k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律。
我们知道,在机器学习中,有三种不同的学习模式:监督学习、无监督学习和强化学习:
- 监督学习,也称为有导师学习,网络输入包括数据和相应的输出标签信息。例如,在 MNIST 数据集中,手写数字的每个图像都有一个标签,代表图片中的数字值。
- 强化学习,也称为评价学习,不给网络提供期望的输出,但空间会提供给出一个奖惩的反馈,当输出正确时,给网络奖励,当输出错误时就惩罚网络。
- 无监督学习,也称为无导师学习,在网络的输入中没有相应的输出标签信息,网络接收输入,但既没有提供期望的输出,也没有提供来自环境的奖励,神经网络要在这种情况下学习输入数据中的隐藏结构。无监督学习非常有用,因为现存的大多数数据是没有标签的,这种方法可以用于诸如模式识别、特征提取、数据聚类和降维等任务。
k 均值聚类是一种无监督学习方法。
还记得哈利波特故事中的分院帽吗?那就是聚类,将新学生(无标签)分成四类:格兰芬多、拉文克拉、赫奇帕奇和斯特莱林。
人是非常擅长分类的,聚类算法试图让计算机也具备这种类似的能力,聚类技术很多,例如层次法、贝叶斯法和划分法。k 均值聚类属于划分聚类方法,将数据分成 k 个簇,每个簇有一个中心,称为质心,k 值需要给定。
k 均值聚类算法的工作原理如下:
- 随机选择 k 个数据点作为初始质心(聚类中心)。
- 将每个数据点划分给距离最近的质心,衡量两个样本数据点的距离有多种不同的方法,最常用的是欧氏距离。
- 重新计算每个簇的质心作为新的聚类中心,使其总的平方距离达到最小。
- 重复第 2 步和第 3 步,直到收敛。
准备工作
使用 TensorFlow 的 Estimator 类 KmeansClustering 来实现 k 均值聚类,具体实现可参考https://github.com/tensorflow/tensorflow/blob/r1.3/tensorflow/contrib/learn/python/learn/estimators/kmeans.py,可以直接进行 k 均值聚类和推理。根据 TensorFlow 文档,KmeansClustering 类对象可以使用以下__init__方法进行实例化:

TensorFlow 文档对这些参数的定义如下:
- num_clusters:要训练的簇数。
- model_dir:保存模型结果和日志文件的目录。
- initial_clusters:指定如何对簇初始化,取值请参阅 clustering_ops.kmeans。
- distance_metric:聚类的距离度量方式,取值请参阅 clustering_ops.kmeans。
- random_seed:Python 中的整数类型,用于初始化质心的伪随机序列发生器的种子。
- use_mini_batch:如果为 true,运行算法时分批处理数据,否则一次使用全部数据集。
- mini_batch_steps_per_iteration:经过指定步数后将计算的簇中心更新回原数据。更多详细信息参见 clustering_ops.py。
- kmeans_plus_plus_num_retries:对于在 kmeans++ 方法初始化过程中采样的每个点,该参数指定在选择最优值之前从当前分布中提取的附加点数。如果指定了负值,则使用试探法对 O(log(num_to_sample)) 个附加点进行抽样。
- relative_tolerance:相对误差,在每一轮迭代之间若损失函数的变化小于这个值则停止计算。有一点要注意就是,如果将 use_mini_batch 设置为 True,程序可能无法正常工作。
配置:请参阅 Estimator。
TensorFlow 支持将欧氏距离和余弦距离作为质心的度量,KmeansClustering 类提供了多种交互方法。在这里使用 fit()、clusters() 和 predict_clusters_idx() 方法:

根据 TensorFlow 文档描述,需要给 fit() 提供 input_fn() 函数,cluster 方法返回簇质心,predict_cluster_idx 方法返回得到簇的索引。
具体做法
- 与以前一样,从加载必要的模块开始,这里需要 TensorFlow、NumPy 和 Matplotlib。这里使用鸢尾花卉数据集,该数据集分为三类,每类都是指一种鸢尾花卉,每类有 50 个实例。可以从https://archive.ics.uci.edu/ml/datasets/iris上下载 .csv 文件,也可以使用 sklearn 库的数据集模块(scikit-learn)来加载数据:

- 加载数据集:

- 绘出数据集查看一下:

代码输出如下:
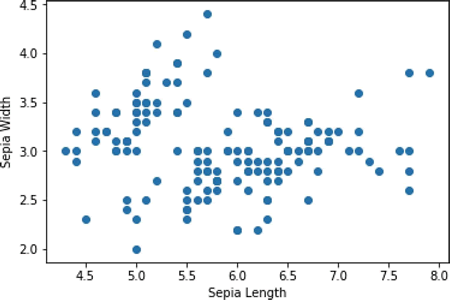
- 可以看到数据中并没有明显可见的分类。定义 input_fn 来给 fit() 方法输入数据,函数返回一个 TensorFlow 常量,用来指定x的值和维度,类型为 float。
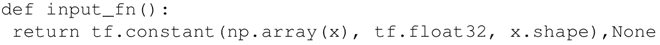
- 开始使用 KmeansClustering 类,分为 3 类,设置 num_clusters=3。通常情况下事先并不知道最优的聚类数量,在这种情况下,常用的方法是采用肘部法则(elbow method)来估计聚类数量:

- 使用 clusters() 方法找到这些簇,使用 predict_cluster_idx() 方法为每个输入点计算分配的簇索引:
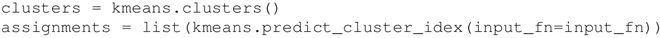
- 对创建的簇进行可视化操作,创建一个包装函数 ScatterPlot,它将每个点的 X 和 Y 值与每个数据点的簇和簇索引对应起来:

使用下面的函数画出簇:
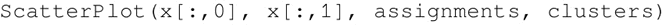
结果如下:
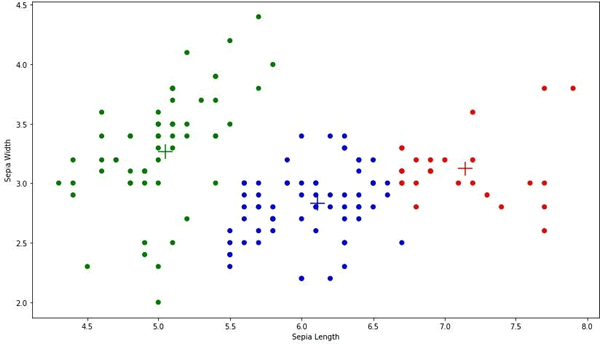
其中“+”号代表三个簇的质心。
解读分析
上面的案例中使用 TensorFlow Estimator 的 k 均值聚类进行了聚类,这里是提前知道簇的数目,因此设置 num_clusters=3。但是在大多数情况下,数据没有标签,我们也不知道有多少簇存在,这时候可以使用肘部法则确定簇的最佳数量。
肘部法则选择簇数量的原则是减少距离的平方误差和(SSE),随着簇数量 k 的增加,SSE 是逐渐减小的,直到 SSE=0,当k等于数据点的数量时,每个点都是自己的簇。
这里想要的是一个较小的 k 值,而且 SSE 也较小。在 TensorFlow 中,可以使用 KmeansClustering 类中定义的 score() 方法计算 SSE,该方法返回所有样本点距最近簇的距离之和:
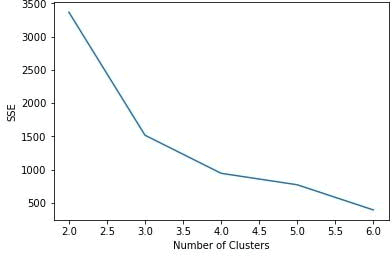
对于鸢尾花卉数据,如果针对不同的 k 值绘制 SSE,能够看到 k=3 时,SSE 的变化是最大的;之后变化趋势减小,因此肘部 k 值可设置为 3:
k 均值聚类因其简单、快速、强大而被广泛应用,当然它也有不足之处,最大的不足就是用户必须指定簇的数量;其次,算法不保证全局最优;再次,对异常值非常敏感。
k均值聚类算法原理和(TensorFlow)实现的更多相关文章
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
随机推荐
- CyclicBarrier一组线程相互等待
/** * CyclicBarrier 一组线程相互等待 */ public class Beer { public static void main(String[] args) { final ; ...
- java8时间处理实例
实例: package com.javaBase.time; import java.time.Clock; import java.time.LocalDate; import java.time. ...
- JavaScaript学习笔记第(一)
js由三部分组成,分别是ECMAScript.DOM.BOM 其中ECMAScript规定了js的语法 js是一门解释型语言.脚本语言.动态类型语言.基于对象语言 书写js代码和CSS一样,有三个书写 ...
- vue v-for 使用问题整理
今天使用v-for指令的时候遇到一个错误 [Vue warn]: Error in render: "TypeError: Cannot read property 'children' o ...
- Springboot项目中pom.xml的Oracle配置错误问题
这几天刚开始学习Springboot碰见各种坑啊,这里记录一个添加Oracle引用的解决方案. 前提:开发工具IDEA2019.2,SpringBoot,maven项目:Oracle版本是Oracle ...
- MVC下通过jquery的ajax调用webapi
如题 jquery的应用,不会的自己去补. 创建一个mvc项目,新建控制器.视图如下: 其中data控制器负责向前台提供数据,home控制器是一个简单的访问页控制器. data控制器代码如下: pub ...
- Mark: 如何用Haskell写一个简单的编译器
作者:aaaron7 链接:https://www.zhihu.com/question/36756224/answer/88530013 如果是用 Haskell 的话,三篇文章足矣. prereq ...
- spring AOP的两种配置
xml配置 定义要被代理的方法的接口 public interface TestAop { public void print(String s); } 实现上述接口 public class Tes ...
- 字符串替换replace方法
字符串替换replace方法: http://www.w3school.com.cn/jsref/jsref_replace.asp http://www.cnblogs.com/skywang/ar ...
- Java 之 枚举(Enum)
一.枚举 1.概述 枚举:JDK1.5引入的,类似于穷举,一一罗列出来 Java 枚举:把某个类型的对象,全部列出来 2.应用 什么情况下会用到枚举类型? 当某个类型的对象是固定的,有限的几个,那么就 ...