图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析
1. 深度优先遍历
深度优先遍历(Depth First Search)的主要思想是:
1、首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;
2、当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。
在此我想用一句话来形容 “不到南墙不回头”。
1.1 无向图的深度优先遍历图解
以下"无向图"为例:
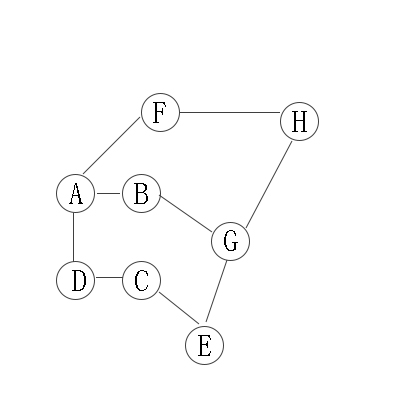
对上无向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问B(A的邻接点)。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"B,D,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"D和F"的前面,因此,先访问B。
第3步:访问G(B的邻接点)。 和B相连只有"G"(A已经访问过了)
第4步:访问E(G的邻接点)。 在第3步访问了B的邻接点G之后,接下来应该访问G的邻接点,即"E和H"中一个(B已经被访问过,就不算在内)。而由于E在H之前,先访问E。
第5步:访问C(E的邻接点)。 和E相连只有"C"(G已经访问过了)。
第6步:访问D(C的邻接点)。
第7步:访问H。因为D没有未被访问的邻接点;因此,一直回溯到访问G的另一个邻接点H。
第8步:访问(H的邻接点)F。
因此访问顺序是:A -> B -> G -> E -> C -> D -> H -> F
1.2 有向图的深度优先遍历
有向图的深度优先遍历图解:
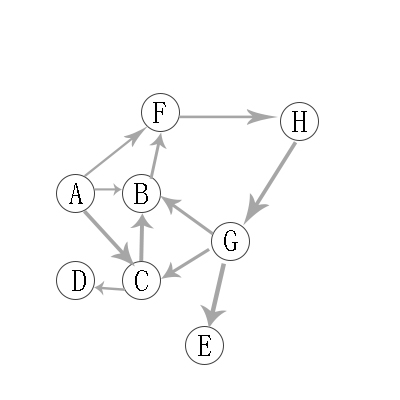
对上有向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问(A的出度对应的字母)B。 在第1步访问A之后,接下来应该访问的是A的出度对应字母,即"B,C,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"C和F"的前面,因此,先访问B。
第3步:访问(B的出度对应的字母)F。 B的出度对应字母只有F。
第4步:访问H(F的出度对应的字母)。 F的出度对应字母只有H。
第5步:访问(H的出度对应的字母)G。
第6步:访问(G的出度对应字母)E。 在第5步访问G之后,接下来应该访问的是G的出度对应字母,即"B,C,E"中的一个。但在本文的实现中,顶点B已经访问了,由于C在E前面,所以先访问C。
第7步:访问(C的出度对应的字母)D。
第8步:访问(C的出度对应字母)D。 在第7步访问C之后,接下来应该访问的是C的出度对应字母,即"B,D"中的一个。但在本文的实现中,顶点B已经访问了,所以访问D。
第9步:访问E。D无出度,所以一直回溯到G对应的另一个出度E。
因此访问顺序是:A -> B -> F -> H -> G -> C -> D -> E
2.广度优先遍历
广度优先遍历(Depth First Search)的主要思想是:类似于树的层序遍历。
2.1 无向图的广度优先遍历图解:
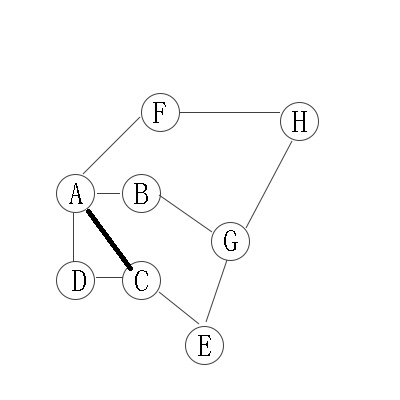
从A开始,有4个邻接点,“B,C,D,F”,这是第二层;
在分别从B,C,D,F开始找他们的邻接点,为第三层。以此类推。
因此访问顺序是:A -> B -> C -> D -> F -> G -> E -> H
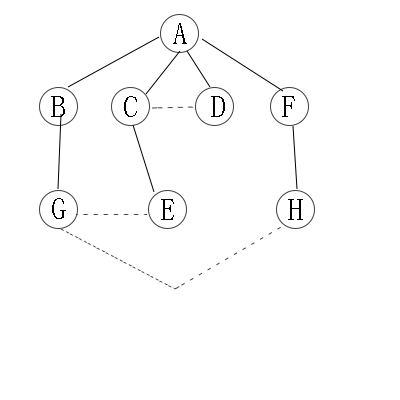
2.2 有向图的广度优先遍历图解:
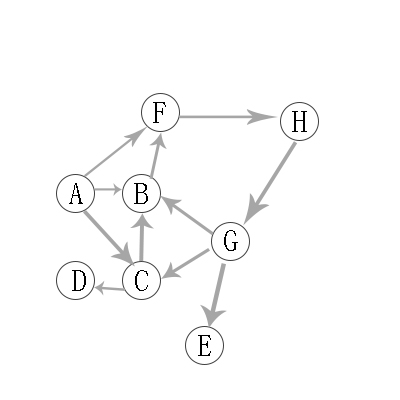
与无向图类似 。可以参考。
因此访问顺序是:A -> B -> C -> F -> D -> H -> E -> G
没有贴代码,需要可以给博主私哦。
PS:打字不易,转载请说明出处。
图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析的更多相关文章
- 图的深度优先搜索(DFS)和广度优先搜索(BFS)算法
深度优先(DFS) 深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- 图的 储存 深度优先(DFS)广度优先(BFS)遍历
图遍历的概念: 从图中某顶点出发访遍图中每个顶点,且每个顶点仅访问一次,此过程称为图的遍历(Traversing Graph).图的遍历算法是求解图的连通性问题.拓扑排序和求关键路径等算法的基础.图的 ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 深度优先搜索DFS和广度优先搜索BFS
DFS简介 深度优先搜索,一般会设置一个数组visited记录每个顶点的访问状态,初始状态图中所有顶点均未被访问,从某个未被访问过的顶点开始按照某个原则一直往深处访问,访问的过程中随时更新数组visi ...
- 图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次.(连通图与非连通图) 深度优先遍历(DFS): 1.访问指定的起始顶点: 2.若当前访问的顶点的邻接顶点有未被访问的,则 ...
- 【C++】基于邻接矩阵的图的深度优先遍历(DFS)和广度优先遍历(BFS)
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...
- 图的深度优先搜索dfs
图的深度优先搜索: 1.将最初访问的顶点压入栈: 2.只要栈中仍有顶点,就循环进行下述操作: (1)访问栈顶部的顶点u: (2)从当前访问的顶点u 移动至顶点v 时,将v 压入栈.如果当前顶点u 不存 ...
随机推荐
- SAP Cloud Platform上Destination属性为odata_gen的具体用途
今天工作发现,SAP Cloud Platform上创建Destination维护的WebIDEUsage属性很有讲究: 帮助文档:https://help.sap.com/viewer/825270 ...
- linux c 错误的捕获
经常在调用linux 系统api 的时候会出现一些错误,比方说使用open() write() creat()之类的函数有些时候会返回-1,也就是调用失败,这个时候往往需要知道失败的原因.这个时候使用 ...
- 自适应高度文本框 react contenteditable
import React, { Component } from 'react'; import PropTypes from 'prop-types'; const reduceTargetKeys ...
- DoD与TCP/IP
DoD与TCP/IP都是协议栈. 什么是协议栈? 就是一套软件,默认安装完Windows就有,可以卸载再安装.把他卸载了,你就不能上网. 数据的封装以及解封装有网卡以及绑定的TCP/IP协议栈完成 A ...
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍
转载:https://www.cnblogs.com/lifexy/p/8485634.html 在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Uni ...
- 2.Storm集群部署及单词统计案例
1.集群部署的基本流程 2.集群部署的基础环境准备 3.Storm集群部署 4.Storm集群的进程及日志熟悉 5.Storm集群的常用操作命令 6.Storm源码下载及目录熟悉 7.Storm 单词 ...
- Linux 下DNS详解
配置之前先了解一下bind DNS服务器软件:BIND是一种开源的DNS(Domain Name System)协议的实现,包含对域名的查询和响应所需的所有软件.它是互联网上最广泛使用的一种DNS服务 ...
- ORACLE归档日志满了之后,如何删除归档日志
当ORACLE归档日志满后如何正确删除归档日志 版权声明:本文为博主原创文章,未经博主允许不得转载. 当ORACLE 归档日志满了后,将无法正常登入ORACLE,需要删除一部分归档日志才能正常登入OR ...
- ggplot2绘制Excel所有图
出处:https://brucezhaor.github.io/blog/2016/06/13/excel2ggplot/#%E5%89%8D%E8%A8%80 目录 前言 1.用到的包 2.数据准备 ...
- Requests的基础学习
官方文档链接:http://cn.python-requests.org/zh_CN/latest/ 安装: pip install requests 错误异常: 1.所有Requests显式抛出的异 ...