案.在众多数据库中,MySQL数据库算是入门比较简单.语法比较简单,同时也比较实用的一个.在这篇博客中,将以MySQL数据库为例,介 ...
- python操作mysql数据库的常用方法使用详解
python操作mysql数据库 1.环境准备: Linux 安装mysql: apt-get install mysql-server 安装python-mysql模块:apt-get instal ...
- 【转】python操作mysql数据库
python操作mysql数据库 Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口. Python 数据库接口支持非常多的数据库 ...
- Python 操作MySQL 数据库
Python 操作 MySQL 数据库 Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口. Python 数据库接口支持非常多的 ...
- python操作mysql数据库的相关操作实例
python操作mysql数据库的相关操作实例 # -*- coding: utf-8 -*- #python operate mysql database import MySQLdb #数据库名称 ...
随机推荐
- ASE19团队项目beta阶段Backend组 scrum5 记录
本次会议于12月11日,19:30在微软北京西二号楼sky garden召开,持续10分钟. 与会人员:Zhikai Chen, Lihao Ran, Xin Kang 请假人员:Hao Wang 每 ...
- eclipse导入项目后出现红色叉号的解决方案
对于一名程序员来说,我导入的项目在项目的名称上无端加了一个红色的叉号,虽然这个不友好的符号,对于我整个的项目运行没有任何影响,但是总让我觉得不舒服,大大的叉号写在我的项目的脑袋上,我心里能舒服吗?于是 ...
- Linux上使用trash回收机制来替换rm命令
因为我们日常使用的rm 命令没有恢复机制,删除了文件就找不到了,往往重要的文件,我们要特别小心才对,但是有时还是避免不了我们的误操作.可能会造成很大的影响. 本博文简单介绍一下,用trash命令仿照W ...
- 案例:selenium实现登录处理弹窗
func.py https://www.cnblogs.com/andy9468/p/10899508.html main.py中 # 导入webdriver import os import tim ...
- 【shell】shell基础
一.数据类型 1.shell变量 运行shell时,会同时存在三种变量: 1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量. 2) 环 ...
- python Beautiful Soup 采集it books pdf,免费下载
http://www.allitebooks.org/ 是我见过最良心的网站,所有书籍免费下载 周末无聊,尝试采集此站所有Pdf书籍. 采用技术 python3.5 Beautiful soup 分享 ...
- 用js刷剑指offer(旋转数组的最小数字)
题目描述 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转. 输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素. 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个 ...
- java学习笔记14-多态
多态可以理解为同一个操作在不同对象上会有不同的表现 比如在谷歌浏览器上按F1会弹出谷歌的帮助页面.在windows桌面按F1会弹出windows的帮助页面. 多态存在的三个必要条件: 继承 重写 父类 ...
- 【万能的DFS和BFS基础框架】-多刷题才是硬道理!
- 2018/7/31-zznuoj-问题 A: A + B 普拉斯【二维字符串+暴力模拟+考虑瑕疵的题意-0的特例】
问题 A: A + B 普拉斯 在计算机中,数字是通过像01像素矩阵来显示的,最终的显示效果如下: 现在我们用01来构成这些数字 当宝儿姐输入A + B 时(log10(A)<50,log10 ...