IDEA创建本地Spark程序,并本地运行
1 IDEA创建maven项目进行测试
v创建一个新项目,步骤如下:
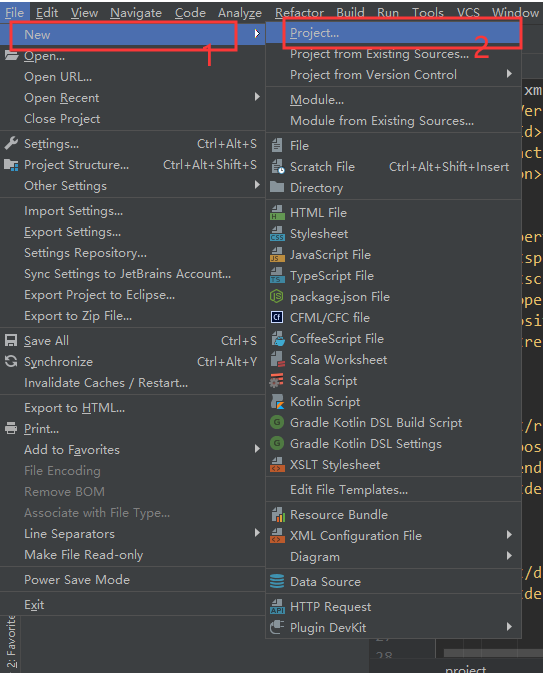

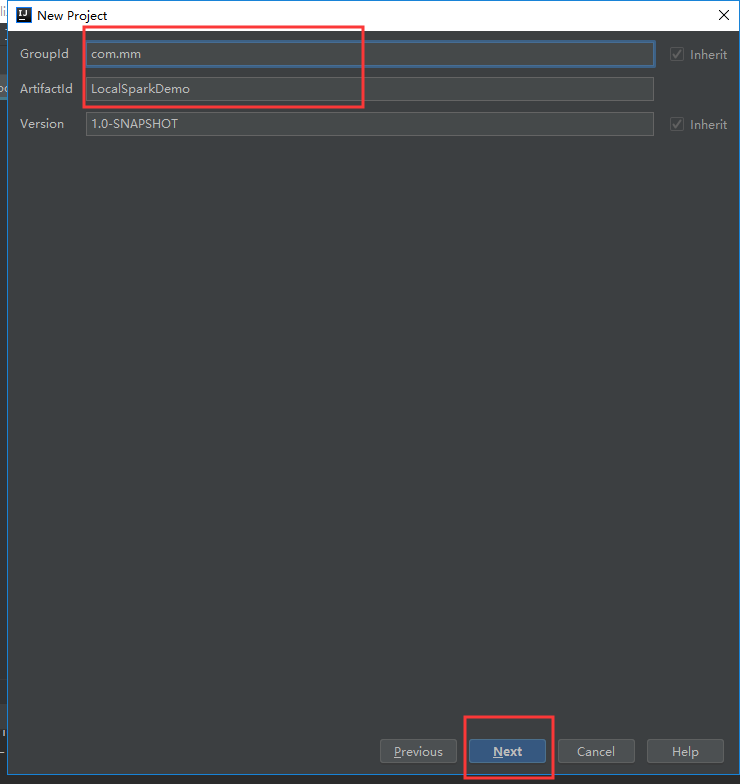
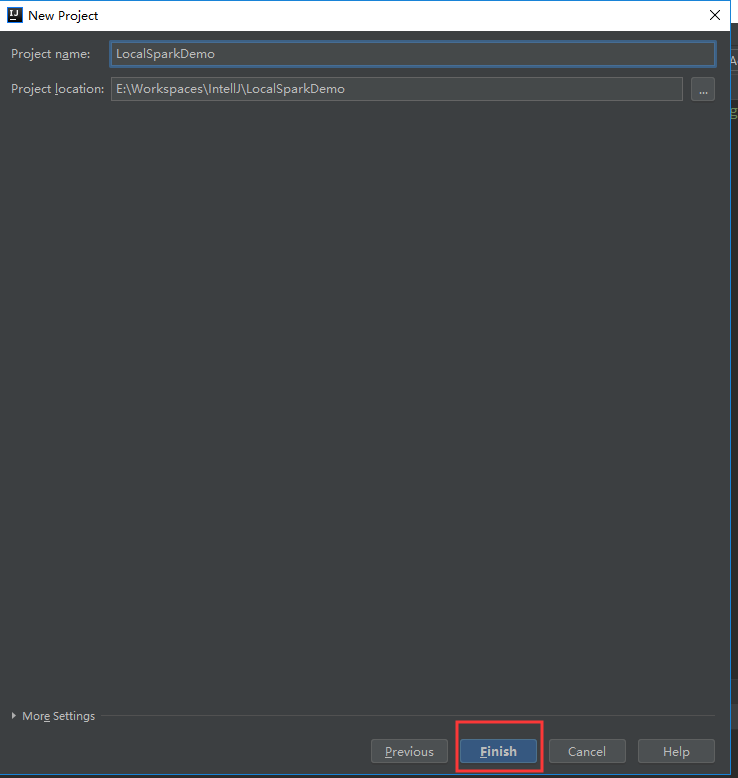
选择“Enable Auto-Import”,加载完后:选择“Enable Auto-Import”,加载完后: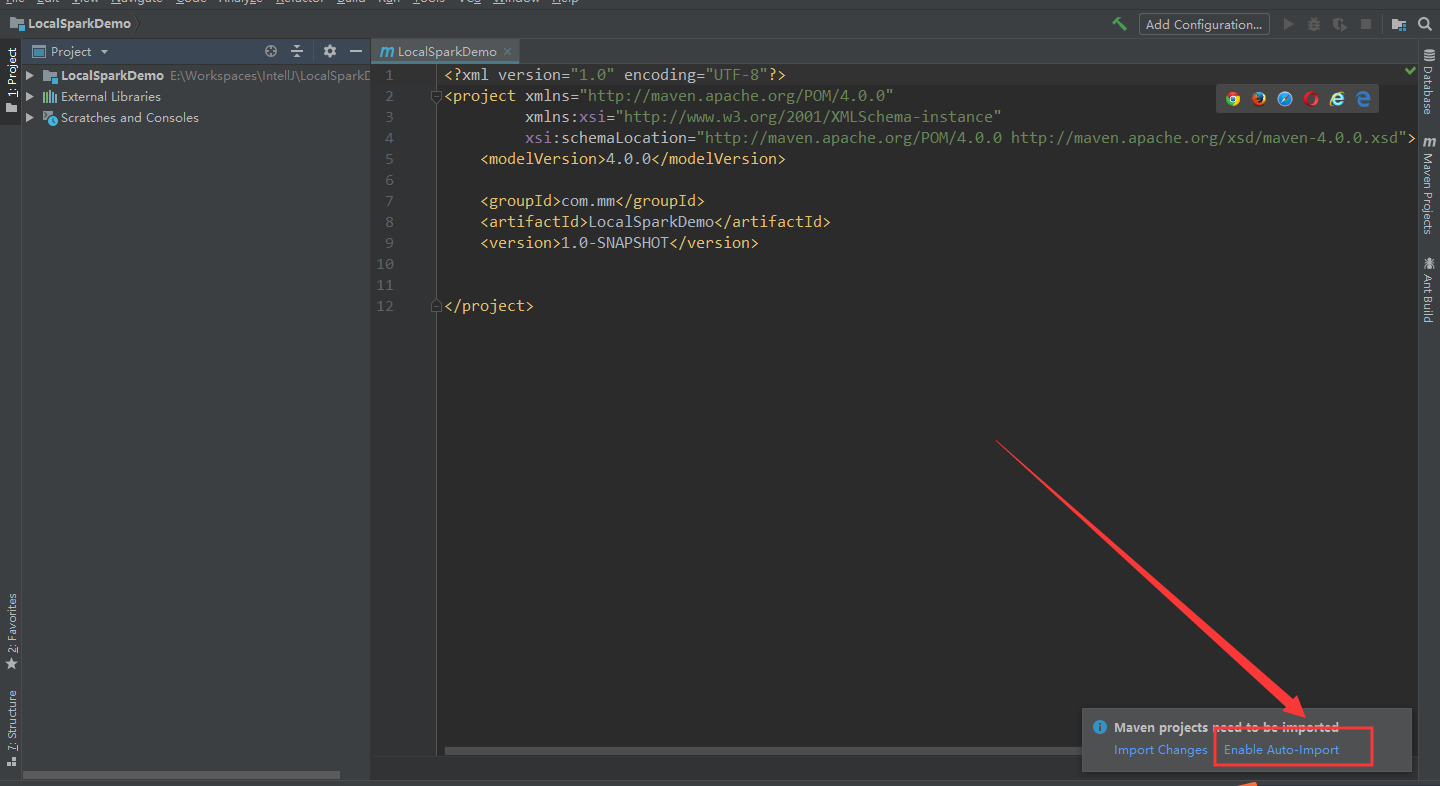
添加SDK依赖:


点击OK ok

可以看到scala包加载成功

再修改pox.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.</modelVersion>
<groupId>com.wangle</groupId>
<artifactId>LocalSpark</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spark.version>2.1.</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build> </project>
新建“Demo1.scala”,测试
IDEA创建本地Spark程序,并本地运行的更多相关文章
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- 如何在本地使用scala或python运行Spark程序
如何在本地使用scala或python运行Spark程序 包含两个部分: 本地scala语言编写程序,并编译打包成jar,在本地运行. 本地使用python语言编写程序,直接调用spark的接口, ...
- Spark程序本地运行
Spark程序本地运行 本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!! spark是基于hadoop运算的,两者有依赖关系,见下图: 前言: 1.环境 ...
- 在IntelliJ IDEA中创建和运行java/scala/spark程序
本文将分两部分来介绍如何在IntelliJ IDEA中运行Java/Scala/Spark程序: 基本概念介绍 在IntelliJ IDEA中创建和运行java/scala/spark程序 基本概念介 ...
- 本地Pycharm将spark程序发送到远端spark集群进行处理
前言 最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置,spark集群安装并集成到hadoop集群, ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
随机推荐
- kafka如何保证数据可靠性和数据一致性
数据可靠性 Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知.本文从 Producter 往 Broker 发送消息.Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠 ...
- for循环的嵌套之打印倒三角的星星
var str = ''; for(var i = 1; i<=10;i++) { for(var j = i; j<=10;j++) { str = str + '★' ; { str ...
- Docer安装及简单使用
前提条件 如果是CentOS8,可以参考这篇文章centos8.0安装docker Docker 运行在 CentOS 7 上,要求系统为64位.系统内核版本为 3.10 以上. Docker 运行在 ...
- springboot项目打包成jar/war包
springboot项目打包过程中包含第三方jar 开发IDE是IntelliJ IDEA,数据库是mysql,内置服务器tomcat. 打包步骤: 1. 确定项目调试运行没问题 2. 将第三方jar ...
- 死磕Java内部类
Java内部类,相信大家都用过,但是多数同学可能对它了解的并不深入,只是靠记忆来完成日常工作,却不能融会贯通,遇到奇葩问题更是难以有思路去解决.这篇文章带大家一起死磕Java内部类的方方面面. 友情提 ...
- pom.xml文件引入tools.jar
最近做hbase开发时,引入相关jar包后,出现了以下错误 Missing artifact jdk.tools:jdk.tools:jar:1.8 绝对地址引用 <dependency> ...
- Nginx通过geo模式实现限速白名单和全局负载均衡 - 运维笔记
Nginx的geo模块不仅可以有限速白名单的作用,还可以做全局负载均衡,可以要根据客户端ip访问到不同的server.比如,可以将电信的用户访问定向到电信服务器,网通的用户重 定向到网通服务器”,从而 ...
- win7下每次打开Excel2007都提示向程序发送命令时出现问题的解决方案
每次打开Excel2007都提示向程序发送命令时出现问题,要打开两次才可以打开,下面介绍该问题的解决办法. 第一种情况:也就是屏蔽DDE的解决方案,这是大多数人都是这种情况,该情况的解决办法: exc ...
- losetup命令使用
1.losetup命令 Linux系统losetup命令用来设置循坏设备,循坏设备可以把文件虚拟成块设备,借此来模拟整个文件系统,让用户得以将其视为硬盘驱动器,光驱等设备,并挂入当作目录来使用. (1 ...
- Controller如何进行重定向跳转
因为在Controller的返回都是默认走视图解析器的InternalResourceViewResolver,而视图解析器都是进行请求转发,需要在返回时地址前加入字符redirect: 视图解析器不 ...