MapReduce shuffle的过程分析
shuffle阶段其实就是多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
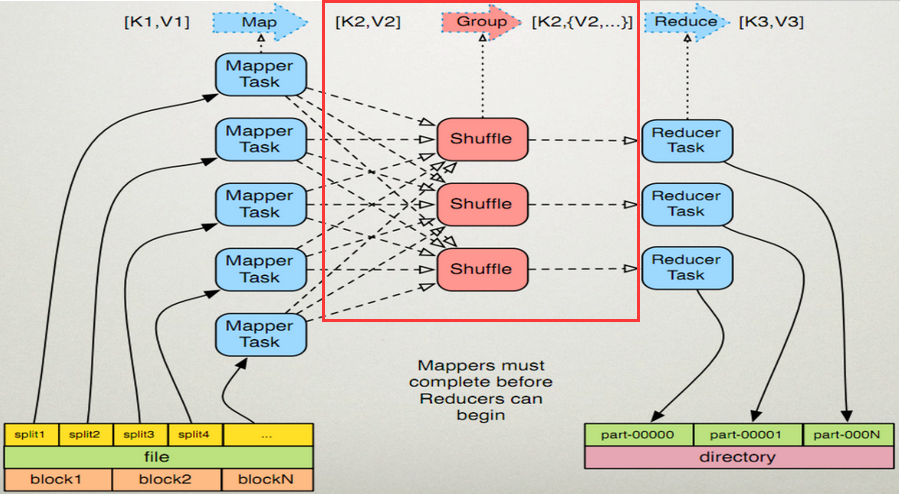

Map端:
1、在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。(注意:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。)
2、写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
3、最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Reduce端:
1、Copy阶段:Reducer通过Http方式得到输出文件的分区。reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
2、Merge阶段:如果形成多个磁盘文件会进行合并从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
3、Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。)
MapReduce shuffle的过程分析的更多相关文章
- shuffle的过程分析
shuffle的过程分析 shuffle阶段其实就是之前<MapReduce的原理及执行过程>中的步骤2.1.多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点 ...
- MapReduce Shuffle过程
MapReduce Shuffle 过程详解 一.MapReduce Shuffle过程 1. Map Shuffle过程 2. Reduce Shuffle过程 二.Map Shuffle过程 1. ...
- hadoop2.0安装中遇到的错误:mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid
转:http://blog.csdn.net/bamuta/article/details/12995139 解决办法 : 在1个网站上找到了解决方法,(网络忘了没记)urg, my copy/pas ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- 大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle
Shuffle本意是 混洗, 洗牌的意思, 在MapReduce过程中需要各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为Shuffle. 在Ha ...
- MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle简介 Shuffle的本意是洗牌.混洗的意思,把一组有规则的数据尽量打乱成无规则的数据.而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规 ...
随机推荐
- flex应用实例
代码如下: <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" c ...
- vue组件间的传值方式及方法调用汇总
1.传值 a.父组件传子组件 方法一: 父页面: <myReportContent v-if="contentState==1" :paramsProps='paramsPr ...
- vue中用div的contenteditable属性实现v-for遍历,双向数据绑定的动态表格编辑
1.HTML部分 <tr v-for="(item,index) in customerVisitList2" :key="index"> < ...
- 1249: 人见人爱A^B
题目描述 求A^B的最后三位数表示的整数. 说明:A^B的含义是“A的B次方” 输入 输入数据包含多个测试实例,每个实例占一行,由两个正整数A和B组成(1<=A,B<=10000),如果 ...
- Linux服务器TIME_WAIT进程的解决与原因
linux服务器上tcp有大量time_wait状态的解决方法和原因解释 毫无疑问,TCP中有关网络编程最不容易理解的是它的TIME_WAIT状态,TIME_WAIT状态存在于主动关闭socket连接 ...
- C#当中的BeginInvoke和EndInvoke
我们已经知道 C#当中 存在async/await .BackGroudWorker类以及TPL(任务并行库).当然C#还有一些旧的模式来支持异步编程.参考<C#图解教程> 1. Beg ...
- string::clear
void clear() noexcept;功能:把string对象置为空 #include <iostream>#include <string> using namespa ...
- 基于JQ的记忆翻牌游戏
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- 遍历windows窗口
原文 1. GetDesktopWindow GetNextWindow HWND hAll = ::GetDesktopWindow(); HWND hCurrent = ::GetNextWind ...
- 双向绑定v-bind
通过v-model绑定输出数据 <script> export default { data() { return { pagestyle:'https://v4.bootcss.com/ ...