Research Guide: Pruning Techniques for Neural Networks
Research Guide: Pruning Techniques for Neural Networks
2019-11-15 20:16:54
Original: https://heartbeat.fritz.ai/research-guide-pruning-techniques-for-neural-networks-d9b8440ab10d
Pruning is a technique in deep learning that aids in the development of smaller and more efficient neural networks. It’s a model optimization technique that involves eliminating unnecessary values in the weight tensor. This results in compressed neural networks that run faster, reducing the computational cost involved in training the networks. This is even more crucial when deploying models to mobile phones or other edge devices. In this guide, we’ll look at some of the research papers in the field of pruning neural networks.
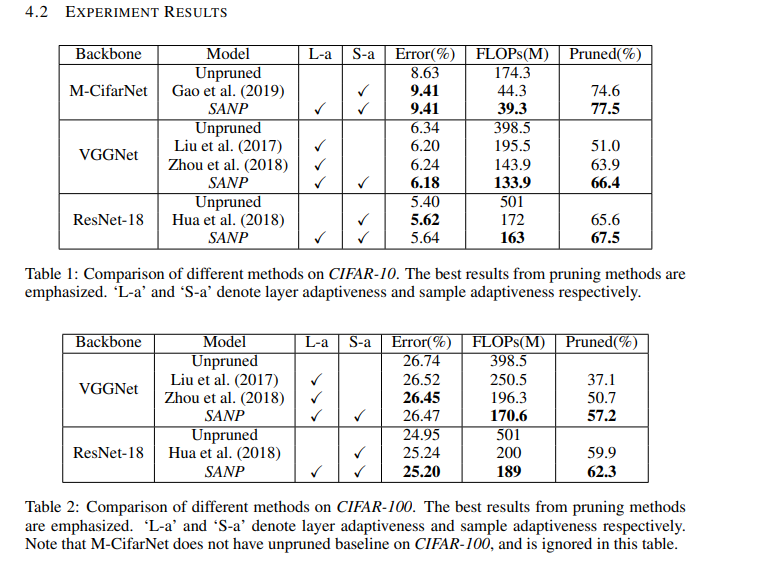
Pruning from Scratch (2019)
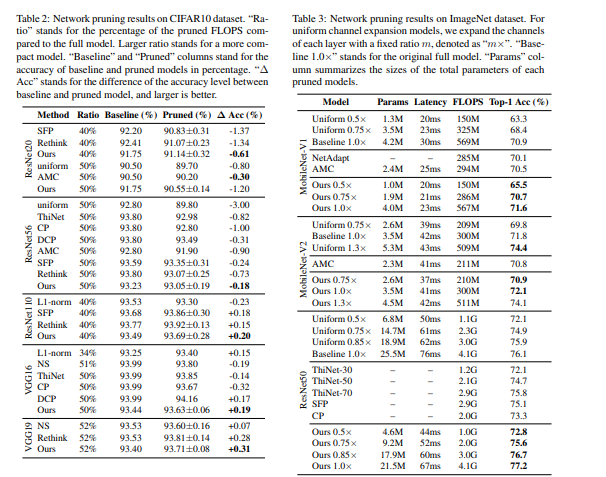
The authors of this paper propose a network pruning pipeline that allows for pruning from scratch. Based on experimentation with compression classification models on CIFAR10 and ImageNet datasets, the pipeline reduces pre-training overhead incurred while using normal pruning methods, and also increases the accuracy of the networks.
Below is an illustration of the three stages involved in the traditional pruning process. This process involves pre-training, pruning, and fine-tuning.

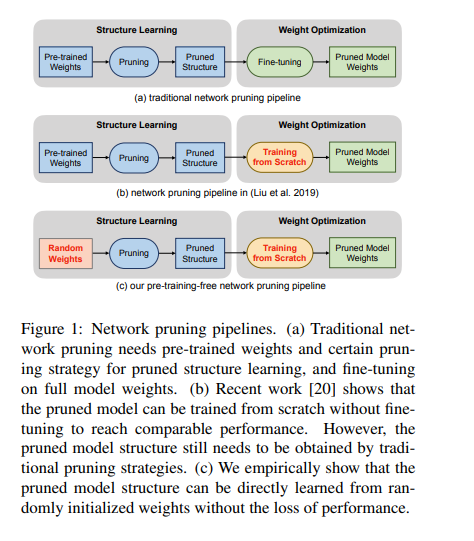
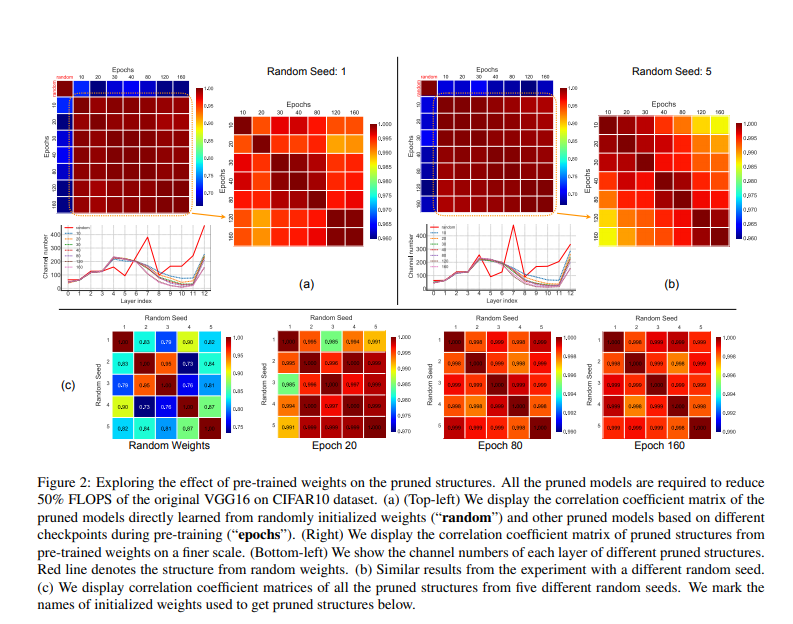
The pruning technique proposed in this paper involves building a pruning pipeline that can be learned from randomly initialized weights. Channel importance is learned by associating scalar gate values with each network layer.
The channel importance is optimized to improve the model performance under the sparsity regularization. During this process, the random weights are not updated. Afterward, a binary search strategy is used to determine the channel number configurations of the pruned model, given resource constraints.

Here’s a look at model accuracy obtained on various datasets:

Optimizing ML models is especially important (and tricky) when deploying to low-power devices like smartphones. Fritz AI has the expertise and the tools designed to help make this process as easy as possible.
Adversarial Neural Pruning (2019)
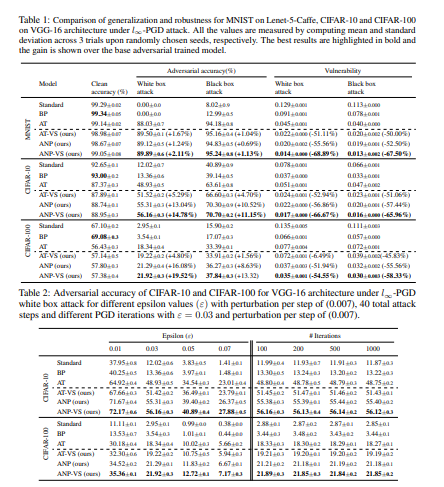
This paper considers the distortion problem of latent features of a network in the presence of adversarial perturbation. The proposed method learns a bayesian pruning mask to suppress the higher distorted features in order to maximize its robustness on adversarial deviations.
The authors consider the vulnerability of latent features in deep neural networks. The method proposed prunes out vulnerable features while preserving robust ones. This is done by adversarially learning the pruning mask in a Bayesian framework.


Adversarial Neural Pruning (ANP) combines the concept of adversarial training with the Bayesian pruning methods. The baseline for this method is:
- a standard convolutional neural network
- the adversarial trained network
- adversarial neural pruning with beta-Bernoulli dropout
- the adversarial trained network regularized with vulnerability suppression loss
- the adversarial neural pruning network regularized with vulnerability suppression loss
Here’s a table showing the performance of the model.

Rethinking the Value of Network Pruning (ICLR 2019)
The network pruning methods proposed in this paper are divided into two categories. The target pruned model’s architecture is determined by either a human or a pruning algorithm. In experimentation, the authors also compare the results obtained by training pruned models from scratch and fine-tuning from inherited weights for both predefined and automatic methods.
The figure below shows the results obtained for predefined structured pruning using L1-norm based filter pruning. Each layer involves pruning a certain percentage of filters with smaller L1-norm. The Pruned Model column represents the list of predefined target models used to configure each model. The observation is that in each row, scratch-trained models achieve at least the same level of accuracy as fine-tuned models.


As shown below, ThiNet greedily prunes the channel that has the smallest effect on the next layer’s activation values.

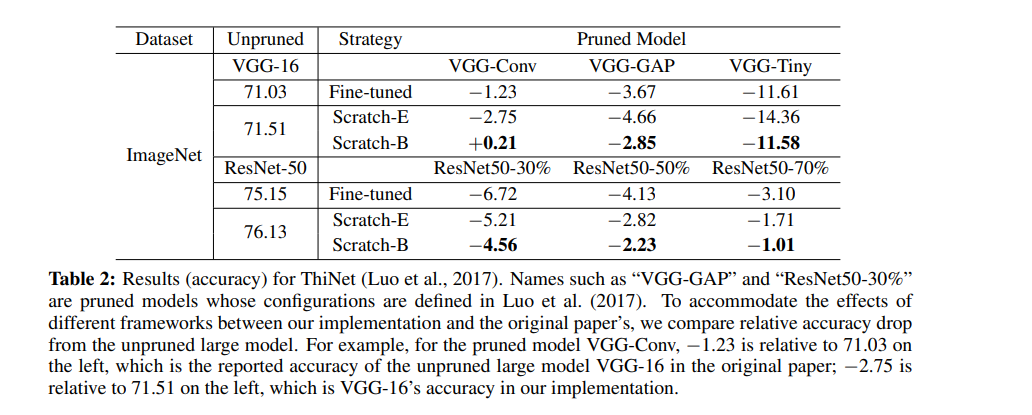
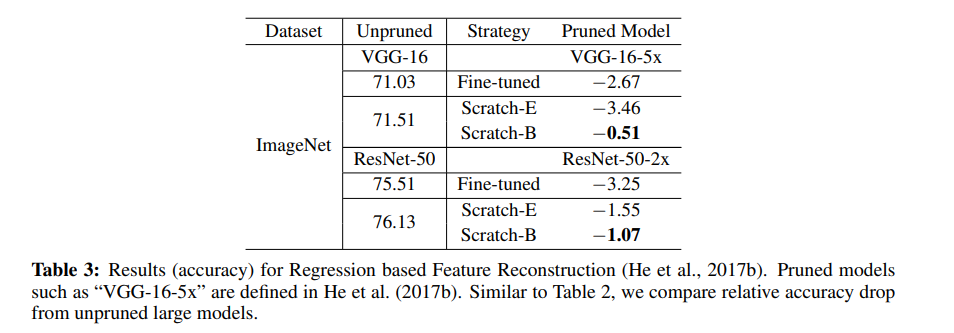
The next table shows the results obtained by Regression-based Feature Reconstruction. The method prunes channels by minimizing the feature map reconstruction error of the next layer. This optimization problem is solved by LASSO regression.

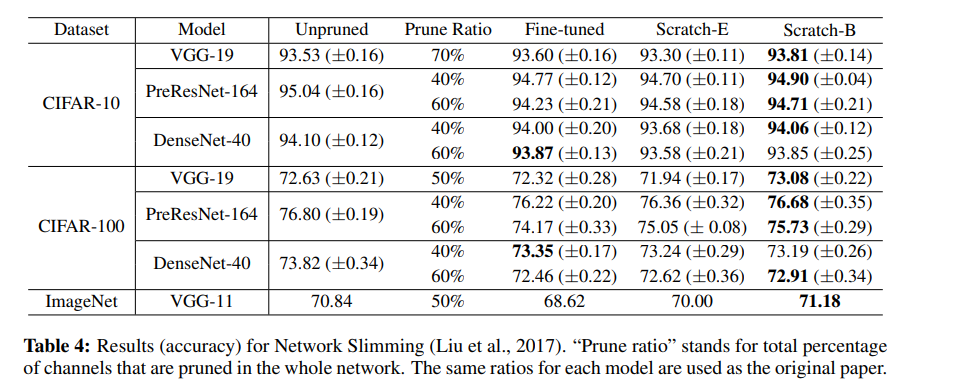
For Network Slimming, L1-sparsity is imposed on channel-wise scaling factors from Batch Normalization layers during training. It prunes channels with lower scaling factors afterward. This method produces automatically discovered target architectures since the channel scaling factors are compared across layers.

Deep learning — for experts, by experts. We’re using our decades of experience to deliver the best deep learning resources to your inbox each week.
Network Pruning via Transformable Architecture Search (NeurIPS 2019)
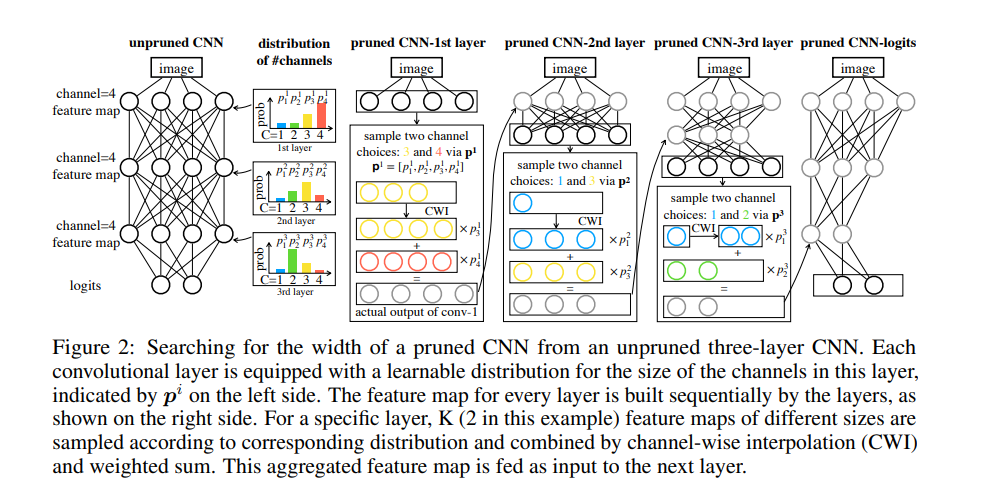
This paper proposes applying neural architecture search directly for a network with a flexible channel and layer sizes. Minimizing the loss of the pruned networks aids in learning the number of channels. The feature map of the pruned network is made up of K feature map fragments that are sampled based on the probability distribution. The loss is back-propagated to the network weights and to the parameterized distribution.
The width and depth of the pruned network are obtained from the maximum probability for the size in each distribution. These parameters are learned by knowledge transfer from the original networks. Experiments on the model are done on CIFAR-10, CIFAR-100, and ImageNet.

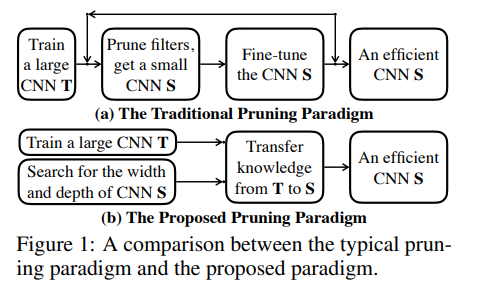
This approach of pruning consists of three stages:
- Training an unpruned large network with a standard classification training procedure.
- Searching for the depth and width of a small network via Transformable Architecture Search (TAS). TAS aims at searching for the best size of a network.
- Transferring the information from the unpruned network to the searched small network by a simple knowledge distillation (KD) approach.

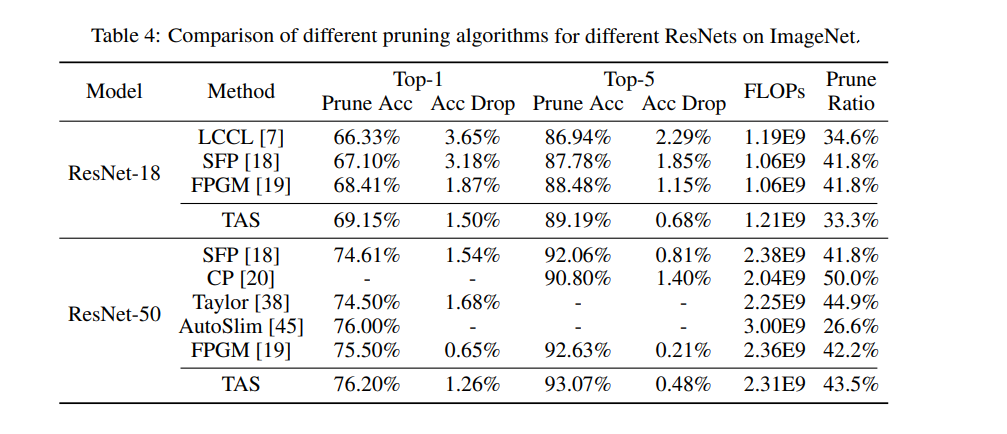
Here’s a comparison of different pruning algorithms for different ResNets on ImageNet:

Self-Adaptive Network Pruning (ICONIP 2019)
This paper proposes reducing the computational cost of CNNs via a self-adaptive network pruning method (SANP). The method does so by introducing a Saliency-and-Pruning Module (SPM) for each convolutional layer. This module learns to predict saliency scores and applies pruning to each channel. SANP determines the pruning strategy with respect to each layer and each sample.
As seen in the architecture diagram below, the Saliency-and-Pruning module is embedded in each layer of the convolutional network. The module predicts saliency scores for the channels. This is done based on input features. Pruning decisions for each channel are then generated.
The convolution operation is skipped for channels whose corresponding pruning decision is 0. The backbone network and the SPMs are then jointly trained with the classification and cost objectives. The computation costs are estimated depending on the pruning decision in each layer.


Some of the results obtained by this method are shown below:

Structured Pruning of Large Language Models (2019)
The pruning method proposed in this paper is based on low-rank factorization and augmentedLagrangian 10 norm regularization. 10 regularization relaxes the constraints imposed from structured pruning, while low-rank factorization enables retention of the dense structure of the matrices.
Regularization enables the network to choose which weights to remove. The weight matrices are factorized into two smaller matrices. A diagonal mask between these two matrices is then set. The mask is pruned during training via 10 regularization. The augmented Lagrangian approach is used to control the final sparsity level of the model. The authors refer to their method as FLOP (Factorized L0 Pruning).
The character-level language model used is the enwik8 dataset that contains 100M bytes of data taken from Wikipedia. FLOP is evaluated on SRU and Transformer-XL. Some of the results obtained are shown below.


Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — pruning techniques
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to exploring the emerging intersection of mobile app development and machine learning. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Fritz AI, the machine learning platform that helps developers teach devices to see, hear, sense, and think. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and Heartbeat), join us on Slack, and follow Fritz AI on Twitter for all the latest in mobile machine learning.
Research Guide: Pruning Techniques for Neural Networks的更多相关文章
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks Part 2
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- A Beginner's Guide To Understanding Convolutional Neural Networks(转)
A Beginner's Guide To Understanding Convolutional Neural Networks Introduction Convolutional neural ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- A Beginner's Guide To Understanding Convolutional Neural Networks Part One (CNN)笔记
原文链接:https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolu ...
- 论文笔记——Data-free Parameter Pruning for Deep Neural Networks
论文地址:https://arxiv.org/abs/1507.06149 1. 主要思想 权值矩阵对应的两列i,j,如果差异很小或者说没有差异的话,就把j列与i列上(合并,也就是去掉j列),然后在下 ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- [转]An Intuitive Explanation of Convolutional Neural Networks
An Intuitive Explanation of Convolutional Neural Networks https://ujjwalkarn.me/2016/08/11/intuitive ...
- An Intuitive Explanation of Convolutional Neural Networks
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ An Intuitive Explanation of Convolu ...
- 一目了然卷积神经网络 - An Intuitive Explanation of Convolutional Neural Networks
An Intuitive Explanation of Convolutional Neural Networks 原文地址:https://ujjwalkarn.me/2016/08/11/intu ...
随机推荐
- Java 之 LinkedHashSet 集合
一.概述 java.util.LinkedHahset 集合 extends HashSet 集合 在HashSet下面有一个子类java.util.LinkedHashSet,它的底层是一个哈希表( ...
- ES6 对象解构赋值(浅拷贝 VS 深拷贝)
对象的扩展运算符(...)用于取出参数对象的所有可遍历属性,拷贝到当前对象之中. 拷贝对象 let aa = { age: 18, name: 'aaa' } let bb = {...aa}; co ...
- 排序算法的c++实现——插入排序
插入排序的思想是:给定一个待排序的数组,我们从中选择第一个元素作为有序的基态(单个元素肯定是有序的), 然后从剩余的元素中选择一个插入到有序的基态中,使插入之后的序列也是有序状态,重复此过程,直到全部 ...
- DTC测试
DTC配置好后要在2台server之间测试下是否能使用. 1.在A台上建立ODBC的连接B. 控制面板→管理工具→ODBC Datat Source(32bit) 点击添加 选择SQL SERVER ...
- Intel网卡的漫游主动性
- 浅谈flask源码之请求过程
更新时间:2018年07月26日 09:51:36 作者:Dear. 我要评论 这篇文章主要介绍了浅谈flask源码之请求过程,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟随 ...
- PAT甲级1017题解——模拟排序
题目分析: 本题我第一次尝试去做的时候用的是优先队列,但是效率不仅代码量很大,而且还有测试样例过不去,很显然没有找到一个好的数据结构来解决这道题目(随着逐渐的刷PAT甲级的题会发现有时选择一个好的解题 ...
- httprunner学习12-hook 机制实现setup和teardown
前言 unittest框架里面有个非常好的概念:前置( setUp )和后置( tearDown )处理器,真正会用的人不多. HttpRunner 实际上也是从用的unittest框架,里面也有前置 ...
- JavaScript基础13——面向对象
什么是面向对象? 面向对象(Object Oriented,OO)是软件开发方法.面向对象的概念和应用已超越了程序设计和软件开发,扩展到如数据库系统,交互式界面,应用结构,应用平台,分布式系统,网络管 ...
- 大文件断点续传插件webupload插件
java两台服务器之间,大文件上传(续传),采用了Socket通信机制以及JavaIO流两个技术点,具体思路如下: 实现思路: 1.服:利用ServerSocket搭建服务器,开启相应端口,进行长连接 ...