zookeeper源码 — 三、集群启动—leader、follower同步
zookeeper集群启动的时候,首先读取配置,接着开始选举,选举完成以后,每个server根据选举的结果设置自己的角色,角色设置完成后leader需要和所有的follower同步。上面一篇介绍了leader选举过程,这篇接着介绍启动过程中的leader和follower同步过程。
本文结构如下:
- 同步过程
- 总结
同步过程
设置server当前状态
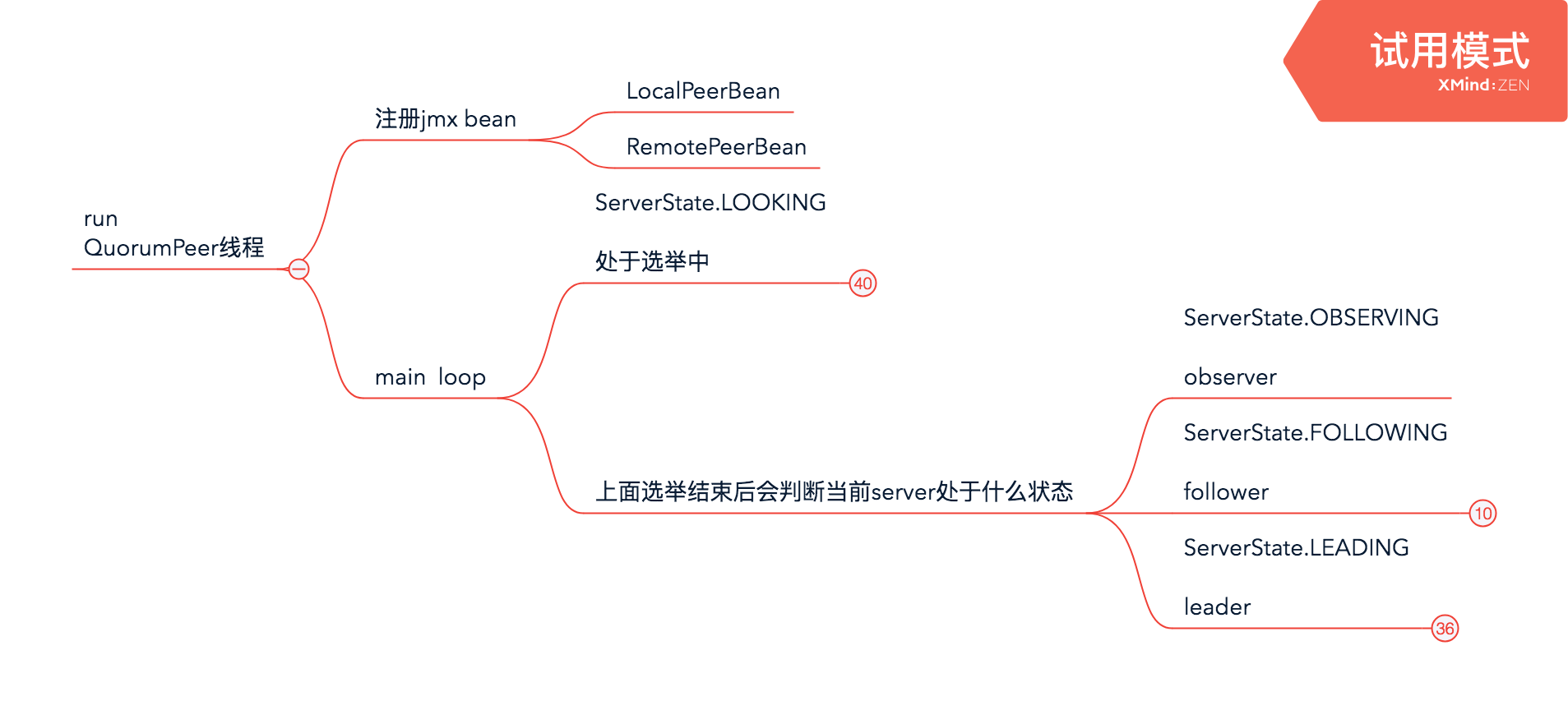
server刚启动的时候都处于LOOKING状态,选举完成后根据选举结果和对应配置进入对应的状态,设置状态的方法是:
private void setPeerState(long proposedLeader, SyncedLearnerTracker voteSet) {
ServerState ss = (proposedLeader == self.getId()) ?
ServerState.LEADING: learningState();
self.setPeerState(ss);
if (ss == ServerState.LEADING) {
leadingVoteSet = voteSet;
}
}
- 如果当前server.myId等于选举出的leader的myId——也就是proposedLeader,则当前server就是leader,设置peerState为ServerState.LEADING
- 否则判断当前server的具体角色,因为follower和observer都是learner,需要根据各自的配置来决定该server的状态(配置文件里面的key是peerType,可选的值是participant、observer,如果不配置learnerType默认是LearnerType.PARTICIPANT)
- 如果配置的learnerType是LearnerType.PARTICIPANT,则状态为ServerState.FOLLOWING
- 否则,状态为ServerState.OBSERVING
准备同步
leader开始工作的入口就是leader.lead方法,这里的leader是Leader的实例,如下图所示
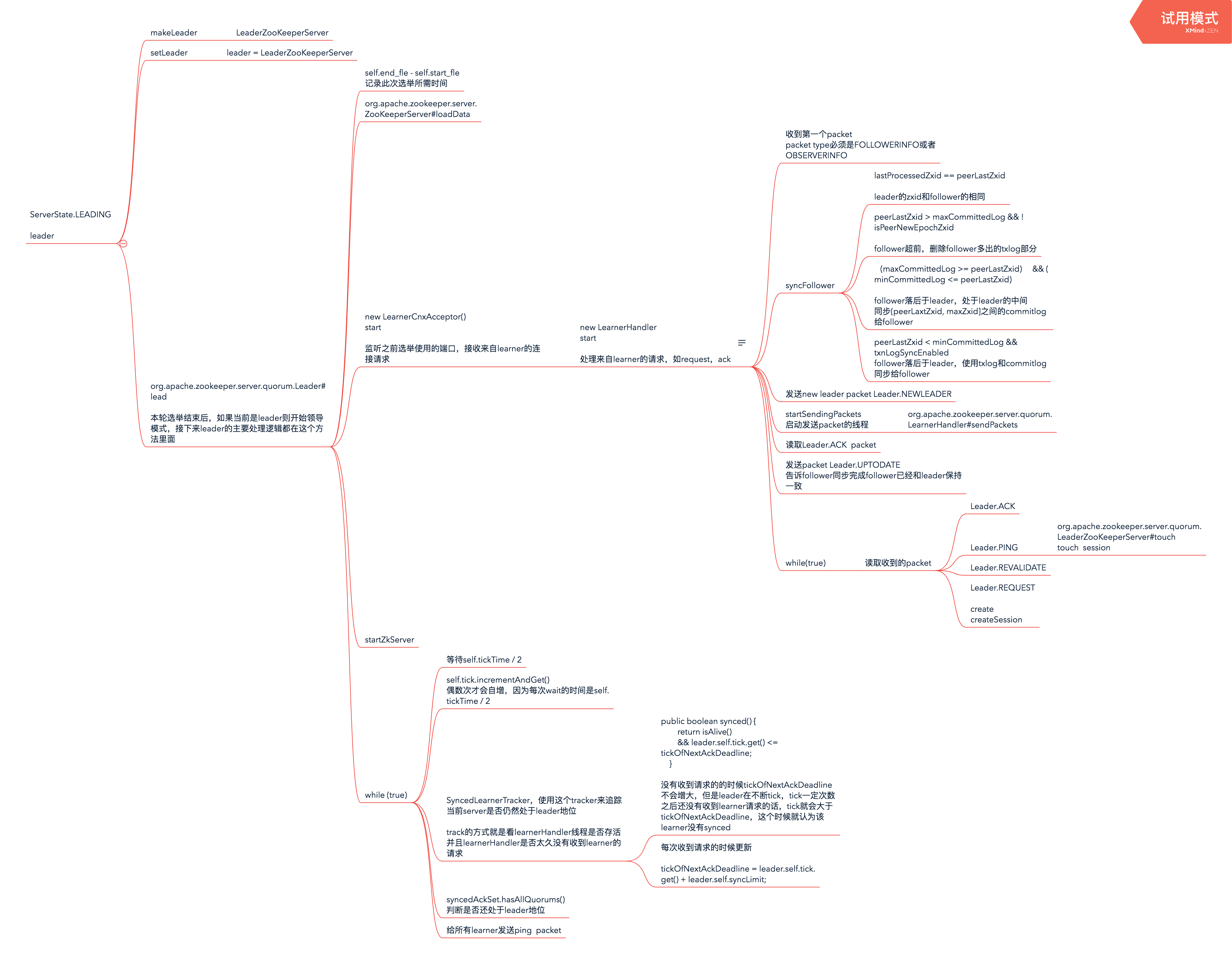
准备的过程是:
- 创建leader的实例,Leader,构造方法中传入LeaderZooKeeperServer的实例
- 调用leader.lead
- 加载ZKDatabase
- 监听指定的端口(配置的用来监听learner连接请求的端口,配置的第一个冒号后的端口),接收来自follower的请求
- while循环,检查当前选举的状态是否发生变化需要重新进行选举
同时,follower设置完自己的状态后,也开始进行类似leader的工作
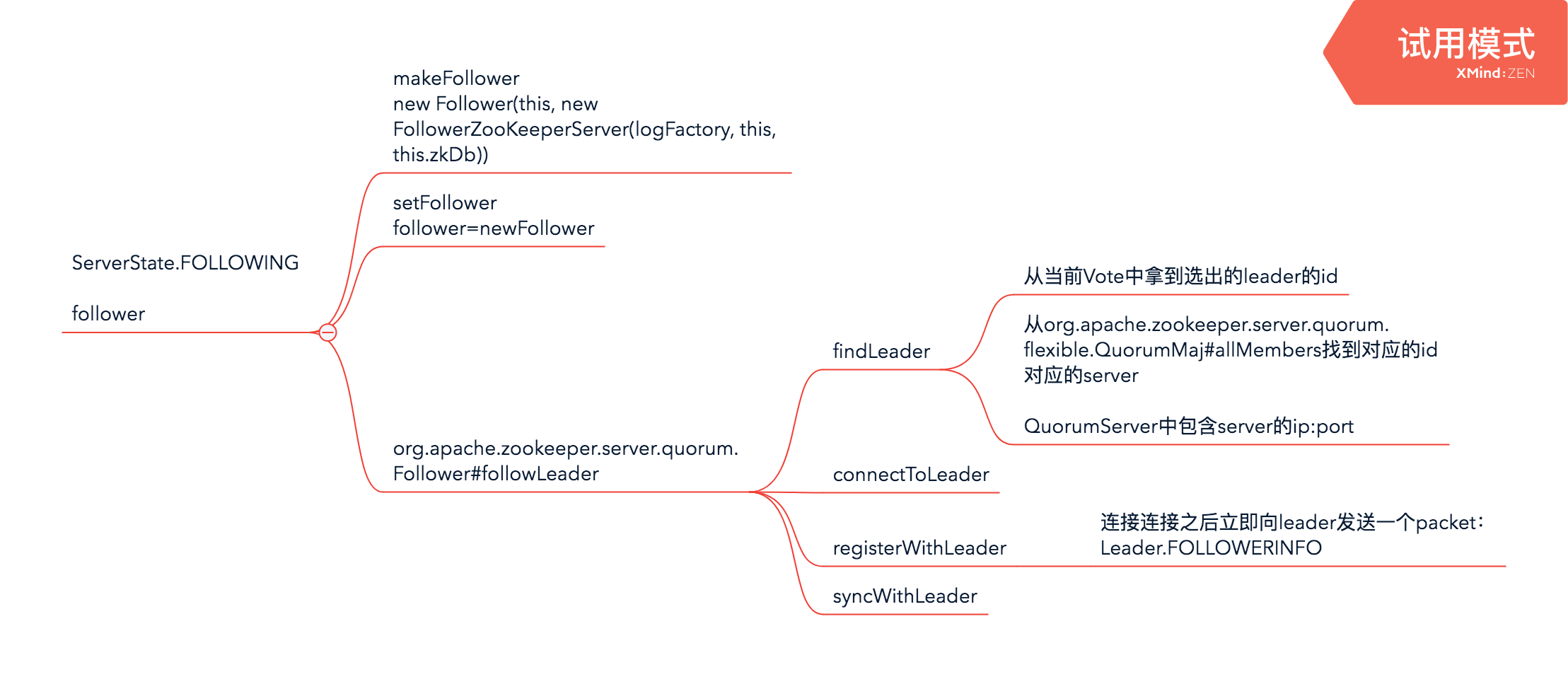
- 创建follower,也就是Follower的实例,同时创建FollowerZooKeeperServer
- 建立和leader的连接
进行同步
同步的总体过程如下:
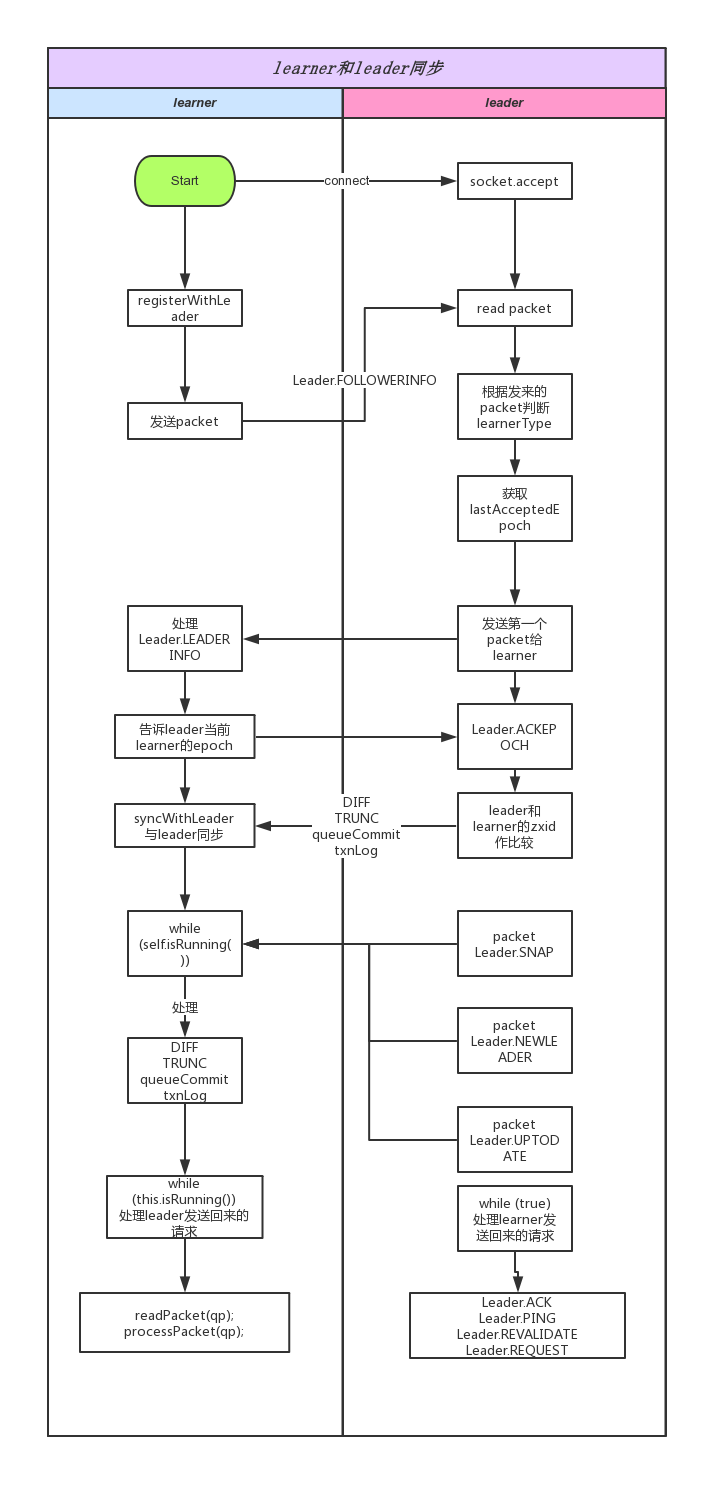
在准备阶段完成follower连接到leader,具备通信状态
- leader阻塞等待follower发来的第一个packet
- 校验packet类型是否是Leader.FOLLOWERINFO或者Leader.OBSERVERINFO
- 读取learner信息
- sid
- protocolVersion
- 校验follower的version不能比leader的version还要新
- leader发送packet(Leader.LEADERINFO)给follower
- follower收到Leader.LEADERINFO后给leader回复Leader.ACKEPOCH
- leader根据follower ack的packet内容来决定同步的策略
- lastProcessedZxid == peerLastZxid,leader的zxid和follower的相同
- peerLastZxid > maxCommittedLog && !isPeerNewEpochZxid follower超前,删除follower多出的txlog部分
- (maxCommittedLog >= peerLastZxid) && (minCommittedLog <= peerLastZxid) follower落后于leader,处于leader的中间 同步(peerLaxtZxid, maxZxid]之间的commitlog给follower
- peerLastZxid < minCommittedLog && txnLogSyncEnabled follower落后于leader,使用txlog和commitlog同步给follower
- 接下来leader会不断的发送packet给follower,follower处理leader发来的每个packet
- 同步完成后follower回复ack给leader
- leader、follower进入正式处理客户端请求的while循环
总结
zookeeper为了保证启动后leader和follower的数据一致,在启动的时候就进行数据同步,leader与follower数据传输的端口和leader选举的端口不一样。数据同步完成后就可以接受client的请求进行处理了。
zookeeper源码 — 三、集群启动—leader、follower同步的更多相关文章
- Dubbo 源码分析 - 集群容错之 LoadBalance
1.简介 LoadBalance 中文意思为负载均衡,它的职责是将网络请求,或者其他形式的负载"均摊"到不同的机器上.避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况.通 ...
- Dubbo 源码分析 - 集群容错之 Cluster
1.简介 为了避免单点故障,现在的应用至少会部署在两台服务器上.对于一些负载比较高的服务,会部署更多台服务器.这样,同一环境下的服务提供者数量会大于1.对于服务消费者来说,同一环境下出现了多个服务提供 ...
- Dubbo 源码分析 - 集群容错之 Router
1. 简介 上一篇文章分析了集群容错的第一部分 -- 服务目录 Directory.服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由.上一篇文章关于服务路由相关逻辑没有 ...
- zookeeper源码 — 二、集群启动—leader选举
上一篇介绍了zookeeper的单机启动,集群模式下启动和单机启动有相似的地方,但是也有各自的特点.集群模式的配置方式和单机模式也是不一样的,这一篇主要包含以下内容: 概念介绍:角色,服务器状态 服务 ...
- zookeeper源码 — 一、单机启动
zookeeper一般使用命令工具启动,启动主要就是初始化所有组件,让server可以接收并处理来自client的请求.本文主要结构: main入口 配置解析 组件启动 main入口 我们一般使用命令 ...
- Dubbo 源码分析 - 集群容错之 Directory
1. 简介 前面文章分析了服务的导出与引用过程,从本篇文章开始,我将开始分析 Dubbo 集群容错方面的源码.这部分源码包含四个部分,分别是服务目录 Directory.服务路由 Router.集群 ...
- Dubbo源码学习--集群负载均衡算法的实现
相关文章: Dubbo源码学习文章目录 前言 Dubbo 的定位是分布式服务框架,为了避免单点压力过大,服务的提供者通常部署多台,如何从服务提供者集群中选取一个进行调用, 就依赖Dubbo的负载均衡策 ...
- Dubbo源码(七) - 集群
前言 本文基于Dubbo2.6.x版本,中文注释版源码已上传github:xiaoguyu/dubbo 集群(cluster)就是一组计算机,它们作为一个总体向用户提供一组网络资源.这些单个的计算机系 ...
- dubbo源码分析- 集群容错之Cluster(一)
1.集群容错的配置项 failover - 失败自动切换,当出现失败,重试其他服务器(缺省),通常用于读操作,但重试会带来更长的延时. failfast - 快速失效,只发起一次调用,失败立即报错.通 ...
随机推荐
- 关于NSOperationQueue,一个容易让初学者误解的问题
凡是学习NSOperationQueue的人,都会遇到setMaxConcurrentOperationCount这个函数.在网上的许多博文中,都将setMaxConcurrentOperationC ...
- 有选择性的启用SAP UI5调试版本的源代码
在低版本的SAP UI5应用中,我们一旦切换成调试模式,那么应用程序源代码和UI5框架程序的源代码的调试版本都会重新加载,耗时很长. 我最近发现UI5新版本1.66.1提供了选择性加载调试版本的源代码 ...
- HashMap、HashTable差异详解
HashMap和HashTable有什么不同?在面试和被面试的过程中,我问过也被问过这个问题,也见过了不少回答,今天决定写一写自己心目中的理想答案. 代码版本 JDK每一版本都在改进.本文讨论的Has ...
- [daily]使用iptables配置NAT的命令速查
时常,快速的配置一个临时的NAT环境是很常用需求. 但是,每次我都要读iptables的手册,才能配出来.所以,备忘一个速查. DNAT: iptables -t nat -A PREROUTING ...
- IT基础架构
- github release 文件下载贼慢,干脆失败的解决方法
链接:Free Download Manager 5提取码:4194 Free Download Manager 下载工具可以解决Github 下载缓慢或失败问题,至少能加快下载速度. 如果嫌百度网盘 ...
- Python内存数据序列化到硬盘上哪家强
1. 闲扯一下:文件 磁盘上的数据,我们一般称为 “文件” ,一般不同的文件都有各自的后缀名,比如 .txt .docx .xlsx .jpg .mp3 .avi .这些不同类型的文件一般分为两大类: ...
- Linux学习笔记(八)Linux常用命令:用户登录查看命令
一.查看登录用户信息 w [用户名] 二.Who who 三.查询当前登录和过去登陆的用户信息 last 四.查看所有用户最后一次登录时间 lastlog
- HttpClient获取数据
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议 ...
- Spring整合rabbitmq(转载)
原文地址:https://my.oschina.net/never/blog/140368 1.首先是生产者配置 <?xml version="1.0" encoding=& ...