Java源码 -- LinkedList
1.1、LinkedList概述
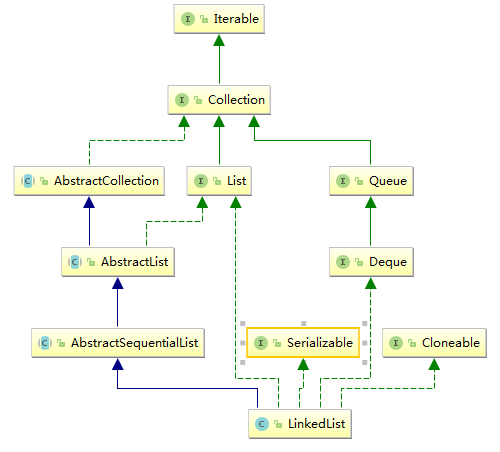
LinkedList是一种可以在任何位置进行高效地插入和移除操作的有序序列,它是基于双向链表实现的。
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
1.2、LinkedList的数据结构
1)基础知识补充
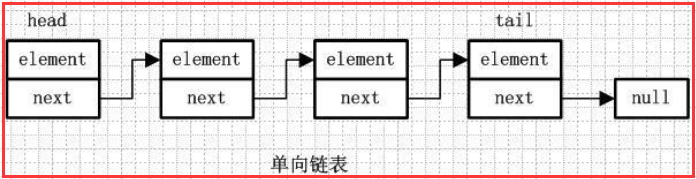
1.1)单向链表:
element:用来存放元素
next:用来指向下一个节点元素
通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
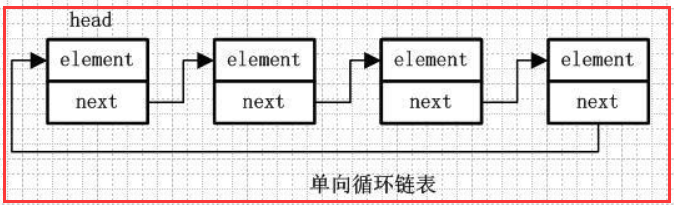
1.2)单向循环链表
element、next 跟前面一样
在单向链表的最后一个节点的next会指向头节点,而不是指向null,这样存成一个环
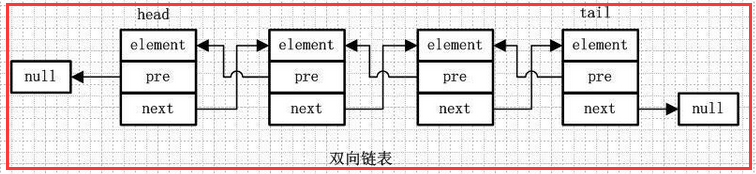
1.3)双向链表
element:存放元素
pre:用来指向前一个元素
next:指向后一个元素
双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
1.4)双向循环链表
element、pre、next 跟前面的一样
第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。
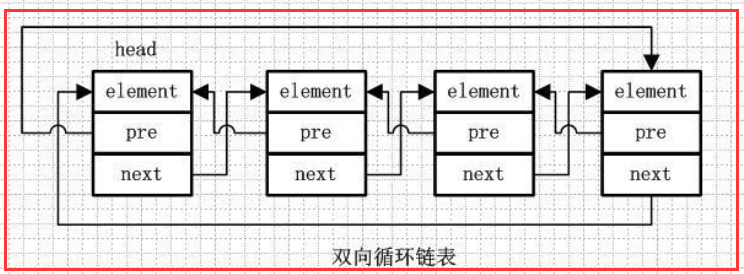
2)LinkedList的数据结构

如上图所示,LinkedList底层使用的双向链表结构,有一个头结点和一个尾结点,双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
1.3、LinkedList的特性
在我们平常中我们只知道一些常识性的特点:
1)是通过链表实现的,
2)如果在频繁的插入,或者删除数据时,就用linkedList性能会更好。
那我们通过API去查看它的一些特性
1)Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
这告诉我们,linkedList是一个双向链表,并且实现了List和Deque接口中所有的列表操作,并且能存储任何元素,包括null,
这里我们可以知道linkedList除了可以当链表使用,还可以当作队列使用,并能进行相应的操作。
2)All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
这个告诉我们,linkedList在执行任何操作的时候,都必须先遍历此列表来靠近通过index查找我们所需要的的值。通俗点讲,这就告诉了我们这个是顺序存取,
每次操作必须先按开始到结束的顺序遍历,随机存取,就是arrayList,能够通过index。随便访问其中的任意位置的数据,这就是随机列表的意思。
3)api中接下来讲的一大堆,就是说明linkedList是一个非线程安全的(异步),其中在操作Interator时,如果改变列表结构(add\delete等),会发生fail-fast。
通过API再次总结一下LinkedList的特性:
1)异步,也就是非线程安全
2)双向链表。由于实现了list和Deque接口,能够当作队列来使用。
链表:查询效率不高,但是插入和删除这种操作性能好。
3)是顺序存取结构(注意和随机存取结构两个概念搞清楚)
1.4、源码分析
属性,构造器
//实际元素个数
transient int size = 0;
//指向第一个节点的指针。
transient Node<E> first;
//指向第一个节点的指针
transient Node<E> last; //无参构造器
public LinkedList() {
}
//有参构造器
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
内部类
//linkedList的奥秘就在这里,通过Node实现双向链表
private static class Node<E> {
E item; // 数据域(当前节点的值)
Node<E> next; // 后继(指向当前一个节点的后一个节点)
Node<E> prev; // 前驱(指向当前节点的前一个节点) // 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
核心方法
linkFirst
//链接e作为第一个元素。就是让当前e元素作为链表的第一个元素
private void linkFirst(E e) {
final Node<E> f = first; //先将第一个节点赋值给新节点
final Node<E> newNode = new Node<>(null, e, f); //将e元素传入,创建一个新节点,f节点作为后继
first = newNode; //把e节点赋值给第一个节点
if (f == null) //如果第一个节点是null,则newNode 节点即是第一个也是最后一个节点
last = newNode;
else //如果不为空,则将f节点的前驱指向第一个节点newNode
f.prev = newNode;
size++; //大小自增
modCount++; //当修改时,modCount自增,防止并发异常,fail-fast
}
linkLast
//没有作用域,默认是friendly,范围是在同一个类,同一个package中
//链接e作为最后一个元素。与上面相反,将当前e元素作为链表的最后一个元素
void linkLast(E e) {
final Node<E> l = last; //先将最后一个节点赋值给新节点
final Node<E> newNode = new Node<>(l, e, null); //将e元素传入,创建一个新节点,l节点作为前驱节点
last = newNode; //把新节点赋值给最后一个节点
if (l == null) //如果最后的节点是null,则newNode 节点即是第一个也是最后一个节点
first = newNode;
else //如果不为空,l节点的后继指向最后一个节点
l.next = newNode;
size++; //大小自增
modCount++; //modCount自增
}
linkBefore
//在非空节点succ之前插入元素e
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; //将succ节点的前驱节点赋值一个新节点
final Node<E> newNode = new Node<>(pred, e, succ); //创建一个新节点,因为在succ之前,所以newNode的后继节点是succ,前驱节点是succ之前所指向的节点
succ.prev = newNode; //此时succ前驱节点就是新节点newNode
if (pred == null) //如果succ前驱节点是null,则succ是链表的第一个节点,所以newNode将是第一个节点
first = newNode;
else //如果不为null,则succ的前驱节点的后继节点即是新插入的newNode节点
pred.next = newNode;
size++; //大小自增
modCount++; //modCount自增
}
unlinkFirst
//取消非空的第一个节点f的链接。这个意思是 移除链表的第一节点
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item; //将节点元素内容拿出来
final Node<E> next = f.next; //将f节点的后继节点拿出来
f.item = null;
f.next = null; // help GC 将其清空,呼叫垃圾回收人员来干活了
first = next; //让f节点的后继节点成为第一个节点
if (next == null) //如果next节点为null,则f节点就是最后一个节点
last = null;
else //如果不为空,成为第一个节点的前驱节点即是null
next.prev = null;
size--; //大小自减
modCount++; //modCount自增
return element; //返回删除节点元素内容
}
unlinkLast
//取消非空最后一个节点l的链接。就是删除链表的最后一个节点
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item; //拿出节点内容
final Node<E> prev = l.prev; //将l的前驱节点赋值一个新节点prev
l.item = null;
l.prev = null; // help GC 呼叫垃圾回收,请求帮助
last = prev; //删除最后一个节点l后,l的前驱节点prev便是最后一个节点
if (prev == null) //若prev节点为空,则l是链表的唯一节点,所以删除当前节点,链表清空,first为null
first = null;
else //如果不为空,则prev下一个节点为null
prev.next = null;
size--;
modCount++;
return element;
}
unlink
//删除链表中的x节点
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item; //拿出节点内容
final Node<E> next = x.next; //拿出后继节点
final Node<E> prev = x.prev; //拿出前驱节点 if (prev == null) { //如果前驱节点prev为null,则x是链表的第一节点,删除后后继节点next便是第一个节点
first = next;
} else { //如果prev不为空,删除x节点后,x的前驱节点prev的后继节点就是x的后继节点next。(1、2、3 少了2, 那1后面的就是3啦)
prev.next = next;
x.prev = null;
} if (next == null) { //如果后继节点next为null,则x是链表的最后一个节点,删除后后继节点prev便是最后的节点
last = prev;
} else { //如果next不为空,删除x节点后,x的后继节点next的前驱节点就是x的前驱节点prev。(1、2、3 少了2, 那3前面的就是1啦)
next.prev = prev;
x.next = null;
} x.item = null;
size--;
modCount++;
return element;
}
增删改查方法
//返回列表中的第一个元素
public E getFirst() {
final Node<E> f = first;
if (f == null) //如果为空,抛出异常
throw new NoSuchElementException();
return f.item;
} //返回列表中最后一个元素
public E getLast() {
final Node<E> l = last;
if (l == null) //若为空,则异常
throw new NoSuchElementException();
return l.item;
} //删除链表的第一个元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f); //调用unlinkFirst方法删除
} //删除链表的最后一个元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l); //调用unLinkList方法删除
} //将元素添加到列表头部
public void addFirst(E e) {
linkFirst(e);//调用linkFirst方法添加
} //将元素添加到列表尾部
public void addLast(E e) {
linkLast(e); //调用linkLast方法添加
}
//默认将元素添加到尾部
public boolean add(E e) {
linkLast(e);
return true;
} //删除节点
public boolean remove(Object o) {
if (o == null) { //如果o为空,则找出列表为空的删除
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x); //调用unlink删除
return true;
}
}
} else { //如果o不为空,则找出删除
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x); //调用unlink删除
return true;
}
}
}
return false;
} //添加集合
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);//默认是添加链表最后
} //
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); //越界检查 Object[] a = c.toArray(); //将内容转换为数组
int numNew = a.length; //长度
if (numNew == 0) //为空便什么不用干了
return false; Node<E> pred, succ; //创建两个空节点
if (index == size) { //如果index==size 则在链表最后添加元素
succ = null;
pred = last;
} else { //如果index!=size
succ = node(index); //这个是获得index位置的节点
pred = succ.prev; //index位置节点的前置节点
} for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null); //循环数组,创建新节点
if (pred == null) //如果index位置节点的前置节点prev是null,即index是首位
first = newNode;
else
pred.next = newNode; //每一次循环的节点 是 上一节点的后继节点
pred = newNode; //更新prev节点
} if (succ == null) { //如果index位置的节点为null,则pred为最后的节点
last = pred;
} else { //将节点连接上,index位置节点的前置节点便是循环添加的最后一个节点,最后一个节点prev的后继节点便是succ节点
pred.next = succ;
succ.prev = pred;
} size += numNew; //大小更新
modCount++;
return true;
} //清空链表内容
public void clear() {
for (Node<E> x = first; x != null; ) { //循环清空后,呼叫GC
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
} //位置访问操作 //获取指定位置的内容
public E get(int index) {
checkElementIndex(index); //越界检查
return node(index).item; //调用对应方法
} //设置指定位置节点内容
public E set(int index, E element) {
checkElementIndex(index); //越界检查
Node<E> x = node(index); //获取位置节点
E oldVal = x.item;
x.item = element;
return oldVal; //返回老节点内容
} //添加节点
public void add(int index, E element) {
checkPositionIndex(index); //越界检查
//根据不同情况,选择不同添加方式:1 位置添加;2 最后位置添加
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
} //指定位置删除
public E remove(int index) {
checkElementIndex(index);//越界检查
return unlink(node(index)); //调用删除方法
}
//返回指定元素索引处的(非空)节点。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { //index在链表前面区域 size >> 1 等同于 size除以2
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { //index在链表后面区域
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
搜索操作的方法
//找出元素第一次的位置
public int indexOf(Object o) {
int index = 0; //初始位置0
if (o == null) { //元素为空。找出为空节点的位置
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++; //每次循环,位置自增
}
} else { //元素不为空。找出元素位置
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++; //每次循环,位置自增
}
}
return -1;
}
//找出元素最后一次出现的位置
public int lastIndexOf(Object o) {
int index = size; //初始位置为size,最后的位置
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
队列操作的方法
//返回链表第一个节点内容
final Node<E> f = first;
return (f == null) ? null : f.item;
} //返回链表第一个节点内容
public E element() {
return getFirst();
} //删除链表第一个节点,并返回
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
} //删除第一个节点,并返回
public E remove() {
return removeFirst();
} //在首位,添加节点
public boolean offer(E e) {
return add(e);
} // 双端队列的操作
//在首位 添加节点
public boolean offerFirst(E e) {
addFirst(e);
return true;
} //在尾部,添加节点
public boolean offerLast(E e) {
addLast(e);
return true;
} //返回第一个节点中的元素
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
} //返回最后一个节点中的元素
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
} //删除第一个节点内容,并返回
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
} //删除最后一个节点内容,并返回
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
} //在首部,添加节点
public void push(E e) {
addFirst(e);
} //删除第一个节点
public E pop() {
return removeFirst();
} //删除此列表中指定元素的第一个匹配项(在从头到尾遍历列表时)
public boolean removeFirstOccurrence(Object o) {
return remove(o);
} //删除此列表中指定元素的最后一次出现(从首尾遍历该列表时)。
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x); //调用删除方法
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x); //调用删除方法
return true;
}
}
}
return false;
}
LinkedList的迭代器
在LinkedList中除了有一个Node的内部类外,应该还能看到另外两个内部类,那就是ListItr,还有一个是DescendingIterator。
1、ListItr内部类
只继承了一个ListIterator
看到方法名之后,就发现不止有向后迭代的方法,还有向前迭代的方法,所以我们就知道了这个ListItr这个内部类干嘛用的了,就是能让linkedList不光能像后迭代,也能向前迭代。
看一下ListItr中的方法,可以发现,在迭代的过程中,还能移除、修改、添加值得操作。
2 DescendingIterator内部类

//看一下这个类,还是调用的ListItr,作用是封装一下Itr中几个方法,让使用者以正常的思维去写代码,例如,在从后往前遍历的时候,也是跟从前往后遍历一样,使用next等操作,而不用使用特殊的previous。
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
总结
1)linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构。
2)能存储null值
3)跟arrayList相比较,就真正的知道了,LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好
4)从源码中看,它不存在容量不足的情况
5)linkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值。
6)linkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口。
Java源码 -- LinkedList的更多相关文章
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- [收藏] Java源码阅读的真实体会
收藏自http://www.iteye.com/topic/1113732 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我 ...
- 如何阅读Java源码?
阅读本文大概需要 3.6 分钟. 阅读Java源码的前提条件: 1.技术基础 在阅读源码之前,我们要有一定程度的技术基础的支持. 假如你从来都没有学过Java,也没有其它编程语言的基础,上来就啃< ...
- Java源码阅读的真实体会(一种学习思路)
Java源码阅读的真实体会(一种学习思路) 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈 ...
- Java源码阅读的真实体会(一种学习思路)【转】
Java源码阅读的真实体会(一种学习思路) 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+ ...
- Java源码系列1——ArrayList
本文简单介绍了 ArrayList,并对扩容,添加,删除操作的源代码做分析.能力有限,欢迎指正. ArrayList是什么? ArrayList 就是数组列表,主要用来装载数据.底层实现是数组 Obj ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
随机推荐
- 【csp模拟赛6】相遇--LCA
对于30%的数据:暴力枚举判断 对于60%的数据:还是暴力枚举,把两条路径都走一遍计一下数就行,出现一个点被访问两次即可判定重合 对于100%的数据:找出每条路径中距离根最近的点(lca),判断这个点 ...
- 删数问题(SDUT2072 )
删数问题 Time Limit: 1000 msMemory Limit: 65536 KiB Problem Description 键盘输入一个高精度的正整数n(≤100位),去掉其中任意s个数字 ...
- 2019.7.9 校内测试 T3 15数码问题
这一次是交流测试?边交流边测试(滑稽 15数码问题 大家应该都玩过这个15数码的游戏吧,就在桌面小具库那里面哦. 一看到这个题就知道要GG,本着能骗点分的原则输出了 t 个无解,本来以为要爆零,没想到 ...
- this关键字的用法小结
1.this :指它所在函数所属对象的引用. 简单说:哪个对象调用this所在的函数,this就指哪个对象. 主要是为了区分:成员变量和局部变量 2.构造函数之间的调用用this关键字,如,this( ...
- 浅谈 es6 箭头函数, reduce函数介绍
今天来谈一下箭头函数, es6的新特性 首先我们来看下箭头函数长什么样子, let result = (param1, param2) => param1+param2; 上述代码 按照以前书写 ...
- pwn学习日记Day20 《程序员的自我修养》读书笔记
可执行文件的装载与进程 覆盖装入和页映射是两种典型的动态装载方法 进程建立的三步 1.创建一个独立的虚拟地址空间 2.读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系. 3.将CPU的指令寄存 ...
- mybatis+mysql批量插入和批量更新、存在及更新
mybatis+mysql批量插入和批量更新 一.批量插入 批量插入数据使用的sql语句是: insert into table (字段一,字段二,字段三) values(xx,xx,xx),(oo, ...
- 【Centos】搭建 SVN 服务器
1.如果仅仅只是搭建 svn 服务器: (a).先检查 svn 是否已经安装了 rpm -qa subversion #输入这个命令后,会出现 subversion 版本号 (b).如果没有安装, ...
- 【Java】利用java.io.PrintWriter写出文本文件
代码: package com.hy.expired; import java.io.FileNotFoundException; import java.io.PrintWriter; public ...
- leetcode 79. Word Search 、212. Word Search II
https://www.cnblogs.com/grandyang/p/4332313.html 在一个矩阵中能不能找到string的一条路径 这个题使用的是dfs.但这个题与number of is ...