Kafka性能调优分析-线上环境篇
正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

------------------------正文开始---------------------------
一、背景介绍:
在平时的开发中,使用kafka来发送数据已经非常熟悉,但是在使用的过程中,其实并没有比较深入的探索kafka使用过程中
一些参数配置,带来的损失可能就是没有充分的发挥出kfka的优势,无法很好的满足业务场景。在意识这个问题后,专门腾出
时间来总结一下kakfa参数配置的调优,以充分发挥kafka在低时延,高吞吐等不同场景下的优势。
二、通用介绍:
-------- 生产者配置 -------
常规参数设置解析:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("buffer.memory", 67108864);
props.put("batch.size", 131072);
props.put("linger.ms", 100);
props.put("max.request.size", 10485760);
props.put("acks", "1");
props.put("retries", 10);
props.put("retry.backoff.ms", 500); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
1、内存缓冲的大小:buffer.memory

首先我们看看“buffer.memory”这个参数是什么意思?
Kafka的客户端发送数据到服务器,一般都是要经过缓冲的,也就是说,你通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲
里,然后把很多消息收集成一个一个的Batch,再发送到Broker上去的。所以这个“buffer.memory”的本质就是用来约束KafkaProducer能够使用的内存缓
冲的大小的,他的默认值是32MB。那么既然了解了这个含义,大家想一下,在生产项目里,这个参数应该怎么来设置呢?你可以先想一下,如果这个内
存缓冲设置的过小的话,可能会导致一个什么问题?首先要明确一点,那就是在内存缓冲里大量的消息会缓冲在里面,形成一个一个的Batch,每个Batch
里包含多条消息。然后KafkaProducer有一个Sender线程会把多个Batch打包成一个Request发送到Kafka服务器上去。
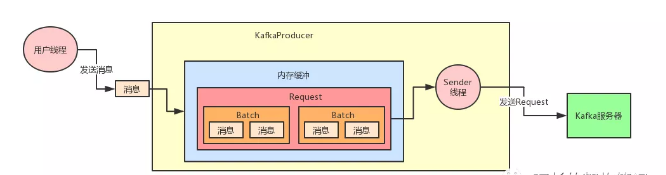
那么如果要是内存设置的太小:
可能导致一个问题:消息快速的写入内存缓冲里面,但是Sender线程来不及把Request发送到Kafka服务器。这样是不是会造成内存缓冲很快就被写满?一旦被写满,
就会阻塞用户线程,不让继续往Kafka写消息了。所以对于“buffer.memory”这个参数应该结合自己的实际情况来进行压测,你需要测算一下在生产环境,你的用户线程会
以每秒多少消息的频率来写入内存缓冲。比如说每秒300条消息,那么你就需要压测一下,假设内存缓冲就32MB,每秒写300条消息到内存缓冲,是否会经常把内存缓冲
写满?经过这样的压测,你可以调试出来一个合理的内存大小。
2、多少数据打包为一个Batch合适:batch.size
接着你需要思考第二个问题,就是你的“batch.size”应该如何设置?
这个东西是决定了你的每个Batch要存放多少数据就可以发送出去了。比如说你要是给一个Batch设置成是16KB的大小,那么里面凑够16KB的数据就可以发送了。这个参数的
默认值是16KB,一般可以尝试把这个参数调节大一些,然后利用自己的生产环境发消息的负载来测试一下。
比如说发送消息的频率就是每秒300条,那么如果比如“batch.size”调节到了32KB,或者64KB,是否可以提升发送消息的整体吞吐量。因为理论上来说,提升batch的大小,可以允许
更多的数据缓冲在里面,那么一次Request发送出去的数据量就更多了,这样吞吐量可能会有所提升。但是这个东西也不能无限的大,过于大了之后,要是数据老是缓冲在Batch里迟
迟不发送出去,那么岂不是你发送消息的延迟就会很高。比如说,一条消息进入了Batch,但是要等待5秒钟Batch才凑满了64KB,才能发送出去。那这条消息的延迟就是5秒钟。所以
需要在这里按照生产环境的发消息的速率,调节不同的Batch大小自己测试一下最终出去的吞吐量以及消息的 延迟,设置一个最合理的参数。
3、要是一个Batch迟迟无法凑满怎么办:linger.ms
要是一个Batch迟迟无法凑满,此时就需要引入另外一个参数了,“linger.ms”,他的含义就是说一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去了。
给大家举个例子,比如说batch.size是16kb,但是现在某个低峰时间段,发送消息很慢。这就导致可能Batch被创建之后,陆陆续续有消息进来,但是迟迟无法凑够16KB,难道此时就一直等着吗?
当然不是,假设你现在设置“linger.ms”是50ms,那么只要这个Batch从创建开始到现在已经过了50ms了,哪怕他还没满16KB,也要发送他出去了。所以“linger.ms”决定了你的消息一旦写入一个Batch,
最多等待这么多时间,他一定会跟着Batch一起发送出去。避免一个Batch迟迟凑不满,导致消息一直积压在内存里发送不出去的情况。这是一个很关键的参数。这个参数一般要非常慎重的来设置,
要配合batch.size一起来设置。举个例子,首先假设你的Batch是32KB,那么你得估算一下,正常情况下,一般多久会凑够一个Batch,比如正常来说可能20ms就会凑够一个Batch。
那么你的linger.ms就可以设置为25ms,也就是说,正常来说,大部分的Batch在20ms内都会凑满,但是你的linger.ms可以保证,哪怕遇到低峰时期,20ms凑不满一个Batch,还是会在25ms之后强制Batch发送出去。
如果要是你把linger.ms设置的太小了,比如说默认就是0ms,或者你设置个5ms,那可能导致你的Batch虽然设置了32KB,但是经常是还没凑够32KB的数据,5ms之后就直接强制Batch发送出去,这样也不太好其实,会导致你的Batch形同虚设,一直凑不满数据。
4、最大请求大小 :“max.request.size”
这个参数决定了每次发送给Kafka服务器请求的最大大小,同时也会限制你一条消息的最大大小也不能超过这个参数设置的值,这个其实可以根据你自己的消息的大小来灵活的调整。给大家举个例子,你们公司发送的消息都是那种大的报文消息,每条消息都是很多的数据,一条消息可能都要20KB。此时你的batch.size是不是就需要调节大一些?比如设置个512KB?然后你的buffer.memory是不是要给的大一些?比如设置个128MB?只有这样,才能让你在大消息的场景下,还能使用Batch打包多条消息的机制。但是此时“max.request.size”是不是也得同步增加?
因为可能你的一个请求是很大的,默认他是1MB,你是不是可以适当调大一些,比如调节到5MB?
5、重试机制:“retries”和“retries.backoff.ms”
“retries”和“retries.backoff.ms”决定了重试机制,也就是如果一个请求失败了可以重试几次,每次重试的间隔是多少毫秒。
这个大家适当设置几次重试的机会,给一定的重试间隔即可,比如给100ms的重试间隔。
6、确认机制:acks
此配置是表明当一次produce请求被认为完成时的确认值。特别是,多少个其他brokers必须已经提交了数据到他们的log并且向他们的leader确认了这些信息。典型的值包括:
0: 表示producer从来不等待来自broker的确认信息(和0.7一样的行为)。这个选择提供了最小的时延但同时风险最大(因为当server宕机时,数据将会丢失)。
1:表示获得leader replica已经接收了数据的确认信息。这个选择时延较小同时确保了server确认接收成功。
-1:producer会获得所有同步replicas都收到数据的确认。同时时延最大,然而,这种方式并没有完全消除丢失消息的风险,因为同步replicas的数量可能是1。如果你想确保某些replicas接收到数据,那么你应该在topic-level设置中选项min.insync.replicas设置一下。
7、min.insync.replicas:
当min.insync.replicas和acks强制更大的耐用性时。典型的情况是创建一个副本为3的topic,将min.insync.replicas设置为2,并设置acks为“all”。如果多数副本没有收到写入,这将确保生产者引发异常。
-------- 消费者配置 -------
1、fetch.min.bytes:
每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。
2、auto.commit.enable
如果为真,consumer所fetch的消息的offset将会自动的同步到zookeeper。这项提交的offset将在进程挂掉时,由新的consumer使用。
三、优化进阶篇:
------------------------------------- 优化之 --- 提升吞吐量 -----------------------------------

------------------------------------- 优化之 --- 保证低时延 -----------------------------------


---------------------------------------------------- 参数说明 ----------------------------------------------------
replica复制配置
每个follow从leader拉取消息进行同步数据,follow同步性能由这几个参数决定:
- num.replica.fetchers:拉取线程数
- replica.fetch.min.bytes:拉取最小字节数
- replica.fetch.min.bytes:拉取最大字节数
- replica.fetch.wait.max.ms:最大等待时间
优化建议
- num.replica.fetchers 配置多可以提高follower的I/O并发度,单位时间内leader持有更多请求,相应负载会增大,需要根据机器硬件资源做权衡
- replica.fetch.min.bytes=1 默认配置为1字节,否则读取消息不及时
- replica.fetch.max.bytes= 5 * 1024 * 1024 默认为1MB,这个值太小,5MB为宜,根据业务情况调整
- replica.fetch.wait.max.ms follow拉取频率,频率过高,会导致cpu飙升,因为leader无数据同步,leader会积压大量无效请求情况
压缩速度
- compression.type:压缩的速度上lz4=snappy<gzip。
有序性
- max.in.flight.requests.per.connection (affects ordering,设置为1可以保证有序性,但是发送性能会受影响。不为1的时候,如果发生消息重发则会乱序),在单个连接中,producer客户端在阻塞之前,可以允许未被确认的最大请求数,即当一个连接中未被确认的请求数超过了该设置,那么该producer客户端将会阻塞。注意:如果该值设置得比1大,当出现发送失败的情况,且
retries配置项又开启时,那么存在消息被重新排序的风险。
幂等性:enable.idempotence
重要性:低
类型:Boolean
默认值:false
是否使用幂等性。如果设置为true,表示producer将确保每一条消息都恰好有一份备份;如果设置为false,则表示producer因发送数据到broker失败重试使,可能往数据流中写入多分重试的消息。
注意:如果使用idempotence,即enable.idempotence为true,那么要求配置项max.in.flight.requests.per.connection的值必须小于或等于5;配置项retries的值必须大于0;acks配置项必须设置为all。如果这些值没有被用户明确地设置,那么系统将自动选择合适的值。如果设置 的值不合适,那么会抛出ConfigException异常。
网络和IO线程配置优化
配置参数
- num.network.threads:Broker处理消息的最大线程数
- num.io.threads:Broker处理磁盘IO的线程数
优化建议
- 一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1
- num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍.
日志保留策略配置
当kafka server的被写入海量消息后,会生成很多数据文件,且占用大量磁盘空间,如果不及时清理,可能磁盘空间不够用,kafka默认是保留7天。
优化建议
- 减少日志保留时间,建议三天或则更多时间。log.retention.hours=72
- 段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(如果文件过小,则文件数量比较多,kafka启动时是单线程扫描目录(log.dir)下所有数据文件),文件较多时性能会稍微降低。log.segment.bytes=1073741824
log数据文件刷盘策略
为了大幅度提高producer写入吞吐量,需要定期批量写文件
优化建议
- 每当producer写入10000条消息时,刷数据到磁盘。log.flush.interval.messages=10000
- 每间隔1秒钟时间,刷数据到磁盘。log.flush.interval.ms=1000
Kafka性能调优分析-线上环境篇的更多相关文章
- golang 性能调优分析工具 pprof (上)
一.golang 程序性能调优 在 golang 程序中,有哪些内容需要调试优化? 一般常规内容: cpu:程序对cpu的使用情况 - 使用时长,占比等 内存:程序对cpu的使用情况 - 使用时长,占 ...
- Kafka性能调优 - Kafka优化的方法
今天,我们将讨论Kafka Performance Tuning.在本文“Kafka性能调优”中,我们将描述在设置集群配置时需要注意的配置.此外,我们将讨论Tuning Kafka Producers ...
- golang 性能调优分析工具 pprof(下)
golang 性能调优分析工具 pprof(上)篇, 这是下篇. 四.net/http/pprof 4.1 代码例子 1 go version go1.13.9 把上面的程序例子稍微改动下,命名为 d ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- 【调优】kafka性能调优
主要优化原理和思路 kafka是一个高吞吐量分布式消息系统,并且提供了持久化.其高性能的有两个重要特点: 利用了磁盘连续读写性能远远高于随机读写的特点: 并发,将一个topic拆分多个partitio ...
- kafka性能调优(转)
原文 https://blog.csdn.net/weixin_39478115/article/details/79155287 Broker参数配置 1.网络和io操作线程配置优化 # brok ...
- MySQL性能调优与架构设计-架构篇
架构篇(1) 读书笔记 1.Scale(扩展):从数据库来看,就是让数据库能够提供更强的服务能力 ScaleOut: 是通过增加处理节点的方式来提高整体处理能力 ScaleUp: 是通过增加当前处理节 ...
- kafka性能调优
https://blog.csdn.net/u013063153/article/details/73826322
- JVM性能调优实践——JVM篇
前言 在遇到实际性能问题时,除了关注系统性能指标.还要结合应用程序的系统的日志.堆栈信息.GClog.threaddump等数据进行问题分析和定位.关于性能指标分析可以参考前一篇JVM性能调优实践-- ...
随机推荐
- Codeforces Round #455 (Div. 2) 909D. Colorful Points
题 OvO http://codeforces.com/contest/909/problem/D CF 455 div2 D CF 909D 解 算出模拟的复杂度之后就是一个很水的模拟题 把字符串按 ...
- XHTML测试题
1.XHTML 指的是? A.EXtra Hyperlinks and Text Markup Language B.EXtensible HyperText Marking Language C.E ...
- idea tomcat服务器运行打印日志到控制台是乱码解决方案
1.试过网上很多方面,给启动的时候加参数,什么-Dfile.encoding=utf8等等都没用. 2.最后是修改了tomcat-conf-logger.properties中的 我的一开始utf-8 ...
- JAVA实现四则运算的简单计算器
开发环境eclipse java neon. 今天用JAVA的swing界面程序设计制作了一个四则运算的简易计算器.代码以及截图如下: computer.java: ///////////////// ...
- java中的变量和数据类型
变量和javascript的变量含义一样 在Java中,变量分为两种:基本类型的变量和引用类型的变量.(javascript中同样是这样的) 基本数据类型 基本数据类型是CPU可以直接进行运算的类型. ...
- 第三章 python数据规整化
本章概要 1.去重 2.缺失值处理 3.清洗字符型数据的空格 4.字段抽取 去重 把数据结构中,行相同的数据只保留一行 函数语法: drop_duplicates() #导入pandas包中的read ...
- Codeforces 940 E.Cashback (单调队列,dp)
Codeforces 940 E.Cashback 题意:一组数,要分为若干个区间,每个区间长度为ki(1<=ki<=n),并且对于每个区间删去前ki/c(向下取整)个小的数(即对区间升序 ...
- 【转】mysql基础汇总
mysql基础知识语法汇总整理(二) 原文:https://www.cnblogs.com/cxx8181602/p/9525950.html 连接数据库操作 /*连接mysql*/ mysql - ...
- XXE_payload
<?php $xmlfile = file_get_contents('php://input'); $creds=simplexml_load_string($xmlfile); echo $ ...
- 获取当前页面的webview ID
代码: A页面 <script type="text/javascript"> var ws = null; mui.plusReady(function(){ ws ...