Python——EM(期望极大算法)教学(附详细代码与注解)
今天,我们详细的讲一下EM算法。
前提准备
Jupyter notebook 或 Pycharm
火狐浏览器或谷歌浏览器
win7或win10电脑一台
网盘提取csv数据
需求分析
实现高斯混合模型的 EM 算法(GMM_EM)
高斯混合模型是多个高斯模型的线性叠加而成的,高斯混合模型的概率分布表示如下:
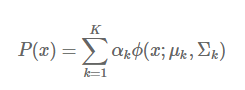
其中,k表示模型的个数,αkα_kαk 是第 k 个模型的系数,表示出现该模型的概率,ϕ(x;μk,Σk) 是第 k 个高斯模型的概率分布。
E步:样本 xix_ixi来自于第 k 个模型的概率,我们把这个概率称为模型 k 对样本 xix_ixi 的“责任”,也叫“响应度”,记作 γ(ik)γ_(ik)γ(ik),计算公式如下:
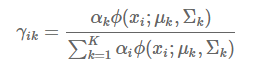
M步:根据样本和当前 γ 矩阵重新估计参数,注意这里 x 为列向量,计算公式如下:
【目标】给定一堆没有标签的样本和模型个数 K,以此求得混合模型的参数,然后就可以用这个模型来对样本进行聚类。
python代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal #本问题考虑的是高斯混合模型,所以导入多元高斯分布multivariate_normal
def prob_Y_k(Y,mu_k,cov_k): #Y为样本矩阵
norm = multivariate_normal(mean = mu_k , cov = cov_k) #生成多元正太分布,mu为第k个模型的均值,cov为第k个模型的协方差矩阵(协方差矩阵必须是实对称矩阵)
return norm.pdf(Y) #返回样本Y来自于第k个模型的概率
def Estep(Y,mu,cov,alpha): #Y为样本矩阵,alpha为权重
N = Y.shape[0] #样本数
K = alpha.shape[0] #模型数
assert N>1 , "There must be more than one sample!" #为避免单个样本导致返回的结果的类型不一致,因此要求样本数必须大于一
assert K>1 , "There must be more than one gaussian model!" #为避免单个模型结果的类型不一致,因此要求模型须大于一
gamma = np.mat(np.zeros((N,K))) #初始化响应度矩阵,行对应样本数,列对应模型数
prob = np.zeros((N,K)) #初始化所有样本出现的概率矩阵,行对应样本数,列对应响应度
for k in range(K):
prob[:,k] = prob_Y_k(Y,mu[k],cov[k]) #第k个模型的概率prob_Y_k
prob = np.mat(prob) #K个prob放入数组中
for k in range(K):
gamma[:,k] = alpha[k] * prob[:,k] #计算模型k对样本i的响应度
for i in range(N):
gamma[i,:] /= np.sum(gamma[i,:]) #第i个样本的占总样本的响应程度
return gamma #gamma为响应度矩阵
def Mstep(Y,gamma): #传入样本矩阵Y和Estep得到的gamma响应度矩阵
N, D = Y.shape #N为样本数,D为特征数
K = gamma.shape[1] #模型数
mu = np.zeros((K,D)) #初始化参数均值mu,每个模型的D维各有均值故mu的矩阵为K行D列
cov = [] #初始化参数协方差矩阵
alpha = np.zeros(K) # 初始化权重数组,每个模型都有权值
#接下来是更新每个模型的参数
for k in range(K):
Nk = np.sum(gamma[:,k]) #第k个模型所有样本的响应度之和
mu[k,:] = np.sum(np.multiply(Y, gamma[:,k]),axis=0)/Nk #更新参数均值mu,对每个特征求均值
cov_k = (Y - mu[k]).T * np.multiply((Y - mu[k]), gamma[:,k]) / Nk #更新cov
cov = np.append(cov_k)
alpha[k] = Nk / N
cov = np.array(cov)
return mu, cov, alpha
def normalize_data(Y): #将所有数据进行归一化处理,
for i in range(Y.shape[1]):
max_data = Y[:,i].max()
min_data = Y[:,i].min()
Y[:,i] = (Y[:,i] - min_data)/(max_data - min_data) #此处用到min-max归一化
debug("Data Normalized")
return Y
def init_params(shape,K): #在执行该算法之前,需要先给出一个初始化的模型参数。我们让每个模型的μ为随机值,Σ 为单位矩阵,α 为 1/K,即每个模型初始时都是等概率出现的。
N, D = shape郑州人流手术多少钱 http://mobile.chnk120.com/
mu = np.random.rand(K, D) #生成一个K行D列的[0,1)之间的数组
cov = np.array([np.eye(D)] * K) #生成K个D维的对角矩阵
alpha = np.array([1.0 / K] * K) #生成K个权重
debug("Parameters initialized.")
debug("mu:",mu, "cov:",cov ,"alpha:",alpha,sep = "\n" )
return mu, cov, alpha
def GMM_EM(Y, K, times): #高斯混合EM算法,Y为给定样本矩阵,K为模型个数,times为迭代次数,目的是求该模型的参数
Y = normalize_data(Y) #调用前面定义的normalize_data函数,归一化样本矩阵Y
mu, cov, alpha = init_params(Y.shape, K) #调用init_params函数得到初始化的参数mu,cov,alpha
for i in range(times):
gamma = Estep(Y, mu, cov, alpha) #调用Estep得到响应度矩阵
mu, cov, alpha = Mstep(Y, gamma) #调用Mstep得到更新后的参数mu,cov,alpha
debug("{sep} Result {sep}".format(sep="-"*20))
debug("mu:", mu , "cov:",cov , "alpha:",alpha , sep="\n")
return mu,cov,alpha
import matplotlib.pyplot as plt
from gmm import *
DEBUG = True
Y = np.loadtxt("gmm.data") #载入数据
matY = np.matrix(Y ,copy = True)
K = 2 #模型个数(相当于聚类的类别个数)
mu, cov, alpha = GMM_EM(matY , K , 100) #调用GMM_EM函数,计算GMM模型参数
N = Y.shape[0]
gamma = Estep(matY, mu, cov, alpha) #求当前模型参数下,各模型对样本的响应矩阵
category = gamma.argmax(axis = 1).flatten().tolist()[0] #对每个样本,求响应度最大的模型下标,作为其类别标识
class1 = np.array([Y[i] for i in range(N) if category[i] == 0]) #将每个样本放入对应样本的列表中
class2 = np.array([Y[i] for i in range(N) if category[i] == 1])
plt.plot(class1[:,0],class1[:,1], 'rs' ,label = "class1")
plt.plot(class2[:,0],class2[:,1], 'bo' ,label = "class2")
plt.legend(loc = "best")
plt.title("GMM Clustering By EM Algorithm")
plt.show()
import numpy as np
import matplotlib.pyplot as plt
cov1 = np.mat("0.3 0 ; 0 0.1") #2维协方差矩阵(必须是对角矩阵)
cov2 = np.mat("0.2 0 ; 0 0.3")
mu1 = np.array([0,1])
mu2 = np.array([2,1])
sample = np.zeros((100,2)) #初始化100个样本,样本特征为2
sample[:30, :] = np.random.multivariate_normal(mean=mu1, cov=cov1, size=30) #生成多元正态分布矩阵
sample[30:, :] = np.random.multivariate_normal(mean=mu2, cov=cov2, size=70)
np.savetxt("sample.data",sample) # 将array保存到txt文件中
plt.plot(sample[:30, 0], sample[:30, 1], "bo") #30个样本用蓝色圆圈标记
plt.plot(sample[30:, 0], sample[30:, 1], "rs") #70个样本用红色方块标记
plt.title("sample_data")
plt.show()
Python——EM(期望极大算法)教学(附详细代码与注解)的更多相关文章
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- EM 期望最大化算法
(EM算法)The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用到了. ...
- 零基础学Python之结构化数据(附详细的代码解释和执行结果截图)
3结构化数据 字典(查找表).集合.元组.列表 3.1字典 是有两列任意多行的表,第一列存储一个键,第二列存储一个值. 它存储键/值对,每个唯一的键有一个唯一与之关联的值.(类似于映射.表) 它不会维 ...
- Java平台调用Python平台已有算法(附源码及解析)
1. 问题描述 Java平台要调用Pyhon平台已有的算法,为了减少耦合度,采用Pyhon平台提供Restful 接口,Java平台负责来调用,采用Http+Json格式交互. 2. 解决方案 2.1 ...
- 零基础学python之函数与模块(附详细的代码和安装发布文件过程)
代码重用——函数与模块 摘要:构建函数,创建模块,安装发布文件,安装pytest和PEP 8插件,确认PEP8兼容性以及纠错 重用代码是构建一个可维护系统的关键. 代码组是Python中对块的叫法. ...
- 手把手教你用Python实现“坦克大战”,附详细代码!
小时候玩的“坦克大战”,你还记得吗? 满满的回忆 ! 今天,我们使用Python以及强大的第三方库来实现一个简单的坦克大战游戏. 整体效果 环境依赖 python3.7 pygame1.9.6 ...
- LTMP手动编译安装以及全自动化部署实践(附详细代码)
大家使用LNMP架构,一般可以理解为Linux Shell为CentOS/RadHat/Fedora/Debian/Ubuntu/等平台安装LNMP(Nginx/MySQL /PHP),LNMPA(N ...
- JavaScript之破解数独(附详细代码)
在上一篇分享中,我们用Python和Django来破解数独,这对不熟悉Python和Django的人来说是非常不友好的.这次,笔者只用HTML和JavaScript写了破解数独的程序,对于熟悉前端 ...
- 动画展现十大经典排序算法(附Java代码)
0.算法概述 0.1 算法分类 十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序. 非比较类排序: ...
随机推荐
- 201871010101- 陈来弟《面向对象程序设计(java)》第6-7周学习总结
201871010101- 陈来弟<面向对象程序设计(java)>第6-7周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh ...
- 莫烦TensorFlow_09 MNIST例子
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_dat ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- [LeetCode] 617. Merge Two Binary Trees 合并二叉树
Given two binary trees and imagine that when you put one of them to cover the other, some nodes of t ...
- [LeetCode] 17. Letter Combinations of a Phone Number 电话号码的字母组合
Given a string containing digits from 2-9inclusive, return all possible letter combinations that the ...
- DingTalk钉钉消息推送(.net core 3 WebApi尝鲜记)
我发了个朋友圈,Swagger真他妈的牛B,解放了开发API的码农,麻麻再也不用担心我们写API文档耽误回家吃饭了. /// <summary> /// 发送钉钉消息 /// </s ...
- 你还在为了JVM而烦恼么?(内存结构和垃圾回收算法)
做JAVA也有接近2年的时间了,公司的leader说,做JAVA,三年是个坎,如果过了三年你还没有去研究JVM的话,那么你这个程序员只能是板砖的工具了.恰逢辞职,来个JVM的解析可好? JVM是J ...
- 联合CRF和字典学习的自顶向下的视觉显著性-全文解读
top-down visual saliency via joint CRF anddictionary learning 自顶向下的视觉显著性是使用目标对象的可判别表示和一个降低搜索空间的概率图来进 ...
- 2018年Java面试题整理
面试是我们每个人都要经历的事情,大部分人且不止一次,这里给大家总结最新的2018年面试题,让大家在找工作时候能够事半功倍. 1. Switch能否用string做参数? a. 在 Java 7 之前 ...
- pymysql模块常用操作
pymysql安装 pip install pymysql 链接数据库.执行sql.关闭连接 import pymysql user = input('请输入用户名请输入密码:').strip() p ...