Data - 数据挖掘的基础概念
主要内容来自于《微信公众号:程SIR说》
1 数据挖掘
数据挖掘(Data Mining,简称DM),是指从大量的数据中,挖掘出未知的且有价值的信息和知识的过程。
数据挖掘是一门交叉学科,覆盖了统计学、计算机程序设计、数学与算法、数据库、机器学习、市场营销、数据可视化等领域的理论和实践成果。
2 - 数据挖掘的基本思想
数据挖掘的别名机器学习和统计学习一样,数据挖掘的实质是通过计算机的计算能力在一堆数据中发掘出规律并加以利用的过程。
因此对数据挖掘而言,就需要经历规则学习、规则验证和规则使用的过程。
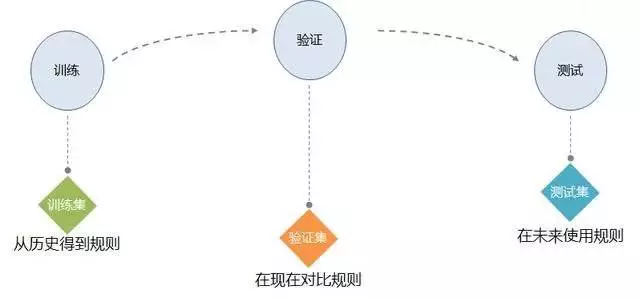
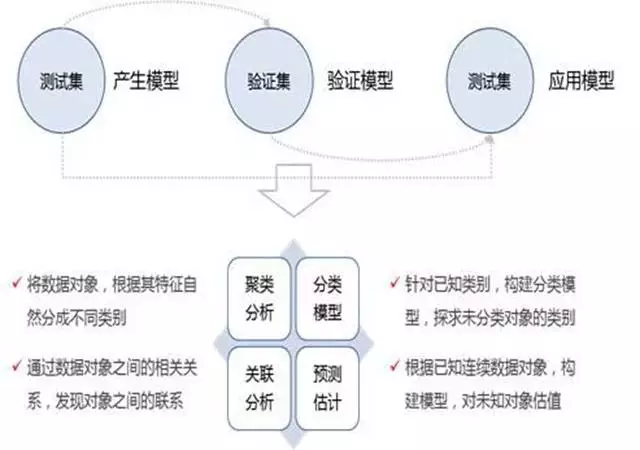
2.1 训练
规则学习又称为模型训练,在这个步骤中,有一个数据集将作为训练集。
按照相关的算法和输出规则的要求,从训练集中筛选出需要使用的变量,并根据这些变量生成相关的规则。
有的时候,是将过去已经发生的数据作为训练集,在对比已知的结果和输入的变量的过程中,以尽可能降低输出误差的原则,拟合出相应的模型。
2.2 验证
当产生了规则后,就需要验证规则的效果和准确度,这个时候就需要引入验证集。
验证集和训练集具有相同的格式,既包含了已知的结果也包含了输入的变量。
与训练集不同的是,对验证集的应用是直接将规则应用于验证集中,去产生出相应的输出结果,并用输出的结果去对比实际情况,以来确定模型是否有效。
如果有效的话,就可以在实际的场景中应用。如果效果不理想,则回头去调整模型
2.3 测试
测试集是将模型在实际的场景中使用,是直接应用模型的步骤。
在测试集中,只包含输入变量却没有像其他两个数据一样存在的已知结果。
正因为结果未知,就需要用测试集通过模型去产生的输出的结果。
这个输出结果,将在为结果产生以后进行验证,只要有效,模型就会一直使用下去。
3 - 数据挖掘的流程分解
与数据分析的流程相似,都是从数据中发现知识的过程,只不过由于数据体量和维度的原因,数据挖掘在计算上最大。
数据挖掘是一个周而复始的过程,在生成规则的过程中,不断地对模型进行调整,从而提升精度。
同时也将多批次的历史数据引入到数据挖掘的过程中,进行多次的验证,从而在时间上保证模型的稳定性。
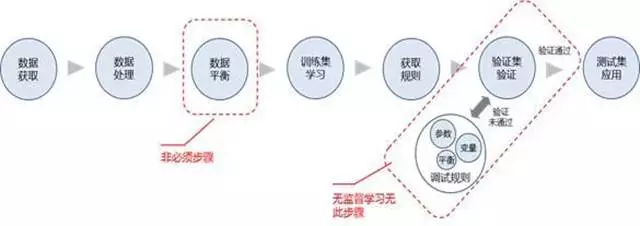
3.1 数据获取
首先是进行数据获取,数据获取的来源很多,有系统中自行记录的数据,对这种数据只要导出即可,同时也有外来数据,比如网页爬取得数据,或者是购买的数据,这些数据需要按照分析系统的需求进行导入。
3.2 数据处理
在完成了数据获取步骤后,就需要进行数据处理,数据处理即是处理数据中的缺失值,错误值以及异常值,按照相关的规则进行修正或者删除,同时在数据处理中也需要根据变脸之间的关系,产生出一系列的衍生变量。
总而言之,数据处理的结果是可以进行分析的数据,所有数据在进行分析以前都需要完成数据处理的步骤。
3.3 数据平衡
如果数据在分布上存在较极端的情况,就需要经历数据平衡的不走。
例如对于要输出的原始变量而言,存在及其少量的一种类别以及及其大量的另一种类别,就像有大量的0和少量的1一样,在这种情况下,就需要对数据进行平衡,通过复制1或者削减0的形式生成平衡数据集。
3.4 训练集学习
当完成数据平衡后,将会把数据处理的结果分出一部分作为验证集使用,如果数据平衡性好,那么剩下的部分作为训练集,如果平衡性不好,那么平衡数据集就会作为训练集使用。
3.5 获取规则
当有了训练集后,就按照相关的算法对训练集进行学习,从而产生出相关的规则和参数。
3.6 验证集验证
当有了规则以后,就将产生的规则用在验证集中,通过对比已知结果和输出结果之间的误差情况,来判断是否通过。
3.7 测试集应用
如果通过则在后面再测试集中使用,如果未通过,就通过数据平衡、参数调整,以及变量选择等手段重新调整规则,并再次进行验证,直到通过验证。
4 - 数据挖掘的模式
在数据挖掘中,对于规则的获取,存在三种方式,分别是监督学习,无监督学习和半监督学习,这三种方式都是通过从数据的统计学习来制定规则。
在一个数据挖掘问题中,变量可以分为自变量和因变量,规则是以自变量为输入,以因变量为输出的结果,由此对数据挖掘问题,就把自变量定义为X,把因变量定义为Y。
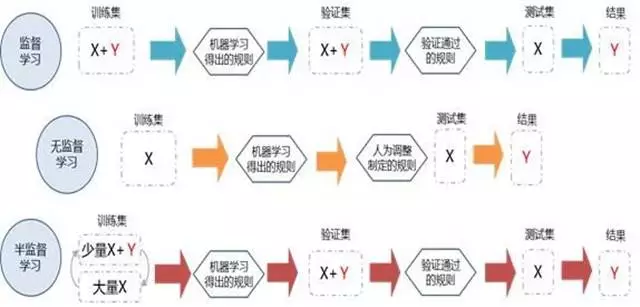
4.1 监督学习
对于监督学习而言,训练集中包括了自变量X和因变量Y,通过对比X和Y的关系,得除相应的规则,同时再在验证集中,通过输入验证集的自变量X,借助规则得到因变量Y的预测值,再将Y的预测值与实际值进行对比,看是否可以将模型验证通过,如果通过了,就把只包含自变量X的测试集用于规则中,最终输出因变量Y的预测值。
在监督学习中,因变量的实际值和预测值的对比,就起到监督的作用,在规则制定中需要尽量引导规则输出的结果向实际值靠拢。
4.2 无监督学习
对无监督学习而言,训练集中,就没有包含因变量Y,需要根据模型的目标,通过对自变量X的分析和对比来得出相关的规则,并能够产生合理的输出结果,即Y,在制定规则的过程中,需要有一些人为的原则对规则进行调整。
当完成调整后,就可以把只包含自变量X的测试集放到规则中,去产生规则的结果Y。
4.3 对比监督学习和无监督学习
最大的区别就是,在制定规则的过程中,是否有Y用于引导规则的生成。
监督学习中,有Y存在,生成规则过程中和生成规则时,也会对比Y的预测值和实际值。
而在无监督学习中,就没有Y作为对比的标准,相应的规则都直接由X产生。
4.4 半监督学习
半监督学习,与监督学习类似,也需要因变量Y参与到规则生成和规则验证中去。
但是在训练集只用只有一少部分的对象既有自变量X和因变量Y,还有大部分对象只包含了自变量X。
因此在对半监督学习的规则生成中,需要有一些特殊的手段来处理只包含的自变量X的对象后,再生成相关的规则。
在后面的验证和测试的流程都与监督学习一致。
因而对于半监督学习,最重要的问题就是如何借助少量的因变量Y而产生出可以适用的规则。
4.5 机器学习与数据挖掘
与数据挖掘类似的有一个术语叫做”机器学习“,这两个术语在本质上的区别不大,如果在书店分别购买两本讲数据挖掘和机器学习的书籍,书中大部分内容都是互相重复的。具体来说,小的区别如下:
机器学习:
更侧重于技术方面和各种算法,一般提到机器学习就会想到语音识别,图像视频识别,机器翻译,无人驾驶等等各种其他的模式识别,甚至于谷歌大脑等AI,这些东西的一个共同点就是极其复杂的算法,所以说机器学习的核心就是各种精妙的算法。
数据挖掘:
更偏向于“数据”而非算法,而且包括了很多数据的前期处理,用爬虫爬取数据,然后做数据的清洗,数据的整合,数据有效性检测,数据可视化(画图)等等,最后才是用一些统计的或者机器学习的算法来抽取某些有用的“知识”。前期数据处理的工作比较多。
所以,数据挖掘的范畴要更广泛一些。
5 数据挖掘能解决什么问题
商业上的问题多种多样,例如:
- “如何能降低用户流失率?”
- “某个用户是否会响应本次营销活动?“
- "如何细分现有目标市场?"
- “如何制定交叉销售策略以提升销售额?”
- “如何预测未来销量?”
从数据挖掘的角度看,都可以转换为五类问题:
- 分类问题
- 聚类问题
- 回归问题
- 关联分析
- 推荐系统
5.1 分类问题
简单来说,就是根据已经分好类的一推数据,分析每一类的潜在特征建立分类模型。对于新数据,可以输出新出具属于每一类的概率。
分类模型通常是通过监督学习产生的,根据已知的对象的类别和其具体特征特征的数据,通过训练从而产生由特征判断类别的规则。在分类模型中,规则的输出就是具体的类别。
比如主流邮箱都具备的垃圾邮件识别功能:一开始,正常邮件和垃圾邮件都是混合在一起的,如果我们手工去点击哪些是垃圾邮件,逐渐的,垃圾邮件就会自动被识别放到垃圾文件夹。如果我们对于混在正常邮件中的垃圾持续进行判断,系统的识别率就会越来越高。我们人工点击判断,相当于预先分类(两类:垃圾邮件和非垃圾邮件),系统就会自己学习两类邮件的特征建立模式,对于新邮件,会根据模式判断属于每个类别的可能性。
分类算法示意


5.2 聚类问题
聚类的的目的也是把数据分类,但类别并不是预先定义的,算法根据“物以类聚”的原则,判断各条数据之间的相似性,相似的就归为一类。
比如我有十万消费者的信息数据,比如包括性别,年龄,收入,消费等,通过聚类的方法事可以把这些数据分成不同的群,理论上每群用户内都是相似性较高的,就可以覆盖分群用户制定不同的策略
聚类分析是一种无监督学习的数据挖掘方法,其目的是基于对象之间的特征,自然地将变量划分为不同的类别。
在聚类分析中,基本的思想就是根据对象不同特征变量,计算变量之间的距离,距离理得越近,就越有可能被划为一类,离得越远,就越有可能被划分到不同的类别中去。
聚类算法示意


5.3 回归问题
回归问题和分类问题有点类似,但是回归问题中的因变量是一个数值,而分类问题,最终输出的因变量是一个类别。简单理解,就是定义一个因变量,在定义若干自变量,找到一个数学公式,描述自变量和因变量之间的关系。
比如,我们要研究房价(Y),然后收集房子距离市中心的距离(X1),面积(X2),收集足够多的房子的数据,就可以建立一个房价和距离、面积的方程式(例如Y=aX1+bX2),这样给出一个新的距离和面积数据,就可以预测这个房子的价格。
回归问题示意


5.4 关联分析
关联分析主要就是指”购物篮分析“,很有名气案例是【啤酒与尿布】的故事,”据说“这是一个真实的案例:沃尔玛在分析销售记录时,发现啤酒和尿布经常一起被购买,于是他们调整了货架,把两者放在一起,结果真的提升了啤酒的销量。后来还分析背后的原因,说是因为爸爸在给宝宝买尿布的时候,会顺便给自己买点啤酒……
所以,关联分析就是基于数据识别产品之间潜在的关联,识别有可能频繁发生的模式。
常用于揭示事件之间的关系,是通过无监督学习的方式,产生的输出事件之间发生关系的规则。
关联分析示意

5.5 推荐系统
利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。也就是平时我们在浏览电商网站、视频网站、新闻App中的"猜你喜欢"、“其他人也购买了XXX”等类似的功能。
6 数据挖掘的工作流程
数据挖掘的通用流程叫做CRISP-DM(Cross Industry Standard Process-Data Mining)数据挖掘方法论。
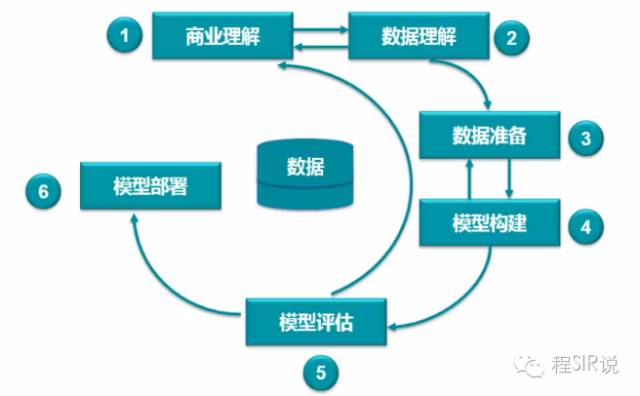
6.1 商业理解
商业理解阶段主要完成对商业问题的界定,以及对企业内外部资源进行评估与组织,最终确定将企业的商业目标转化为数据挖掘目标,并制定项目的方案
6.2 数据理解
了解企业目前数据现状,提出数据需求,并尽可能多的收集数据。通过初步的数据探索,快速了解数据的质量
6.3 数据准备
在建立数据挖掘模型之前对数据做最后的准备工作,主要是把收集到的各部分数据关联起来,形成一张最终数据宽表。这个阶段其实是耗时最长的阶段,一般会占据整个数据挖掘项目的70%左右的时间,包括数据导入、数据抽取、数据清洗、数据合并、新变量计算等工作。
6.4 模型构建
模型构建是数据挖掘工作的核心阶段。主要包括准备模型的训练集和验证集,选择并使用适当的建模技术和算法,模型建立,模型效果对比等工作
6.5 模型评估
模型评估主要从两个方面进行评价:
1)技术层面:
- 设计对照组进行比较。
- 根据常用的模型评估指标进行评价,如命中率、覆盖率、提升度等
2)业务经验:业务专家凭借业务经验对数据挖掘结果进行评估
6.6 模型部署
将数据挖掘成果程序化,将模型写成存储过程固化到IT平台上,并持续观察模型衰退变化,在发生模型衰退时,引入新的变量进行模型优化。
7 数据挖掘的误区
误区一:算法至上论。认为数据挖据是某些对大量数据操作的算法,这些算法能够自动地发现新的知识。
误区二:技术至上论。认为数据挖据必须需要非常高深的分析技能,需要精通高深的数据挖掘算法,需要熟练程序开发设计。
这两种认知都有一定的偏颇。实际上,数据挖掘本质上是人们处理商业问题的方法,通过适量的数据挖掘来获得有价值的结果,技术在随着大数据时代的来临变得愈发重要,但是最好的数据挖掘工程师往往是那些熟悉和理解业务的人。
Data - 数据挖掘的基础概念的更多相关文章
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- Jmeter基础之---jmeter基础概念
Jmeter基础之---jmeter基础概念 JMeter 介绍: 一个非常优秀的开源的性能测试工具. 优点:你用着用着就会发现它的重多优点,当然不足点也会呈现出来. JMeter 介绍: 一个非常优 ...
- 理解 angular2 基础概念和结构 ----angular2系列(二)
前言: angular2官方将框架按以下结构划分: Module Component Template Metadata Data Binding Directive Service Dependen ...
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Hadoop基础概念介绍
基于YARN的配置信息, 参见: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ hadoop入门 - 基础概念 ...
- JavaWeb开发技术基础概念回顾篇
JavaWeb开发技术基础概念回顾篇 第一章 动态网页开发技术概述 1.JSP技术:JSP是Java Server Page的缩写,指的是基于Java服务器端动态网页. 2.JSP的运行原理:当用户第 ...
- MongoDB入门系列(一):基础概念和安装
概述 MongoDB是目前非常流行的一种非关系型数据库,作为入门系列的第一篇本篇文章主要介绍Mongdb的基础概念知识包括命名规则.数据类型.功能以及安装等. 环境: OS:Windows Versi ...
- Spring Data(一)概念和仓库的定义
Spring Data(一)概念和仓库的定义 Spring Data的主要任务是为数据访问提供一个相似的.一致的.基于Spring的编程模型,同时又保留着下面各个数据存储的特征.它使得使用数据访问技术 ...
- 【UML】NO.70.EBook.9.UML.4.001-【PowerDesigner 16 从入门到精通】- 基础概念
1.0.0 Summary Tittle:[UML]NO.70.EBook.9.UML.4.001-[PowerDesigner 16 从入门到精通]- 基础概念 Style:DesignPatte ...
随机推荐
- 登录授权、TCP/IP、HTTPS
今天继续纯理论的东东,比较枯燥,但是又很重要,坚持.. 登录和授权 登录和授权的区别: 登录:身份认证,即确认「你是你」的过程. 授权:由身份或持有的令牌确认享有某些权限(例如获取用户信息).登录过程 ...
- 安装卸载JDK
卸载JDK 删除Java的安装目录 删除JAVA_HOME 删除path下关于Java的目录 java-version 安装JDK 百度搜索JDK8,找到下载地址 同意协议 下载电脑对应的版本 双击安 ...
- 使用python批量造测试数据
# -*- coding:utf-8 -*- import json import os import time class Virtual_Data: def __init__(self): sel ...
- Oracle自动化安装脚本-part01-亲试ok
#!/bin/bash node_num=$1 base_config=./network.conf 网络配置文件 software_config=./software.conf 软件包 ...
- BZOJ 2502 清理雪道/ Luogu P4843 清理雪道 (有源汇上下界最小流)
题意 有一个有向无环图,求最少的路径条数覆盖所有的边 分析 有源汇上下界最小流板题,直接放代码了,不会的看dalao博客:liu_runda 有点长,讲的很好,静心看一定能看懂 CODE #inclu ...
- nginx配置及使用
偶尔会用到nginx部署项目,记录nginx配置备忘.主要有端口.地址及别名,代理转发和https配置. 配置文件为nginx.conf. 部署http项目: 1.找到http下的server配置项 ...
- 8、Spring Boot 2.x 服务器部署
1.8 服务器部署 完整源码: Spring-Boot-Demos 1.8.1 jar包提取出来maven打包(避免每次重复打相同的jar包),pom.xml配置如下: <build> & ...
- Shell 05 Sed
一.基本用方法 1.sed文本处理工具的用法 用法1:前置命令 | sed [选项] '条件指令' 用法2:sed [选项] '条件指令' 文件.. .. 注意:没有条件时候,默认所有条件, ...
- tinymce+粘贴word图片例子
tinymce是很优秀的一款富文本编辑器,可以去官网下载.https://www.tiny.cloud 这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用. http ...
- GitLab 如何删除 Forked from
在 GitLab 中有 Forked from. 如何删除这个? 在 Settings 中选择 General 然后选择 Advanced 高级选项 然后单击移除 fork 关系的选项,你就可以将这个 ...