RDD java API使用
1.RDD介绍:
JavaRDD<String> lines=sc.textFile(inputFile);
(2)分发对象集合,这里以list为例
List<String> list=new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
JavaRDD<String> temp=sc.parallelize(list);
//上述方式等价于
JavaRDD<String> temp2=sc.parallelize(Arrays.asList("a","b","c"));
List<String> list=new ArrayList<String>();
//建立列表,列表中包含以下自定义表项
list.add("error:a");
list.add("error:b");
list.add("error:c");
list.add("warning:d");
list.add("hadppy ending!");
//将列表转换为RDD对象
JavaRDD<String> lines = sc.parallelize(list);
//将RDD对象lines中有error的表项过滤出来,放在RDD对象errorLines中
JavaRDD<String> errorLines = lines.filter(
new Function<String, Boolean>() {
public Boolean call(String v1) throws Exception {
return v1.contains("error");
}
}
);
//遍历过滤出来的列表项
List<String> errorList = errorLines.collect();
for (String line : errorList)
System.out.println(line);
union
/**
* Take the first num elements of the RDD. This currently scans the partitions *one by one*, so
* it will be slow if a lot of partitions are required. In that case, use collect() to get the
* whole RDD instead.
*/
def take(num: Int): JList[T]
程序示例:接上
JavaRDD<String> unionLines=errorLines.union(warningLines); for(String line :unionLines.take(2))
System.out.println(line);
输出:
List<String> unions=unionLines.collect();
for(String line :unions)
System.out.println(line);
遍历输出RDD数据集unions的每一项
|
函数名
|
实现的方法
|
用途
|
|
Function<T,R>
|
R call(T)
|
接收一个输入值并返回一个输出值,用于类似map()和filter()的操作中 |
| Function<T1,T2,R> |
R call(T1,T2)
|
接收两个输入值并返回一个输出值,用于类似aggregate()和fold()等操作中
|
| FlatMapFunction<T,R> |
Iterable <R> call(T)
|
接收一个输入值并返回任意个输出,用于类似flatMap()这样的操作中
|
JavaRDD<String> errorLines=lines.filter(
new Function<String, Boolean>() {
public Boolean call(String v1)throws Exception {
return v1.contains("error");
}
}
);
List<String> strLine=new ArrayList<String>();
strLine.add("how are you");
strLine.add("I am ok");
strLine.add("do you love me")
JavaRDD<String> input=sc.parallelize(strLine);
JavaRDD<String> words=input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
List<String> strLine=new ArrayList<String>();
strLine.add("how are you");
strLine.add("I am ok");
strLine.add("do you love me");
JavaRDD<String> input=sc.parallelize(strLine);
JavaRDD<String> words=input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
JavaPairRDD<String,Integer> counts=words.mapToPair(
new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2(s, 1);
}
}
);
JavaPairRDD <String,Integer> results=counts.reduceByKey(
new org.apache.spark.api.java.function.Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}
) ;
class ContainError implements Function<String,Boolean>{
public Boolean call(String v1) throws Exception {
return v1.contains("error");
}
}
JavaRDD<String> errorLines=lines.filter(new ContainError());
for(String line :errorLines.collect())
System.out.println(line);
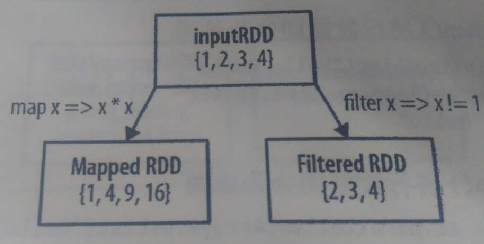
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> result=rdd.map(
new Function<Integer, Integer>() {
public Integer call(Integer v1) throwsException {
return v1*v1;
}
}
);
System.out.println( StringUtils.join(result.collect(),","));
输出:
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> results=rdd.filter(
new Function<Integer, Boolean>() {
public Boolean call(Integer v1) throws Exception {
return v1!=1;
}
}
);
System.out.println(StringUtils.join(results.collect(),","));
结果:
JavaRDD<String> rdd =sc.parallelize(Arrays.asList("hello world","hello you","world i love you"));
JavaRDD<String> words=rdd.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
System.out.println(StringUtils.join(words.collect(),'\n'));
输出:
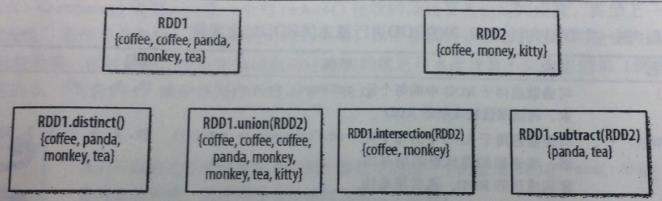
|
函数
|
用途
|
|
RDD1.distinct()
|
生成一个只包含不同元素的新RDD。需要数据混洗。 |
|
RDD1.union(RDD2)
|
返回一个包含两个RDD中所有元素的RDD |
|
RDD1.intersection(RDD2)
|
只返回两个RDD中都有的元素 |
|
RDD1.substr(RDD2)
|
返回一个只存在于第一个RDD而不存在于第二个RDD中的所有元素组成的RDD。需要数据混洗。 |
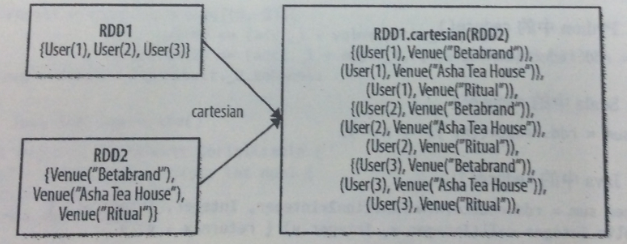
|
RDD1.cartesian(RDD2)
|
返回两个RDD数据集的笛卡尔集 |
JavaRDD<Integer> rdd1 = sc.parallelize(Arrays.asList(1,2));
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1,2));
JavaPairRDD<Integer ,Integer> rdd=rdd1.cartesian(rdd2);
for(Tuple2<Integer,Integer> tuple:rdd.collect())
System.out.println(tuple._1()+"->"+tuple._2());
输出:
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer sum =rdd.reduce(
new Function2<Integer, Integer, Integer>() {
public Integercall(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
System.out.println(sum.intValue());
输出:55
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer sum =rdd.fold(0,
new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
System.out.println(sum);
②计算RDD数据集中所有元素的积:
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer result =rdd.fold(1,
new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1*v2;
}
}
);
System.out.println(result);
(3)aggregate()操作
public class AvgCount implements Serializable{
public int total;
public int num;
public AvgCount(int total,int num){
this.total=total;
this.num=num;
}
public double avg(){
return total/(double)num;
}
static Function2<AvgCount,Integer,AvgCount> addAndCount=
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) throws Exception {
a.total+=x;
a.num+=1;
return a;
}
};
static Function2<AvgCount,AvgCount,AvgCount> combine=
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) throws Exception {
a.total+=b.total;
a.num+=b.num;
return a;
}
};
public static void main(String args[]){
SparkConf conf = new SparkConf().setMaster("local").setAppName("my app");
JavaSparkContext sc = new JavaSparkContext(conf);
AvgCount intial =new AvgCount(0,0);
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6));
AvgCount result=rdd.aggregate(intial,addAndCount,combine);
System.out.println(result.avg());
}
}
这个程序示例可以实现求出RDD对象集的平均数的功能。其中addAndCount将RDD对象集中的元素合并起来放入AvgCount对象之中,combine提供两个AvgCount对象的合并的实现。我们初始化AvgCount(0,0),表示有0个对象,对象的和为0,最终返回的result对象中total中储存了所有元素的和,num储存了元素的个数,这样调用result对象的函数avg()就能够返回最终所需的平均数,即avg=tatal/(double)num。
| 级别 |
使用的空间
|
cpu时间
|
是否在内存
|
是否在磁盘
|
备注
|
|
MEMORY_ONLY
|
高 |
低
|
是
|
否
|
直接储存在内存 |
| MEMORY_ONLY_SER |
低
|
高
|
是
|
否
|
序列化后储存在内存里
|
|
MEMORY_AND_DISK
|
低 |
中等
|
部分
|
部分
|
如果数据在内存中放不下,溢写在磁盘上 |
|
MEMORY_AND_DISK_SER
|
低 |
高
|
部分
|
部分
|
数据在内存中放不下,溢写在磁盘中。内存中存放序列化的数据。 |
|
DISK_ONLY
|
低
|
高
|
否
|
是
|
直接储存在硬盘里面
|
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4,5));
rdd.persist(StorageLevel.MEMORY_ONLY());
System.out.println(rdd.count());
System.out.println(StringUtils.join(rdd.collect(),','));
RDD还有unpersist()方法,调用该方法可以手动把持久化的RDD从缓存中移除。
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4,5));
JavaDoubleRDD result=rdd.mapToDouble(
new DoubleFunction<Integer>() {
public double call(Integer integer) throws Exception {
return (double) integer*integer;
}
}
);
System.out.println(result.max());
RDD java API使用的更多相关文章
- Spark基础与Java Api介绍
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3832405.html 一.Spark简介 1.什么是Spark 发源于AMPLab实验室的分布式内存计 ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
- 降维-基于RDD的API
降维-基于RDD的API Singular value decomposition (SVD) Performance SVD Example Principal component analysis ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Atitit 图像处理 调用opencv 通过java api attilax总结
Atitit 图像处理 调用opencv 通过java api attilax总结 1.1. Opencv java api的支持 opencv2.4.2 就有了对java api的支持1 1. ...
- 【分布式】Zookeeper使用--Java API
一.前言 上一篇博客我们通过命令行来操作Zookeper的客户端和服务端并进行相应的操作,这篇主要介绍如何通过API(JAVA)来操作Zookeeper. 二.开发环境配置 首先打开Zookeeper ...
- Elasticsearch的CRUD:REST与Java API
CRUD(Create, Retrieve, Update, Delete)是数据库系统的四种基本操作,分别表示创建.查询.更改.删除,俗称"增删改查".Elasticsearch ...
- [转]HDFS中JAVA API的使用
HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的文件进行操作的过程. 对分HDFS中的 ...
- HDFS中JAVA API的使用
HDFS中JAVA API的使用 HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的 ...
随机推荐
- ELK文档--ELK简介
请参考:http://www.cnblogs.com/aresxin/p/8035137.html
- python selectors模块实现 IO多路复用机制的上传下载
import selectorsimport socketimport os,time BASE_DIR = os.path.dirname(os.path.abspath(__file__))''' ...
- C++——多态实现原理分析
前言 虚函数执行速度要稍慢一些.为了实现多态性,每一个派生类中均要保存相应虚函数的入口地址表,函数的调用机制也是间接实现.所以多态性总是要付出一定代价,但通用性是一个更高的目标. 实验环境 Windo ...
- 用js刷剑指offer(二叉搜索树与双向链表)
题目描述 输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表.要求不能创建任何新的结点,只能调整树中结点指针的指向. 牛客网链接 js代码 /* function TreeNode(x) { ...
- web开发常见的鉴权方式
结合网上找的资料整理了一下,以下是web开发中常见的鉴权方法: 预备:一些基本的知识 RBAC(Role-Based Access Control)基于角色的权限访问控制(参考下面①的连接) l ...
- WCF服务代理类-学习
类:ServiceDescriptionImporter Class 公开一种为 XML Web services 生成客户端代理类的方法. 地址:https://docs.microsoft.com ...
- jade变量声明和数据传递
声明一个变量 - var course = 'jade'; 取得一个变量 #{course} 大括号里面写入变量命,前面加个#号就可以取得变量 在括号里面可以进行诸多都运行操作,比如大小写 #{cou ...
- Tomcat 安装配置
操作系统:win10 家庭版 1. 官网下载 https://tomcat.apache.org/download-80.cgi 我下载的免安装装. 2.文件解压到目录 D:\Program File ...
- webpack 配置react脚手架(五):mobx
1. 配置项.使用mobx,因为语法时es6-next,所以先配置 .babelrc 文件 { "presets": [ ["es2015", { " ...
- @EnableCircuitBreaker熔断超时机制
客户端请求服务端的时候总是报超时,默认熔断机制是1S