[Java复习] 缓存Cache part1
1. 在项目中是如何使用缓存的?为什么要用?不用行不行?用了可能会有哪些不良后果?
结合项目业务,主要两个目的:高性能和高并发。缓存走内存,天然支持高并发。
不良后果:
- 缓存与DB双写不一致
- 缓存雪崩,缓存穿透
- 缓存并发竞争
2. Redis的线程模型是什么?
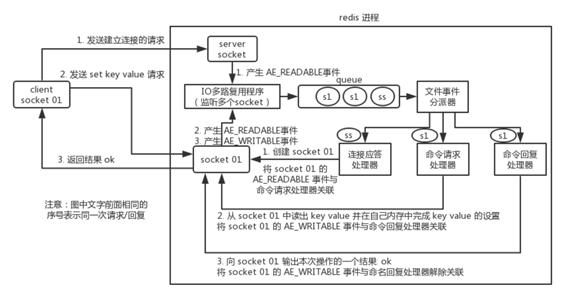
Redis内部使用文件事件处理器(file event handler),这个处理器是单线程,所有Redis才叫单线程模型。
采用IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
文件处理器包含4个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
socket并发不同操作,对应不同文件事件处理器,IO多路复用监听多个socket,将产生事件的socket放入队列排队,
文件事件分发器每次从队列中取出一个socket,根据socket事件类型交给对应的事件处理器进行处理。
I/O多路复用:

在同一个线程里面, 通过拨开关的方式,来同时传输多个I/O流。
Redis 通信过程:
3. 为什么Redis单线程模型也能效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
4. Redis 都有哪些数据类型?分别在哪些场景下使用比较合适?
数据类型:
string:最基本。普通Set get,简单K-V缓存
set name zhangsan
hash:类map结构。可以把结构化数据(对象)缓存。把简单对象缓存,后续操作可以只修改对象中某个字段。
key=user
value={
"id": 100,
"name":"zhangsan",
"age",20
}
hset user id 100
hset user name zhangsan
hset user age 20
list:有序列表。微博大V粉丝以list格式放Redis缓存。
key=某大V value=[zhangsan, li, wangwu]
list的lrange命令:从某个元素开始读取多少个元素,可以基于list实现简单分页。
lrange mylist 0 -1
0开始位置,-1结束位置,结束位置为-1时,表示列表的最后一个位置,即查看所有。
lpush, lpop //栈(FILO)
set: 无序,自动去重。
JVM的hashset可以去重,但是多台机器的呢?这个Redis的set适用于分布式全集去重。可以基于set做交集,并集,差集。查看大V共同好友等等。
sadd myset 1 // 添加元素1
smembers myset // 查看全部元素
sismember myset 2 // 判断是否包含某个元素
srem myset 1 // 删除元素1
srem myset 1 3 // 删除某些元素
scrad myset // 查看元素个数
spop myset // 随机删除一个元素
smove testset myset abc // 将testset的元素abc移到myset
sinter testset myset // 求两个set交集
sunion testset myset // 求两个元素并集
sdiff testset myset //求差集 在testset中而不宅myset的元素
sorted set: 排序的set,去重还可以排序。例如写入元素带分数,自动根据分数排序。
zadd board 85 zhangsan
zadd board 72 lisi
zadd board 96 wangwu
zadd board 63 zhaoliu
zrevrange board 0 3 // 获取排名前三 rev 改降序
zrank board zhaoliu
5. Redis的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?(往Redis写入数据怎么会没了?)
缓存基于内存,内存有限,写入超过内存容量,肯定有数据失效。要么设置过期时间,要么被redis干掉。
设置过期时间:
如果设置一批key只能存活1个小时,1个消息后,redis是怎么对这批数据进行删除的?
redis过期策略是:定期删除 + 惰性删除。
定期删除:随机抽取一些过期key来检查和删除。
为什么?如果很多key,10W个key设了过期时间,每隔几百毫秒,去检查,会造成高CPU负载。所以实际上redis时随机抽取key来删除。
惰性删除:并不是key到时间就被删除,而是过期后查询这个key时,redis查询下这key过期了,删除。不会返回值。
数据明明过期了,怎么还占用着内存?
但是实际上这还是有问题的,如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?
如果大量过期 key 堆积在内存里,导致 redis 内存块耗尽了,咋整?
解决方案是:走内存淘汰机制。
内存淘汰机制:
Redis内存淘汰机制如下:
- noeviction: 当内存不足时,新写入操作会报错。 (不会用)
- allkeys-lru:当内存不足时,移除最近最少使用的 key(最常用的)。
- allkeys-random:当内存不足时,随机删除。
- volatile-lru:当内存不足时,设置了过期时间的键中,移除最近最少使用的 key(这个一般不太合适)。
- volatile-random:当内存不足时,设置了过期时间的key中,随机移除某个 key。
- volatile-ttl:当内存不足时,设置了过期时间的key中,有更早过期时间的 key 优先移除。
手写一个 LRU(Least Recent Used) 算法:
利用JDK实现一个Java版LRU.
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE; // 传递进来最多能缓存多少数据
public LRUCache(int cacheSize) {
// 设置一个hashmap的初始大小
// true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > CACHE_SIZE;
}
}
用到的LinkedHashMap的构造函数:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
{
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
参数说明:
initialCapacity: 初始容量大小,使用无参构造方法时,此值默认是16
loadFactor: 负载因子,使用无参构造方法时,此值默认是 0.75f
accessOrder: false: 基于插入顺序 true: 基于访问顺序
重点看看accessOrder的作用,使用无参构造方法时,此值默认是false。
accessOrder = true: 基于访问的顺序,get一个元素后,这个元素被加到最后(使用了LRU 最近最少被使用的调度算法)
6. 如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么?
Redis实现高并发:
主从架构,一主多从,读写分离,主节点负责写,将数据同步到其他从节点,从节点负责读。
好处:轻松水平扩容,支撑高并发。

Redis Replication 的核心机制:
Master节点异步复制到Slave节点。
注意点:1. Master节点必须使用持久化。
2. Master的各种备份方案。如从备份中挑一份RDB去恢复Master,才能确保Master启动时,是有数据的。
Redis 主从复制的核心原理:
Slave第一次连Master, 发送PSYNC给Master, 触发full resynchronization全量复制。
Master生产快照RDB文件,同时在内存缓存最新数据(从客户端接收最新写命令),发送RDB给Slave。
Slave先把RDB写磁盘,再加载到内存。然后Master再把内存中缓存的写命令发到Slave,Slave再同步这些写命令。
如果Slave与Master因网络原因断开后,再连接时,Master只会发缺少的部分数据到Slave。
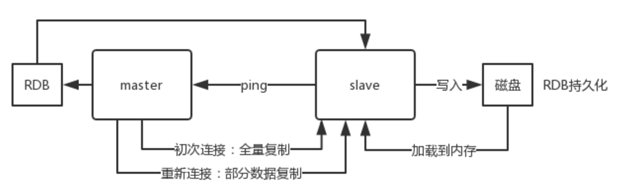
主从复制的断点续传:
master内存中维护一个backlog,master和slave都有一个replica offset,还有一个master run id.
master run id:是一个节点的唯一id, Host + IP有可能能变更。
如果连接断开,再连上后slave就从上次replica offset开始复制,如果没有找到,就全量复制。
无磁盘化复制:
master在内存中创建RDB,不写磁盘,发给Slave。
repl-diskless-sync yes
# 等待 5s 后再开始复制,因为要等更多 slave 重新连接过来
repl-diskless-sync-delay 5
复制的流程:
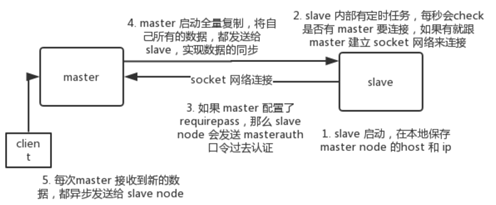
全量复制:
如果在复制期间,内存缓冲区持续消耗超过 64MB,或者一次性超过 256MB,那么停止复制,复制失败。
client-output-buffer-limit slave 256MB 64MB 60
heartbeat:
master默认每隔10秒发送一次heartbeat,slave每隔1秒发送一个 heartbeat。
Redis如何做到高可用:
redis的高可用架构,叫做failover故障转移,也可以叫做主备切换。
master在故障时,自动检测,并且将某个slave自动切换为master的过程,叫做主备切换。
Redis高可用,做主从架构,加上哨兵机制,实现主备切换。
Redis 哨兵集群实现高可用:
sentinel(哨兵)主要功能:
- 集群监控:监控master和slave进程是否正常
- 消息通知:实例有故障时,发送消息给管理员
- 故障转移:master挂了,自动转移到slave
- 配置中心:如果故障转移,通知客户端新的master地址
哨兵至少需要 3 个实例,来保证自己的健壮性。
经典的 3 节点哨兵集群:
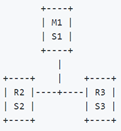
配置 quorum=2,如果 M1 所在机器宕机了,那么三个哨兵还剩下 2 个,S2 和 S3 可以一致认为 master 宕机了,然后选举出一个来执行故障转移,同时3个哨兵的majority是2,所以还剩下的2个哨兵运行着,就可以允许执行故障转移。
redis 哨兵主备切换的数据丢失问题:
两种情况和导致数据丢失:
1. 异步复制导致的数据丢失
有部分数据还没有来得及复制到slave,master就挂了,这部分数据就丢失。
2. 脑裂导致的数据丢失
脑裂,指某个master突然脱离正常网络,无法与其他slave连接,但master还在运行,
此时哨兵认为master挂了,开启选举,将其他slave选为master。这个时候集群内有2个mster, 就叫脑裂。
此时,客户端会向旧master写数据,当旧master恢复成一个新的slave挂到新master时,新master并没有这段时间数据,就丢失了。
数据丢失问题的解决方案:
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有 1 个 slave(min-slaves-to-write),数据复制和同步的延迟不能超过 10 秒,如果超过了,master不再接收请求。
有了 min-slaves-max-lag 这个配置,减少异步复制数据的丢失量。
如果不能继续给指定数量slave发送数据,且slave超过10秒没有给自己发ack,则拒绝客户端写请求,最多丢10秒数据。
sdown 和 odown 转换机制:
sdown 是主观宕机,就一个哨兵如果自己觉得一个 master 宕机了,那么就是主观宕机。
odown 是客观宕机,如果 quorum 数量的哨兵都觉得一个 master 宕机了,那么就是客观宕机。
sdown: 如果一个哨兵 ping 一个 master,超过了 is-master-down-after-milliseconds 指定的毫秒数之后,就主观认为 master 宕机了
哨兵集群的自动发现机制:
哨兵之前通过Redis的pub/sub实现互相发现。每隔两秒,每个哨兵会往自己监控的master+slave对应的__sentinel__:hello这个channel里发送消息,
消息包括自己的host,ip, run id还有对master的监控配置。每个哨兵都监听自己监控的channel, 消费其他哨兵的消息,感知其他哨兵的存在。
slave 配置的自动纠正:
当一个slave成为master时,哨兵确保其余slave连接到新的master上。
slave -> master选举算法:
slave选举考虑因素:
跟master断开连接的时长,slave优先级,复制数据的offset,run id
如果一个 slave 跟 master 断开连接的时间已经超过了 down-after-milliseconds 的 10 倍,外加 master 宕机的时长,那么 slave 就被认为不适合选举为 master。
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
选举排序:
1. slave priority越低,优先级越高。默认配置中slave-priority=100
2. slave priority相同时,看replica offset,哪个复制的数据多,offset靠后,优先级高
3. 以上相同时,选run id小的slave
quorum和majority:
哨兵主备切换时,需要quorum数量的哨兵认为sdown(主观down),才能转换为odown。
这个时候选一个哨兵来做切换,这个哨兵还需要得到majority哨兵的授权,才能正式执行切换。
configuration epoch(version):
哨兵会对一套redis的 master + slave 进行监控,有相应的监控配置。
执行切换的哨兵,会从新master(slave->master)得到一个configuration epoch,是一个version号,每次切换的version号必须唯一。
如果选举出的哨兵进行切换失败,则其他哨兵等待failover-timeout时间后,接替做切换,重新获取一个新的configuration epoch作为新的version。
configuration传播:
哨兵完成切换后,在自己本地更新生成最新master配置,然后通过hello channel同步给其他哨兵。
新的master配置是跟着新的version号,其他哨兵都是根据版本号的大小来更新自己的master配置。
Part1总结:
redis高并发:主从架构,一主多从,一般项目足够,一主写入数据,单机几W的QPS,多从用来查询数据,多个实例可以提供10W的QPS。
比如Redis主只有8G内存,其实最多只能容纳8G的数据量。如果要容量的数据量更大,就需要redis集群,用集群后可以提供每秒几十万的读写并发。
redis高可用:如果主从架构,加上哨兵集群就可以实现。一个实例宕机,自动进行主备切换。
[Java复习] 缓存Cache part1的更多相关文章
- [Java复习] 缓存Cache part2
7. Redis持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的? 为什么要持久化? 如果只是存在内存里,如果redis宕机再重启,内存数据就丢失了,所以要用持久化机 ...
- Java 中常用缓存Cache机制的实现
所谓缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例.这样做可以减少系统开销,提高系统效率. 所谓缓存,就是将程序或系统经常要调用的对象存在内存中 ...
- Java 中常用缓存Cache机制的实现《二》
所谓缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例.这样做可以减少系统开销,提高系统效率. AD: Cache 所谓缓存,就是将程序或系统经常要 ...
- Java中常用缓存Cache机制的实现
缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例. 这样做可以减少系统开销,提高系统效率. 缓存主要可分为二大类: 一.通过文件缓存,顾名思义文件 ...
- Java中经常使用缓存Cache机制的实现
缓存,就是将程序或系统常常要调用的对象存在内存中,一遍其使用时能够高速调用,不必再去创建新的反复的实例. 这样做能够降低系统开销.提高系统效率. 缓存主要可分为二大类: 一.通过文件缓存,顾名思义文件 ...
- 5个强大的Java分布式缓存框架推荐
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的 缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了 ...
- java 复习001
java 复习001 比较随意的记录下我的java复习笔记 ArrayList 内存扩展方法 分配一片更大的内存空间,复制原有的数据到新的内存中,让引用指向新的内存地址 ArrayList在内存不够时 ...
- java 开源缓存框架--转载
原文地址:http://www.open-open.com/13.htm JBossCache/TreeCache JBossCache是一个复制的事务处理缓存,它允许你缓存企业级应用数据来更好的 ...
- Java分布式缓存框架
http://developer.51cto.com/art/201411/457423.htm 在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓 ...
随机推荐
- SVN安装配置教程
第一步:安装Apache LInux centos6.5 (备注:为了方便可以把linux防火墙关掉,这样就不需要一个一个开端口了,建议开发测试可以这样,正式环境不推荐) 第二步:安装SVN服 ...
- Codeforces #366 Div. 2 C. Thor (模拟
http://codeforces.com/contest/705/problem/C 题目 模拟题 : 设的方法采用一个 r 数组(第几个app已经阅读过的消息的数量),和app数组(第几个app发 ...
- linux网络编程之socket编程(十)
今天继续socket编程的学习,最近晚上睡觉都没有发热,没有暖气的日子还是种煎熬,快乐的十一也已经走来,幸福有暖气的日子也快啦,好了,回到正题~ ①close终止了数据传送的两个方向. ②shutdo ...
- linux网络编程之system v消息队列(二)
今天继续学习system v消息队列,主要是学习两个函数的使用,开始进入正题: 下面则开始用代码来使用一下该发送函数: 在运行之前,先查看一下1234消息队列是否已经创建: 用上次编写的查看消息队列状 ...
- ngtos 天融信
NGFW系列产品基于天融信公司10年高品质安全产品开发经验结晶的NGTOS系统架构,采用了多项突破性技术.基于分层的设计思想,天融信公司通过长期的安全产品研发经验,分析多种安全硬件平台技术的差异,创造 ...
- Python离线断网情况下安装numpy、pandas和matplotlib等常用第三方包
联网情况下在命令终端CMD中输入“pip install numpy”即可自动安装,pandas和matplotlib同理一样方法进行自动安装. 工作的电脑不能上外网,所以不能通过直接输入pip命令来 ...
- JavaScript 弹出窗口总结
1: window.open <!-- window.open('page.html', 'newwindow', 'height=100, width=400, top=0,left=0, t ...
- CSP2019 D1T3 树上的数 (贪心+并查集)
题解 因为博主退役了,所以题解咕掉了.先放个代码 CODE #include<bits/stdc++.h> using namespace std; const int MAXN = 20 ...
- centos7安装docker-compose
安装docker # 安装依赖 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # 添加docker下载仓库 sudo ...
- eclipse/myeclipse SVN资源库URL中文乱码问题解决办法
右击选择资源库地址 可以自定义名称