【hbase】hbase理论学习
HBase用途:
基于Hadoop Distributed File System,是一个开源的,基于列存储模型的分布式数据库。
HBase简介:
HBase是一个分布式的、多版本的、面向列的开源数据库
1)利用Hadoop HDFS作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
2)利用Hadoop MapReduce来处理HBase中的海量数据
3)利用Zookeeper作为协同服务。
HBase中表的特点:
1)大:一个表可以有上亿行,上百万列(列多时,插入变慢)
2)面向列:面向列(族)的存储和权限控制,列(族)独立检索。
3)稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
4)每个cell中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
5)HBase中的数据都是字符串,没有类型;
HBase 特点:
1)强一致性:同一行数据的读写只在同一台Region Server上进行
2)水平伸缩:Region的自动分裂以及Master的balance;
只用增加Datanode机器即可增加容量;
只用增加Region Server机器即可增加读写吞吐量
3)支持有限查询方式和一级索引:
仅支持单行事务
仅支持三种查询方式(single row key、range row key、scan all rows of table)【可通过hive等实现多表关联查询】
仅基于row key的索引
4)高性能随机写:WAL (Write Ahead Log)
HBase与RDBMS对比:
注:DBMS即关系数据库管理系统(Relational Database Management System),是将数据组织为相关的行和列的系统,而管理关系数据库的计算机软件就是关系数据库管理系统,常用的数据库软件有Oracle、SQL Server等。
Hbase基本用法:
(1)建立一个表scores,有两个列族grad和courese
代码如下:
hbase(main):001:0> create ‘scores','grade', ‘course'
可以使用list命令来查看当前HBase里有哪些表。使用describe命令来查看表结构。
(记得所有的表明、列名都需要加上引号)
(2)按设计的表结构插入值:
代码如下:
put ‘scores','Tom','grade:','5′
put ‘scores','Tom','course:math','97′
put ‘scores','Tom','course:art','87′
put ‘scores','Jim','grade:','4′
put ‘scores','Jim','course:english','89′
put ‘scores','Jim','course:art','80′
这样表结构就起来了,其实比较自由,列族里边可以自由添加子列很方便。如果列族下没有子列,加不加冒号都是可以的。
put命令比较简单,只有这一种用法:
hbase> put ‘tablename′, ‘rowname′, ‘colname′, ‘value', timestamp
注:tablename指表名,rowname指行键名,colname指列名,value指单元格值。timestamp指时间戳,一般都省略掉了
(3)根据键值查询数据
get ‘scores’,‘Jim’
get ‘scores’,‘Jim’,‘grade’
可能会发现规律了,HBase的shell操作,一个大概顺序就是操作关键词后跟表名,行名,列名这样的一个顺序,如果有其他条件再用花括号加上。
get有用法如下:
hbase> get ‘t1′, ‘r1′
hbase> get ‘t1′, ‘r1′, {TIMERANGE => [ts1, ts2]}
hbase> get ‘t1′, ‘r1′, {COLUMN => ‘c1′}
hbase> get ‘t1′, ‘r1′, {COLUMN => ['c1', 'c2', 'c3']}
hbase> get ‘t1′, ‘r1′, {COLUMN => ‘c1′, TIMESTAMP => ts1}
hbase> get ‘t1′, ‘r1′, {COLUMN => ‘c1′, TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> get ‘t1′, ‘r1′, {COLUMN => ‘c1′, TIMESTAMP => ts1, VERSIONS => 4}
hbase> get ‘t1′, ‘r1′, ‘c1′
hbase> get ‘t1′, ‘r1′, ‘c1′, ‘c2′
hbase> get ‘t1′, ‘r1′, ['c1', 'c2']
(4)扫描所有数据 scan ‘scores'
也可以指定一些修饰词:TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH,or COLUMNS。没任何修饰词,就是上边例句,就会显示所有数据行。
例句如下:
hbase> scan ‘.META.'
hbase> scan ‘.META.', {COLUMNS => ‘info:regioninfo'}
hbase> scan ‘t1′, {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => ‘xyz'}
hbase> scan ‘t1′, {COLUMNS => ‘c1′, TIMERANGE => [1303668804, 1303668904]}
hbase> scan ‘t1′, {FILTER => “(PrefixFilter (‘row2′) AND (QualifierFilter (>=, ‘binary:xyz'))) AND (TimestampsFilter ( 123, 456))”}
hbase> scan ‘t1′, {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
过滤器filter有两种方法指出:
a. Using a filterString – more information on this is available in the Filter Language document attached to the HBASE-4176 JIRA
b. Using the entire package name of the filter.
还有一个CACHE_BLOCKS修饰词,开关scan的缓存的,默认是开启的(CACHE_BLOCKS=>true),可以选择关闭(CACHE_BLOCKS=>false)。
(5)删除指定数据
代码如下:
delete ‘scores','Jim','grade' delete ‘scores','Jim'
删除数据命令也没太多变化,只有一个:
hbase> delete ‘t1′, ‘r1′, ‘c1′, ts1
另外有一个deleteall命令,可以进行整行的范围的删除操作,慎用!
如果需要进行全表删除操作,就使用truncate命令,其实没有直接的全表删除命令,这个命令也是disable,drop,create三个命令组合出来的。
(6)统计行数:
代码如下:
hbase> count ‘t1′
hbase> count ‘t1′, INTERVAL => 100000
hbase> count ‘t1′, CACHE => 1000
hbase> count ‘t1′, INTERVAL => 10, CACHE => 1000
count一般会比较耗时,使用mapreduce进行统计,统计结果会缓存,默认是10行。统计间隔默认的是1000行(INTERVAL)。
(7)修改表结构
代码如下:
disable ‘scores'
alter ‘scores',NAME=>'info'
enable ‘scores'
alter命令使用如下(如果无法成功的版本,需要先通用表disable):
a、改变或添加一个列族:
hbase> alter ‘t1′, NAME => ‘f1′, VERSIONS => 5
b、删除一个列族:
hbase> alter ‘t1′, NAME => ‘f1′, METHOD => ‘delete' hbase> alter ‘t1′, ‘delete' => ‘f1′
c、也可以修改表属性如MAX_FILESIZE MEMSTORE_FLUSHSIZE, READONLY,和 DEFERRED_LOG_FLUSH:
hbase> alter ‘t1′, METHOD => ‘table_att', MAX_FILESIZE => '134217728′
d、可以一次执行多个alter命令:
hbase> alter ‘t1′, {NAME => ‘f1′}, {NAME => ‘f2′, METHOD => ‘delete'}
HBase的体系结构:

Client
* 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
* 保证任何时候,集群中只有一个master
* 存贮所有Region的寻址入口。
* 实时监控Region server的上线和下线信息。并实时通知给Master
* 存储HBase的schema和table元数据
Master
* 为Region server分配region
* 负责Region server的负载均衡
* 发现失效的Region server并重新分配其上的region
* 管理用户对table的增删改查操作
Region Server
* Region server维护region,处理对这些region的IO请求
* Region server负责切分在运行过程中变得过大的region
HBase数据表的一些关键概念:
Row key键:
a.表中行的键是字节数组(最大长度是 64KB )
b.任何字符串都可以作为键;
c.表中的行根据行的键值进行排序,数据按照Row key的字节序(byte order)排序存储;
d.字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行键必须用0作左填充
e.所有对表的访问都要通过键
f.通过单个row key访问
g.通过row key的range
h.全表扫描
Column Family列族:
a.HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
b.列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english,
c.新的列族成员可以随后按需、动态加入;
d.权限控制、存储以及调优都是在列族层面进行的;
e.同一列族成员最好有相同的访问模式和大小特征;
f.HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
Cell qualifier列族修饰符(列):
a.通过列族:单元格修饰符,可以具体到某个列;
b.可以把单元格修饰符认为是实际的列名;
c.在列族存在,客户端随时可以把列添加到列族;
Timestamp时间戳:
a.在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
b.时间戳的类型是 64位整型。
c.时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
d.时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
Region区域:
a.HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;
b.每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region;
c.当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Region 上。
HBase物理存储
1、Table中的所有行都按照row key的字典序排列。
2、Table 在行的方向上分割为多个HRegion。
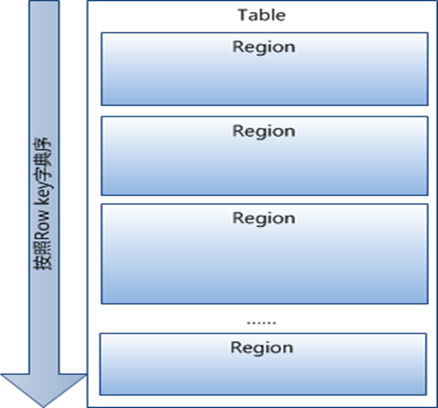
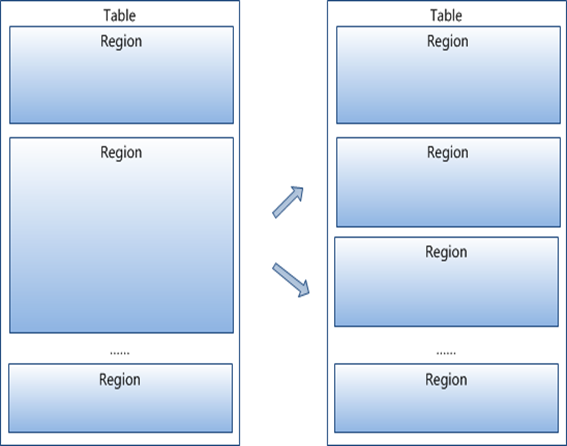
3、Region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,HRegion就会等分会两个新的HRegion。当table中的行不断增多,就会有越来越多的HRegion。
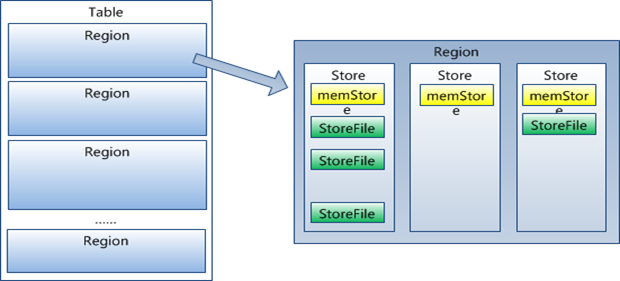
4 、HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的HRegion server上。但一个HRegion是不会拆分到多个server上的。
5 、HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成。
如图:StoreFile以HFile格式保存在HDFS上。
HFile分为六个部分:
Data Block 段:保存表中的数据,这部分可以被压缩
Meta Block段 (可选的):保存用户自定义的kv对,可以被压缩。
File Info 段:HFile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段:Data Block的索引。每条索引的key是被索引的 block的第一条记录的key。
Meta Block Index段 (可选的):Meta Block的索引。
Trailer段:这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会
首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来 做安全check),然后,DataBlock
Index会被读取到内存中,这样,当检索
某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个
block读取到内存中,再找到需要的key
➜ Data Block Index采用LRU机制淘汰。
➜ HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
➜ 目标Hfile的压缩支持两种方式:Gzip,Lzo。
【hbase】hbase理论学习的更多相关文章
- [HBase] - Hbase调优1
版本:HBase-0.98.6-cdh5.3.6 HBase参数调优 1. zookeeper.session.timeout: 默认90000(毫秒), 控制连接zk的timeout时间.由于hba ...
- [Hbase]Hbase章4 Hbase分区爆了
又搞事了,发生了啥事呢:生产分区数暴了,What? 目前的情况: 前提:单Region Server分区上限设置为1000: 目前A表的数据量半年达到25E,20G一分区,达到了900多个分区,这是要 ...
- [hbase] hbase 基础使用
一.准备 hadoop 2.8.0 (提前配置好) hbase 1.2.6 zookeeper 3.4.9 (配置完成) jdk1.8 hadoop 集群信息: zk集群: 二.安装配置 1.下载(官 ...
- [Hbase]Hbase章3 Hbase单点故障
很长一段时间以来,一个region同一时间只能在一台RS(Region Server)中打开.如果一个region同时在多个RS上打开,就是multi-assign问题,会导致数据不一致甚至丢数据的情 ...
- [Hbase]Hbase章2 Hbase读写过程解析
写数据 Hbase使用memstore和storefile存储对表的更新.数据在更新时首先写入hlog和memstore,memstore中的数据是排序的,当memstore累计到一定的阀值时,就会创 ...
- [Hbase]Hbase章1 Hbase框架及基本概念
Hbase框架介绍 HBase是一个分布式的.面向列的开源数据库. 不同点: l 和一般的关系数据库不同,hbase是一个适合于非结构化数据存储的数据库. l Hbase是基于列而不是基于行的模式 ...
- [Hbase]Hbase知识大全
HBase简介 是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop生态系统中的重要 ...
- [Hbase]Hbase技术方案
HBase架构简介 HBase在完全分布式环境下,由Master进程负责管理RegionServers集群的负载均衡以及资源分配,ZooKeeper负责集群元数据的维护并且监控集群的状态以防止单点故障 ...
- [Hbase]Hbase容灾方案
介绍两种HBase的数据备份或者容灾方案:Snapshot,Replication: 一.Snapshot 开启快照功能,在hbase-site.xml文件中添加如下配置项: <property ...
- [Hbase]hbase命令行基本操作
-进入hbase shell hbase shell - 帮助help help - 查看hbase versionversion - 查看hbase 状态 status - 创建表create 't ...
随机推荐
- EOS 数据库RAM使用量的计算
如果你是EOS的合约开发者,相信你很有可能跟我一样对内存(RAM)的使用量感到不解.在使用multi_index进行数据存储时,明明只存了一点数据,但区块链浏览器中显示的内存占用量却上升了不少.在这篇 ...
- 《精通CSS第3版》(5)漂亮的盒子
- linux下node.js 查版本号和更新 how to update node
我用的Mac,不是windows,不太清楚那个怎么搞. Linux下就是终端直接命令 //查版本号 node --version // v6.10.1 我很久没更了 //更新 //先清理Npm的cac ...
- xmlns:amq="http://activemq.apache.org/schema/core"报错
如题,项目集成ActiveMQ是配置文件报错 原因是:Spring命名空间配置错误,缺少相应的spring-bean.很显然,引用不到就是没有jar包啊. 我的解决办法,早pom.xml引用依赖 &l ...
- python限定方法参数类型、返回值类型、变量类型等
typing模块的作用 自python3.5开始,PEP484为python引入了类型注解(type hints) 类型检查,防止运行时出现参数和返回值类型.变量类型不符合. 作为开发文档附加说明,方 ...
- kafka与Rocketmq的区别
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介,可完全水平扩容,为了进一步降低成本,我们认为存储部分可以进一步优化,2011年初,Linkin开源了Kaf ...
- 简易商城 [ html + css ] 练习
1. 前言 通过使用 HTML + CSS 编写一个简易商城首页. 如图: 2. 布局思路 通过页面分析,大致可以决定页面的布局分为 5 大板块. 接下来,可以先定义页面的布局: <!DOCTY ...
- 查看appPackage和appActivity的多种方法
一.通过adb shell 查看 adb shell dumpsys activity | grep 包名 列如: C:\Users\admin>adb shell root@shamu:/ # ...
- precommit那些事儿
一.使用背景 我们有将 lint 命令添加进 npm scripts 中,但是很多人在提交代码时都会忘记或者没有习惯去执行检查,结果就是导致不符合规范的代码被上传到远端代码仓库. 二.问题分析 我们可 ...
- easyui datagrid 中序列化后的日期格式化
1.在easyui datagrid 中序列化后的日期显示为:/Date(1433377800000)/ 2.格式化后的显示为: 2015-06-04 08:30:00 3.使用代码如下: 3.1. ...