count(*),count(1),count(字段)
如果null参与聚集运算,则除count(*)之外其它聚集函数都忽略null.
如:
ID DD
1 e
2 null
select count(*) from table --结果是2
select count(DD) from table ---结果是1
按地区查询企业数目 实际上我只有4个企业填写了其区域编码测试的 count(字段) ,结果正确
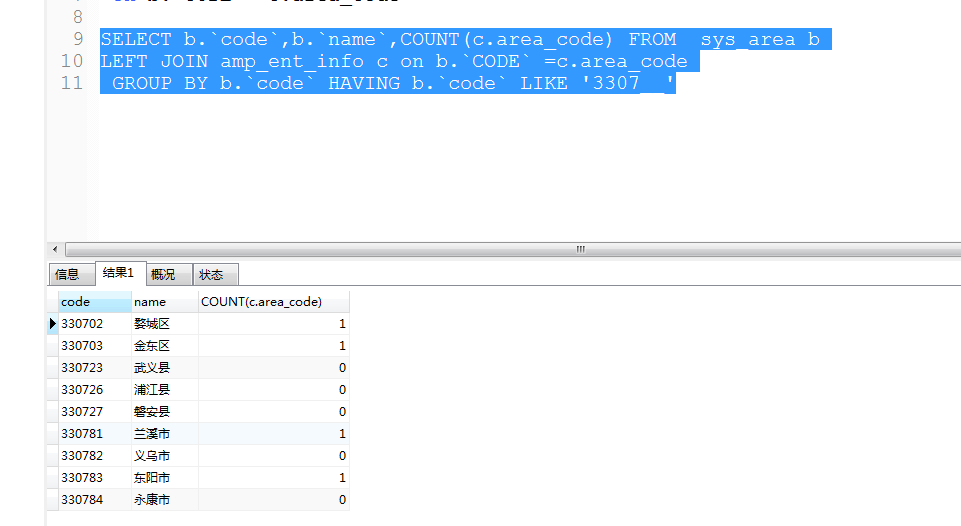
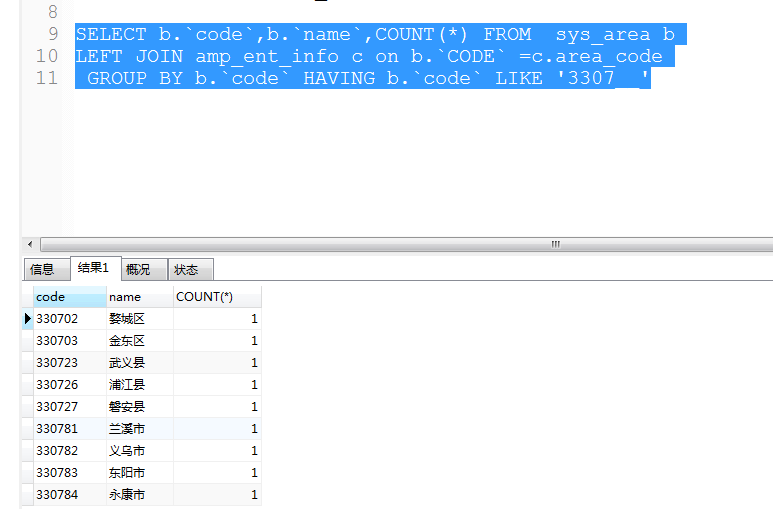
然而,用count(*),就不对。所以 数数的表字段的有null(空的没写的)请用字段来数,但是最后肯定是所以数据度不会空的,所以也一样
我在300万业务数据上测试的结果是count(ROWID),count(1),count(主键)这个三种情况速度差不多,
count(*)这种明显慢,察看执行计划,COUNT(*)时候走的是全表查询。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。
但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
这个也与表的记录数多少有关!如果1w以外的数据量,做过表分析之后,反而count(1)的用时比count(*)多了。
另外,当数据量达到10w多的时候,使用count(1)要比使用count(*)的用时稍微少点!
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的啦
count(*) count(1) 两者比较。主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的
因此:count(1)和count(*)基本没有差别!
sql调优,主要是考虑降低:consistent gets和physical reads的数量。
count(*),count(1),count(字段)的更多相关文章
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- Count(*), Count(1) 和Count(字段)的区别
1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和count(*)的 ...
- 【mysql优化】mysql count(*)、count(1)、count(主键字段)、count(非主键字段)哪个性能最佳
测试结果为:count(*)和count(1)基本相等,count(非主键字段)最耗性能 -- 数据量 708254select count(*) from tmp_test1;-- avg 0.22 ...
- MySql-count(*)与count(id)与count(字段)之间的执行结果和性能分析
在mysql数据库中,当我们需要统计数据的时候,一定会用到count()这个方法,那么count(值)里面的这个值,到底应该怎么选择呢!常见有3种选择,(*,数字,列名),分别列出它们的执行结果和性能 ...
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- MySQL学习笔记:count(1)、count(*)、count(字段)的区别
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请 ...
- count(1)、count(*)、count(字段)的区别
count(1)和count(*): 都为统计所有记录数,包括null 执行效率上:当数据量1W+时count(*)用时较少,1w以内count(1)用时较少 count(字段): 统计字段列的行数, ...
- mysql 5.7中 count(0) count(*) count(主键) count(非空字段)效率比较
mysql count(0) count(*) count(主键) count(非空字段) 效率比较 写代码的时候经理在背后说了一句count(0)的效率高于count(*) ,索性全部测试了一下 结 ...
- 图解MySQL:count(*) 、count(1) 、count(主键字段)、count(字段)哪个性能最好?
大家好,我是小林. 当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1).count(*).count(字段 ...
- COUNT(1)和COUNT(*)区别
项目经常用到count(1),但是和count(*)什么区别? 从下面实验结果来看,Count (*)和Count(1)查询结果是一样的,都包括对NULL的统计,而count(列名) 是不包括NULL ...
随机推荐
- 处理输入为非对角阵的Clustering by fast search and find of density peak代码
Clustering by fast search and find of density peak. Alex Rodriguez, Alessandro Laio 是发表在Science上的一篇很 ...
- Ubuntu14.04+安卓系统4.3+JDK6编译源码
本博客主要参照: https://www.jianshu.com/p/ecb9c132030f https://blog.csdn.net/gobitan/article/details/243674 ...
- sublime的简单配置(解决为什么package control无效)
1:下载sublime text 3 要到它的官网下载,要英文的. 2:安装sublime的包. 进入sublime按快捷键ctrl+~(~是键盘左上角Esc下面的键). 3:在这里面输入如下代码.( ...
- quartz定时任务表达式案例
表示式 说明 "0 0 12 * * ? " 每天12点运行 "0 15 10 ? * *" 每天10:15运行 "0 15 10 * * ?&quo ...
- Go项目实战:打造高并发日志采集系统(二)
日志统计系统的整体思路就是监控各个文件夹下的日志,实时获取日志写入内容并写入kafka队列,写入kafka队列可以在高并发时排队,而且达到了逻辑解耦合的目的.然后从kafka队列中读出数据,根据实际需 ...
- rocketMQ配置事故
公司的binlog消息通知,基于canal采集然后转发到rocketmq推送给业务进行消费. 基于此机制,为了实现实时计算通用源端处理,订阅了若干rocketmq的topic进行数据的幂等事务性投递到 ...
- CTF—攻防练习之Capture the Flag
主机:192.168.32.152 靶机:192.168.32.160 首先nmap扫描端口: ftp,ssh,http服务 dirb扫描目录,flag下有一个flag password目录下,查看源 ...
- 【VS开发】关于线程安全一些细节体会
[VS开发]关于线程安全一些细节体会 标签(空格分隔): [VS开发] 利用C++进行GUI界面开发,最大的问题往往是多线程安全问题,由于C++不具备收集内存垃圾的功能,所以必须由程序员负责维护,因此 ...
- springcloud 心得记录
1.nacos,模块启动无加载顺序 2.nacos,线上配置中心修改文件后,需重启模块
- speedtest-cli 命令
speedtest-cli是一个使用python编写的命令行脚本,通过调用speedtest.net测试上下行的接口来完成速度测试,项目地址:https://github.com/sivel/spee ...