web端自动化——selenium3用法详解
selenium中文学习文档链接:https://selenium-python-zh.readthedocs.io/en/latest/getting-started.html
selenium3+Python3安装详看链接:https://www.cnblogs.com/linxiu-0925/p/9597634.html
sublime text3安装详看链接:https://www.cnblogs.com/linxiu-0925/p/9636301.html
selenium3、sublime text3安装过程在这就不细说了。
前提:
对于初学者来说,python自带的IDLE,精简又方便,不过一个好的编辑器能让python编码变得更方便,更加优美些。
不过呢,也可以自己去下载其他更好用的代码编辑器,在这推荐:
PyCharm,这是一个专门为python而开发设计的编辑器,功能齐全,方便实用。
Sublime Text,它不仅仅提供python编译,上面可以运行多种语言。画面精简美观,功能特别强大,可以自己设计一些参数调试编辑器功能。不过对于初次接触的人,安装python编译环境比较麻烦。
我前期使用的是python自带的IDLE编写代码,后面使用sublime Text、pycharm来编写代码。
#1导入模块
from selenium import webdriver
#2选择浏览器
browser = webdriver.Chrome()
browser = webdriver.Firefox()
brower = webdriver.IE()
具体例子代码如下:
#导入模块
from selenium import webdriver
#选择浏览器
browser = webdriver.Chrome()
#打开url
browser.get("http://www.baidu.com")
#关闭
browser.close()
3、查找元素
在一个页面中有很多不同的策略可以定位一个元素。在你的项目中, 你可以选择最合适的方法去查找元素。Selenium提供了下列的方法给你:
- find_element_by_id 定位唯一属性id。
- find_element_by_name 定位带有属性name。
- find_element_by_xpath XPath是一种在XML文档中定位元素的语言(比较难*)。
- find_element_by_link_text 定位文本链接。
- find_element_by_partial_link_ textpartial link定位是对 link定位的一种补充,有些文本链接会比较长,这个时候我们可以取文本链接的一部分定位,只要这一部分信息可以唯一地标识这个链接。
- find_element_by_tag_name 如打开任意一个页面,查看前端都会发现大量的<d i v>、<input>, <a>等tag ,所以很难通过标tag name去区分不同的元素。
- find_element_by_class_name 定位带有属性class。
- find_element_by_css_selector CSS是一种语言,它用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定属性。(比较难*)
1.9 用By定位元素
针对前面介绍的8种定位方法,WebDriver还提供了另外一套写法,即统一调用 find_element()方法 ,通过By来声明定位的方法,并且传入对应定位方法的定位参数。具体如下:
find_element(By.id,"kw")
find_element(By.name,"wd")
find_element(By.class_name,"s_ipt")
find_element(By.tag_name,"input")
find_element(By.link_text,"新 闻 ")
find_element(By.partial_link_text," 新 ")
find_element(By.XPath,"//* [@class = ‘bg s_btn’ ]")
find_element(By.CSS_selector,"span .bg s_btn_wr>input#su")
find_element()方法只用于定位元素。它需要两个参数,第一个参数是定位的类型,由By提供;第二个参数是定位的具体方式。在使用By之前需要将By类导入。
from selenium.webdriver.common.by import By
一次查找多个元素 (这些方法会返回一个list列表):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
除了上述的公共方法,下面还有两个私有方法,在你查找也页面元素的时候也许有用。 他们是 find_element 和 find_elements 。
另外还有通过BY元素属性来查找元素。
例子:
在引用from selenium import webdriver的基础上,还得引用from selenium.webdriver.common.by import By。
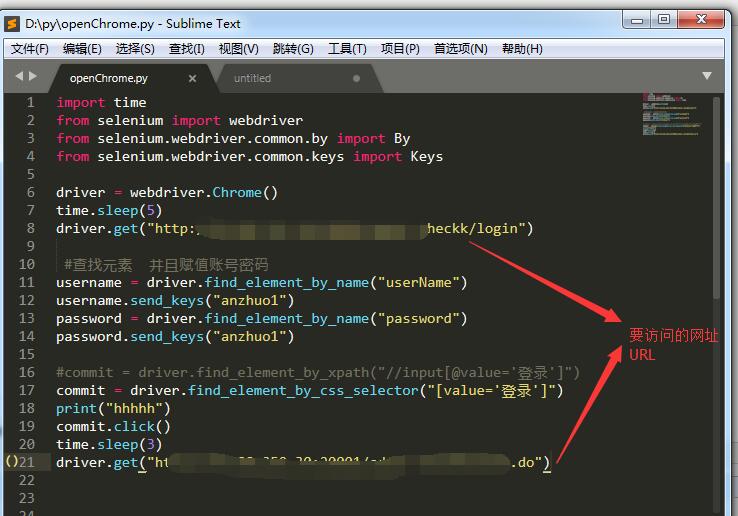
代码如下:环境【selenium3+Python3+sublime text3】,
1、在sublime text3编写代码自动化登录进入主页的过程:输入正确的账号密码,然后点击登录,进入测试网址的主页面。
2、接着保存为py文件,如:openChrome.py,保存在D盘的py文件路径下,
3、然后通过Windows电脑的cmd命令行运行python命令:python D:\py\openChrome.py,即可
selenium用法讲解:
(1)浏览器操作:
WebDriver提供了maxmize_window()方法使打开的浏览器全屏显示,其用法与set_window_sizeO相同, 但它不需要参数。
WebDriver提供了back()和forward()方法来模拟后退和前进按钮。
WebDriver提供了refresh()方法模拟刷新。
WebDriver提供了截图函数get_screenshot_as_file()来截取当前窗口。
如:driver.get_screenshot_as_file(r"C:\Users\baidu.png")
WebDriver还提供了close()方法,用来关闭当前窗口。
WebDriver还提供了quit()方法,用来退出驱动并关闭所有关联的窗口。
(2)元素基本操作
clear(): 清除文本
send_keys ( * value): 模拟按键输入
click(): 单击元素
submit(): 提交表单
size: 返回元素的尺寸
text: 获取元素的文本
current_url: 获取当前URL
title: 获取元素的标题
get_attribute(name):获得属性值
is_displayed():判断该元素是否用户可见
(3)鼠标事件
在WebDriver,将这些关于鼠标操作的方法封装在ActionChains类提供:
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
使用的时候需导入:from selenium.webdriver.common.action_chains import ActionChains
(4)键盘事件
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
send_keys(Keys.BACK_SPACE) 删除键(backspace)
send_keys( Keys. SPACE) 空格键(space)
send_keys( Keys.TAB) 制表键(Tab)
send_keys( Keys. ESCAPE) 回退键(esc)
send_keys( Keys. ENTER) 回车键(enter)
send_keys(Keys.CONTROL,’a’) 全选(ctrl+A)
send_keys(Keys.CONTROL,’c’) 复制(ctrl+C)
send_keys(Keys.CONTROL,’x’) 剪切(ctrl+X)
send_keys(Keys.CONTROL,’v’) 粘贴(ctrl+v)
send_keys(keys.F1) 键盘F1
……
send_keys(keys.F12) 键盘F12
使用的时候需导入:from selenium.webdriver.common.keys import Keys
(5)设置元素等待
Webdriver提供了两种类型的等待:显式等待和隐式等待。
5.1)显式等待
显式等待使Webdriver等待某个条件成立时继续执行,否则在达到最大时长时抛出超时异常(TimeoutException)。

WebDriverWait类是由WebDirver提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。具体格式如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored__exceptions=None)
driver :浏览器驱动。
timeout :最长超时时间,默认以秒为单位.
poll__frequency:检测的间隔(步长)时间,默认为0.58。
ignored_exceptions :超时后的异常信息,默认情况下抛NoSuchElementException异常。
WebDriverWait()一般由until()或until_not()方法配合使用,下面是until()和until_not()方法的说明。
until(method,message=‘’)
调用该方法提供的驱动程序作为一个参数,直到返回值为True。
until_not(method, message=‘’)
调用该方法提供的驱动程序作为一个参数,直到返回值为False。
通过as关键字将expected_conditions重命名为EC,并调用presence_of_element_located()方法判断元素是否存在。
记得导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
5.2)隐式等待
隐式等待是通过一定的时长等待页面上某元素加载完成。如果超出了设置的时长元素 还没有被加载,则抛出 NoSuchElementException 异常。WebDriver 提供了 implicitly_wait() 方法来实现隐式等待,默认设置为0。
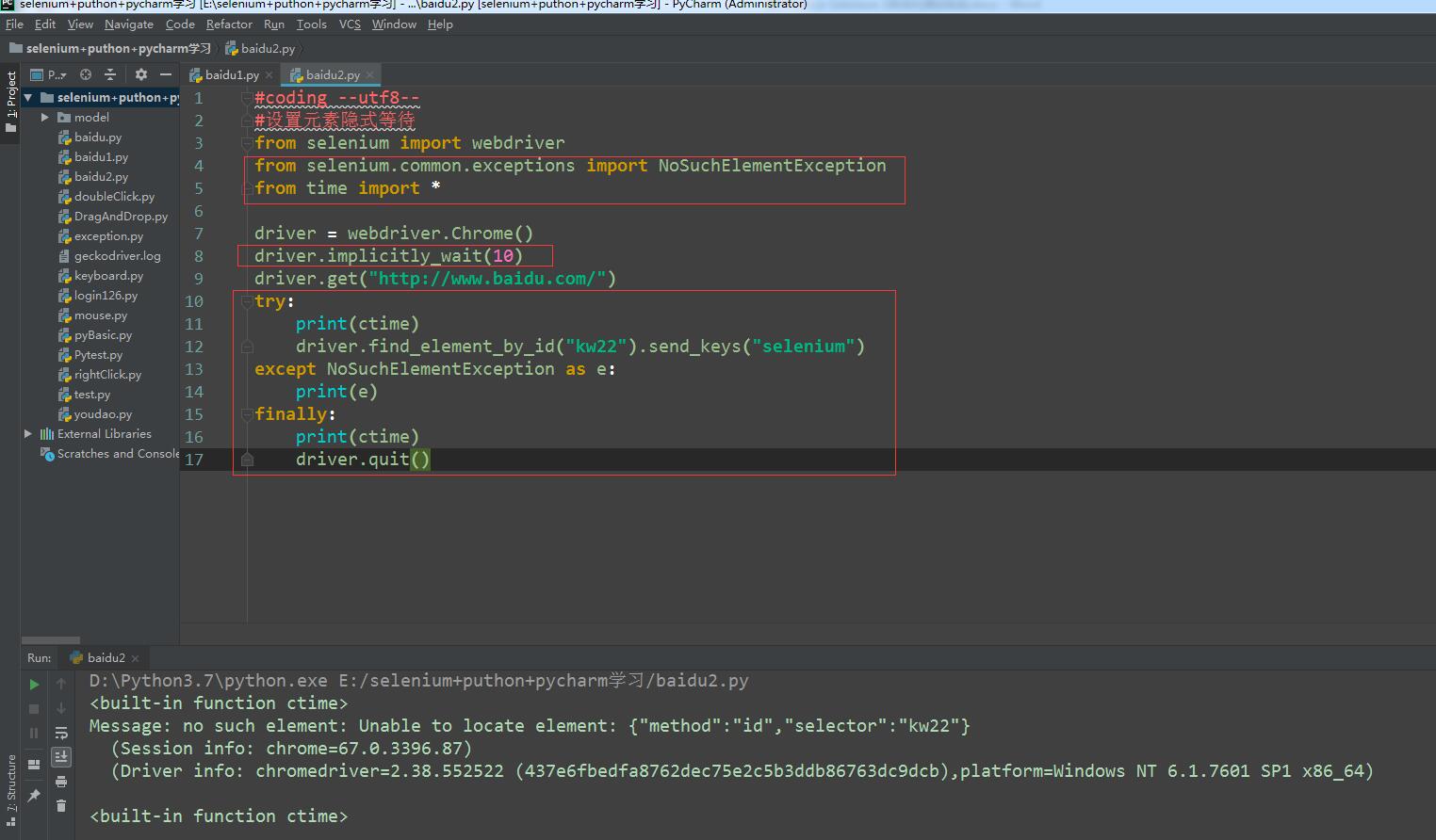
implicitly_wait()默认参数的单位为秒,本例中设置等待时长为10秒。首先这10秒并非一个固定的等待时间,它并不影响脚本的执行速度。其次,它并不针对页面上的某一元素进行等待。当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它将以轮询的方式不断地判断元素是否被定位到。假设在第6秒定位到了元素则继续执行,若直到超出设置时长(10秒)还没有定位到元素,则抛出异常。
记得导入:
from selenium.common.exceptions import NoSuchElementException
from time import *
5.3)休眠等待
脚本在执行到某一位置时做固定时间的休眠,尤其是在脚本调试过程中。这时可以使用sleep()方法,需要说明的是,sleep()方法由Python的time模块提供。

当执行到sleep()方法时会固定休眠一定的时长,然后再继续执行。sleep()方法默认参数以秒为单位,如果设置时长小于1秒,则可以用小数表示,如sleep(0.5)表示休眠0.5秒。
记得导入:
from time import * #from time import sleep
(6)复选框
Len()方法可以用来计算元素的个数;
click()方法是对某个元素进行勾选;
pop().click(),其实是对某个元素取消勾选。
如果只想勾选一组元素中的某一个该如何操作呢?
pop()或pop(-1): 默认获取一组元素中的最后一个。
pop(0): 默认获取一组元素中的第一个。
pop(1): 默认获取一组元素中的第二个。
这样就可以操作这一组元素中的任意一个元素了,只需数一数需操作的元素是这一组中的第几个。
(7)多表单切换
switch_to_frame()默认可以直接取表单的id或name属性,如果iframe没有可用的id和name属性,则可以通过下面的方式xpath进行定位。
xf=driver.find_element_by_xpath("//div[@id='loginDiv']/iframe")
driver.switch_to.frame(xf)
补充:
switch_to.parent_content()跳出当前一级表单;
switch_to.default_content()跳回最外层的页面。
(8)多窗口切换
Webdriver提供了switch_to_window()方法,可以实现在不同的窗口之间切换。
current_window_handle:获得当前窗口句柄。
window_handles:返回所有窗口的句柄到当前会话。
switch_to.window();用于切换到相应的窗口,与上一节的switch_to.frame ()类似,前者用于不同窗口的切换,后者用于不同表单之间的切换。

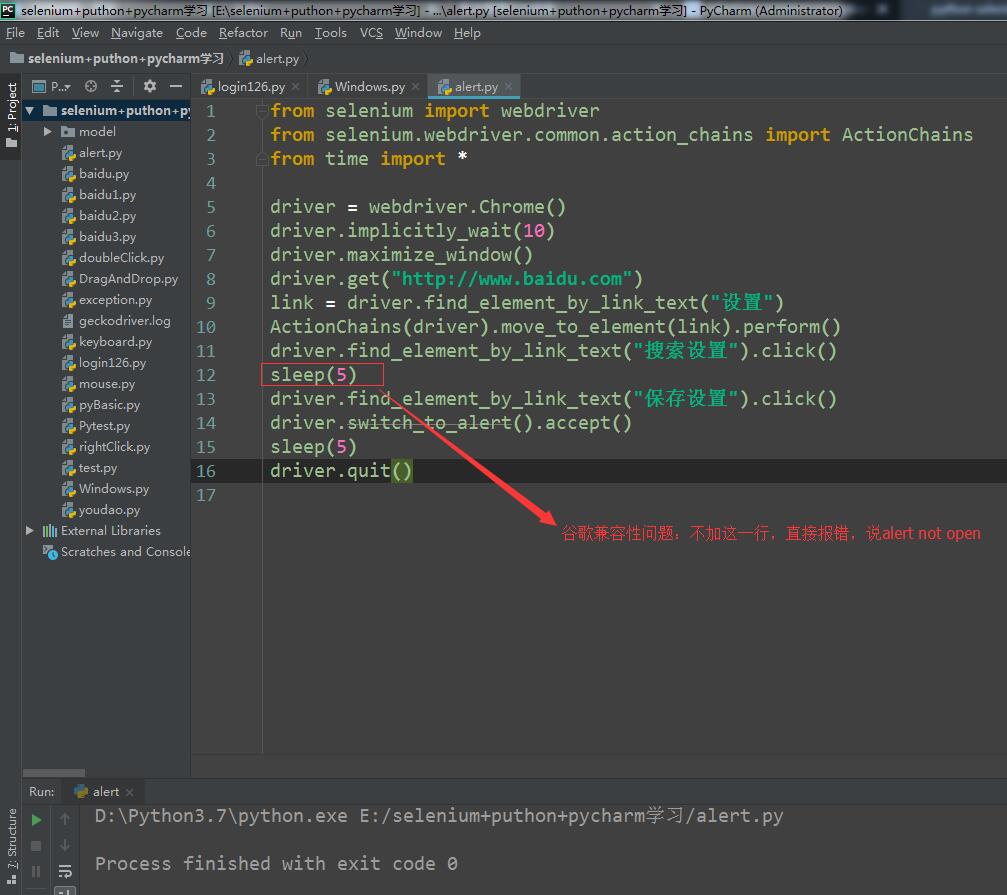
(9)警告框处理
在WebDriver中处理JavaScript所生成的alert、confirm以及prompt十分简单,具体做法是使用switch_to_alert()方法定位到 aler/confim/prompt,然后使用 text/accept/dismiss/send_keys等方法进行操作。
1) text:返回aler/confirm/prompt中的文字信息。
2) accept():接受现有警告框。
3) dismiss():解散现有警告框。
4) send_keys(keysToSend): 发送文本至警告框。keysToSend:将文本发送至警告框。
(10)文件上传、下载
对于Web页面的上传功能实现一般有以下两种方式。
1) 普通上传:普通的附件上传是将本地文件的路径作为一个值放在input标签中,通过form表单将 这个值提交给服务器。
2) 插件上传:一般是指Flash、Javascript、Ajax等技术所实现的上传功能。
send_keys实现上传
对于通过input标签实现的上传功能,可以将其看作是一个输入框,即通过send_keys()指定本地文件路径的方式实现文件上传。
记得导入:import os
file_path='file:///'+os.path.abspath('upfile.html')
driver.get(file_path)
upfile.html就是文件名称。
AutoIt实现上传
AutoIt目前最新版本是v3,它是一个使用类似BASIC脚本语言的免费软件,它被设计用来进行Windows GUI(图形用户界面)的自动化测试。它利用模拟键盘按键,鼠标移动和窗口/控件的组合来实现自动化任务。
官方网站:https://www.autoitscript.com/site/。
这种方式不推荐使用,因为生成的exe文件不在python里面,不可控。
文件下载
WebDriver允许我们设置默认的文件下载路径,也就是说,文件会自动下载并且存放到设置的目录中。
为了让Firefox浏览器能实现文件下载,我们需要通过FirefoxProfile()对其做一些设置。
browser.download.folderList
设置成0代表下载到浏览器默认下载路径,设置成2则可以保存到指定目录。
browser.download.manager.showWhenStarting
是否显示开始;True为显示,Flase为不显示。
browser.download.dir
用于指定所下载文件的目录。Os.getcwd()函数不需要传递参数,用于返回当前的目录。 browser.helperApps.neverAsk.saveToDisk
指定要下载页面的Content_type值,“application/octet-stream”为文件的类型。
HTTP Content-type 常用对照表:http://tool.oschina.net/commons
#下载文件
from selenium import webdriver
import os
from time import *
from selenium.webdriver.common.action_chains import ActionChains fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showWhenStarting",True)
fp.set_preference("browser.download.useDownloadDir","F:\\下载") fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream")#下载文件的类型
driver = webdriver.Firefox(firefox_profile=fp)
driver.get("https://www.python.org/")#下载文件的URL
driver.implicitly_wait(10)
download = driver.find_element_by_link_text("Downloads")
ActionChains(driver).move_to_element(download).perform()
driver.find_element_by_link_text("Windows").click()
driver.find_element_by_link_text("Latest Python 3 Release - Python 3.7.1").click()
print("正在下载中")
sleep(10)
driver.quit()
(11)操作cookie
WebDriver操作cookie的方法:
1)get_cookiess():获得所有 cookie 信息。
1) get_cookie(name):返回字典的 key 为“name” 的 cookie 信息。
2) add_cookie(cookie_dict):添加cookie。“cookie_dict”指字典对象,必须有name和value值。
4)delete_cookie(name,optionsString):删除cookie信息。“name”是要删除的cookie的名称,“optionsString”是该cookie的选项,目前支持的选项包括“路径”,“域”。
5)delete_all_cookies():删除所有 cookie 信息。
from selenium import webdriver
from time import *
driver = webdriver.Chrome()
driver.get("http://www.youdao.com")
cookie = driver.get_cookies()
print(cookie)
driver.add_cookie({'name':'key-aaa','value':'value-bbb'})
cookie = driver.get_cookies()
for cookie in driver.get_cookies():
print("%s -> %s" % (cookie['name'], cookie['value']))
sleep(5)
driver.quit()
(12)滚动条操作
浏览器滚动条并没有提供相应的操作方法。在这种情况下,就可以借助JavaScript来控制浏览器的滚动条。 WebDriver提供了execute_script()方法来执行JavaScript代码。
js="window.scrollTo(100,450);"
driver.execute_script(js)
(13)HTML5的视频播放
test_video.py
from selenium import webdriver
from time import *
driver=webdriver.Chrome()
driver.get("http://videojs.com/")
video=driver.find_element_by_xpath(".//*[@id='preview-player_html5_api']")
#返回文件的播放地址
url=driver.execute_script("return arguments[0].currentSrc;",video)
print(url)
print("start")
driver.execute_script("return arguments[0].play();",video)
#播放15秒
sleep(15)
print("stop")
driver.execute_script("arguments[0].pause();",video)
sleep(5)
driver.quit()
JavaScript函数有个内置的对象叫做arguements。arguements对象包含了函数调用的参数数组,[0]表示取对象的第1个值。
currentSrc熟悉返回当前音频/视频的URL。如果未设置音频/视频,则返回空字符串。
load()、play()、 pauseO等控制着视频的加载、播放和暂停。
(14)验证码处理
记得导入:from random import randint
14.1去掉验证码
14.2设置万能验证码
例子如下:
from selenium import webdriver
from random import randint
from time import * verify = randint(1000,9999)
print("生成的随机数:%d" %verify)
number = input("请输入随机数:")
print(number)
number = int(number)
if number == verify:
print("登录成功")
elif number == 132741:
print("登录成功")
else:
print("验证码输入有误") 14.3记录cookie
通过向浏览器中添加cookie可以绕过登录的验证码,这是比较有意思的一种解决方案。
使用cookie进行登录最大的难点是如何获得用户名密码的name ,如果找到不到name 的名字,就没办法向value 中输用户名、密码信息。
我建议是可以通过get_cookies()方法来获取登录的所有的cookie信息,从而进行找到用户名、密码的name 对象的名字;
当然,最简单的方法还是询问前端开发人员。
cookie是由path,domain,name,value这些东西组成的。通过登录之后查看抓取cookie
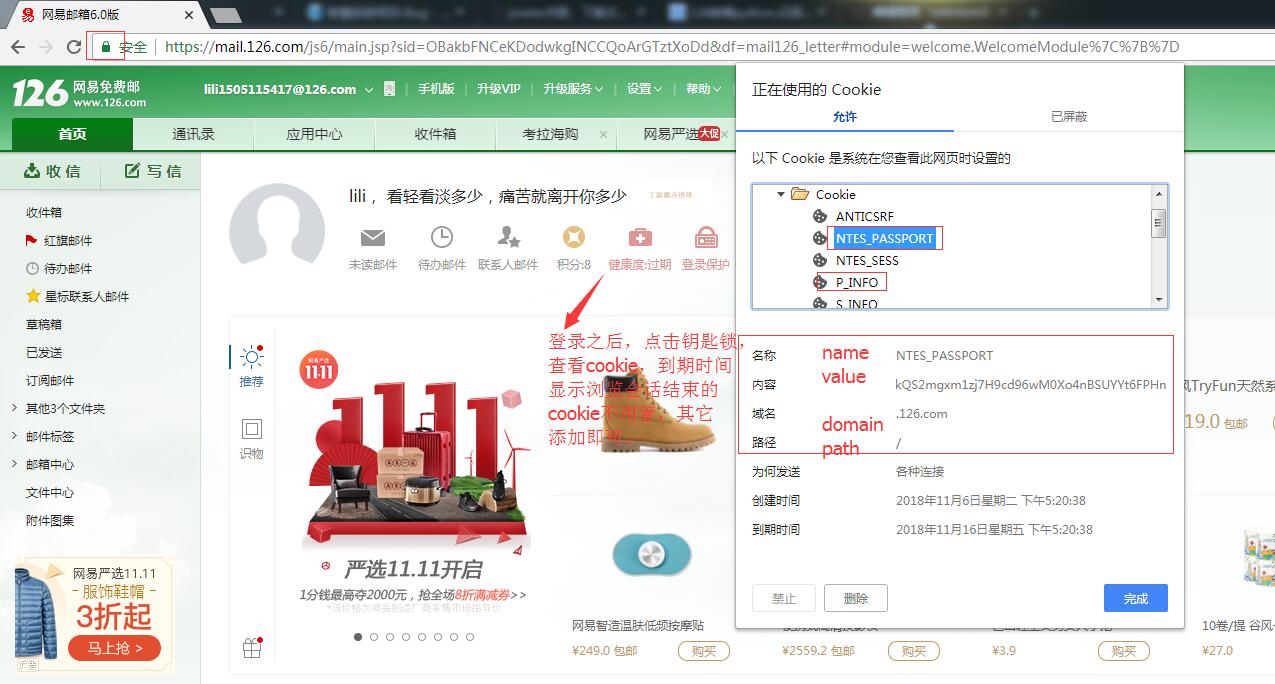
1查看代码如下:
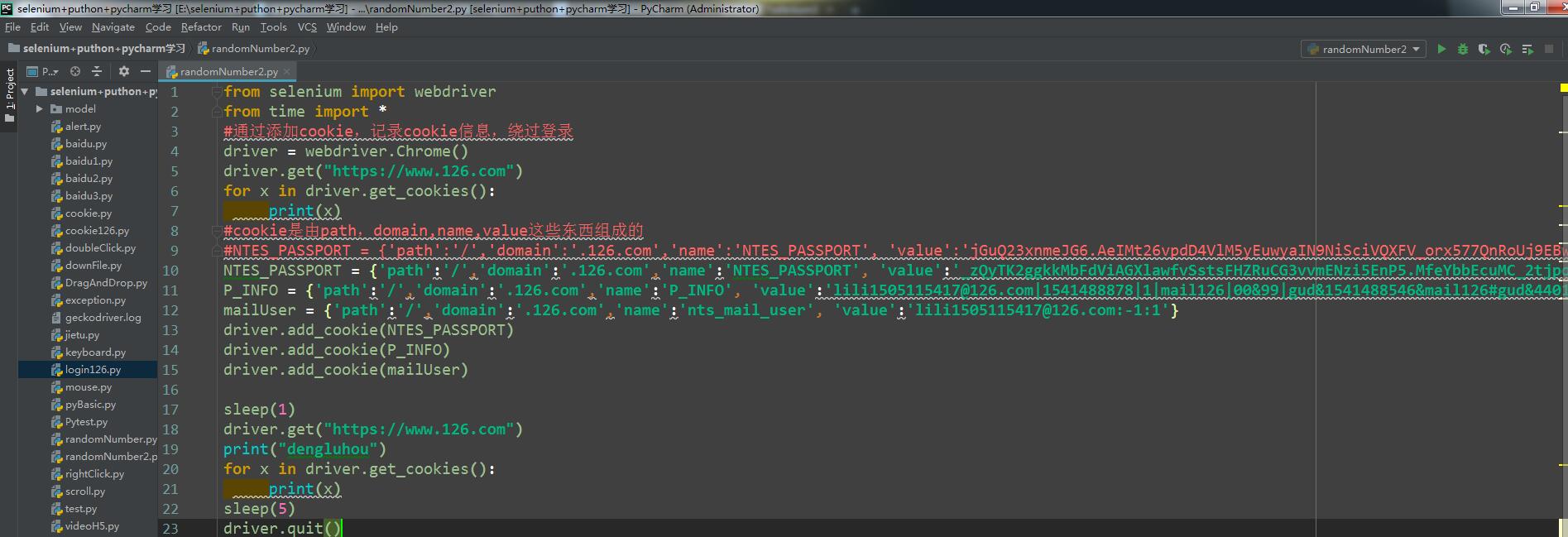
2直接可以复制的代码如下:
from selenium import webdriver
from time import *
#通过添加cookie,记录cookie信息,绕过登录
driver = webdriver.Chrome()
driver.get("https://www.126.com")
for x in driver.get_cookies():
print(x)
#cookie是由path,domain,name,value这些东西组成的
#NTES_PASSPORT = {'path':'/','domain':'.126.com','name':'NTES_PASSPORT', 'value':'jGuQ23xnmeJG6.AeIMt26vpdD4VlM5yEuwyaIN9NiSciVQXFV_orx577QnRoUj9EBwk8vmaaKeGTVow.w0PyLqqDs1MMxO6sUjd1slzQOV6MCoUVcTOplG5PwYsdxyBtcJA2fYTIawueAA2nS2KV_i1HUny7ocH9PyJQwDIFFlqPR4DtPsqNrrignV_iShGt5'}
NTES_PASSPORT = {'path':'/','domain':'.126.com','name':'NTES_PASSPORT', 'value':'_zQyTK2ggkkMbFdViAGXlawfvSstsFHZRuCG3vvmENzi5EnP5.MfeYbbEcuMC_2tjpoTA1yy3hIB5MpUpqlzX66VvJOOeDGvCNk.E1G6unLqMiwhVTJA5BV0j6ggfC3OgHHs_bKmWvD6Gv53sNAmxVUATBfxfq_fLTyJTBo3tezVSz4RGiO6hDKfA00U4dweD'}
P_INFO = {'path':'/','domain':'.126.com','name':'P_INFO', 'value':'lili1505115417@126.com|1541488878|1|mail126|00&99|gud&1541488546&mail126#gud&440100#10#0#0|&0|mail126|lili1505115417@126.com'}
mailUser = {'path':'/','domain':'.126.com','name':'nts_mail_user', 'value':'lili1505115417@126.com:-1:1'}
driver.add_cookie(NTES_PASSPORT)
driver.add_cookie(P_INFO)
driver.add_cookie(mailUser) sleep(1)
driver.get("https://www.126.com")
print("dengluhou")
for x in driver.get_cookies():
print(x)
sleep(5)
driver.quit()
14.4验证码图片技术处理
这种方法需要研究验证码技术处理。
web端自动化——selenium3用法详解的更多相关文章
- web端自动化——Selenium3+python自动化(3.7版本)-火狐62版本环境搭建
前言 目前selenium版本已经升级到3.0了,网上的大部分教程是基于2.0写的,所以在学习前先要弄清楚版本号,这点非常重要.本系列依然以selenium3为基础. 一.selenium简介 Sel ...
- web端自动化——Selenium3+python自动化(3.7版本)-chrome67环境搭建
前言 目前selenium版本已经升级到3.0了,网上的大部分教程是基于2.0写的,所以在学习前先要弄清楚版本号,这点非常重要.本系列依然以selenium3为基础. 一.selenium简介 Sel ...
- web端自动化——selenium3+Python3+pycharm自动化
1.前言: 对于初学者来说,python自带的IDLE,精简又方便,不过一个好的编辑器能让python编码变得更方便,更加优美些. 不过呢,也可以自己去下载其他更好用的代码编辑器,在这推荐: PyCh ...
- 移动端自动化==>AppiumApi接口详解
Appium 初始化配置信息(Desired Capabilities) Desired Capabilities实际上就是一个字典,它主要用于向Appium Server提供初始化配置参数,如:想要 ...
- 1:CSS中一些@规则的用法小结 2: @media用法详解
第一篇文章:@用法小结 第二篇文章:@media用法 第一篇文章:@用法小结 这篇文章主要介绍了CSS中一些@规则的用法小结,是CSS入门学习中的基础知识,需要的朋友可以参考下 at-rule ...
- centos7.2环境nginx+mysql+php-fpm+svn配置walle自动化部署系统详解
centos7.2环境nginx+mysql+php-fpm+svn配置walle自动化部署系统详解 操作系统:centos 7.2 x86_64 安装walle系统服务端 1.以下安装,均在宿主机( ...
- Sqlmap 工具用法详解
Sqlmap 工具用法详解 sqlmap是一款自动化的sql注入工具. 1.主要功能:扫描.发现.利用给定的url的sql注入漏 ...
- @RequestMapping 用法详解之地址映射
@RequestMapping 用法详解之地址映射 引言: 前段时间项目中用到了RESTful模式来开发程序,但是当用POST.PUT模式提交数据时,发现服务器端接受不到提交的数据(服务器端参数绑定没 ...
- linux管道命令grep命令参数及用法详解---附使用案例|grep
功能说明:查找文件里符合条件的字符串. 语 法:grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>] ...
随机推荐
- vs 在高分屏下开发 winform 配置
一.窗体控件大小 第一种方法:使用网格避免整除误差 在选项中将Windows窗体设计器的LayoutMode(布局模式)改成SnapToGrid(对齐到网格),并将Default Grid Cell ...
- Firefox修復QQ快速登錄
中了一次毒,然後火狐裏面就不能用QQ的快捷登錄了,後找到修復方法: 將QQ的四個文件放入火狐的插件文件夾裏面即可. 1.QQ文件目錄: C:\Program Files (x86)\Tencent\Q ...
- maven ssm 编译异常记录:
maven ssm 编译异常记录: javax.servlet.jsp 解决: 清除 tomacat libraries 修改 pom 文件 <dependency> <groupI ...
- Pytest权威教程12-跳过(Skip)及预期失败(xFail): 处理不能成功的测试用例
目录 跳过(Skip)及预期失败(xFail): 处理不能成功的测试用例 Skip跳过用例 xFail:将测试函数标记为预期失败 Skip/xFail参数设置 返回: Pytest权威教程 跳过(Sk ...
- StarUML自动生成Java代码
下载一个starUML 链接:https://pan.baidu.com/s/1pIGNVmhtwBxMrCG9LHdkCQ 提取码:c4i6 复制这段内容后打开百度网盘手机App,操作更方便哦 添加 ...
- 超级详细的git使用指北
原文地址:https://www.cnblogs.com/wupeixuan/p/11947343.html 1.0 安装和配置 1.1 Git 安装 1.2 Git 配置 2.0 Git 基 ...
- border-radius后面写px/rem与百分比有什么区别?
首先百分比,表示的是设置50%表示的是圆是弧度,设置px/rem,是表示你想要变圆弧的半径是多少
- spring boot 之登录拦截
登录拦截,请求的session里面有username者判断为登录状态 @Configuration public class WebSecurityConfig extends WebMvcConfi ...
- 五笔字典86版wubi拆字图编码查询
五笔字典86版 软件能查询以下数据,五笔编码,汉字拆字图,拼音,部首,笔划,笔顺,解释,五笔口诀等等.这些数据只针对单个汉字查询(大概7000字左右).词组查询只支持五笔编码查询(有60000个词组+ ...
- 与 ES5 相比,React 的 ES6 语法有何不同?
以下语法是 ES5 与 ES6 中的区别: 1.require 与 import // ES5 var React = require('react'); // ES6 import React fr ...