全面解读Group Normalization,对比BN,LN,IN
前言
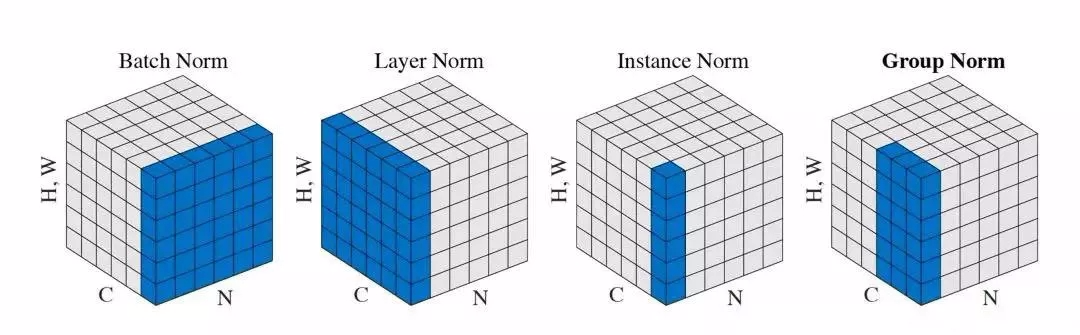
Group Normalizition是什么
What's wrong with BN

How GN work
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: input features with shape [N,C,H,W]
# gamma, beta: scale and offset, with shape [1,C,1,1]
# G: number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
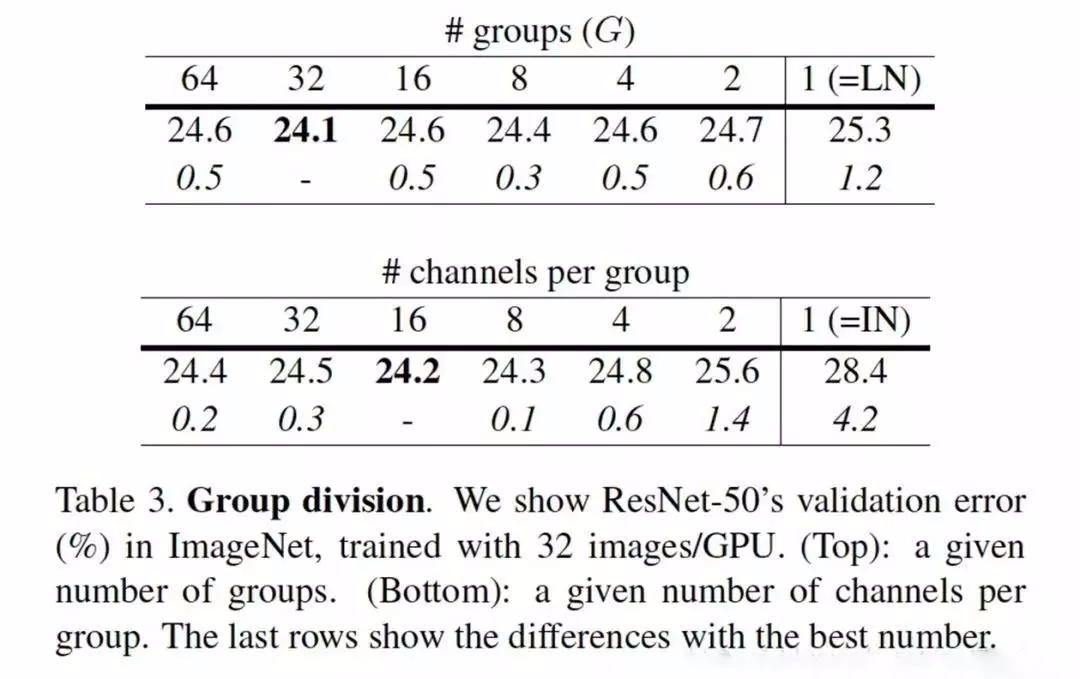
Why GN work
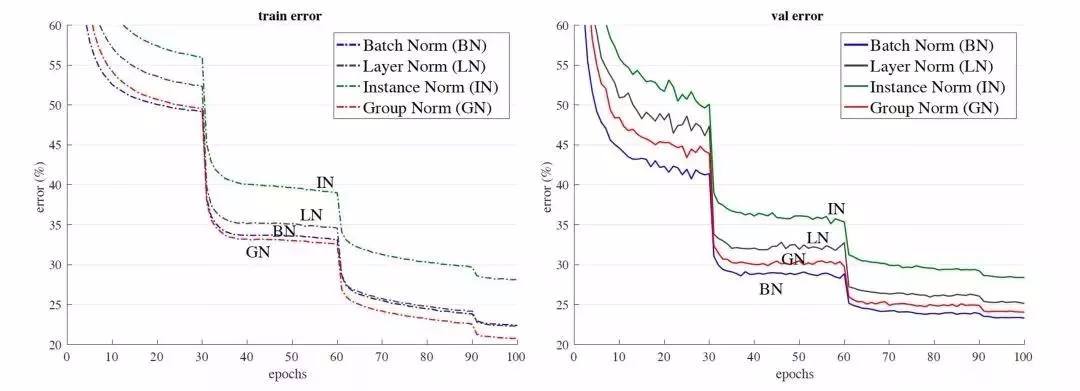
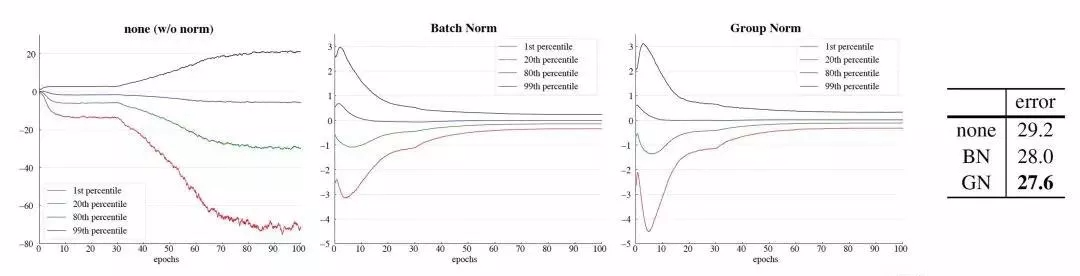
效果展示

全面解读Group Normalization,对比BN,LN,IN的更多相关文章
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- Group Normalization笔记
作者:Yuxin,Wu Kaiming He 机构:Facebook AI Research (FAIR) 摘要:BN是深度学习发展中的一个里程碑技术,它使得各种网络得以训练.然而,在batch维度上 ...
- Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization、Switchable Normalization比较
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更 ...
- Group Normalization
Group Normalization 2018年03月26日 18:40:43 阅读数:1351 FAIR 团队,吴育昕和恺明大大的新作Group Normalization. 主要的优势在于,BN ...
- 解读Batch Normalization
原文转自:http://blog.csdn.net/shuzfan/article/details/50723877 本次所讲的内容为Batch Normalization,简称BN,来源于<B ...
- SQL Server - Partition by 和 Group by对比
参考:https://www.cnblogs.com/hello-yz/p/9962356.html —————————————————— 今天大概弄懂了partition by和group by的区 ...
- partition by和group by对比
今天大概弄懂了partition by和group by的区别联系. 1. group by是分组函数,partition by是分析函数(然后像sum()等是聚合函数): 2. 在执行顺序上, 以下 ...
- MySQL 里面的Where 和Having和Count 和distinct和Group By对比
mysql> select accid as uid,date(datetime) AS datetime from game.logLogin GROUP BY accid HAVING da ...
- 深度学习归一化:BN、GN与FRN
在深度学习中,使用归一化层成为了很多网络的标配.最近,研究了不同的归一化层,如BN,GN和FRN.接下来,介绍一下这三种归一化算法. BN层 BN层是由谷歌提出的,其相关论文为<Batch No ...
随机推荐
- PE系统——安装教程
本教程使用到的软件我会在本文末给出,若失效了请私信我,重新上传. 1.安装PE系统前,把U盘插在电脑上(如果你需要安装Windows10系统,请插入一个容量至少8G的U盘).当然容量最好是32—64G ...
- vue辅助函数mapStates与mapGetters
状态管理器 <!-- store.js: --> import Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex) export de ...
- mouseover和mouseenter两个事件的区别
mouseover(鼠标覆盖) mouseenter(鼠标进入) 二者的本质区别在于,mouseenter不会冒泡,简单的说,它不会被它本身的子元素的状态影响到.但是mouseover就会被它的子元素 ...
- JavaWeb 之 JSTL 标签
JSTL 标签库 一.概述 1.概念 JSTL : JavaServer Pages Tag Library JSP标准标签库. 是由 Apache 组织提供的开源的免费的 jsp 标签. 2.作用 ...
- base64的使用
import base64with open("test.jpg", "rb") as f: file = f.read()file_base64 = base ...
- 基于cmake编译glew
cmake已经成为了C/C++开源项目的主流构建工具.glew也提供了cmake的脚本,但用cmake编译glew容易采坑:glew的github上的代码,无论是master分支还是glew-2.1. ...
- 交换机 VLAN 的划分
交换机怎么划分VLAN?本次的实验很简单,就是通过VLAN的划分,使不同VLAN之间无法通信,但是相同VLAN不受影响. 实验拓扑 在一台交换机下连接三台VPC,划分VLAN,地址规划如下: 名称 接 ...
- TensorFlow 2 快速教程,初学者入门必备
TensorFlow 2 简介 TensorFlow 是由谷歌在 2015 年 11 月发布的深度学习开源工具,我们可以用它来快速构建深度神经网络,并训练深度学习模型.运用 TensorFlow 及其 ...
- springboot 2.2.1默认跳到登录页
最新的springboot 2.2.1版本,启动之后访问http://localhost:8080 会直接跳转到默认登录页,是由于springboot默认配置了安全策略,在启动类中忽略该配置即可 在启 ...
- jQ native 构造函数