Spark(四十六):Spark 内存管理之—OFF_HEAP
存储级别简介
Spark中RDD提供了多种存储级别,除去使用内存,磁盘等,还有一种是OFF_HEAP,称之为 使用JVM堆外内存

使用OFF_HEAP的优点:在内存有限时,可以减少频繁GC及不必要的内存消耗(减少内存的使用),提升程序性能。
Spark内存管理根据版本划分为两个阶段:spark1.6[官网给出spark1.5之前(包含spark1.5)]之前阶段、spark1.6之后阶段。
1.6.0及以后版本,使用的统一内存管理器,由UnifiedMemoryManager实现。
- ü MemoryManger在spark1.6之前采用静态内存管理
(StaticMemoryManager[https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/memory/StaticMemoryManager.scala]),
- ü Spark1.6之后默认为统一内存管理
(UnifiedMemoryManager[https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/memory/UnifiedMemoryManager.scala])统一内存管理模块包括了堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)两大区域
从1.6.0版本开始,Spark内存管理模型发生了变化。旧的内存管理模型由StaticMemoryManager类实现,现在称为“legacy(遗留)”。默认情况下,“Legacy”模式被禁用,这意味着在Spark 1.5.x和1.6.0上运行相同的代码会导致不同的行为。
为了兼容,您可以使用spark.memory.useLegacyMode参数(目前spark2.4版本中也依然保留这个静态内存管理模型)启用“旧”内存模型:
- spark.memory.useLegacyMode=true(默认为false)
该参数官网给出的解释:
Whether to enable the legacy memory management mode used in Spark 1.5 and before. The legacy mode rigidly partitions the heap space into fixed-size regions, potentially leading to excessive spilling if the application was not tuned. The following deprecated memory fraction configurations are not read unless this is enabled:
spark.shuffle.memoryFraction
spark.storage.memoryFraction
spark.storage.unrollFraction
在Spark1.x以前,默认的off_heap使用的是Tachyon。但是Spark中默认操作Tachyon的TachyonBlockManager开发完成之后,代码就不再更新。当Tachyon升级为Alluxio之后移除不使用的API,导致Spark默认off_heap不可用(spark1.6+)。
错误情况可参考:https://alluxio.atlassian.net/browse/ALLUXIO-1881
Spark2.0的OFF_HEAP
从spark2.0开始,移除默认的TachyonBlockManager以及ExternalBlockManager相关的API。
移除情况可参考:https://issues.apache.org/jira/browse/SPARK-12667。
但是在Spark2.x的版本中,OFF_HEAP这一存储级别,依然存在:

那么,这里的OFF_HEAD 数据是如何存储的呢?
在org.apache.spark.memory中,有一个MemoryMode,MemoryMode标记了是使用ON_HEAP还是OFF_HEAP。
在org.apache.spark.storage.memory.MemoryStore中,根据MemoryMode类型来调用不同的存储。

在MemoryStore中putIteratorAsBytes方法,是用于存储数据的方法。

其实真正管理(存储)values的对象是valuesHolder,valueHolder是SerializedValuesHolder的类对象,我们看下SerializedValuesHolder是怎么定义的。
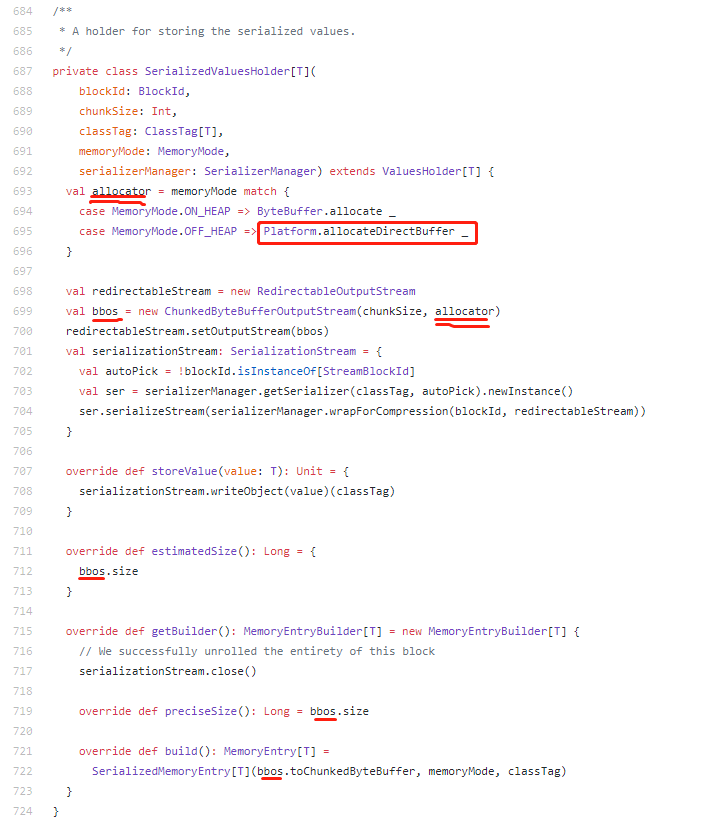
在该方法中,OFF_HEAP使用的是org.apache.spark.unsafe.Platform(https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java)来做底层存储的,Platform是利用java unsafe API实现的一个访问off_heap的类,所以,spark2.x的OFF_HEAP就是利用java unsafe API实现的内存管理。
Spark2.x OFF_HEAP优势:
- ü 优点:在内存有限时,可以减少频繁GC及不必要的内存消耗(减少内存的使用,),提升程序性能。
- ü 缺点:没有数据备份,也不能像alluxio那样保证数据高可用,丢失数据则需要重新计算。
参考
《Spark2.x 内存管理之---OFF_HEAP https://blog.csdn.net/qq_21439395/article/details/80773121》
- 关于 java unsafe API 可参考:
《Java中Unsafe类详解 https://www.cnblogs.com/mickole/articles/3757278.html 》
《JAVA并发编程学习笔记之Unsafe类 https://blog.csdn.net/aesop_wubo/article/details/7537278》
Spark(四十六):Spark 内存管理之—OFF_HEAP的更多相关文章
- Android简易实战教程--第四十六话《RecyclerView竖向和横向滚动》
Android5.X后,引入了RecyclerView,这个控件使用起来非常的方便,不但可以完成listView的效果,而且还可以实现ListView无法实现的效果.当然,在新能方便也做了大大的提高. ...
- linux基础-第十六单元 yum管理RPM包
第十六单元 yum管理RPM包 yum的功能 本地yum配置 光盘挂载和镜像挂载 本地yum配置 网络yum配置 网络yum配置 Yum命令的使用 使用yum安装软件 使用yum删除软件 安装组件 删 ...
- NeHe OpenGL教程 第四十六课:全屏反走样
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- Linux操作系统基础(四)保护模式内存管理(2)【转】
转自:http://blog.csdn.net/rosetta/article/details/8570681 Linux操作系统基础(四)保护模式内存管理(2) 转载请注明出处:http://blo ...
- 四十六、android中的Bitmap
四十六.android中的Bitmap: http://www.cnblogs.com/linjiqin/archive/2011/12/28/2304940.html 四十七.实现调用Android ...
- “全栈2019”Java第四十六章:继承与字段
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 第四十六个知识点 在Sigma协议中,正确性,公正性和零知识性意味着什么
第四十六个知识点 在Sigma协议中,正确性,公正性和零知识性意味着什么 Sigma协议 Sigma协议是Alice想要向Bob证明一些东西的协议(Alice知道一些秘密).他们有下面的一般范式:Al ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- Spark 1.6以后的内存管理机制
Spark 内部管理机制 Spark的内存管理自从1.6开始改变.老的内存管理实现自自staticMemoryManager类,然而现在它被称之为"legacy". " ...
随机推荐
- 【English】 Re-pick up English for learning big data (not updated regularly)
2019.10.6 parse:解析mean:平均数stddev:标准偏差 2019.10.7 bigdata platform:大数据平台 2019.10.14 allocate resource ...
- LInux-命令在后台运行
在终端运行一个持续很久的命令,一旦开始运行这个终端就会等待命令结束,才能输入下个指令,所以可以让这种指令放到后台运行,终端可以继续执行新指令. 后台运行 这种命令要满足1.要运行一段时间2.不需要与用 ...
- CPN tools 帮助文档资料和实例
1.替代变迁 包含有替代变迁的页面叫做父页,当CPN网使用替代变迁的时候,替代变迁所表达的逻辑必须在某一个位置得到实现,实现替代变迁逻辑页面叫做子页或者子网. 将替代变迁相邻的库所叫做槽库所,也即是在 ...
- Java8 Stream 流使用场景和常用操作
JAVA8内置的函数式编程接口应用场景和方式 pojo类对象和默认创建list的方法 import lombok.AllArgsConstructor; import lombok.Data; imp ...
- qingqing的项目
1 https://www.cnblogs.com/zhangqing979797/p/10147679.html 2 https://www.cnblogs.com/zhangqing979797/ ...
- STM32移植USB驱动总结
https://blog.csdn.net/stm32_newlearner/article/details/88095944 stm32 移植usb驱动开发 单片机 STM32单片机和51单片机 ...
- 《Exception》第五次作业:项目需求分析改进与系统设计
一.项目基本介绍 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 Exception 作业学习目标 1掌握面向对象需求分析方法:2.学习软件系统总 ...
- Exec Maven插件
1.为什么使用exec? 现在的工程往往依赖 众多的jar包,不像war包工程,对于那些打包成jar包形式的本地java应用来说,通过java命令启动将会是一件极为繁琐的事情,原因很简单,太 多的依赖 ...
- Nginx一个server配置多个location(使用alias)
公司测试环境使用nginx部署多个前端项目.网上查到了两个办法: 在配置文件中增加多个location,每个location对应一个项目比如使用80端口,location / 访问官网: locati ...
- 用1 x 2的多米诺骨牌填满M x N矩形的方案数(完美覆盖)
题意 用 $1 \times 2$ 的多米诺骨牌填满 $M \times N$ 的矩形有多少种方案,$M \leq 5,N < 2^{31}$,输出答案模 $p$. 分析 当 $M=3$时,假设 ...