【Mybatis】缓存
一、概述
1.1 缓存的意义
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
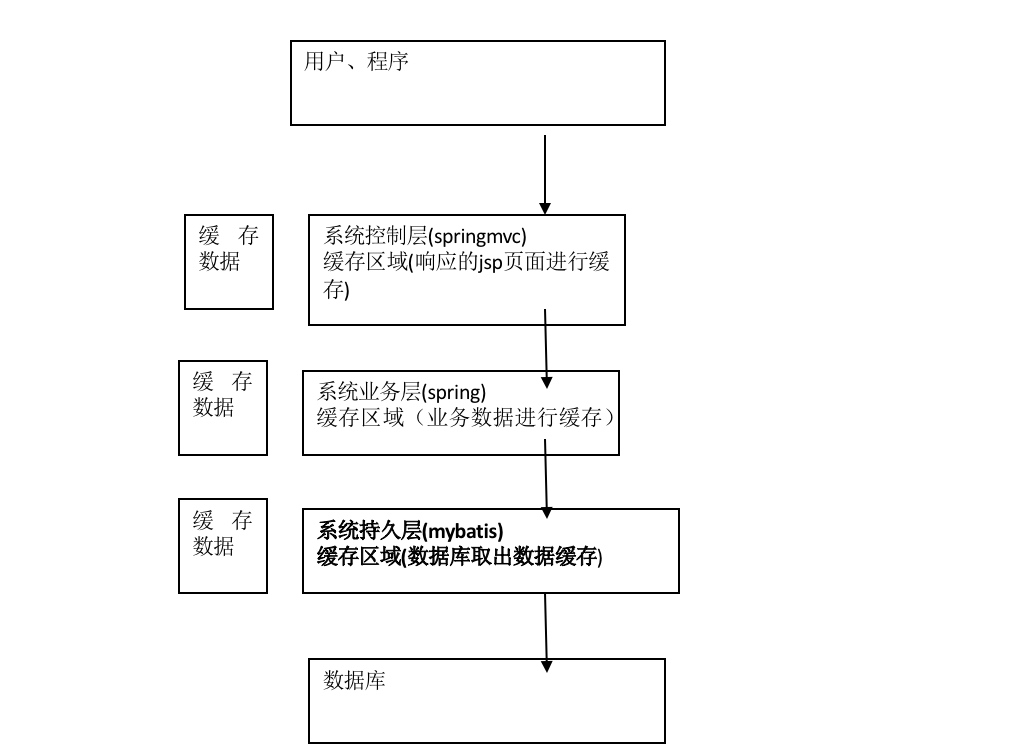
1.2 mybatis持久层缓存
- mybatis提供一级缓存和二级缓存
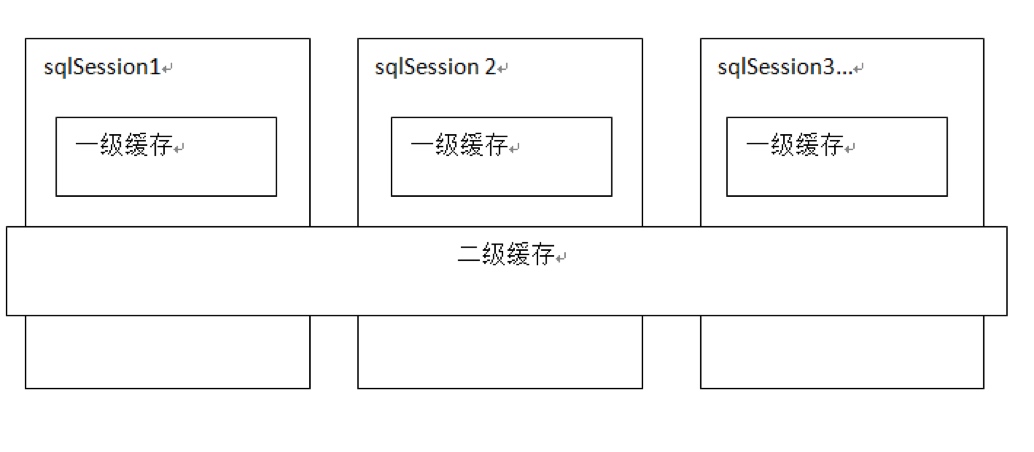
- mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据,二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。
二、一级缓存
2.1 原理
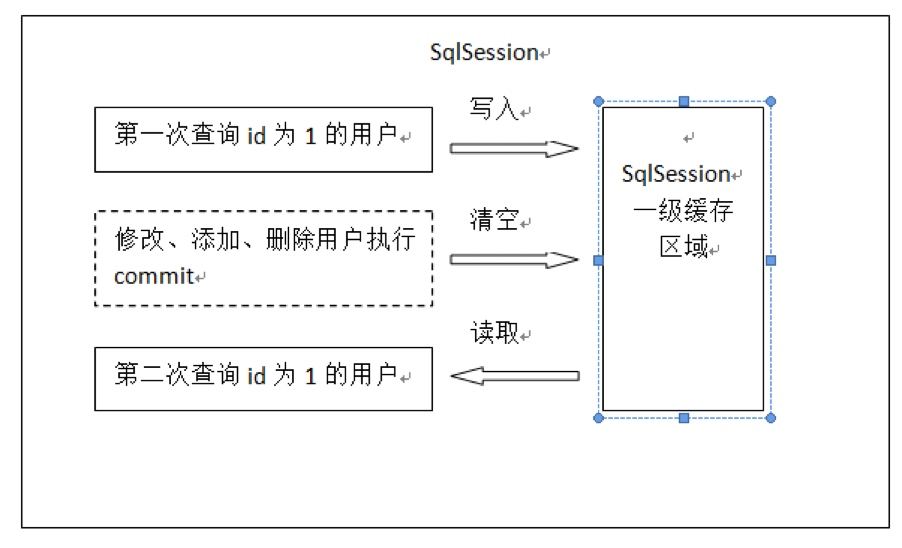
- 第一次发出一个查询sql,sql查询结果写入sqlsession的一级缓存中,缓存使用的数据结构是一个map
- key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识)
- value:用户信息
- 同一个sqlsession再次发出相同的sql,就从缓存中取走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
- 每次查询都先从缓存中查询:
- 如果缓存中查询到则将缓存数据直接返回。
- 如果缓存中查询不到就从数据库查询:
2.2 一级缓存配置
- mybatis默认支持一级缓存不需要配置。
- 注意:mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession。
一级缓存测试
//一级缓存
@Test
public void testCache1() throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询用户id为1的用户
User user = userMapper.findUserById(1);
System.out.println(user);
//中间修改用户要清空缓存,目的防止查询出脏数据
/*user.setUsername("测试用户2");
userMapper.updateUser(user);
sqlSession.commit();*/
//第二次查询用户id为1的用户
User user2 = userMapper.findUserById(1);
System.out.println(user2);
sqlSession.close();
}
三、二级缓存
3.1 原理
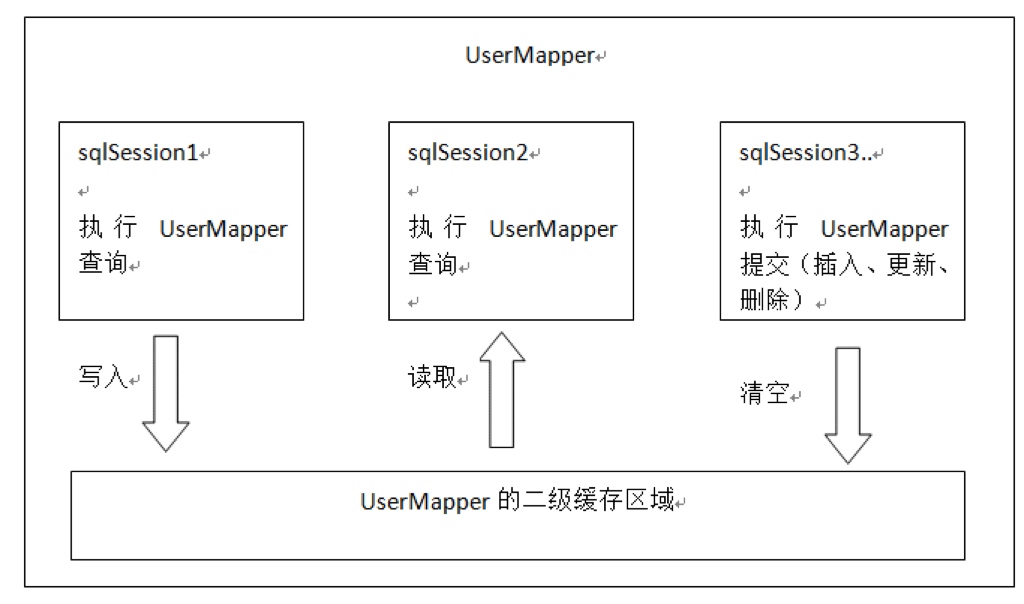
- 二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构是map。
- 每次查询先看是否开启二级缓存,如果开启从二级缓存的数据结构中取缓存数据,
- 如果从二级缓存没有取到,再从一级缓存中找,如果一级缓存也没有,从数据库查询。
3.2 mybatis二级缓存配置
| 描述 | 允许值 | 默认值 | |
|---|---|---|---|
| cacheEnabled | 对在此配置文件下的所有cache 进行全局性开/关设置。 | true false | true |
- 在核心配置文件SqlMapConfig.xml中加入
<setting name="cacheEnabled" value="true"/>- 要在你的Mapper映射文件中添加一行:
<cache />,表示此mapper开启二级缓存。
3.3 查询结果映射的pojo序列化
- mybatis二级缓存需要将查询结果映射的pojo实现
java.io.serializable接口,如果不实现则抛出异常:
org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException: com.hao.mybatis.po.User - 二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以要实现java.io.serializable接口。
- 如果结果映射的pojo中还包括了pojo,都要实现java.io.serializable接口。
3.4 二级缓存禁用
- 对于变化频率较高的sql,需要禁用二级缓存:
- 在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
3.5 刷新缓存
- 如果sqlsession操作commit操作,对二级缓存进行刷新(全局清空)。
- 设置statement的flushCache是否刷新缓存,默认值是true。
3.6 测试代码
@Test
public void testCache2() throws Exception {
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class);
//第一次查询用户id为1的用户
User user = userMapper1.findUserById(1);
System.out.println(user);
sqlSession1.close();
//中间修改用户要清空缓存,目的防止查询出脏数据
/*user.setUsername("测试用户2");
userMapper3.updateUser(user);
sqlSession3.commit();
sqlSession3.close();*/
//第二次查询用户id为1的用户
User user2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
3.7 mybatis的cache参数
- mybatis的cache参数只适用于mybatis维护缓存。
- flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
- size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
- readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
- 如下例子:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
- 这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
- LRU – 最近最少使用的:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
- WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
3.8 二级缓存的应用场景
- 对查询频率高,变化频率低的数据建议使用二级缓存。
- 对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
- 实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
3.9 mybatis局限性
- mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存。
【Mybatis】缓存的更多相关文章
- mybatis缓存
mybatis缓存http://www.cnblogs.com/QQParadise/articles/5109633.htmlhttp://www.mamicode.com/info-detail- ...
- Mybatis缓存处理机制
一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的支持 一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Se ...
- MyBatis缓存禁用失败
问题:MyBatis缓存无法禁用,同一个session的select查询结果一样,但是数据库其实已改变. 尝试达到想要的目的: 1.msgmapper.xml里的select标签加上 <sele ...
- MyBatis入门学习教程-MyBatis缓存
一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了 package me.gacl.test; 2 import me.gacl.domain.User; import ...
- MyBatis学习总结(七)——Mybatis缓存(转载)
孤傲苍狼 只为成功找方法,不为失败找借口! MyBatis学习总结(七)--Mybatis缓存 一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的 ...
- MyBatis学习总结(七)——Mybatis缓存
一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的支持 一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Se ...
- MyBatis学习总结(七)——Mybatis缓存
一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的支持 一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Se ...
- MyBatis——Mybatis缓存
原文:http://www.cnblogs.com/xdp-gacl/p/4270403.html MyBatis学习总结(七)--Mybatis缓存 一.MyBatis缓存介绍 正如大多数持久层框架 ...
- 【转】MyBatis学习总结(七)——Mybatis缓存
[转]MyBatis学习总结(七)——Mybatis缓存 一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的支持 一级缓存: 基于PerpetualC ...
- 使用MyBatis缓存
(1).为什么需要使用缓存:: MyBatis是一个持久层(数据库层)映射框架,在所有访问数据库的操作中,无疑数据查询是最耗费数据库资源的操作了,因为你一次可能需要查询成千上百万条记录(如果你不加限制 ...
随机推荐
- 算法习题---5.3字典(Uva10815)
一:题目 给出一段英文,里面包含一些单词,空格和标点,单词不区分大小写,默认都为小写.按照字典序输出这些单词(这些单词不能有重复,字母全部变成小写) (一)样例输入 Adventures in Dis ...
- top显示命令详解+top命令使用
http://blog.csdn.net/u014226549/article/details/22041289
- MySQL 过滤复制+复制映射 配置方法
场景 node1 和 node2 为两台不同业务的MySQL服务器.业务方有个需求,需要将node1上的 employees库的departments .dept_manager 这2张表同步到 no ...
- centos umount 卸载出错
target is busy. (In some cases useful info about processes that use the device ) or fuser()) 解决 fuse ...
- 最新 迅游科技java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.迅游科技等10家互联网公司的校招Offer,因为某些自身原因最终选择了迅游科技.6.7月主要是做系统复习.项目复盘.Leet ...
- C++ STL-bitset
1.bitset的声明 #include <bitset> using std::bitset; 2.bitset对象的定义和初始化 可以如下声明一个该类型变量: bitset ...
- ACL 实验
一.环境准备 1. 软件:GNS3 2. 路由:c7200 二.实验操作 实验要求: 1. 掌握标准 ACL.扩展 ACL 的配置方法. 2. 掌握命名 ACL 的配置方法. 3. 掌握访问控制列表配 ...
- 修改 ubuntu NTFS 文件系统下没有执行权限的问题
由于NTFS本身的特殊性,不能对其分区的文件权限进行修改,无论是sudo还是root都没有用. 安装以下两个插件解决问题: sudo apt-get install ntfs-3g //这个12.04 ...
- [转帖]什么是UWB?UWB有什么用?
什么是UWB?UWB有什么用? https://www.sohu.com/a/224891573_531173 小米碰传 就是 UWB吧? 2018-03-05 17:02 UWB在早期被用来应用在近 ...
- Java中XML的四种解析方式(一)
XML是一种通用的数据交换格式,它的平台无关性.语言无关性.系统无关性给数据集成与交互带来了极大的方便.XML在不同的语言环境中解析的方式都是一样的,只不过实现的语法不同而已. XML文档以层级标签的 ...